AAC
Automated audio captioning (AAC)
개념
:오디오 콘텐츠를 텍스트(caption)로 설명하는 것, 소리를 인지하고, 설명할 수 있어야 함
speech-to-text와 차이
단순히 음성을 텍스트로 변환하는 것이 아니라, 다양한 오디오 신호를 분석하여 이를 텍스트로 설명하는 것
- 모델링 범위
- 개념: 소리의 일반적인 성격을 설명할 수 있습니다.
예: "흐릿한 소리". - 물리적 특성: 소리를 내는 객체나 환경의 특성을 설명합니다.
예: "큰 자동차 소리", "작고 빈 방에서 사람들 이야기하는 소리". - 고차원 지식: 특정 상황이나 사건을 설명합니다.
예: "시계가 세 번 울린다".
Figure 1: An example of an automated audio captioning system and process.
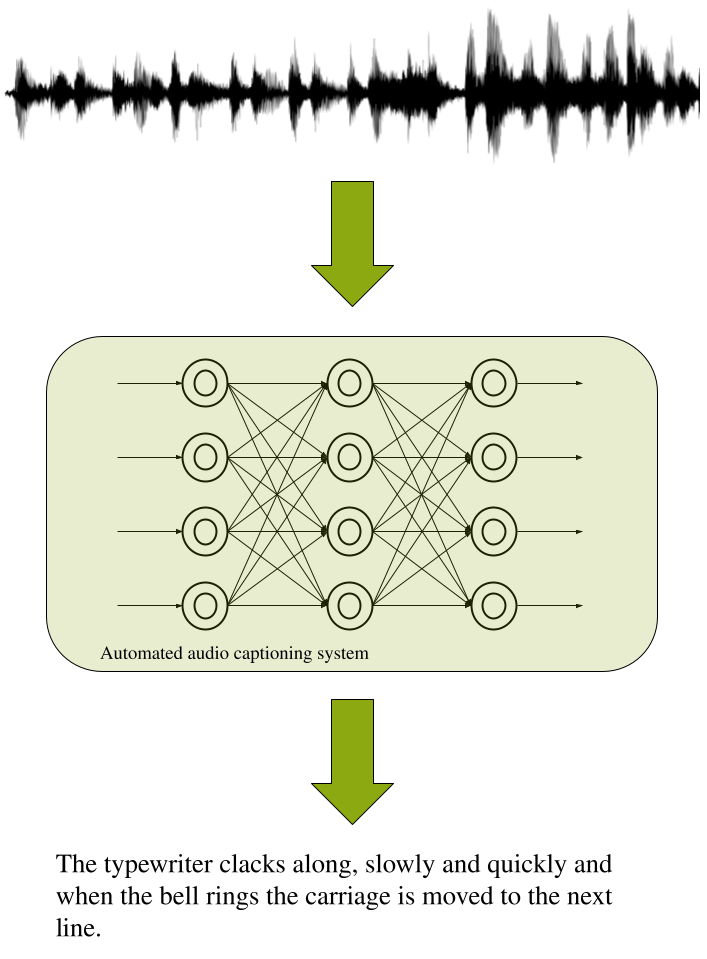
AAC의 구성요소
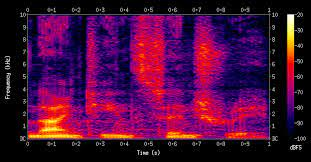
1. Data form : Mel-Spectrogram
우리가 귀로 들을 수 있는 음성 신호는 여러가지 소리가 합쳐진 것입니다.
이를 분석하려면 어떤 신호들이 결합된 것인지 알아야 합니다.

-> 그래서 '주파수' 대역에서 신호의 특성을 파악하려고 했으며
이 때 사용되는 연산이 바로 Fourier Transform, 푸리에 변환입니다.
(입력받은 신호를 푸리에 변환을 이용해 주파수 별로 분류)
푸리에 변환 수식
- 시간 도메인: 신호가 시간에 따라 어떻게 변하는지를 나타냅니다.
주파수 도메인: 신호가 다양한 주파수 성분으로 어떻게 구성되는지를 나타냅니다.- 주어진 시간 도메인 신호 x(t)를 주파수 도메인 신호 X(f)로 변환합니다.
- 여기서 X(f)는 주파수 f에서의 신호 성분을 나타냅니다.
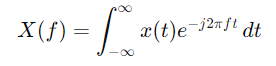
그런데 이렇게 주파수 대역에서 신호를 분석하려고 하니까 어느 시간대에 해당 주파수의 신호의 크기가 얼마나 되는지를 알 수 없습니다. 소리를 분석할 때 소리가 들리는 시간에 관한 정보도 중요한데 말이죠.
그래서, 우리는 '일정한 시간대별로' 푸리에 변환을 적용하는 Short-time Fourier transform (STFT) 이라는 걸 사용합니다.
STFT 수식
- x(τ)는 원래 신호입니다.
- w(τ−t)는 시간 창 함수로, 일반적으로 짧은 기간 동안의 신호를 선택하는 데 사용됩니다.
- t는 시간 이동 변수로, 시간 창을 신호 전체에 걸쳐 이동시키면서 변환을 적용합니다.
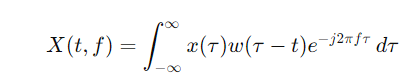
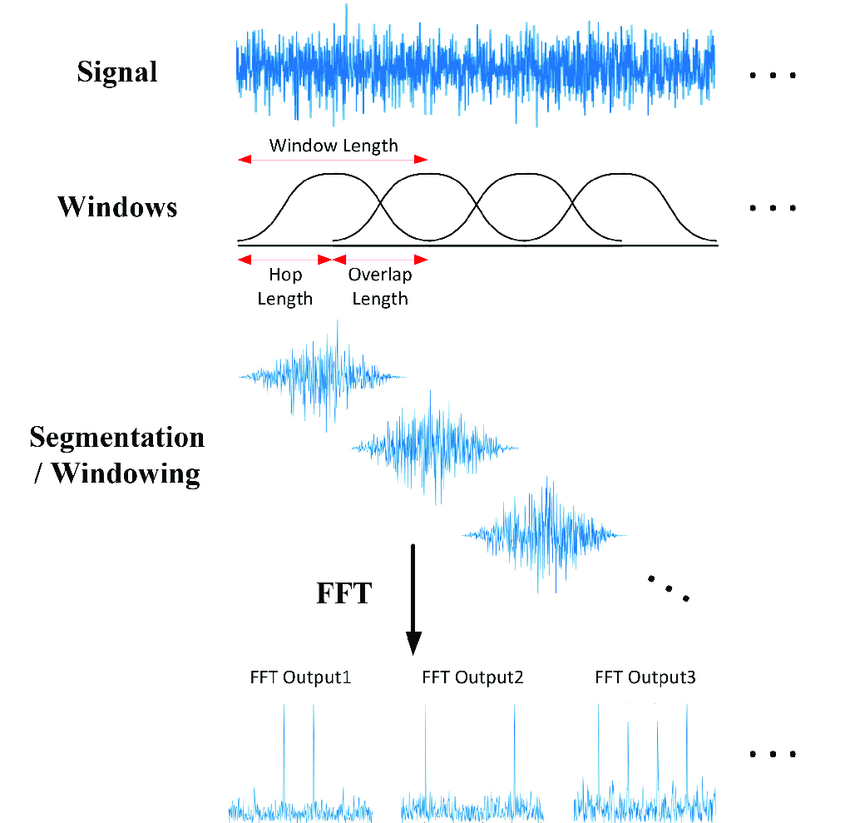
STFT의 단계
1. 신호 분할: 원래 신호를 여러 겹치는 창(window)으로 분할합니다.
2. 창 함수 적용: 각 창에 대해 창 함수를 적용하여 해당 부분 신호를 얻습니다.
3. 푸리에 변환 적용: 각 창에 대해 푸리에 변환을 적용하여 주파수 성분을 계산합니다.
- 시간-주파수 도메인 표현: 모든 창에 대해 계산된 '시간대' 정보와 '주파수' 정보를 하나의 데이터 형식으로 표현할 수 있을겁니다. 이를 Spectrogram이라고 합니다.
- Spectrogram은 사람이 들을 수 있는 주파수 대역을 고려하지 않았습니다. 사람이 들을 수 있는 주파수 대역은 한정적인데 말이죠.
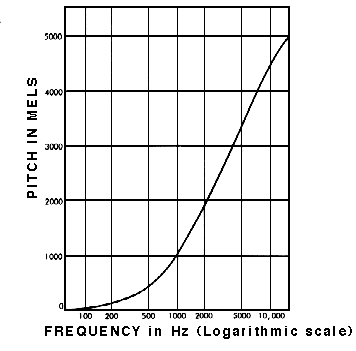
그래서 사람이 들을 수 있는 범위에 맞게 Log Scaling을 수행한 것이 바로 Mel-Spectrogram입니다.
- Log Scaling
- 이 비선형 관계는 인간의 청각적 인식 특성을 반영.
즉, 같은 주파수 차이라도 저주파수 대역 내에서는 더 크게 느껴지고, 고주파수 대역에서는 비슷하게 느껴짐- Mel-Spectrogram
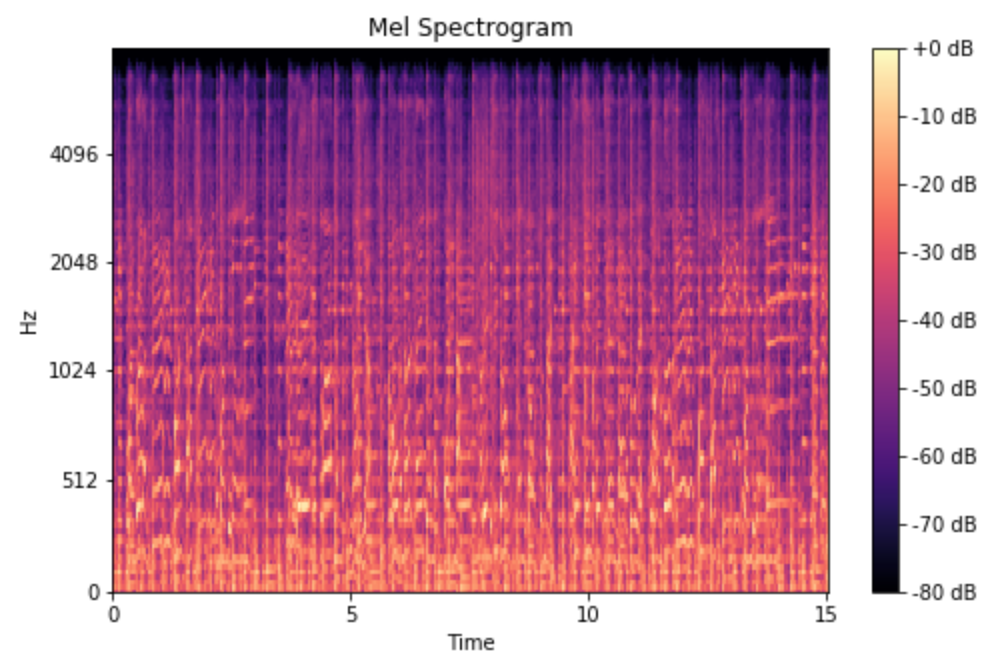
정리하자면, Mel-Spectrogram을 입력 데이터로 많이 사용
2.Model Architecture
[1] Encoder – Decoder 구조
: AAC는 encoder-decoder 구조를 기본 구조로 사용하고 있습니다. 입력 받은 데이터를 특정 크기의 feature vector로 encode 한 뒤, 이를 가지고 caption으로 decode하는 구조인 것이죠. (다른 구조의 네트워크를 사용한 실험은 아직 없음)
[2] Encoder의 구조가 다양하다
: 주로 CNN 등 이미지의 feature map을 생성하는 네트워크를 Encoder로 사용하는 Image Captioning 네트워크와는 달리 AAC는 GRU, LSTM 등 자연어 처리에 주로 쓰이는 네트워크를 사용하기도 하면서 CNN을 encoder로 사용하기도 하였습니다.
가장 처음 모델
CNN을 인코더로 사용한 예시
모두 audio sample의 mel-spetrogram을 입력 데이터로 받는다
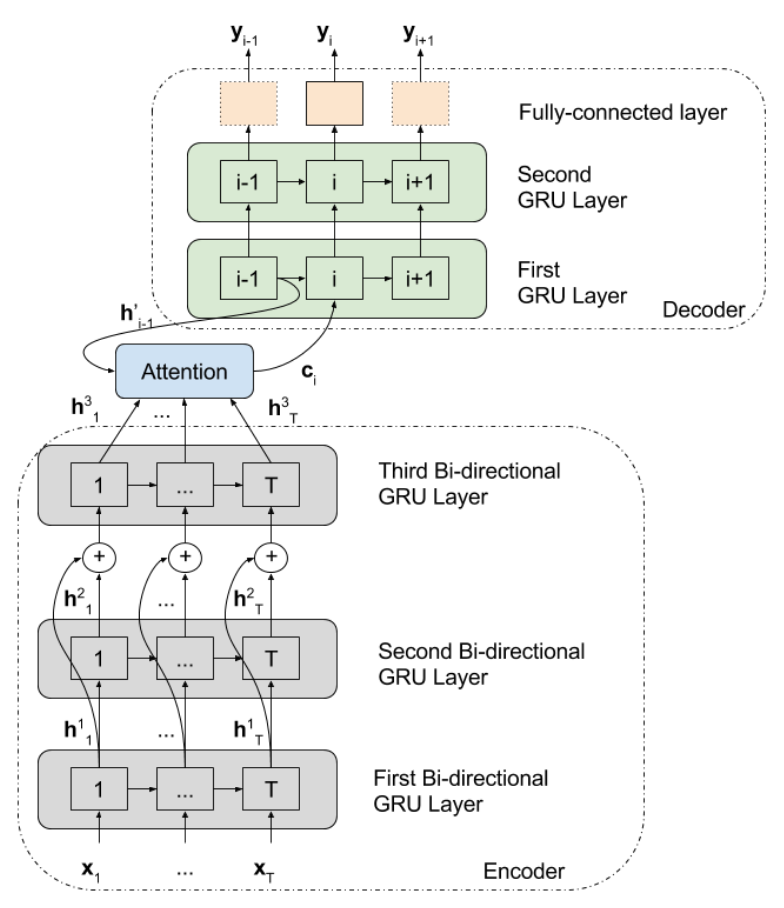
[3] Decoder의 구조는 자연어 처리 네트워크의 Decoder를 사용
: Decoder는 caption 생성을 담당하기 때문에 자연어 처리를 수행할 때 사용되는 Decoder를 사용합니다.
맨 처음 AAC를 위해 제안된 논문에서는 2개의 GRU를 지닌 비교적 간단한 네트워크를 사용했으나 , 점차 더 복잡한 네트워크를 제안하였고 최근엔 나온 AAC 관련 논문에서는 Decoder로 자연어 처리에서 탁월한 성능을 보여준 Attention mechanism 기반 네트워크를 많이 사용합니다.
[4] 부가적인 정보를 사용
: audio clip 외에도 부가적인 정보를 네트워크에 입력해 성능 향상을 이뤄내기도 합니니다. 대표적인 예로 'keyword'가 있습니다. 허나 keyword를 사용할 때 상승하는 계산량 증가에 비해 성능 향상이 미미한데다 '사전학습 된' 키워드 추출 네트워크를 사용하면 성능향상이 있을 '수' 있다는 불확실한 점이 있어 많은 연구가 필요하다고 볼 수 있겠습니다.
3. Dataset
AAC 데이터셋의 구조는 [음성 데이터, caption] 조합
주로 Clotho, Audiocaps를 학습, 평가용 데이터셋으로 많이 사용
Clotho v2 데이터셋
-
오디오 샘플:
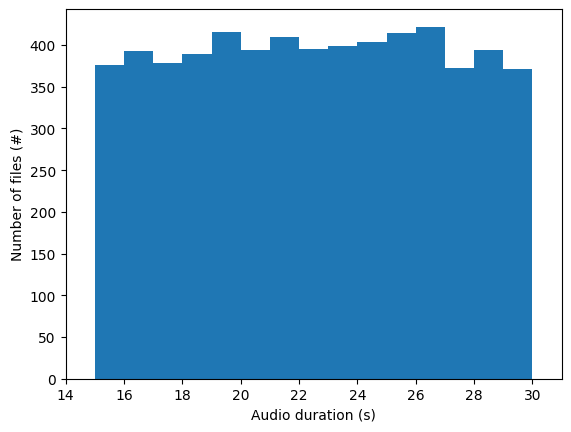
- 길이: 각 오디오 샘플은 15초에서 30초 사이입니다.
- 수량: 총 6972개의 오디오 샘플이 포함되어 있습니다.
이 중 4981개는 Clotho v1에서, 1991개는 Clotho v2에서 추가 - 정규화 및 정리: 모든 파일은 정규화되었으며, 앞뒤의 침묵 부분이 제거
- 제외 조건: Freesound에서 사운드 효과, 음악 또는 음성을 나타내는 태그가 없는 샘플만 사용->자연스러운 환경소리만 사용
- 오디오 샘플의 다양성(자연, 동물 사람, 기계, 장치)
Figure 2: Audio duration distribution for Clotho dataset.
-
캡션:
-
길이: 각 캡션은 8단어에서 20단어 사이입니다.
-
수량: 각 오디오 샘플당 5개의 캡션이 제공되며, 전체적으로 34,860개의 캡션이 있습니다.
-
특징: 캡션은 오디오 샘플의 내용과 상황을 다양하게 설명합니다.
3단계 프레임워크를 통해 수집
- 오디오 설명:
- 초기 캡션 수집: 각 오디오 클립마다 5개의 초기 캡션을 서로 다른 주석자들로부터 수집
- 설명 편집:
- 문법 오류 수정 및 재작성: 초기 캡션의 문법 오류를 수정하고, 문법적으로 올바른 캡션은 다양한 표현을 위해 다시 작성 후 추가
- 설명 점수 매기기:
- 정확성 및 유창성 평가: 세 명의 주석자에 의해 정확성과 유창성에 따라 점수가 매겨짐
- 최종 캡션 선택: 점수가 합산된 후, 정확도 점수와 유창성 점수에 따라 정렬되어 상위 5개의 캡션이 최종적으로 선택
+) 후처리
1. 수동 정리: 최종 캡션에서 아포스트로피 제거, 복합 단어 일관성 유지, 음성 내용 설명 구문 제거, 명명된 개체 대체 등이 이루어집니다.
2. 8단어 미만 캡션 처리: 캡션이 8단어 미만일 경우, 낮은 점수의 캡션 중에서 적절한 것을 찾아 재작성하거나, 불가능할 경우 해당 오디오 파일을 데이터셋에서 제거합니다.
3. 고유 단어 대체: 유일하게 등장하는 단어는 대체하여, 데이터셋의 일관성을 유지합니다.
4. 생성된 caption은 tokenize됨1. 아포스트로피 제거 (Removing Apostrophes) 예시) 제거 전: "It's raining and John's car is parked outside." 제거 후: "It is raining and John is car is parked outside." 2. 복합 단어 일관성 유지 (Ensuring Consistency in Compound Words) 예시) 일관성 없는 경우: "playground", "play-ground", "play ground" 일관성 있게 수정: "playground" 3. 음성 내용 설명 구문 제거 (Removing Phrases Describing Speech Content) "오디오 캡셔닝의 목표가 소리 전체를 설명하는 것이지, 단순히 음성을 텍스트로 전사하는 것이 아니므로 이러한 구문을 제거" 예시) 제거 전: "A person says 'Hello, how are you?'" 제거 후: "A person is speaking." 4. 명명된 개체 대체 (Replacing Named Entities) 예시) 대체 전: "John is playing the piano in New York." 대체 후: "A person is playing the piano in a city." 5. tokenize 예시) 전: "A dog is barking loudly in the park." 후: [1, 2, 3, 4, 5, 6, 7, 8] - 오디오 설명:
-
-
단어 분포:
단어는 모든 분할 간에 비례적으로 분포되며, 특정 분할에만 나타나는 단어가 없도록 설계- 각 분할 간 단어 분포
개발: 55% 검증: 15% 평가: 15% 테스트: 15% - 분할 과정
- 고유 단어 세트 구성: 각 오디오 클립의 캡션에서 고유 단어 세트를 구성
- 단어 빈도 도출: 전체 데이터셋의 단어 모음을 형성하여 특정 단어의 빈도를 도출
- 다중 라벨 층화: 오디오 파일의 고유 단어를 클래스(class)로 사용하여 다중 라벨 층화를 적용
-> 1. 모델의 훈련, 검증, 평가 과정에서 일관성을 유지하고, 2. 데이터 불균형 문제를 해결하며, 3. 공정한 평가 환경을 조성하고, 4. 데이터셋의 신뢰성을 확보하기 위함
이러한 설정은 모델이 다양한 상황에서 일반화된 성능을 발휘하도록 도와줌 - 각 분할 간 단어 분포
