Wide & deep
Memorization, Generalization
1) Memorization
-
Memorization은 기존의 특성들을 사용하여 새로운 특성을 만들어 학습하는 것을 의미합니다.
-
각각의 특성들의 동시 출현을 바탕으로 새로운 특성을 생성하여 상호작용을 '암기'
-
일반적으로 동시출현(co-occurrence)빈도를 표현하는 Cross-product로 생성이 가능합니다.
-
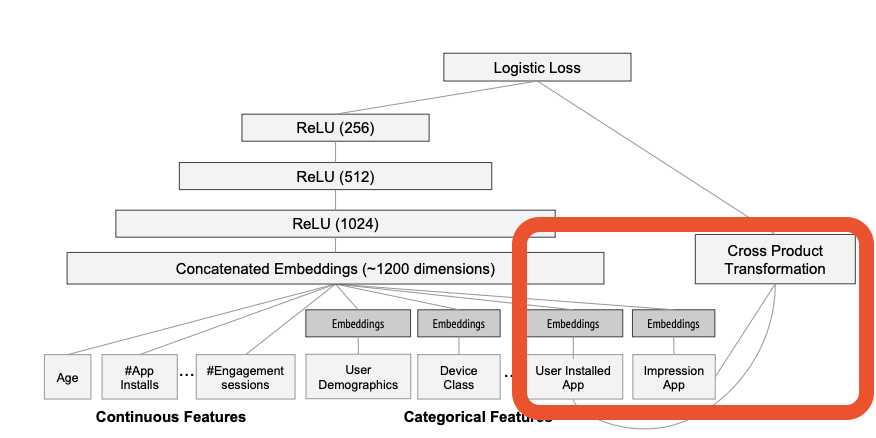
Cross-product Tranformation은 One-hot vector 사이의 AND 연산(cross product)을 통해 동시출현 여부를 의미하는 새로운 Binary feature를 생성
-
동시출현이 평가(Rating)에 끼친 영향에 대한 설명력을 제공하며, 매우 Topical하고 상품에 직접적으로 관련된 정보들을 추천하도록 도와줍니다.
-
하지만 반대로 등장하지 않은 조합에 대한 설명력이 떨어지며, 특성간의 Cross-product transformation이라는 무거운 feature engineering을 필요로 한다는 단점이 존재합니다.
2) Generalization
- Generalization은 Memorization과 반대로, 새로운 특성 조합에 대한 일반화된 예측을 가능하게 하는 방법
- 새로 표현된 Dense한 특성벡터는 서로 내적이 가능하며, 따라서 별도의 Cross-product transformation을 필요로 하지 않습니다.
- -> 과거에 관측되지 않은 특성의 조합에 대한 일반화된 예측을 제공
- 추천시스템에서 Generalization은 추천의 다양성을 증가시키며, 비주류 아이템을 거의 추천하지 않는 Long-tail problem을 극복하도록 도와줄 수 있습니다.
- 하지만 실제로 존재할수 없는 관계에 대해서도 과도한 일반화 결과를 내놓을 가능성이 존재
Wide & deep의 가장 큰 Contribution은 Memorization과 Generalization을 동시에 수행할 수 있다는 점
1.Wide & deep
Model architecture
Wide part와 Deep part로 나누어져 있으며, 각각 Memorization과 Generalization을 담당하고 있습니다.
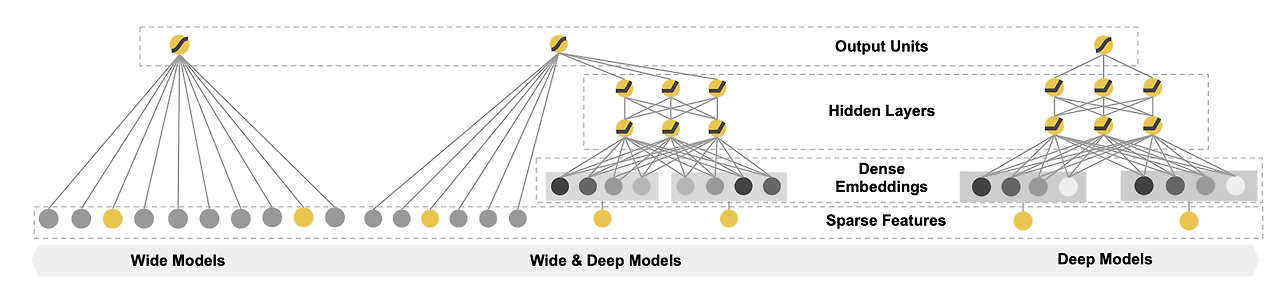
1) Wide component
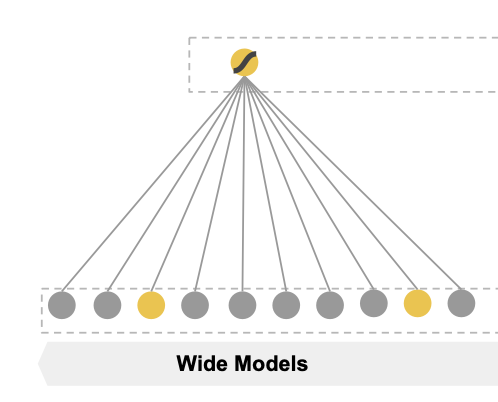
Wide는 Memorization을 담당하는 generalized linear model을 의미
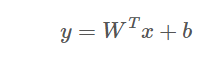
x는 개별적인 raw 특성과 cross-product transformation으로 생성된 새로운 특성을 함께 포함
Wide part는 새로운 특성을 기존의 raw특성에 concatenate하여 모델을 학습합니다. 이러한 작업은 generalized linear model 자체에도 비 선형성을 추가해 줍니다.
2) deep component
wide & deep 모델의 Deep는 feed-forward neural network로서 모델의 Generalization을 담당합니다.
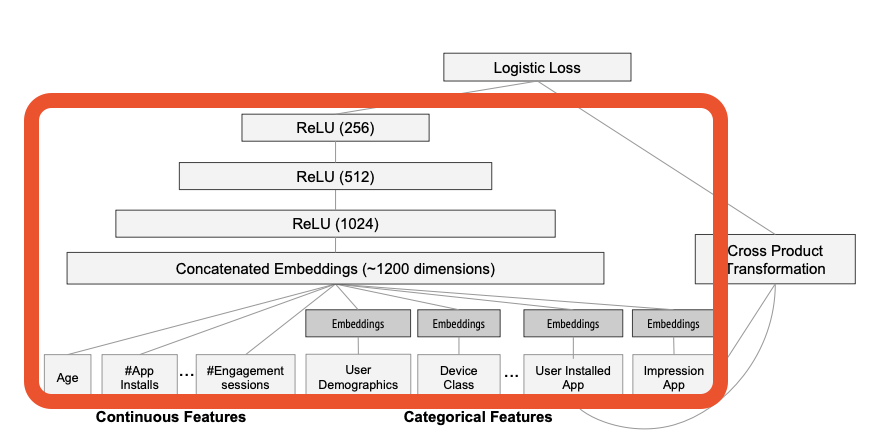
먼저 categorical feature는 embedding layer를 통해 저차원의 특성으로 변환되며, Continuous feature와 concatenate되어 심층 신경망의 입력이 됩니다. 이 때, 임베딩 층은 랜덤으로 초기화되며 모델 학습과정에서 함께 학습됩니다.
또한 각각의 hidden layer에서는 다음과 같은 일반적인 신경망 연산이 진행됩니다.(논문에선 relu 사용)
3)Joint Training of Wide & Deep

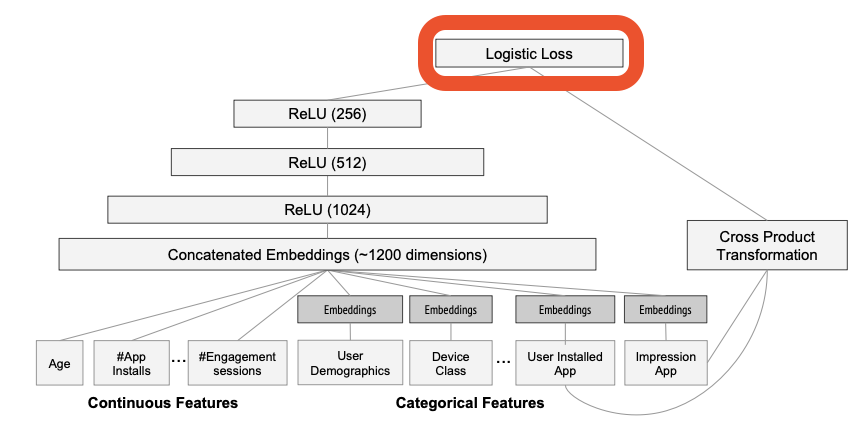
WIde & deep 모델은 output layer에서 Wide part와 Deep part의 output을 가중합(weighted sum)합니다.
따라서 모델은 일반적인 logistic regression을 사용하여 동시에 학습(joint training)이 가능
Wide & deep은 output layer를 통하여 동시에 역전파가 진행됩니다. 따라서 이는 단순한 앙상블과는 다르다고 할 수 있습니다. (각자의 결과가 역전파시 서로 영향을 줌)
Wide part는 FTRL알고리즘이 Optimizer로 사용되었으며, Deep part는 AdaGrad가 사용(Adam으로 바꿔보기)
Xavier 초기화
신경망의 가중치를 초기화하는 한 방법입니다. 이는 가중치의 분산이 특정한 값에 맞도록 설정하여, 학습 초기에 신경망이 각 레이어에서 적절한 신호를 전달할 수 있도록 돕습니다. 이를 통해 학습이 안정되고, 기울기 소실(gradient vanishing) 문제를 완화할 수 있습니다.
자기 실험
문제가 되는 방향으로 출력하게 만들어서 오히려 그 문제를 없애도록 만드는 것
시도
- wide part crossed_cols 늘려보기
- deep part 더 깊게
- wide, deep optimizer 바꿔보기
- deep part를 GRU로 교체
