ACC baseline 정리 (ConvN->Transformer)
요약
본 시스템은 ConvNeXt 인코더, 투사층, 트랜스포머 디코더로 구성된 시퀀스-투-시퀀스 DNN 모델이다. 주요 특징은 다음과 같다:
- 인코더: AudioSet에서 사전 학습된 ConvNeXt 사용, 고정된 가중치.
- 투사층: 드롭아웃, 선형(Linear), ReLU, 드롭아웃으로 구성.
- 디코더: PyTorch의 기본 TransformerDecoder 사용, 문장의 이전 단어와 함께 다음 단어 분포 생성.
- 학습 설정:
Clotho 개발-훈련 서브셋에서 400 에포크 학습.
배치 크기 64, 그래디언트 축적 8 (실제 배치 크기 512).
AdamW 옵티마이저, 초기 학습률 5e-4, 코사인 감쇠.
가중치 감쇠 2, 과적합 방지.
L2 노름 그래디언트 클리핑, 값 1.
라벨 스무딩, 최고 확률 0.2 감소.
오디오와 이전 단어 특징 간의 믹스업으로 잡음 추가. - 추론 설정: 빔 서치, 빔 크기 3, 비중지어 반복 방지.
CoNeTTE
intro
-
자연어 처리의 발전
NLP는 인간-기계 상호작용을 위한 범용 인터페이스로 떠올랐음
인간이 생성한 자유 텍스트는 더 포괄적인 정보를 제공 -
ACC
이미지 캡셔닝 개념이 오디오 처리로 확장되어 AAC가 되었음
AAC 시스템은 인코더-디코더 아키텍처를 사용함 -
CNext-trans 모델
ConvNeXt 아키텍처를 사용하는 완전 합성곱 신경망 오디오 인코더와 트랜스포머 디코더를 포함
AudioCaps(AC)와 Clotho(CL) 데이터셋에서 우수한 성능을 보였음 -
편향 문제
모든 기존 시스템은 최소한 AudioSet(AS)에서 사전 훈련된 오디오 인코더를 사용하는 중
AC 데이터셋이 AS의 훈련 하위 집합에서 선택된 오디오 녹음을 사용하여 편향 문제가 발생함
편향된 인코더와 편향되지 않은 인코더를 비교한 결과, 성능 차이는 상대적으로 작았다. -
데이터셋 결합 실험
따라서 네 개의 AAC 데이터셋(AC, CL, MACS, WavCaps)을 결합하여 훈련을 시도
데이터 결합이 성능을 향상시켰지만, 여전히 단일 타겟 데이터셋에서 훈련된 모델보다 부족했음 -
Task Embedding 도입
디코더 입력에 Task Embedding(TE) 토큰을 도입하여 모델이 각 입력 샘플의 데이터셋 출처를 식별할 수 있도록 했음
TEs가 생성된 캡션의 형식과 내용에 미치는 영향을 분석해봄 -
최종 모델: CoNeTTE
편향되지 않은 CNext-trans와 데이터셋별 Task Embedding을 결합하여 최고의 교차 데이터셋 성능 균형을 달성
만능 모델을 향한 길을 열었다~
관련 연구
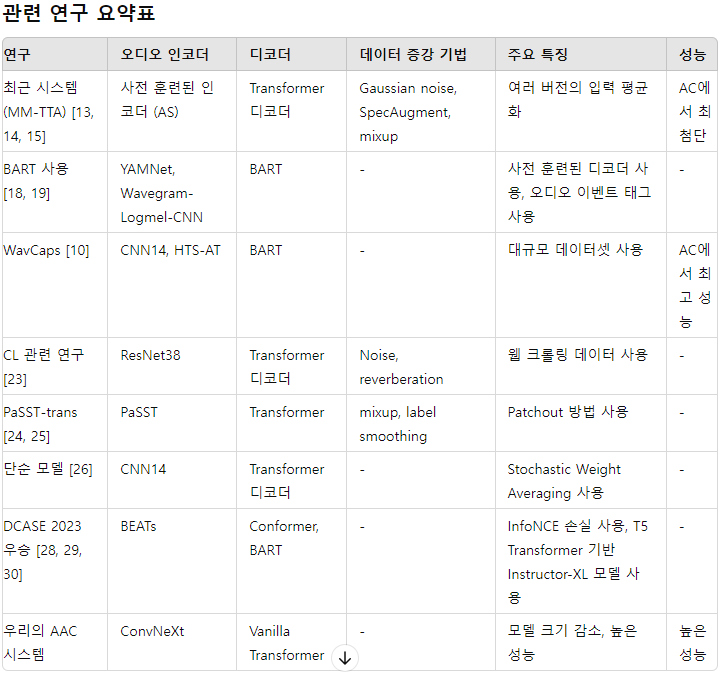
OUR SYSTEM: CNEXT-TRANS
architecture
"CNext-Trans는 표준 인코더-디코더 아키텍처를 사용하는 심층 신경망"
- 인코더는 프레임 단위의 오디오 임베딩을 생성
- 디코더는 이전 단어와 오디오 표현을 바탕으로 다음 단어를 예측
디코더
input: audio embedding + previous words
output: caption
캡션의 구조
: 각 캡션은 문장 시작 토큰()으로 시작하고, 문장 끝 토큰()으로 끝남
훈련
- 교사 강제(Teacher Forcing) 방법을 사용하여 모델을 훈련
- 모델 출력은 다음 단어의 확률
- Cross-Entropy를 통해 실제 값과 비교->loss를 구함
훈련과정
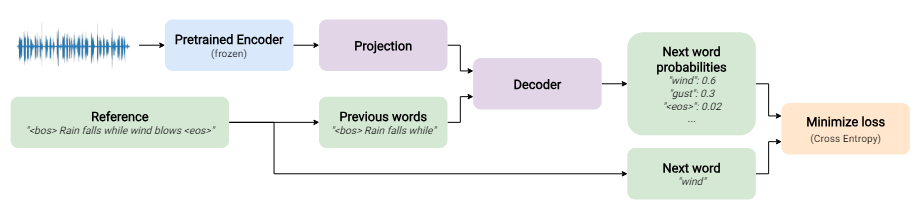
Teacher Forcing method
decoder에 이전의 실제 정답 토큰을 input으로 줌(<->이전에 예측된 토큰을 디코더 input 사용하는 scheduled sampling methods)
추론
- 추론 중에는 디코더의 순방향 메서드를 반복하여 문장의 각 단어를 순차적으로 생성
- 가장 확률이 높은 다음 단어를 이전 단어에 추가하며, EOS 토큰이 나오거나 최대 단어 수에 도달할 때까지 이 과정을 반복
- 이땐 당연히 이전에 예측된 토큰을 input으로 사용
audio encoder:CNN14 and ConvNeXt-Tiny
- 사용된 인코더:
- CNN14
- ConvNeXt-Tiny
두 모델 모두 약 200만 개의 라벨이 지정된 오디오 파일을 포함하는 가장 큰 오디오 태깅 코퍼스인 AudioSet(AS)에서 사전 훈련
- CNN14 아키텍처:
- 여섯 개의 ConvBlock 레이어로 구성된 표준 컨볼루션 기반 네트워크
- 각 ConvBlock은 두 개의 컨볼루션, 배치 정규화, ReLU 활성화, 2차원 평균 풀링으로 구성
- 2048 크기의 프레임 수준 임베딩 생성
- AS 클래스 예측을 위한 풀링, 프로젝션, 분류 레이어 제거
- ConvNeXt 아키텍처:
depthwise sparable convolution
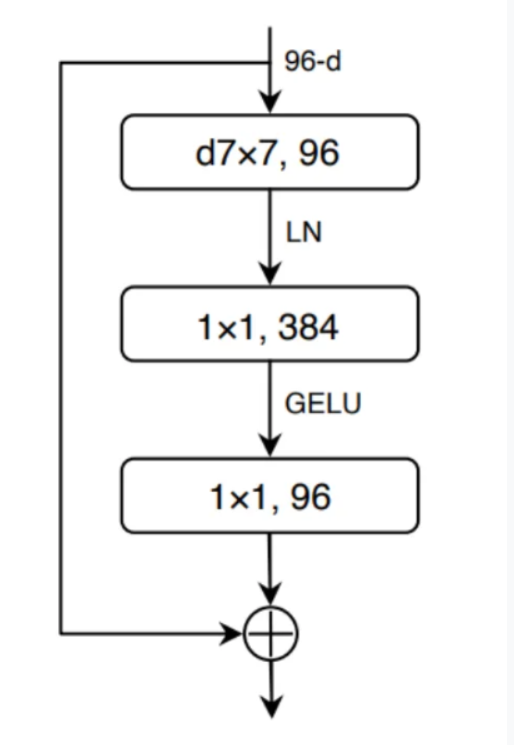
- 훈련 속도를 높이고 과적합을 완화하면서 표준 컨볼루션과 유사한 결과 도출
- residual connection으로 소실되는 그래디언트 문제를 방지하고 기본 residual block에 비해 파라미터 수는 감소
- 추가 네트워크:
- 인코더 위에 작은 네트워크를 추가하여 오디오 프레임 임베딩을 디코더 네트워크와 같은 차원의 하위 공간으로 투영(?)
- 구성 요소: 0.5 드롭아웃, 선형 레이어, ReLU 활성화 함수, 0.5 드롭아웃
- CNN14의 경우 2048 크기, ConvNeXt의 경우 768 크기의 임베딩을 처리하는 선형 레이어
word decoder
- 디코더 네트워크 :
- 구조: 표준 Transformer 디코더 [12]
- 레이어 수: 6개
- 어텐션 헤드 수: 각 레이어당 8개
- 임베딩 크기: 256 (dmodel)
- 레이어 노름 엡실론: 10^-5
- 드롭아웃 확률: 0.2
- 피드포워드 차원 크기: 2048
- 활성화 함수: GELU
- 추론 시 빔 서치(Beam Search):
- 배치별 버전의 빔 서치 알고리즘 구현, 문장 생성 속도 10배 향상 (메모리 사용량 증가)
- 이 알고리즘은 일반적이고 반복적인 내용을 생성하므로, 특정 지표에서 페널티를 받을 수 있음
- 반복 제한:
- 따라서 추론 중 반복을 피하기 위한 제약 조건 도입
(이때, NLTK [39] 패키지의 미리 정의된 스톱워드 리스트는 반복을 허용) - 이 제약 조건으로 “a man speaks while a man speaks”와 같은 반복을 방지
- 그러나, 여전히 "children speak and child speaks"와 같은 유사 단어로 반복적인 내용을 생성할 수 있음
- 추론 중 최소 토큰 수 3개, 최대 토큰 수 20 또는 30으로 제한하여 퇴행적 문장을 피함
과적합 해결
-
AdamW 옵티마이저를 사용
-
data augmentation
"AAC 작업의 경우 많은 오디오 변형(리버브, 배경 소음, 피치 시프트 등)이 타겟 캡션에 설명될 수 있어 데이터 증강의 적용이 특수함"
다음 세 가지 데이터 증강 기법 사용:
2.1 Mixup:
""디코더 입력(오디오 임베딩 및 이전 토큰 임베딩)에 적용""
(타겟 라벨을 섞는 시도는 별다른 개선을 가져오지 않음)
식:
: 오디오 임베딩,
: 해당 라벨
: 현재 배치의 또 다른 오디오 임베딩,
: 해당 라벨
: 고정 하이퍼파라미터,
: 입력 워드 임베딩 레이어,
: 나머지 AAC 디코더 네트워크
2.2 SpecAugment:
""오디오 인코더가 출력한 오디오 프레임 임베딩에 적용""
- 기존 방법: 절대적인 크기의 마스크를 사용하여 특정 영역을 마스킹
- 수정된 방법: 마스크 크기를 축의 비율로 설정하고, 시간 축과 특성 축 모두에 대해 아래 같은 방식으로 두 번 마스킹
2.3 Label Smoothing:수정된 방법의 상세 설명
마스킹 축: 시간 축(Time Axis)과 특성 축(Feature Axis)
마스크 크기: 각 축의 전체 크기(시간 단계 수 또는 임베딩 크기)의 0~10% 사이에서 무작위로 샘플링 - 타겟 캡션에 라벨 스무딩 적용하여 각 토큰의 최대 확률을 제한하고 과적합 감소
DATASETS AND POTENTIAL BIASES
DATASETS
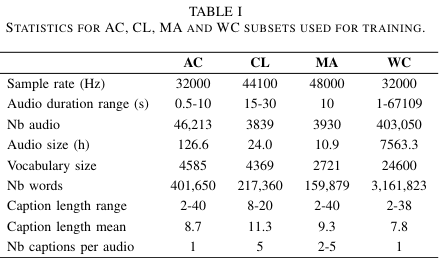
이 연구에서는 AudioCaps(AC), Clotho(CL), Multi-Annotator Captioned Soundscapes(MACS), WavCaps(WC) 데이터셋을 사용하여 자동 오디오 캡셔닝(AAC) 모델을 훈련했습니다. AC는 가장 큰 인간 라벨링 데이터셋으로, 훈련 파일당 하나의 캡션을 갖고 있으며, CL은 FreeSound에서 추출된 작은 데이터셋으로 오디오당 다섯 개의 캡션을 갖고 있습니다. MACS는 다양한 음향 장면에서 소리 이벤트를 기록한 데이터셋이며, WC는 ChatGPT로 생성된 캡션을 포함한 가장 큰 오디오 캡셔닝 데이터셋입니다. 각 데이터셋의 다양한 특성을 반영하여 모델을 훈련하고 평가했습니다.
Potential training data biases in AAC
biases는 AAC와 오디오 태깅(AT) 데이터셋 간 또는 AAC 데이터셋 간의 데이터 소스 중복으로 인해 발생
- 데이터셋 간 중복 비율
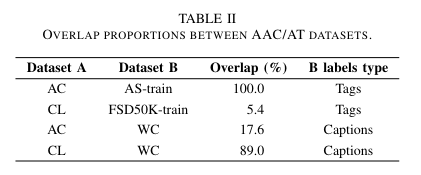
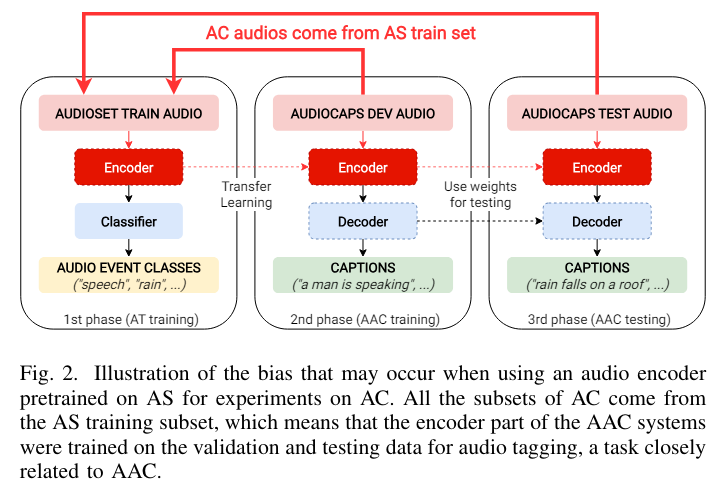
두 가지 편향을 발견
- 첫 번째 편향: 사전 훈련된 오디오 인코더
- AC 전체 데이터셋은 AS 훈련 하위 집합의 일부임
- AS에서 사전 훈련된 인코더는 AC의 모든 오디오 파일(검증 및 테스트 파일 포함)을 이미 본 적이 있는 것
- 인코더는 이미 AC의 audio event를 알고 있음
- 이 편향은 AS와 AC를 포함하는 모든 audio-language task(오디오 캡셔닝 및 오디오 검색)에 해당
- 두 번째 편향: 전체 AAC 시스템에 영향
- WC 데이터셋은 FreeSound와 AS에서의 데이터 소스를 포함함
- 이때, AS는 CL과 AC의 데이터 소스임
- 오디오 인코더 사전 훈련 시 또는 AAC 시스템 훈련 시 이러한 중복 제거 필요
AC와 18%, CL과 89% 중복
- 추가 중복 가능성
- DCASE 챌린지 task 6a에서 사용된 CL 프라이빗 하위 집합과 FSD50K 또는 WC 간 중복 가능성
- 이러한 데이터셋에서 훈련된 모델의 결과가 과대 평가될 수 있음
- 오디오 파일 ID가 제공되지 않아 이러한 잠재적 중복은 불명확
Task Embedding
bias를 없애기 위한 실험들
초기 실험 결과
- AC와 CL에서 외부 데이터 없이 결과를 도출한 후, 더 많은 훈련 데이터를 추가하여 성능을 향상시키려고 시도
- 예상 외로 결과가 저하됨
- 이전 연구 [47]에 따르면, AC와 CL의 소리 이벤트와 글쓰기 스타일이 서로 다른 도메인을 형성하여, 두 데이터셋을 함께 훈련할 때 모델 성능에 영향을 미칠 수 있음
기존 접근 방식
- 많은 AAC 연구 [24, 10, 48]에서는 훈련을 두 단계로 나눠 외부 데이터를 처리:
- 모든 사용 가능한 캡셔닝 데이터셋으로 훈련
- 대상 데이터셋(AC 또는 CL)에서만 미세 조정(fine-tuning)
새로운 접근 방식: Task Embedding
- 모델에 힌트를 제공하여 여러 캡셔닝 데이터셋을 활용할 수 있는 단일 AAC 시스템을 목표로 함
- 오디오 데이터셋 소스에 따라 디코더에 Task Embedding(TE) 태그를 입력으로 도입 (예: <bos_ac>, <bos_cl>)
- 이 태그는 문장 시작 시 사용되는 토큰을 대체하고, 모델이 원하는 글쓰기 스타일에 더 가까운 출력을 생성할 수 있게 함
- 이 방법은 DCASE 챌린지 2023 [49] 참여 시 처음 사용되어, 3위를 차지한 시스템에서 사용됨
- 이번 연구에서는 더 많은 데이터셋과 TE 태그를 사용하여 이 접근 방식을 확장
데이터셋 추가 및 처리
- 모든 공개된 AAC 데이터셋(AC, CL, MA, WC)을 추가하여 테스트
- AC와 WC, CL과 WC 간의 중복 데이터를 제거하여 편향을 피함
- CL 테스트 오디오 파일의 최대 길이인 30초 이상인 WC의 오디오 파일 제거
- WC에는 네 가지 다른 소스가 포함되어 있어 각 소스에 대한 Task Embedding 태그를 추가하여 총 7개의 태스크 생성
- 모든 오디오 캡셔닝 데이터셋을 결합하여 316,122개의 훈련 오디오 파일 생성
데이터 균형 조정 - 대상 데이터셋(AC 또는 CL)과 데이터 균형을 맞춤
- CL의 경우: CL의 3,840개 파일과 다른 데이터셋에서 무작위로 선택한 3,840개 파일을 사용하여 에포크당 7,680개의 훈련 파일 사용
- AC의 경우: AC의 46,213개 파일과 다른 데이터셋에서 같은 수의 파일을 사용하여 에포크당 92,426개의 파일로 훈련
- 다른 균형 조정 전략을 테스트했으나, 이 접근 방식이 가장 좋은 결과를 도출
