BEATs
- input: audio data
- output : sementic embedded audio feature
intro
배경
- 자기지도 학습(SSL)의 성공
- 음성(speech) 및 오디오 처리에서 자기 지도 학습(SSL)이 큰 성과를 거두었음
- 특히 Wav2vec 2.0, HuBERT, WavLM 등은 다양한 음성 처리 작업에서 뛰어난 성능을 발휘
- 오디오 처리의 도전 과제
- 오디오는 다양한 환경적 소리(인간 목소리, 자연 소리, 음악 등)를 포함하고 있어 음성보다 더 복잡한 모델링이 필요.
- 기존 오디오 SSL 모델들은 주로 acoustic feature reconstruction loss 을 사용해 사전 학습을 진행. (버트처럼 복원작업으로 사전학습)
- discrete label prediction을 제안
- 고수준 의미 학습: 불연속 라벨 예측을 통해 모델이 고수준의 의미를 학습할 수 있음. 이는 인간이 소리를 인식하는 방식과 유사.
- 모델링 효율성: 불연속 라벨 예측은 불필요한 세부 정보 대신 의미가 풍부한 토큰을 학습하게 하여, 모델의 효율성을 높임.
- 통합 가능성: 언어, 비전, 음성, 오디오와 같은 다양한 모달리티에서 동일한 사전 학습 방법을 사용할 수 있는 가능성을 열어줌.
acoustic feature
: 멜스펙토그램 같이 오디오에서 나타나는 다양한 특성들(피치, 포만트 등)
고수준 의미 학습
사람: 특정 소리를 추출하고 의미에 맞게 군집화 시키면서 이해
ex) 다른 상황, 크기 등 의 개 짖는 소리이더라도, 개 짖는 소리로 똑같이 파악할 수 있음
-> SSL 모델도 사전학습시 discrete labeling으로 사람이 하는 것처럼 이해시킬 수 있다!
- point)
reconstruction 자체가 그 의미엔 관심없고 그저 자주 나오는 태펀에 맞춰 복원하기 때문에 고차원적 이해는 하지 못함.
반면, discrete label을 주고 예측시킨다는 건 그 의미를 주고 외우도록 시킨다는 것. 결국 SSL모델이 의미파악을 할 수 있는 것과 같아짐
- 문제
- 오디오 신호의 연속성:
오디오 신호는 연속적이기 때문에 언어처럼 split해서 의미별 토큰화하기 어려움 - speech 외 다양한 비음성 신호가 포함 되어 있어 기존 speech tokenizer를 그대로 쓸 수 없음
- 오디오 신호의 연속성:
=> BEATs 제안!
- 전체 프레임 워크
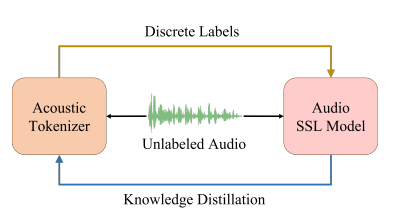
: asoustic tokenizer와 audio SSL model을 반복적인 사전 학습을 통해 최적화하는 프레임워크. - 학습 과정: asoustic tokenizer가 생성한 discrete label로 audio SSL model을 학습하고, 이 모델이 다시 teacher 역할을 하여 토크나이저를 개선.(knowledge distilation)
knowledge distilation
: (원래)큰 모델의 성능을 작은 모델에서도 구현하기 위한 방법
기존 데이터로 학습된 큰 모델(teacher model)의 output(클래스별 확률값)을 soft label로, 기존 데이터의 label을 hard label로 두고 두개의 label을 학습(loss)도 두 개
->큰 모델의 output을 따라감(=성능을 따라감)
BEATs
3.1 Iterative Audio Pre-training
-
BEATs 프레임워크는 음향 토크나이저와 오디오 SSL 모델을 반복적으로 학습하여 최적화함.
- 음향 토크나이저는 라벨이 없는 오디오에서 불연속 라벨을 생성하고, 이를 통해 오디오 SSL 모델을 학습함.
- SSL 모델은 교사 모델로 사용되어, 새로운 음향 토크나이저를 지식 증류로 학습함. 이 과정은 수렴할 때까지 반복됨.
-
세부 과정:
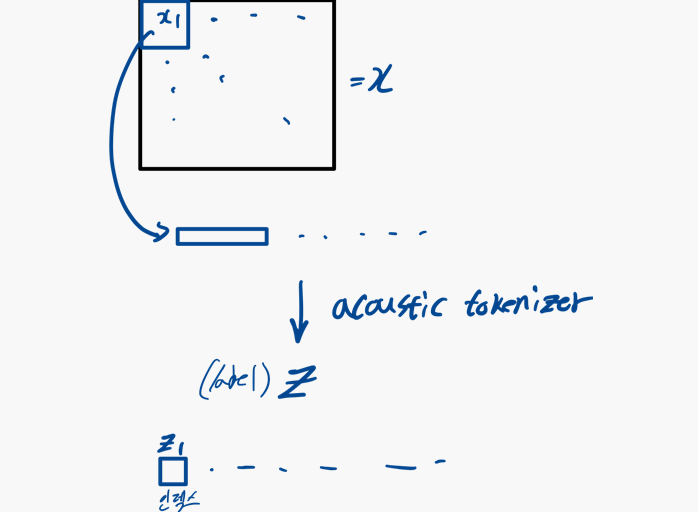
- 입력 데이터 처리:
- 오디오 클립이 입력으로 주어지면, 먼저 해당 오디오의 acoustic feature를 추출.
- 이 acoustic feature는 일정한 크기의 패치로 분할되어,
- 패치 시퀀스 로 평탄화
- 오디오 SSL 모델 학습:
- 음향 토크나이저는 패치 시퀀스 를 패치 수준의 discrete label 로 양자화
- 이 불연속 라벨은 마스크된 예측 목표로 사용되어, 오디오 SSL 모델이 학습됨
- 음향 토크나이저 학습:
- 학습된 오디오 SSL 모델을 사용하여 패치 시퀀스 를 인코딩하고, 출력 시퀀스 를 knowledge distilation의 soft label로 사용
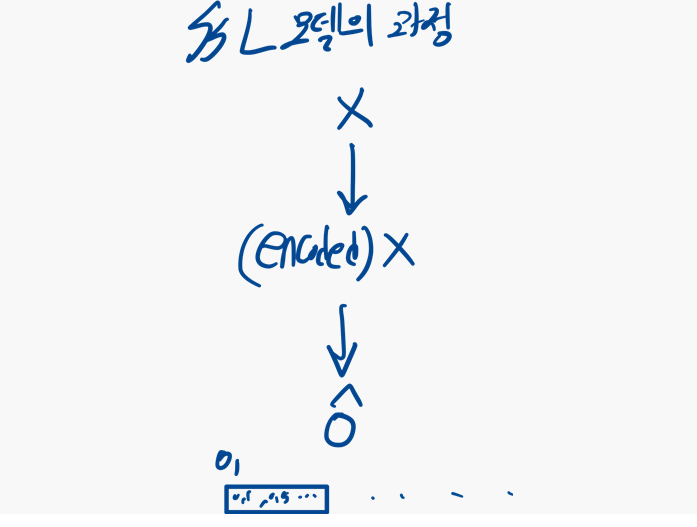
=> 이 과정을 통해 음향 토크나이저는 교사 모델로부터 의미가 풍부한 지식 (semeantic rich information) 을 얻어, 더욱 정교한 discrete label을 생성할 수 있게 됩니다.
-
teacher 모델의 선택:
- 음향 토크나이저를 학습하는 데 사용되는 교사 모델로는 사전 학습된 오디오 SSL 모델이나 미세 조정된 오디오 SSL 모델 둘다 사용가능
- 미세 조정된 모델은 자기 지도 학습과 지도 학습 모두를 통해 의미론적 지식을 학습하므로, 더욱 효과적인 교사 모델이 될 수 있습니다.
-
반복적 학습의 효과:
모델이 수렴할 때까지 반복
의미가 풍부한 지식 (semeantic rich information)얻어 학습가능
결국 semeantic 정보가 풍부한 인코딩을 위한 거임!
음향 특징 추출
멜스펙트로그램은 음향 특징 추출에서 매우 널리 사용되는 방법이지만, MFCC, 크로마 특징, 스펙트럼 특징, 그리고 원시 파형 등 다양한 방법이 사용될 수 있습니다. 각각의 방법은 특정한 응용 분야에 더 적합할 수 있으며, 모델의 목표에 따라 적절한 특징 추출 방법을 선택하는 것이 중요합니다.
3.2 acoustic tokenizer
- 목적:
- 각 반복에서 continuous 오디오 데이터를 discrete label로 변환
- 첫번쨰 반복과 이후 반복에서 사용하는 tokenizer가 달라짐
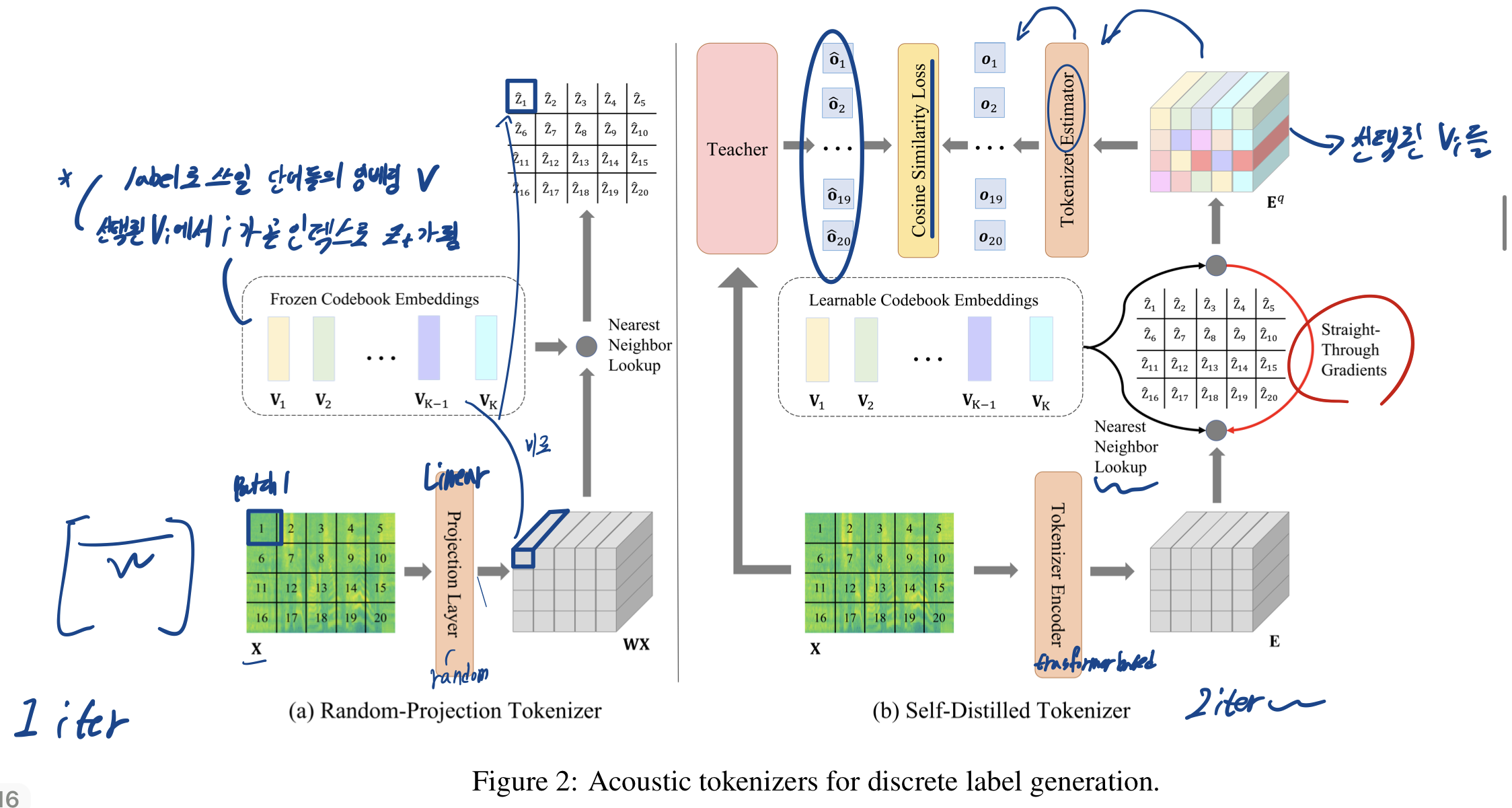
3.2.1 Cold Start: Random-Projection Tokenizer
- 목적:첫번째 반복에서 교사 모델(SSL model)이 없을 때 첫 discrete label을 생성하는데 사용
- 구조: random initialized linear projection layer & codebook embeddings
- 과정
- 가 linear projection layer를 지나며 가 됨
- 각 벡터 는 중에서 가장 가까운 이웃 벡터를 찾아 t번째 오디오 patch의 discrete label ""가 됨
(= 최소가 되는 값)
->가지고 SSL이 학습되고나면, 1 iter 끝
3.2.2 iteration: Self-Distilled Tokenizer
-
목적:
두번째 iter부터 사전 학습된/미세 조정된 오디오 SSL 모델에서 knowledge distilation을 사용해 더 정교한 불연속 라벨을 생성 -
과정:
-
을 Tokenizer Encoder(12-layer transformer layer)에 넣음
-> 를 얻음
-
각 에 대해서 이웃 벡터 를 구함
: normalization -> codebook 활용성을 높여줌 -
(선택된 들)을 Tokenizer Estimatoer(3-layer Transformer estimator)에 넣음
-> 를 얻음
-> SSL의 Output 을 보고 따라가도록 학습
-
-
loss:
와 사이 cos 유사도 & 와 사이 유클리드 거리(차이의 제곱)
sg[⋅]: 정지 그라디언트 연산자
????? 다시 공부
D : pre-training dataset
cos(.,.) : 코사인 유사도 -
추론 시: Tokenizer Estimator를 버리고, 사전 학습된 토크나이저 인코더와 코드북 임베딩을 사용 -> 오디오 입력을 discrete label로 변환
3.3 SSL Model
3.3.1 Backbone
백본으로 ViT사용
- 과정:
- linear projection layer:
-> - Transformer encoder layer:
->
= encoded patch representation
transformer encoder에 쓰인 다양한 기술들
- Convolution-based Relative Position Embedding Layer
: 시퀀스 내에서 토큰 간(임베딩된 패치들 간)의 상대적 거리를 컨볼루션 연산을 통해 인코딩하여, Transformer가 위치 정보를 더 잘 이해하도록 도와줌- Gated Relative Position Bias
- 어텐션 매커니즘에서 사용.
- 쿼리-키 쌍에 대해 Relative Position Bias를 추가하여 상대적 위치 정보를 포함
(예를 들어, 시퀀스에서 두 토큰 간의 거리가 가까울수록 더 큰 가중치를 부여하고, 멀수록 가중치를 낮추는 식. 'QK 행렬에서 생각')- Gated->게이트 메커니즘은 신경망 내에서 특정 정보의 흐름을 제어하거나 조절하는 데 사용
이로인해 위치 정보가 중요한 경우에만 이 정보를 강조가능- DeepNorm
: 깊은 Transformer 모델에서 각 레이어의 입력과 출력을 적절히 정규화- pretraining 과 fine-tuning overview
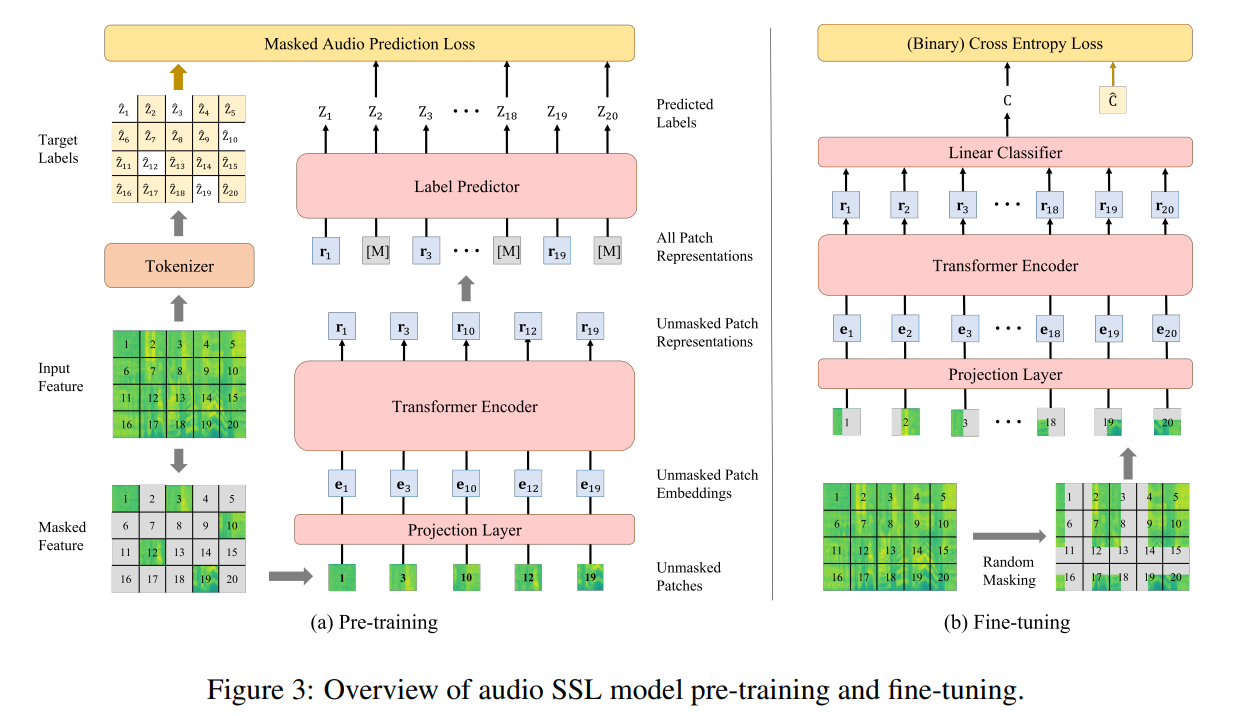
3.3.2 pre-Training
Masked Audio Modeling(MAM) 방법 사용
-
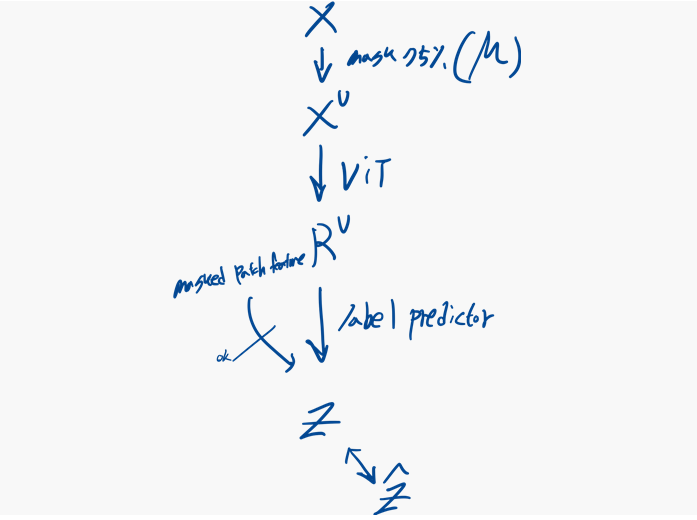
과정:
1) 에서 75%를 무작위로 masking
마스킹 위치:
2) 마스킹 되지 않은 패치 시퀀스 를 ViT에 넣음
->를 얻음
= encoded patch representation
3)(마스킹되지 않은 패치 표현과 마스킹된 패치 특징의 조합)을 label prediction에 넣음
-> discrete label 을 얻음만 넣을때 더 훈련속도를 높이고, 다운 스트림 작업 전반에 성능향상을 줄 수 있음
-
손실:
SSL에서 나온 와 들을 비교cross entropy loss
-
SSL pre-training 과정 그림
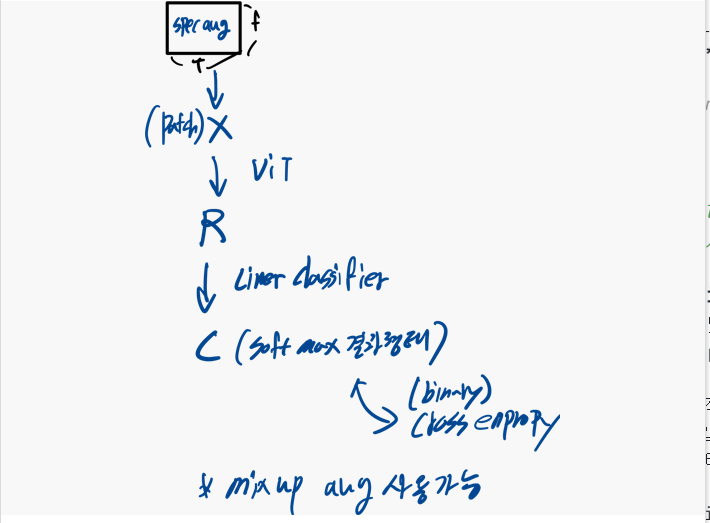
3.3.2 Fine-Tuning
- label predictor 제거 및 task별 선형 분류기 추가
- random masking 대신 spec-augmentation 적용
- 과정:
- spec-augmentation 적용 뒤 패치 시퀀스 로 split하고 flat
- 를 ViT 인코더에 입력하고, 인코딩된 표현 을 얻음
- 선형 분류기를 통해 카테고리 별 확률 을 음
소프트맥스 연산, 평균 풀링 계층, 선형 투영
- single label classification tasks->cross entropy loss
- the multi-label classification tasks->binary cross entropy loss
- SSL fine-training 과정 그림
Experiment
datasets
- pretraining:
AudioSet 데이터셋의 전체 훈련 세트를 사용 - 6개의 다운스트림 작업으로 평가:
3개의 오디오 분류 작업(AS-2M, AS-20K, ESC-50)과 3개의 음성 분류 작업(KS1, KS2, ER)

Implementation Details
-
백본 네트워크:
- 구성: BEATS 모델은 12개의 Transformer 인코더 층, 768차원의 히든 스테이트, 8개의 어텐션 헤드로 구성되며, 약 9000만 개의 파라미터를 가지고 있습니다.
- 모델 크기: 이전 SOTA 모델과 비교 가능하도록 모델 크기를 비슷하게 유지하여 공정한 비교를 가능하게 합니다.
-
음향 특징 추출:
- 샘플링 속도: 모든 원시 오디오 파형의 샘플링 속도를 16,000으로 변환합니다.
- Mel-filter bank 특징: 25ms의 Povey 윈도우를 사용해 128차원 Mel-filter bank 특징을 추출하며, 10ms마다 윈도우가 이동합니다.
- 정규화: 특징은 평균 0, 표준편차 0.5로 정규화됩니다.
- 패치 시퀀스: 음향 특징을 16×16 패치로 나눈 후, 이를 BEATS 모델의 입력으로 사용할 수 있도록 패치 시퀀스로 평탄화합니다.
-
모델 및 토크나이저 학습:
- 사전 학습 과정: BEATS 모델은 AS-2M 데이터셋에서 세 번 반복하여 사전 학습됩니다. 이를 BEATSiter1, BEATSiter2, BEATSiter3, BEATSiter3+로 명명합니다.
- BEATSiter1: 무작위 투영 토크나이저로 생성된 불연속 라벨을 사용해 첫 번째 반복을 수행합니다.
- BEATSiter2 및 BEATSiter3: BEATSiter1과 BEATSiter2를 교사 모델로 하여, 자기 증류 토크나이저를 사용해 두 번째와 세 번째 반복을 수행합니다.
- BEATSiter3+: BEATSiter3+는 BEATSiter2의 지도 학습 버전을 교사로 사용하여 사전 학습이 수행되며, 이 모델은 분류 로짓을 추정하도록 학습됩니다. 이 모델은 사전 학습 중에도 지도 데이터를 활용하여 성능을 향상시킵니다.
-
학습 설정:
- 모든 BEATS 모델은 40만 스텝 동안 배치 크기 5.6K 초로 사전 학습되며, 최대 학습률은 5e-4입니다.
- 코드북은 256차원의 1024개 임베딩으로 구성되어 있습니다.
- 자기 증류 토크나이저는 교사 모델에 따라 배치 크기와 학습률이 다르며, 40만 스텝 동안 학습됩니다.
=>전반적으로, BEATS는 모든 여섯 개의 오디오 및 음성 분류 작업에서 최고의 성능을 달성
우리가 쓸 것
: R (=encoded patch representation)
reconstruction X, discrete labels prediction
R: 소리 별 의미정보(acoustic tokenizer를 통해 생성된)를 담고 있음
=> 오디오의 임베딩 정보를 담은 embeddings를 얻기 위한것!
