
(1) AWS Lambda란 무엇인가
AWS Lambda는 AWS에서 제공하는 서버리스 컴퓨팅 서비스로 사용자가 서버를 프로비저닝하거나 관리하지 않고도 코드를 실행할 수 있게 한다. Lambda는 이벤트 기반으로 동작하며, 특정 이벤트가 발생하면 자동으로 코드를 실행한다.
Lambda는 다양한 AWS 서비스(S3, DynamoDB, API Gateway 등)와 협력하여 이벤트 기반 애플리케이션을 쉽게 구축할 수 있다. 이러한 연계를 통해 데이터 처리, API 백엔드, 자동화 작업 등 다양한 작업을 효율적으로 수행할 수 있다.
-
주요 특징
- 서버리스 환경 : 서버를 설정하거나 관리하지 않아도 된다. AWS가 필요한 리소스를 자동으로 할당하고 관리한다.
- 이벤트 기반 실행 : S3 버킷의 파일 업로드, DynamoDB의 데이터 변경, API Gateway 호출, 클라우드 서비스의 이벤트 등 다양한 이벤트를 트리거로 설정할 수 있다.
- 자동 확장 : Lambda는 요청에 따라 자동으로 확장된다. 즉, 요청이 많을수록 더 많은 리소스를 자동으로 할당하며, 사용자가 별도로 설정하지 않아도 동시 실행이 가능하다.
- 과금 방식 : 실행 시간(밀리초 단위)과 실행 횟수에 기반해 비용이 청구된다. 사용하지 않을 때는 비용이 발생하지 않는다.
- 다양한 언어 지원 : Python, Java, Node.js, Go, Ruby, C# 등 다양한 프로그래밍 언어를 지원한다.
-
주요 사용 사례
- 백엔드 로직 처리 : API Gateway와 연동하여 RESTful API 백엔드를 구성할 때 사용된다.
- 데이터 처리 : S3에 업로드된 데이터를 처리하거나, DynamoDB에서 데이터 변경 이벤트를 처리한다.
- 자동화된 작업 : 주기적으로 실행해야 하는 배치 작업이나 클라우드 리소스의 상태를 모니터링하는 데 활용할 수 있다.
- 실시간 데이터 스트림 처리 : Amazon Kinesis와 연동하여 실시간 데이터를 처리한다.
-
작동 방식
- Lambda 함수 작성 : 특정 트리거(예: S3 업로드, DynamoDB 변경) 발생 시 실행될 코드를 작성하여 업로드한다.
- 트리거 설정 :Lambda를 실행할 이벤트 소스를 정의한다. (ex. S3 버킷의 파일 업로드)
- 코드 실행 : 이벤트가 발생하면 Lambda가 자동으로 코드를 실행하고 필요한 리소스를 동적으로 할당한다.
(1-1) AWS Lambda 함수
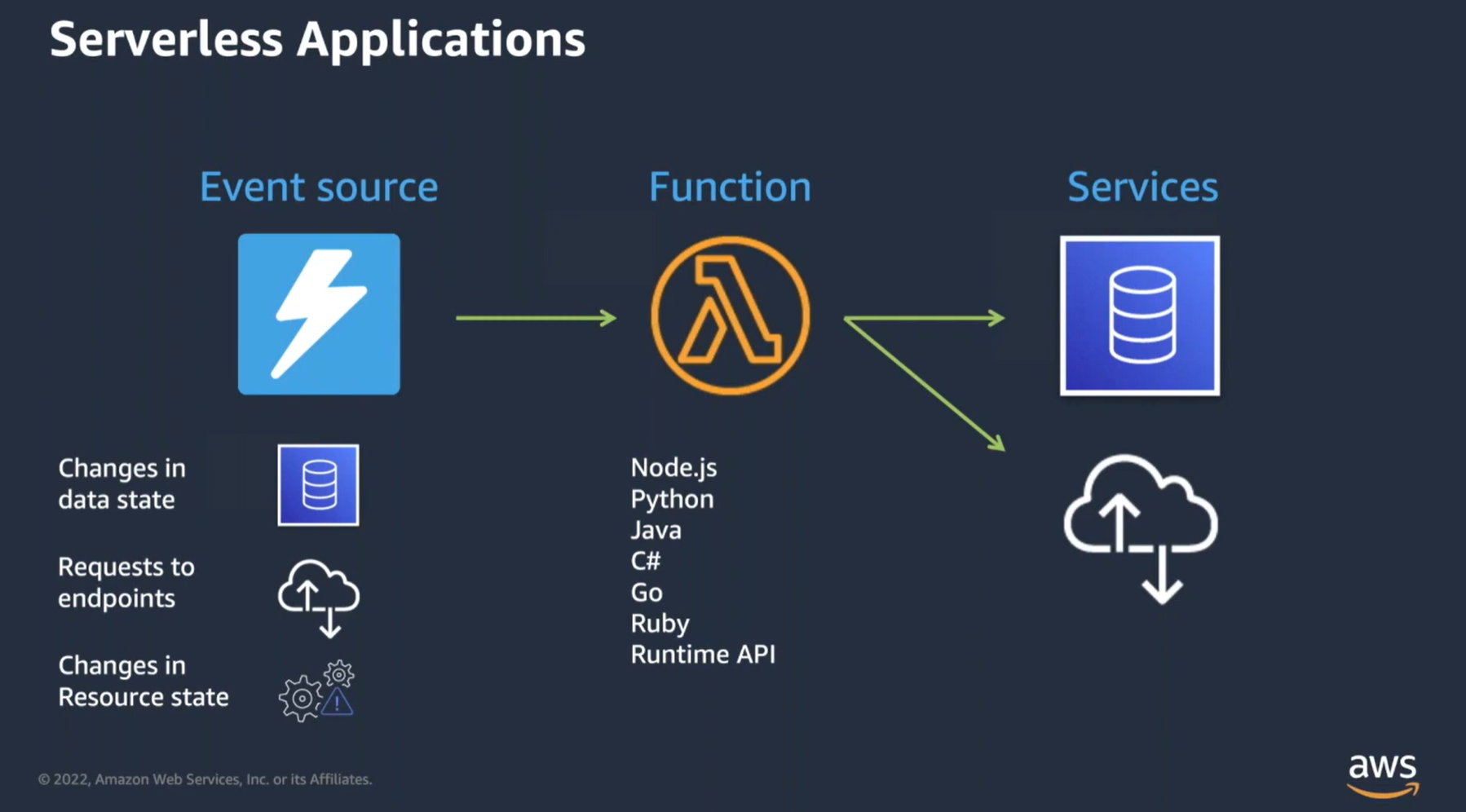
AWS Lambda 함수는 다양한 이벤트 소스(Event Source)에 의해 호출된다. Lambda는 다른 AWS 서비스(S3, DynamoDB, API Gateway 등)와의 긴밀한 연계를 통해 이벤트 기반 애플리케이션의 강력한 운영 환경을 제공한다.
- 이벤트 소스 예시 :
- 데이터 변경 : DynamoDB의 데이터 업데이트
- 엔드포인트 요청 : API Gateway에서의 요청
- 리소스 상태 변경 : S3에 파일 업로드 등
(1-2) Lambda 함수의 구조와 특징
- 핸들러 함수 (Handler Function) : Lambda 호출 시 실행되는 함수로, 각 Lambda 함수는 반드시 하나의 핸들러 함수를 정의해야 한다.
- 핸들러 함수 구성요소 :
- Event 객체 : Lambda 호출 시 전달되는 데이터
- Context 객체 : Lambda 실행 환경과 관련된 정보

(1-3) Lambda 함수의 동작 방식
-
단일 실행 환경
- 하나의 Lambda 함수는 하나의 실행 환경 내에서 실행된다.
- 실행 환경은 요청에 따라 초기화되며, 반복 호출 시 재사용될 수 있다.

-
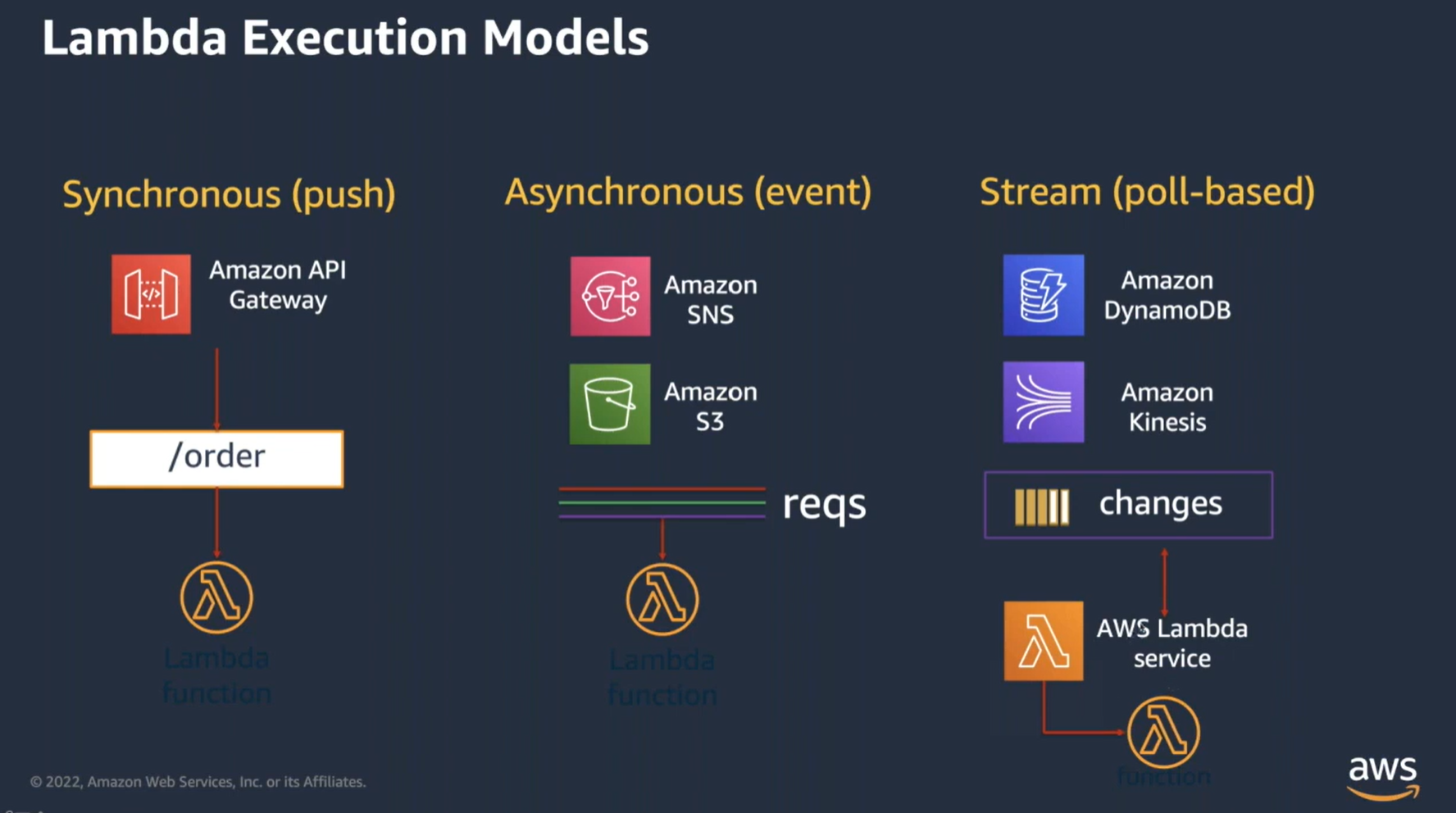
실행 모델
- 동기 호출(Synchronous Invocation) : 호출 즉시 결과를 반환한다.
- 비동기 호출(Asynchronous Invocation) : 호출 후 결과를 기다리지 않는다.
- 스트림 기반 호출(Stream-based Invocation) : 데이터 스트림을 실시간으로 처리한다.
(1-5) Lambda 개발환경 구성
Lambda 함수는 AWS가 제공하는 개발 환경 구성 툴을 통해 효율적으로 작성 및 배포할 수 있다. 개발 환경 구성은 코드 작성, 테스트, 디버깅, 배포를 포괄한다. 
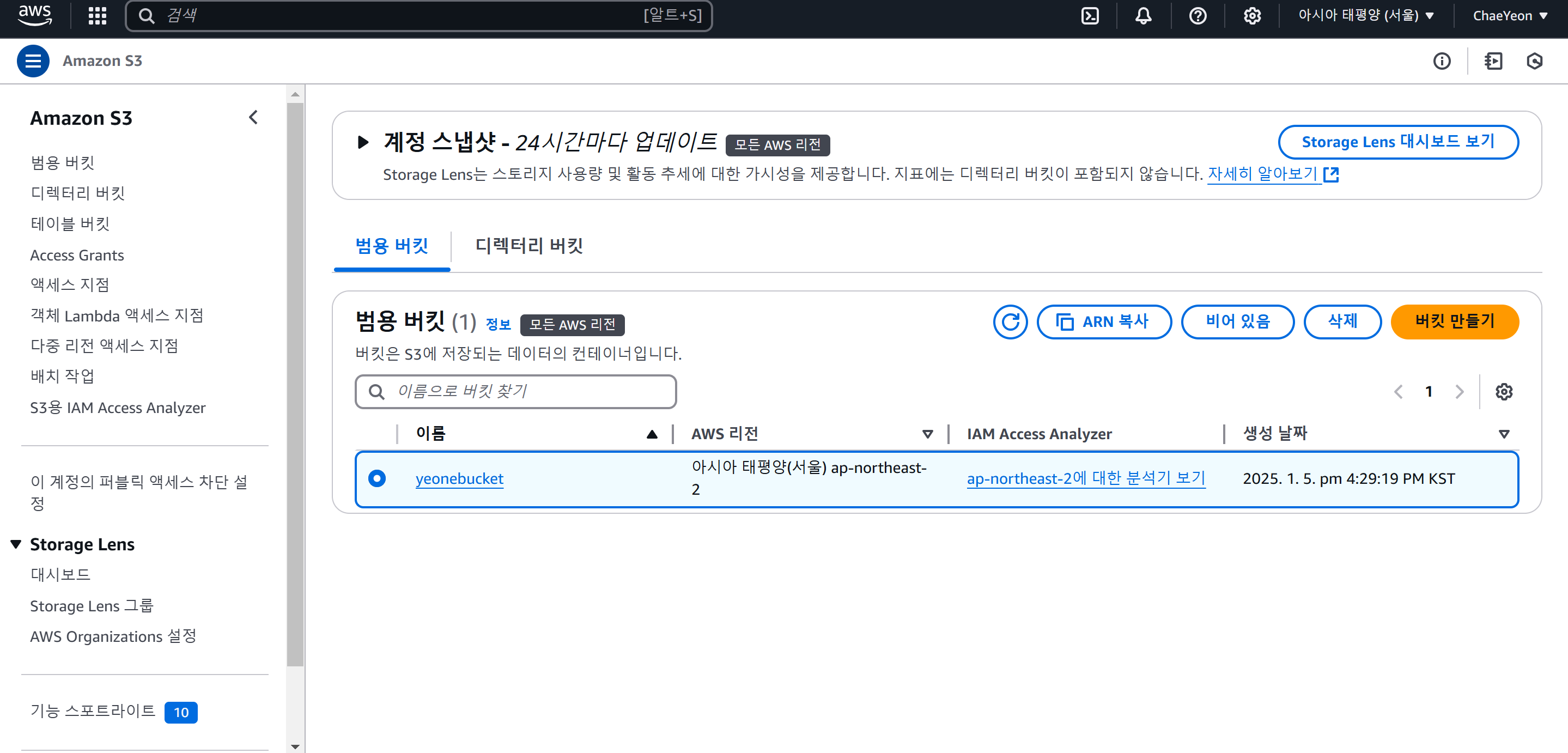
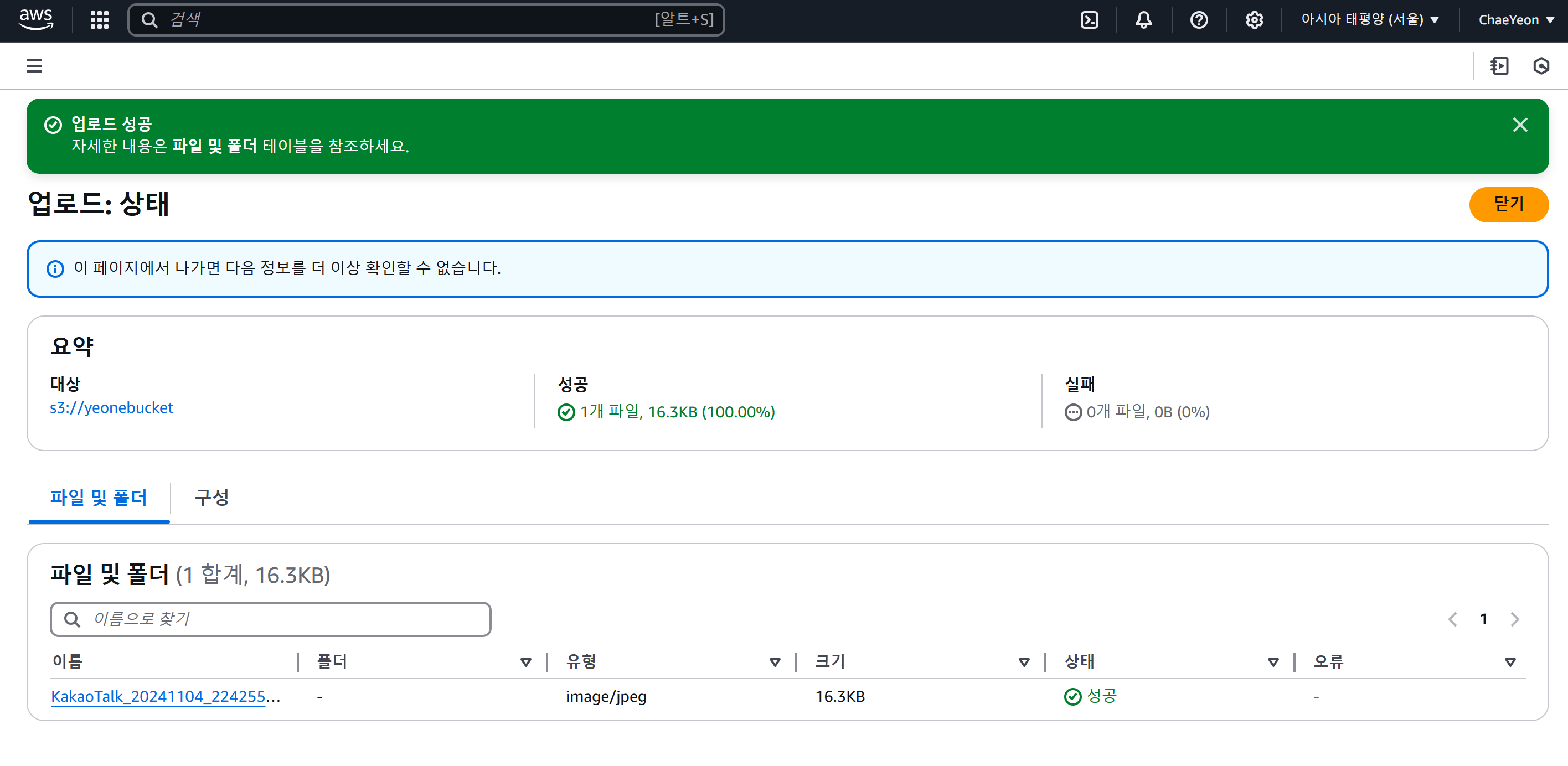
(1-6) Lambda Console을 사용해 애플리케이션 생성 및 S3 이벤트 트리거 설정
Lambda 함수는 이벤트 소스로 S3에 지정하고, 파일을 업로드를 하면 생성 정보가 Lambda 쪽으로 트리거 되도록 한다. Lambda는 어떤 파일이 생성됐는지 확인한다.
- 서비스 → 컴퓨팅 → Lambda 접속
- 함수 생성
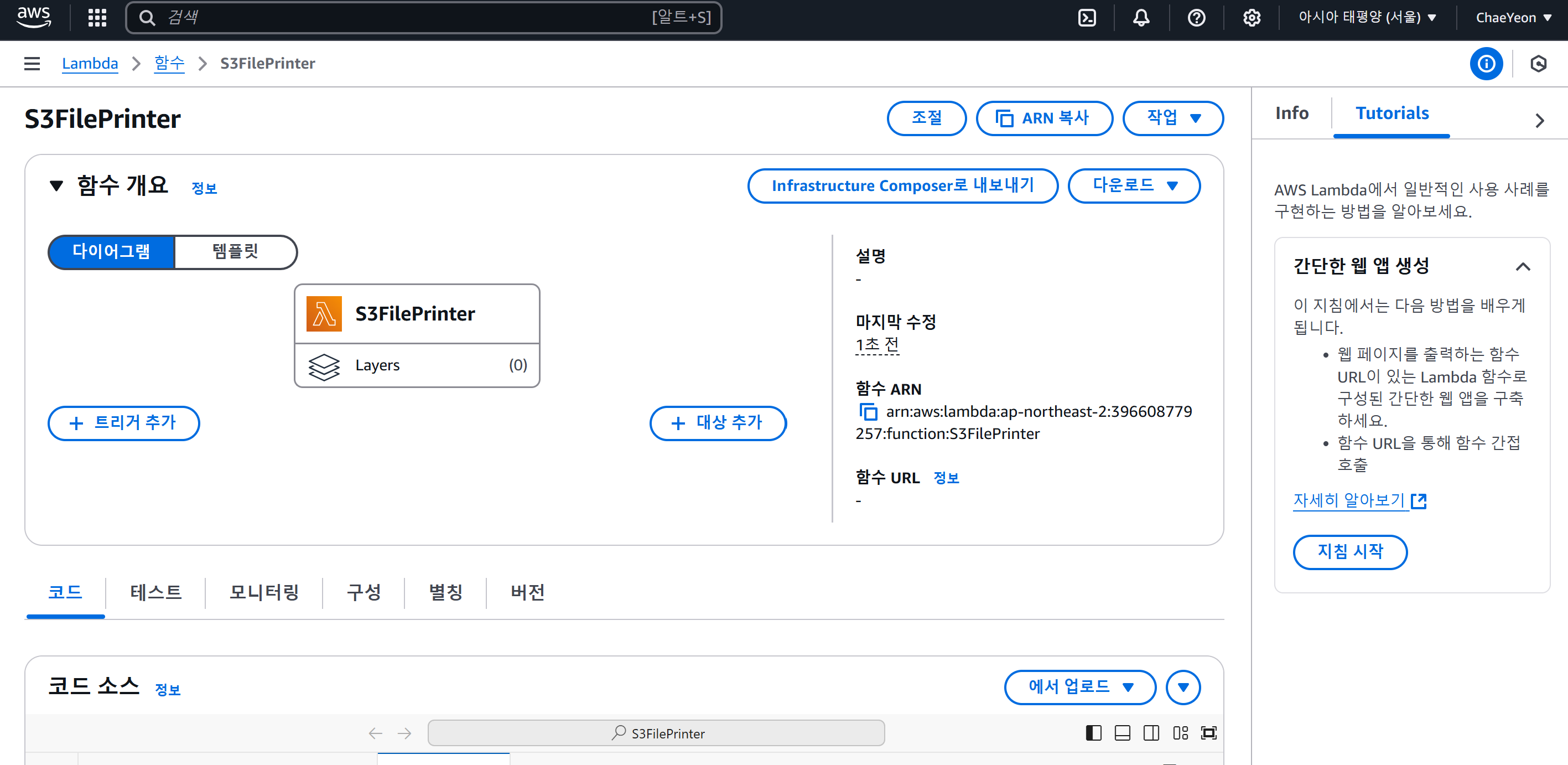
- 트리거 추가
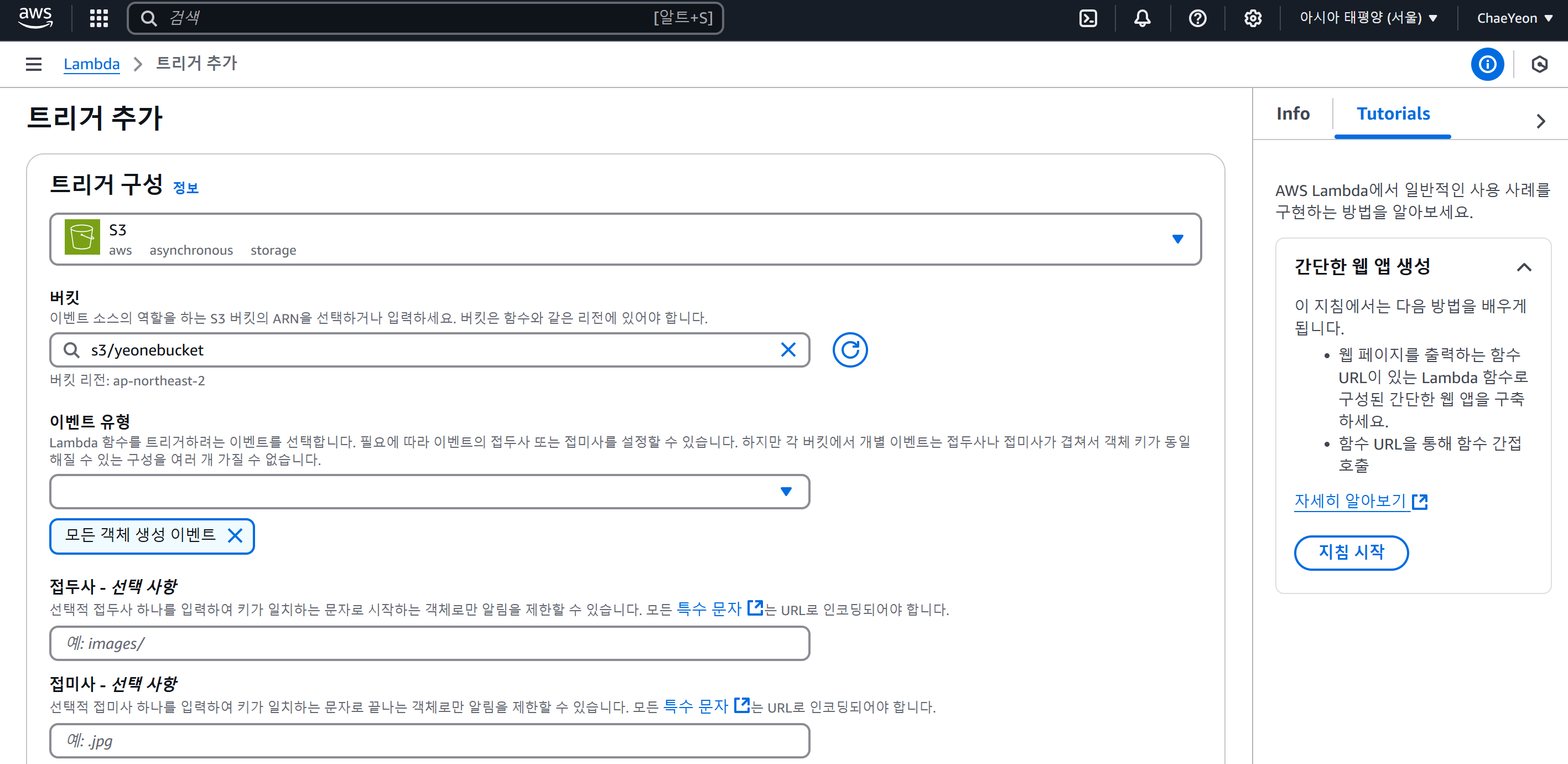
- 트리거 설정 확인
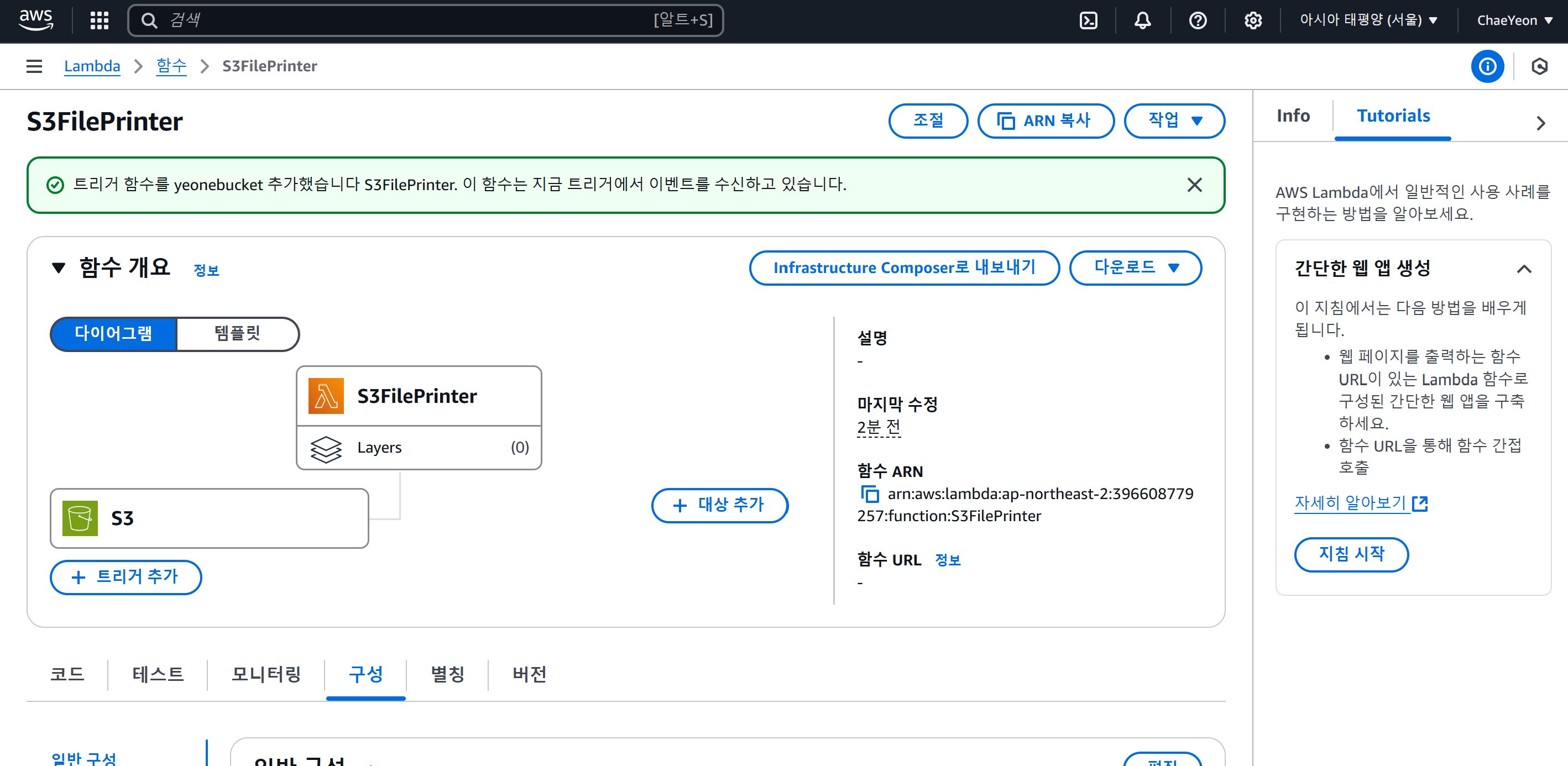
- 코드 작성
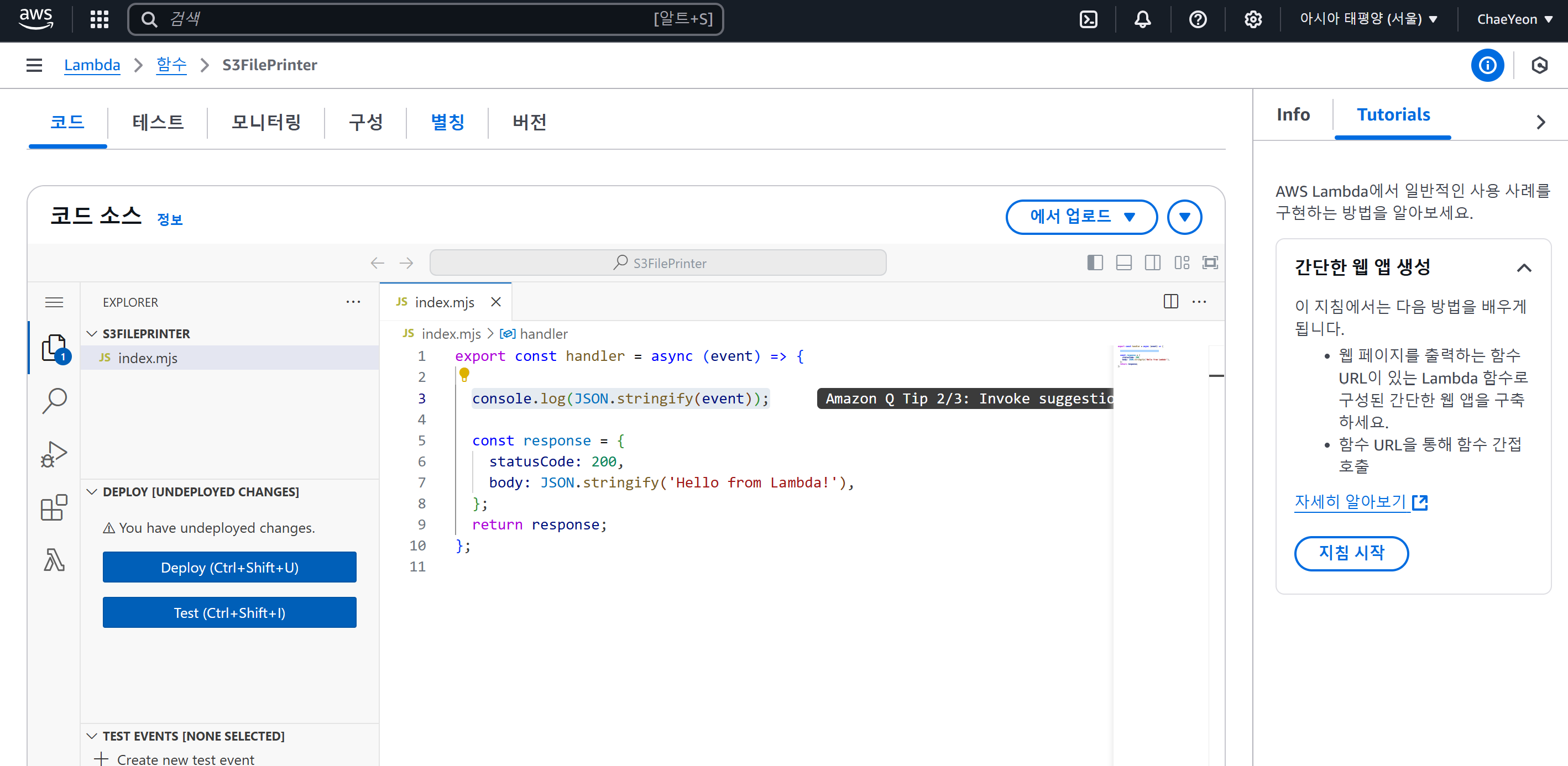
- S3 접속 → 파일 업로드
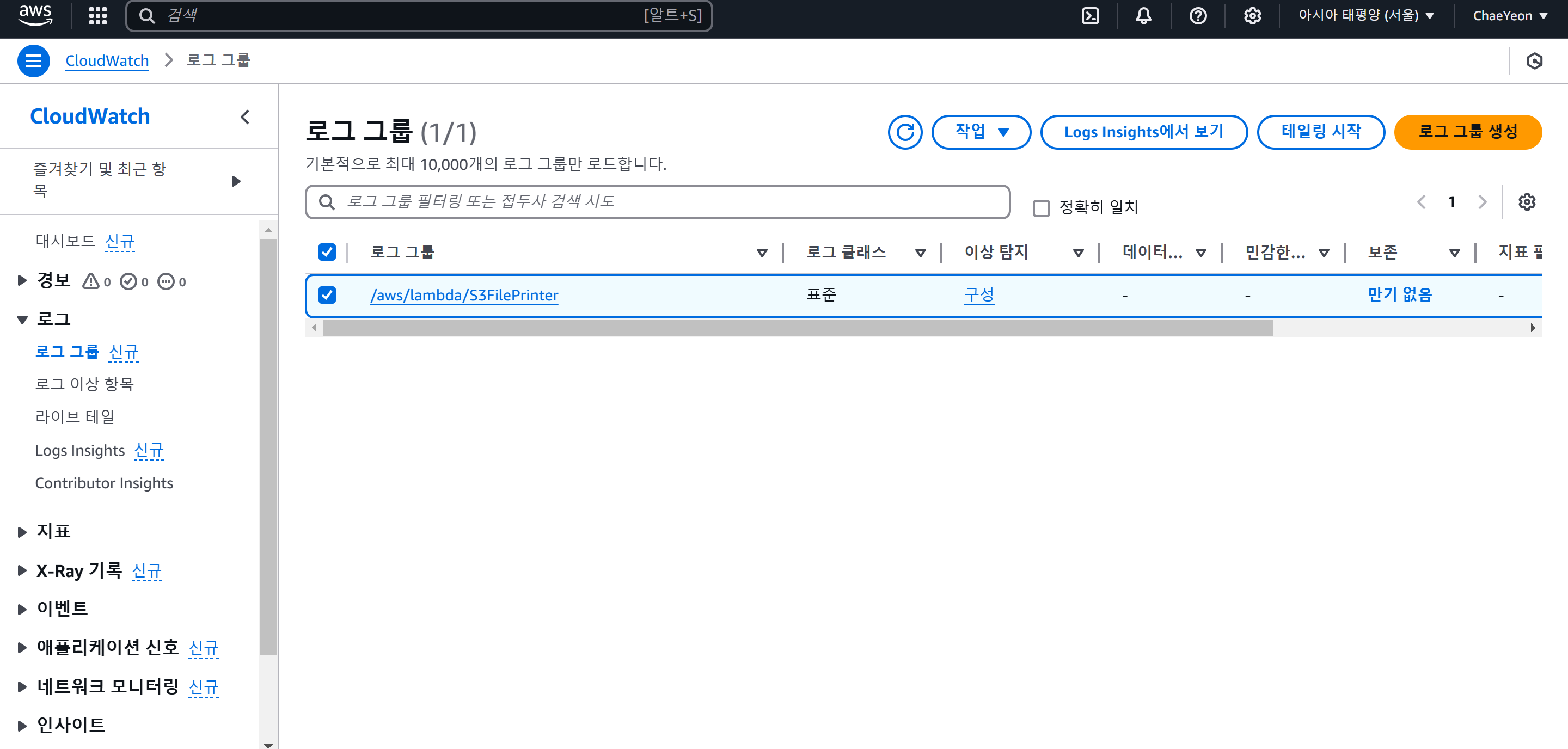
- 관리 및 거버넌스 → CloudWatch → 로그 → 로그 그룹 → 로그 스트림을 통해 상세 로그를 확인한다.
### (2) AWS SAM(Serverless Application Model)
### (2-1) Using AWS SAM
### (3) Cold Start
### (4) Scaling
### (5) Misc. Feactures
### (6) Deployment
### (7) Logging, Monitoring, Tracing
<a href='https://youtu.be/BcoekcPRKWc?si=zZMhcnfSDCdoq9fx' target='_blank'>Amazon Web Services Korea - AWS Lambda 기초부터 실전까지</a>(8) 데이터베이스
데이터베이스(Database)는 애플리케이션이 데이터를 저장하고, 구성하고, 신속하게 검색할 수 있게 한다. 단층 파일(Flat File)에 데이터를 저장할 수도 있지만, 데이터양이 증가하면 검색 속도가 느려진다는 단점이 있다.
개발자는 데이터를 저장하고 검색하기 위해 직접 파일 시스템에서 작업하는 대신, 데이터베이스로 작업을 수행함으로써 애플리 케이션 개발에 집중할 수 있다.
데이터베이스에 기반한 애플리케이션을 구현할 때, 애플리케이션의 가용성과 성능은 데이터베이스 선택과 구성 방법에 달려 있다. 데이터베이스는 관계형과 비관계형 두 가지로 나뉘며, 사용자는 데이터 저장, 구성, 검색 방법에 따라 애플리케이션에 가장 적합한 데이터베이스를 선택할 수 있다.
- Relational Database Service(RDS)
- Redshift
- DynamoDB
(8-1) 관계형 데이터베이스
관계형 데이터베이스는 하나 이상의 테이블을 포함하고 있으며, 열과 행이 있는 스프레드시트로 시각화할 수 있다. 관계형 데이터베이스 테이블에서 열은 속성, 행은 레코드 또는 튜플이라고 한다.
관계형 데이터베이스 테이블에 데이터를 추가하기 전에, 각 열의 이름과 입력될 데이터의 형식을 사전에 정해야 한다. 열에는 순서가 있으며, 테이블을 생성한 후에는 이 순서를 변경할 수 없다. 열의 순서를 정하려면 테이블에 있는 속성 간에 관계를 만들어야 한다. 여기에서 관계형 데이터베이스라는 용어가 나온 것이다. 아래 표는 사원 레코드가 담겨있는 관계형 데이터베이스 테이블의 예시를 보여준다.
| 사원 ID(숫자) | 부서(문자열) | 성(문자열) | 이름(문자열) | 생일(날짜) |
|---|---|---|---|---|
| 101 | 전산 | Smith | Charlotte | 7-16-87 |
| 102 | 마케팅 | Colson | Thomas | 7-4-00 |
데이터는 각 열에서 정의된 형식에 반드시 일치해야 한다. 예를 들어, 사원 ID는 숫자 데이터 형식으로 정의됐기 때문에 문자열을 입력할 수 없다. 관계형 데이터베이스의 한 가지 이점은 어떻게 데이터를 쿼리할지 이해할 필요가 없다는 것이며, 데이터가 일관된 형식으로 존재하는 한 필요한 데이터를 원하는 방식으로 얻기 위해 여러 쿼리를 가공할 수 있다. 관계형 데이터베이스는 임의의 열에 데이터를 쿼리하고 사용자가 데이터 제공 방식을 지정해야 하는 애플리케이션에 적합하다. 표에서 데이터베이스에 쿼리해서 이름이 Charlotte인 모든 사원의 생년월일을 조회할 수 있다. 테이블을 만든 뒤에도 열을 더 추가하거나 삭제할 수 있지만, 열에 저장된 모든 데이터도 삭제된다. 예를 들어, 이름 열을 삭제하면 테이블 내 모든 사원의 이름 데이터가 삭제된다.
(8-2) 다중 테이블
모든 데이터를 단일 테이블에 저장하면 불필요한 중복이 생기기 때문에 데이터베이스가 불필요하게 커지고 쿼리 속도가 느려지므로, 일반적으로 애플리케이션은 다중 테이블을 연결해서 사용한다. 앞의 표에서 전산 부서에 50명의 사원이 근무할 때, 테이블에서 '전산'이라는 문자열은 레코드당 하나씩 50번 나타난다. 이런 불필요한 반복을 피하려면, 아래 표에서 보이는 것처럼 부서 이름을 포함하는 별도의 테이블을 만들 수 있다.
| 부서 ID(숫자) | 부서명(문자열) |
|---|---|
| 10 | 전산 |
| 20 | 마케팅 |
사원 테이블의 각 사원 레코드에 부서명을 입력하는 대신 부서 테이블에 레코드 하나를 생성한다. 사원 테이블은 아래 표에 나온 것처럼 부서 ID를 사용해 각 부서를 참조한다.
| 사원 ID(숫자) | 부서(문자열) | 성(문자열) | 이름(문자열) | 생일(날짜) |
|---|---|---|---|---|
| 101 | 10 | Smith | Charlotte | 7-16-87 |
| 102 | 20 | Colson | Thomas | 7-4-00 |
이러한 관계에서 부서 테이블은 상위 테이블(Parent Table)이고, 사원 테이블은 하위 테이블(Child Table)이다. 사원 테이블의 부서 열에 있는 값은 부서 테이블의 부서 ID를 참조 한다. 사원 테이블의 부서 열의 데이터 형식은 여전히 문자열이라는 사실에 주목해야 한다. 부서 테이블의 부서 ID는 기본 키(Primary Key)라고 한다. 이 기본 키는 행을 고유하게 식별하기 위해서 테이블 내에서 유일해야 한다. 사원 테이블은 부서 ID를 외래 키(Foreign Key)로 참조한다.
(8-3) SQL
관계형 데이터베이스에서는 구조화 질의 언어(SQL, Structured Query Language)를 사용해 데이터를 저장하고 쿼리하고 유지 관리 작업을 수행하므로 SQL 데이터베이스라고도 불린다.
SQL문은 관계형 데이터베이스 관리 시스템(RDBMS, Relational Database Management System)마다 약간씩 다르다. 이는 주요 프로그래밍 언어들에 SQL 문을 만들고 데이터베이스에 입출력하는 라이브러리가 있기 때문이며, AWS 아키텍트로서 SOL까지 알 필요는 없지만, AWS의 관리형 데이터베이스에서 작업하기 위한 일반적인 SQL 용어의 개념은 이해할 필요가 있다.
(8-4) 데이터 쿼리
SELECT문은 SQL 데이터베이스에서 데이터를 쿼리하는 데 사용되며, 데이터베이스에서 조회하고 싶은 특정 열을 지정할 수 있을 뿐 아니라 모든 열에서 값을 기반으로 퀴리할 수 있다. 테이블의 예측 가능한 구조와 외래 키 제약 조건을 사용해서 SELECT문과 함께 JOIN 절을 사용해 여러 테이블의 데이터를 결합할 수 있다.
(8-5) 데이터 저장
INSERT문을 사용하면 테이블에 직접 데이터를 삽입할 수 있다. 대량의 레코드를 저장해야 할 때, COPY 명령을 사용하면 적절하게 형식을 맞춘 파일에서 지정한 테이블로 데이터를 복사할 수 있다.
(9) 온라인 트랜잭션 처리와 온라인 분석 처리
관계형 데이터베이스는 구성에 따라 온라인 트렌젝션 처리(OLTP, Online Transaction Processing)와 온라인 분석 처리(OLAP, Online Analytical Processing)로 나눌 수 있다.
- OLTP
- 데이터베이스는 초당 몇 회씩 순차적으로 데이터를 빈번하게 읽고 쓰는 애플리케이션에 적합하다. OLTP 데이터베이스는 빠른 쿼리에 최적화돼 있으며, 이러한 쿼리는 정기적이고 예측 가능한 경향이 있다. 데이터베이스의 크기와 성능 요구 사항에 따라 OLTP 데이터베이스에는 메모리가 상당히 필요할 수 있는데, 이는 빠른 액세스를 위해 자주 사용하는 테이블 일부를 메모리에 저장하기 때문이다. 보통 단일 서버에 충분한 메모리와 컴퓨팅 성능을 갖추고 OLTP 데이터베이스의 쓰기 작업 전체를 처리한다. OLTP 데이터베이스는 1분당 수백 건의 주문을 처리해야 하는 온라인 주문 시스템을 지원하는 데 적합하다.
- OLAP
- OLAP 데이터베이스는 복잡한 대형 데이터 세트 쿼리에 최적화돼 있으며, 상당한 스토리지와 컴퓨팅이 필요하므로, 데이터웨어하우징 애플리케이션을 구축해 여러 OLTP 데이터베이스를 단일 OLAP 데이터베이스로 모으는 것이 일반적이다. 예를 들어, 사원 관리 시스템용 OLTP 데이터베이스에서 사원 데이터는 여러 테이블에 분산돼 있으며, 데이터웨어하우스는 정기적으로 이러한 테이블을 OLAP 데이터베이스의 단일 테이블에 모은다. OLAP 데이터베이스의 단일 테이블로 모으기 때문에 데이터 쿼리 문을 작성하기가 쉬워지고 쿼리를 처리하는 시간이 줄어든다. 보통 대형 OLAP 데이터베이스에서는 복잡한 쿼리로 인한 컴퓨팅 부하를 여러 데이터베이스 서버가 나눠 맡는다. 파티셔닝이라고 하는 프로세스에서 각 서버는 데이터베이스 일부를 맡아 처리한다.
(10) Amazon Relational Database Service
RDS는 클라우드에서 관계형 데이터베이스 시스템을 실행할 수 있게 하는 관리형 데이터베이스 서비스로서, 데이터베이스 시스템 설정, 백업 수행, 고가용성 보장, 데이터베이스와 기반 운영 체제 패치 적용 등과 같은 작업을 관리한다. 또한, RDS를 사용하면 데이터베이스 장애로부터 복구, 데이터 복원, 데이터베이스 확장을 쉽게 해서 애플리케이션이 요구하는 수준의 가용성과 성 능을 달성할 수 있다.
RDS를 사용해 데이터베이스를 배포할 때, 격리된 데이터베이스 환경인 데이터베이스 인스턴스 구성에서부터 시작한다. 데이터베이스 인스턴스는 지정한 가상 프라이빗 클라우드(VPC)에 존재하나, EC2 인스턴스와는 다르게 AWS가 전적으로 데이터베이 스 인스턴스를 관리한다. SSH를 사용해 액세스할 수 없으며, EC2 인스턴스 사이에서도 보이지 않는다.
(11) 데이터베이스 엔진
데이터베이스 엔진은 데이터베이스에 데이터를 저장, 구성, 반환하는 소프트웨어이며, 데이터베이스 인스턴스는 하나의 데이터베이스 엔진만 실행한다. RDS는 다음 여섯 가지 데이터베이스 엔진 중에서 선택할 수 있다.
- MySQL
- MariaDB
- Oracle
- PostgreSQL
- Amazon Aurora
- Micrasoft SQL
(12) AWS Bedrock
번외로 올해 출판된 AWS 교재 중 Amazon Bedrock이라는 걸 봤다.
Amazon Bedrock으로 시작하는 실전 생성형 AI 개발 바로가기
Bedrock을 이용한 생성형 AI 기초 실습이다.
[Hands-On] AWS Bed-rock을 이용한 생성형 AI 기초 실습 바로가기
현재 목표인 자율주행 로봇 개발에 Amazon Bedrock과 관련되어 도움이 되는지는 프로젝트의 구체적인 요구 사항에 따라 달라진다. Amazon Bedrock은 주로 생성형 AI를 활용하는 서비스로, LLM(Large Language Models) 및 관련 기술을 AWS에서 쉽게 구현할 수 있도록 돕는 도구이다.
Amazon Bedrock이 도움이 될 수 있는 경우는 다음과 같다.
- 자율주행 로봇의 자연어 인터페이스 : 로봇이 사용자의 음성 명령이나 텍스트 명령을 이해하고 반응해야 한다면, 생성형 AI가 필요한 자연어 처리(NLP) 기능을 제공할 수 있다.
- 지식 검색 : Bedrock 기반의 RAG(Retrieval-Augmented Generation)를 사용해 로봇이 실시간으로 데이터를 검색하고 정리해 사용자에게 정보를 제공할 수 있다.
- 유연한 확장 : AI 모델을 쉽게 학습시키고 배포하는 관리형 서비스를 제공하므로 AI 모델 학습 및 운영에 도움이 된다.
Amazon Bedrock은 현재 AWS Free Tier에 포함되어 있지 않으며, 사용 시 별도의 비용이 발생한다. 따라서 비용 문제를 고려할 때 Free Tier 범위 내의 서비스를 우선적으로 학습하기로 했다.
4주 차를 마치며...
데이터베이스를 마치지 못해 5주 차때 이어서 작성할 예정이다.
각 주제 및 서비스 별로 AWS 실습을 제공하고 있어서 참고하면 좋을 것 같다.
