LAVT(Language-Aware Vision Transformer)
LAVT
intro
- Task: Referring image segmentation
- 입력: 텍스트, 이미지
- 출력: 마스크
=> 픽셀 단위의 마스크를 예측하는 것이 목표
- 기존의 단일 모달리티 image segmentation
:고정된 카테고리 조건을 기반으로 분류- Referring image segmentation
: 인간 자연 언어의 훨씬 더 풍부한 어휘와 구문적 다양성을 다루어야 함. 주어진 텍스트 조건에 관련된 시각적 특징을 활용
Referring image segmentation Task에 대한 기존 연구들
: 각각의 인코더 네트워크에서 vision과 language feature를 독립적으로 추출한 다음, 이를 크로스 모달 디코더와 함께 융합하여 예측을 수행
- 크로스 모달 디코더
: 비전과 언어 두 가지 모달리티의 특징을 융합하여 출력하도록 만든 디코더- 융합 전략에는 반복 상호작용, 크로스 모달 어텐션, 다중 모달 그래프 추론, 언어 구조 기반 컨텍스트 모델링 등이 포함
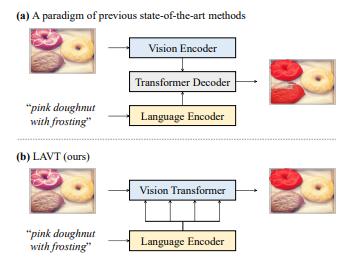
-> 문제: 디코더만 언어와 이미지 특징을 다루면서 트랜스포머 레이어를 효과적으로 활용해 다중 모달 컨텍스트를 온전히 찾아내기 힘들어짐
-> new: 인코더에서부터 언어적 특징과 시각적 특징을 함께 임베딩하는 vision encoder를 활용하자
새로운 접근 방식 LAVT
- LAVT는 시각적 인코딩 단계에서 언어적 특징과 시각적 특징을 초기 융합함
- 이는 트랜스포머 인코더의 상관관계 모델링 능력을 활용하여 다중 모달 컨텍스트를 효과적으로 발굴하도록 함
- 복잡한 크로스 모달 디코더를 필요로 하지 않으며, 가벼운 마스크 예측기를 통해 정확한 분할 결과를 얻을 수 있음
METHOD
3.1 Language aware visual encoding
LAVT pipe line

-
language features 추출 BERT 사용
(는 각각 채널 수와 단어 수) -
vision feature 추출과 vision-language 융합을 네 단계로 구성된 비전 트랜스포머 레이어 계층을 통해 수행
동안 , , 를 통해 3단계에 걸쳐 multi modal feature를 생성하고 결합함: stack of transformer encoder layer(=Swin Transformer),
: 다중 모달 특징 융합 모듈 (->PWAM)
: learnable gating unit (->language pathway)multi modal feature를 생성하고 결합 3단계
- 트랜스포머 레이어 는 이전 단계의 특징을 입력을 받아 (vision feature) 출력
- 다중 모달 특징 융합 모듈 을 통해 와 결합해 (다중 모달 feature set)를 생성
- 는 learnable gating unit 을 통해 가중치를 부여 받고 에 더해져 언어 정보가 업데이트 된 Vision feature인 가 만들어짐
3.2 Pixel-word attention module(PWAM)
-> "으로 어떻게 와 결합하는가"
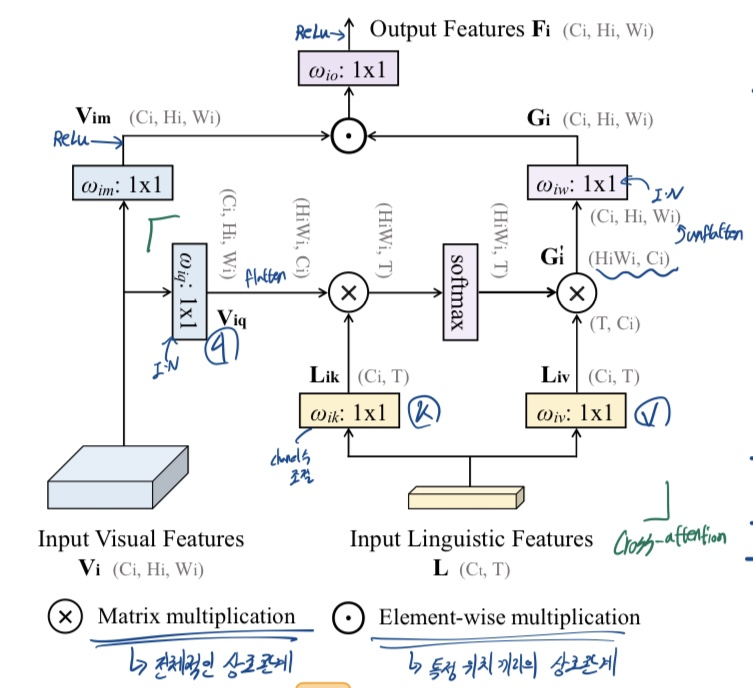
- 와 사이 cross attention 과정
- flatten (C,H,W) -> (HxW,C)
- unflatten (HxW,C) -> (C,H,W)
- 와 에 instance normalization 적용
(https://velog.io/@tjdcjffff/Normalization-trend) - 과 에서 1x1 conv 뒤에 ReLU 적용
3.3 Language pathway
"를 바로 이용 하지 않고 suplement로 이용"
->언어 정보가 이미지 정보를 overwelming 할 수 있어서

- 실험 결과, tanh 최종 비선형성을 사용하는 게이트가 가장 효과적임을 발견
- 처럼 더하는 게 replacement or concatenation보다 효과적이었음
3.4. Segmentation
- [ ; ]: 채널 차원을 따라 특징을 연결.
- : 양선형 보간법을 통한 업샘플링.
- : 배치 정규화와 ReLU 비선형성을 연결한 두 개의 3×3 합성곱으로 구성된 projection 함수.
- 최종 투영: 최종 특징 맵 은 1×1 합성곱을 통해 두 개의 클래스 점수 맵으로 투영.
양선형 보간법(bilinear interpolation)
1. 기존 픽셀 위치 결정: 임의의 픽셀 위치가 기존 픽셀 그리드의 어느 위치에 속하는지 결정합니다.
2. 가중치 계산: 픽셀 위치와 가장 가까운 네 개의 기존 픽셀 간의 거리를 기반으로 가중치를 계산합니다.
3. 보간 수행: 네 개의 기존 픽셀 값과 가중치를 사용하여 새로운 픽셀 값을 계산합니다.
3.5 Implementation
-
프레임워크:
PyTorch [46]에서 구현.
HuggingFace의 Transformer 라이브러리 [57]에서 BERT 구현 사용. -
초기화:
- LAVT의 트랜스포머 레이어: Swin Transformer [35]의 ImageNet22K [11]에서 사전 학습된 분류 가중치로 초기화.
- 언어 인코더: 12개의 레이어와 768의 숨김 크기를 가진 기본 BERT 모델 [55]로 초기화.
-
가중치 초기화
- 나머지 가중치는 무작위로 초기화.
- 는 512로 설정.
-
최적화:
- 교차 엔트로피 손실로 최적화.
- AdamW [38] 옵티마이저 사용: weight decay 0.01, 초기 학습률 0.00005, 다항식 학습률 감소.
- 배치 크기 32로 40 에포크 동안 학습.
-
학습 및 추론:
- 각 객체를 한 번씩 정확히 한 에포크에서 순회하며, 무작위로 지시 텍스트 표현을 샘플링.
- 이미지는 480×480으로 크기 조정.
- 데이터 증강 기법은 적용되지 않음.
- 추론 시, 점수 맵의 채널 차원을 따라 argmax를 사용하여 예측 수행.
->채널 별 결과를 앙상블하는 식의 효과일듯
