Conformer
intro
배경
자동 음성 인식(ASR)
- Transformer: long-range global context modeling에 특화
- CNN: local context를 잘 포착
CNN에서의 global context 파악을 위해 ContextNet에선 Squeeze-and-Excitation가 사용되기도 함
=> Conformer: convolution + Transformer
: 위치별 로컬 특징을 학습하고, 내용 기반 글로벌 상호작용을 사용할 수 있음
- 결합 방식: self attention과 convolution을 한 쌍의 피드 포워드 모듈 사이에 배치하는 새로운 결합 방식을 도입
Wu는 자기 어텐션과 컨볼루션을 각각 2 braches로 나누고, 그 출력들을 결합하는 멀티 브랜치 아키텍처를 제안
2.conformer encoder
Conformer 인코더 구조
모델 아키텍처
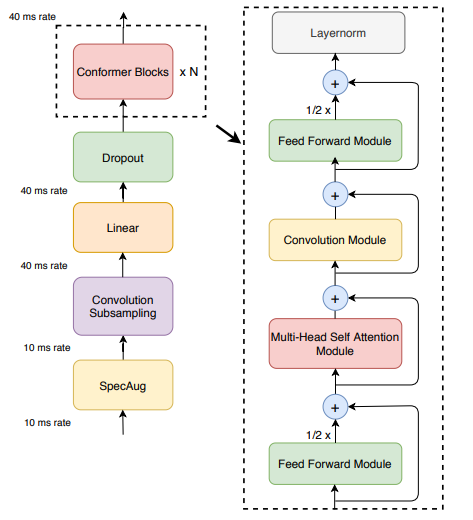
Convolution subsampling(=다운샘플링) layer-> 다수의 Confomer block
conformer 블록 구성:
1. a feed-forward module
2. a self-attention module
3. a convolution module
4. a second feed-forward module
오디오 데이터 -> 음성 신호에 대한 특징 벡터를 반환
2.1. Multi-Headed Self-Attention Module:

- 드롭아웃과 pre-norm residual units 사용
- layer norm
: 각 오디오 하나 당 평균 분산을 구해 정규화
-> 어텐션 계산이 더 안정적이고 효과적으로 이루어지도록 함 - Multi-Headed Self-Attention
- Relative Positional Encoding
: 시퀀스 내의 절대적 위치가 아닌 상대적 거리를 인코딩
-> 상대적 거리 정보는 사인파와 코사인파를 사용하여 인코딩pre-norm residual units
기존:
1.주요 연산(예: 선형 변환, 비선형 활성화, 어텐션 등)
->2.layer norm
->3.residual connection (=x+정규화된 주요 연산 결과)
pre-norm residual units:
1.layer norm
-> 2.주요 연산(예: 선형 변환, 비선형 활성화, 어텐션 등)
-> 3.residual connection(=x+정규화X 주요 연산 결과)
장점) 경사 소실 제어, 깊은 모델에서 더 안정적 학습, 빠른 수렴
2.2. Convolution Module

- Pointwise Convolution:
- expansion facttor = 2 :채널 수 두배 확장
- GLU activation function:
- Depthwise Convolution
- Batchnorm
- Swish Activation
- 다시 Pointwise Convolution으로 채널 복구
2.3. Feed Forward Module

- 드롭아웃과 pre-norm residual units 사용
- 두 개의 선형 변환
- 1번 linear layer에선 채널 수 네배 확장
- 2번 linear layer에선 다시 복구
- Swish Activation
2.4. Conformer Block
- 두 개의 Feed Forward Module 사이 Multi-Headed Self-Attention 모듈과 Convolution 모듈이 배치
- 이때 피드 포워드(FFN) 모듈에서 half-step residual weights를 사용( Macaron-Net 참고 )
- 두 번째 피드 포워드 모듈 뒤에는 최종 레이어 정규화 레이어가 배치
- 계산식
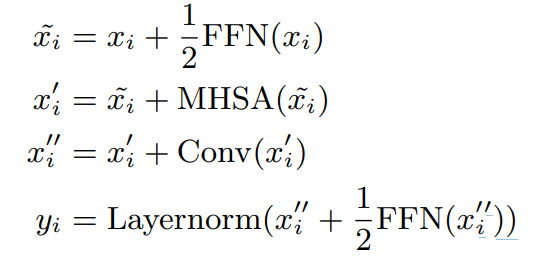
Experients
###3.1. Data
1. 데이터셋:
- LibriSpeech:
- 음성 데이터: 970시간의 라벨이 된 음성 데이터.
- 텍스트 데이터: 언어 모델 구축을 위한 800M 단어 토큰 텍스트 코퍼스.
- 특징 추출:
- filterbanks features:
- 음성 신호의 주파수 성분을 분석하여 얻는 특징
- 푸리에 변환 포함
- 25ms 윈도우에서 10ms 간격으로 계산.
- 80채널 필터뱅크 특징 추출.
- 데이터 증강:
- SpecAugment:
- 스펙트로그램(spectrogram)에 데이터 증강(data augmentation)을 적용하는 기법
- 주파수 마스킹->마스크 파라미터: F = 27.
- 시간 마스킹-> 10개의 시간 마스크 사용.
- 최대 시간 마스크 비율: pS = 0.05.
- 시간 마스크의 최대 크기는 발화 길이의 pS 배로 설정.
Results on LibriSpeech
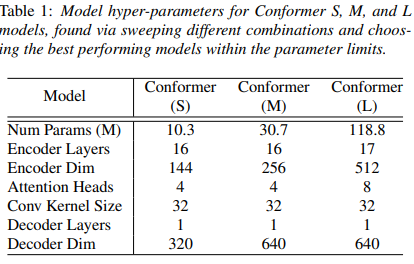
hyperparameter
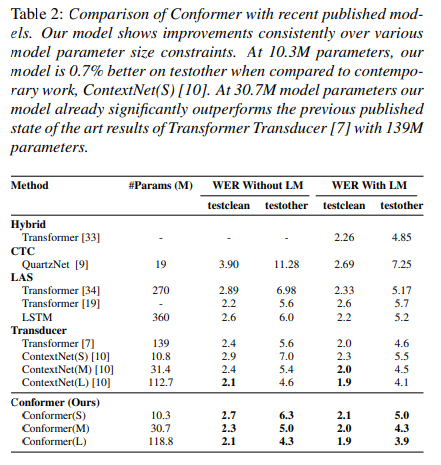
Comparison of Conformer with recent published models
SWISH 활성화: Conformer 모델의 수렴 속도를 빠르게 함
attention head 수 : 16개까지 제일 좋았음(모든 레이어에서 동일하게 했을때 , 늘릴수록 좋아지긴 함)
커널 사이즈 = 32일때 제일 좋았음
결론
결론:
Conformer 아키텍처는 CNN과 Transformer의 장점을 결합하여 효율적인 음성 인식 모델을 제안
->음성 신호에 대한 특징 벡터를 반환
*"10ms", "40ms" 등의 표시는 음성 신호 처리에서 사용된 윈도우와 스트라이드 크기
