
오늘 배운 것 (새로운 것 위주)
데이터 구조
CRISP-DM 방법론
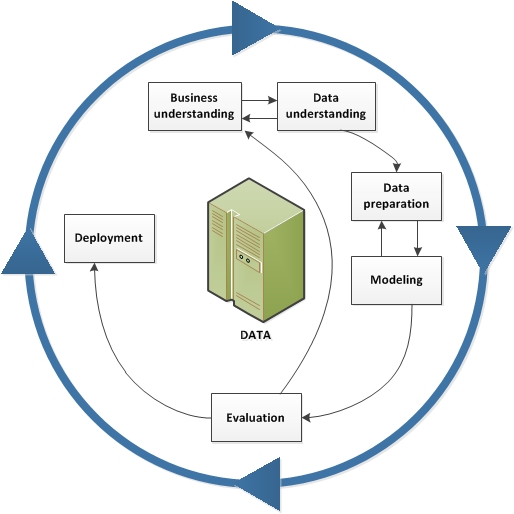
출처 : IBM
-
6단계 사이클로 구성된 데이터 마이닝의 방법론이다.
-
이름이 조금씩 바뀌거나, 일부 단계가 수정되는 것을 제외하면 거의 모든 데이터 마이닝은 이 방법론을 기반으로 한다.
- 비즈니스 이해 단계 : 문제를 정의한다.
- 데이터 이해단계 : 데이터를 수집 및 검증하고, 새로운 인사이트를 얻는다.
- 데이터 전처리
- 모델링 : 학습 및 검증 (각종 모델 적용)
- 평가 : 정의된 문제를 해결하였는지 검증 (모델 해석)
※ 문제가 해결되지 않았다면 1~4단계로 돌아간다. - 배포 : 웹서비스 구축
분석할 수 있는 데이터
분석할 수 있는 데이터의 종류는 크게 두가지로 구분할 수 있다.
- 숫자형 (정량적 데이터)
- 이산형 데이터 : 셀 수 있는 데이터
- 연속형 데이터 : 셀 수 없는 데이터
- 범주형 (정성적 데이터)
- 명목형 데이터 : 범주간 순서가 없음
- 순서형 데이터 : 범주간 순서가 있음
데이터 구조
분석을 위한 데이터 구조의 가장 기본은 2차원 테이블이다.
행 (Rows)
한 행은 하나의 개별적인 분석 단위를 말한다.
판다스의 데이터프레임에서는 행 하나가 하나의 데이터를 나타낸다.
열 (Columns)
목표와 요인으로 구성된다.
- 목표(Target) : label이라고도 하며, 요인으로 설명할 수 있는 정보이다.
- 요인(Feature) : 목표에 영향을 주는 정보이다.
이렇게 2차원 테이블로 구성된 데이터 구조를 다루는데 특화된 패키지가 바로 numpy와 pandas이다.
Numpy 기초
Numpy는 배열의 수치 연산에 특화된 자료형이다.
용어
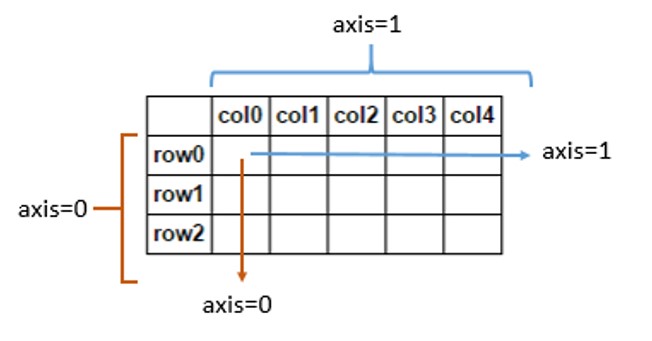
출처 : Stack Overflow
- Axis : 배열의 각 축을 말한다.
- Axis 0 : 행방향 축 (2차원에서) - Axis 0의 수가 곧 분석 단위의 수를 나타낸다
- Axis 1 : 열방향 축 (2차원에서)
- Rank : 축의 개수(차원)
- Shape : 축의 길이 (해당 축에 있는 element의 개수)
Shape 읽는법
Shape(3, ) : 원소가 3개있는 1차원 배열이다.
Shape(2, 3) : 2행 3열로 구성된 Rank 2(2차원)의 배열이다.
Shape(3, 4, 4) : 4 x 4 2차원 배열 3개로 구성된 Rank 3의 배열이다.
※ 예를들어 흑백 이미지데이터에서 (2500, 28, 28)이라면 28px * 28px로 이루어진 이미지 2500장인 데이터를 말한다.
Numpy 인덱스 조회
-
arr[행 인덱스][열 인덱스],arr[행 인덱스, 열 인덱스]두 가지 형태를 사용할 수 있다. -
리스트 처럼 슬라이싱이 가능하다.
arr[행 인덱스]: 행 인덱스 전체arr[:, 열 인덱스]: 열 인덱스 전체 (행 인덱스를 생략할 수 없다)
-
원하는 행 또는 열을 리스트 형태로 지정할 수 있다.
arr[[0, 2], 1:3]: 0행, 2행에서 1~2열의 값을 출력
-
지정하는 방식에 따라 원소가 같아도 서로 다른 차원으로 출력할 수 있다.
- 특정 값을 정해서 조회하면 1차원 배열이 출력
- 행, 열 모두 범위(슬라이싱 또는 리스트)를 지정해서 조회하면 2차원 배열이 출력)
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
print(arr[:, 1])
# >>> [2, 5, 8, 11]
print(arr[:, 1:2])
# >>> [[2],
# [5],
# [8],
# [11]]
유용한 함수
np.where
- syntax :
np.where(condition, if True, if False)
배열의 각 원소마다 조건문을 비교하여, 각각 다른 값을 반환하도록 하는 함수이다.
argmax/argmin
- 각각 배열의 최대값/최소값의 인덱스를 반환한다.
axis인자로 축 방향을 지정하서 행/열별 최대최소값의 인덱스를 받을수도 있다.
Pandas 기초
유용한 메서드
sort_values
데이터프레임을 컬럼을 기준으로 정렬해주는 메서드이다.
컬럼을 리스트에 담아 여러개를 전달하면, 첫번째 컬럼으로 1차 정렬을 한 뒤, 동일 값에 대해 그 다음 컬럼으로 2차 정렬을 한다.
ascending=True/False 옵션으로 오름차순 또는 내림차순을 지정할 수 있다.
count_values
데이터프레임의 unique 값과 그 값을 갖는 원소 수를 출력해주는 메서드이다.
범주의 종류와 빈도를 파악할 때 유용하다.
loc 인덱싱
df.loc[행 조건, <열 이름>]으로 조건에 맞거나, 특정 범위에 해당하는 데이터프레임 값만 조회할 수 있다.
추가학습
데이터 열 이름 변경
-
df.rename메서드를columns={기존 열 이름 : 변경할 열 이름}을 딕셔너리 형식으로 호출하면, 열이름이 변경된 데이터프레임을 반환한다. -
df.column속성에 직접 접근하여 열이름을 변경해 줄 수 있다. 이 경우, 변경하고 싶지 않은 열 이름까지 모두 적어줘야 한다.
열 추가
-
딕셔너리처럼
df['추가할 열 이름'] = [시리즈]로 열을 추가할 수 있다. -
기본적으로 가장 마지막 열에 추가되며,
insert()메서드를 통해 원하는 인덱스에 열을 추가할 수 있다.
행/열 삭제
-
df.drop메서드를 이용하여 행과 열을 삭제할 수 있다.axis=1: 열 방향 삭제 (컬럼명을 입력해주어야 한다)axis=0: 행 방향 삭제 (Default, 인덱스를 입력해 주어야 한다)
-
삭제하면 돌이킬 수 없으니 따로 복사를 한 뒤
inplace=True로 제거하거나, 아니면 아예 새로운 변수명에 제거한 데이터가 들어가도록 하는 것이 좋다.
값 변경
값을 직접 지정
-
df['컬럼명'] = 값으로 컬럼 전체를 값으로 바꿀 수 있다. (위험함) -
df.loc['조건식'] = 값으로 조건을 만족하는 행만 값을 바꿀 수 있다. -
np.where함수를 이용하여 두 가지 종류의 범주값으로 바꿀수도 있다.
메서드/함수 이용
-
series.map: 특정 열의 범주형 변수 값을 바꿀 때 사용한다.columns={기존 범주 값 : 변경할 범주 값}을 딕셔너리 형태로 담아 호출하면 값을 변경할 수 있다. -
pd.cut: 숫자형 변수를 일정 범위를 기준으로 범주형 변수로 바꿀 때 사용한다.pd.cut(변경할 df, 나눌 개수 n, labels=[범주형 값1, 범주형 값2, ..., 범주형 값2])- 예를들어 100을 3으로 나누면 대략 0~33, 34~66, 67~100 의 균등한 세 범위로 나눈다.
bins=[최소값, 범위1, 범위2, ... 범위n-1, 최대값]인자를 통해 범위를 직접 지정할 수도 있다.
