
오늘 배운 것
groupby
범주별로 묶어서 집계함수를 사용할 수 있는 메서드
df.groupby('집계기준변수', as_index)['집계대상변수'].집계함수
tip.groupby('day', as_index=True)['tip'].sum(): 날짜별 팁의 합계- as_index 옵션은 True일 경우 집계기준변수를 인덱스로 사용하고, False일 경우 0, 1, 2 의 순차적인 인덱스로 사용한다.
groupby 결과를 데이터프레임으로 받기
-
as_index를 False로 설정
인덱스가 별도로 생성되므로, 집계기준, 집계대상 최소 2개의 열로 이루어진 데이터프레임을 반환한다. -
집계대상변수를 리스트에 담기
agg() 메서드
df.groupby('집계기준변수', as_index)['집계대상변수'].agg([집계함수1, 집계함수2, ...])
한번에 여러개의 집계함수를 수행하는 메서드이다.
{'컬럼명1' : '집계함수1', '컬럼명2' : '집계함수2'} 와 같은 딕셔너리 문법을 이용해 컬럼별로 서로 다른 집계함수를 설정할 수 있다.
데이터 처리 Overview
데이터 처리란 Raw Data를 분석 가능한 데이터로 변환하는 것.
Raw Data에는 여러가지가 있다.
- Dataset (csv)
- 데이터베이스
- 로그 기록
이 중 실무에서 가장 많이 접하게 되는 것은 데이터베이스이다.
데이터 전처리는 두가지 단계로 나뉜다.
- 데이터 구조 만들기
데이터베이스의 Raw Data를 바탕으로, 데이터 분석을 위한 데이터셋 만들기
- 모델링을 위한 전처리 (좁은 의미의 데이터 전처리)
ML, DL의 모델링 위한 데이터 변환
- 모든 셀은 값이 있어야 한다.
- 모든 값은 숫자로 이루어져 있어야 한다.
- 필요시, 숫자 데이터의 범위를 조절해야 한다.
분석을 위한 데이터 구조
아래와 같이 구성된 2차원 테이블을 기본 구조로 사용한다.
- 행 : 분석 단위
- 열 : target과 feature로 구성된 정보
- y(목표) : 데이터 분석의 목표
- x(요인) : 가설 수립 (목표에 영향을 줄 것이라 생각되는 요인들)
테이블에서 열의 이름도 매우 중요한데, 열 이름과 값이 나타내는 관계가 이상하다면 적절한 이름으로 변경해야 한다.
열 이름 변경
어제 TIL 에서 어느정도 다룬 내용이다.
inplace 매개변수
원본 값을 변경하는 대부분의 메서드에서 옵션으로 줄 수 있는 매개변수이다.
False (기본값) : 원본을 변경하지 않고 조회의 개념으로 사용
True : 원본을 변경
df.columns
열 속성을 직접 변경한다.
df.columns = ['열 이름1', '열 이름2', ...]
모든 열이름을 동시에 지정해야 한다.
변경하지 않는 열 이름이 있다면, 기존 값을 그대로 넣는다.
df.rename()
지정한 열 이름을 변경한다.
df.rename(columns={'원래 이름1':'변경할 이름1', '원래 이름2':'변경할 이름2' ...}, inplace)
원래 이름과 변경할 이름을 딕셔너리에 담아 인자로 전달한다.
inplace를 사용할 수 있다.
열 삭제
열 삭제는 원본 데이터를 잃어버릴 수 있으므로 신중히 해야한다.
원본 데이터를 복사한 별도의 데이터프레임에서 사용하는 것이 좋다.
df.drop()
조건에 맞는 행 또는 열을 삭제한다.
df.drop(<열 이름 또는 인덱스>, axis, inplace)
axis = 0 (기본값) : 지정한 인덱스의 행을 삭제한다.
axis = 1 : 조건식을 만족하는 열을 삭제한다.
리스트를 이용해 여러개의 값을 전달할 수 있다.
값 변경
값 변경 역시 열 삭제와 동일하게 신중해야 한다.
조건에 의한 값 변경
df.loc[]와 조건식을 이용해서 변경이 가능하다.
np.where()를 이용할 수도 있다.
df.map()
범주형 값을 다른 값으로 변경할 때 사용한다.
df['열 이름'].map({'범주값 1' : 변경할 값, '범주값 2' : 변경할 값 ...})
범주값과 변경할 값을 딕셔너리로 전달한다.
변경 할 열의 모든 범주 값을 입력해주어야 한다. 그렇지 않으면 에러가 발생한다.
pd.cut()
숫자형 값을 범위를 이용해 범주형 값으로 변경할 때 사용한다.
pd.cut(df['열 이름'], bins, labels)
-
bins는 정수 또는 리스트를 입력한다.
- 정수를 입력할 경우 지정한 정수만큼의 범위로 나누어 범주 값을 지정한다.
- ex) 최소값 0, 최대값 60이고, 3을 지정할 경우 20이하, 40이하, 60이하의 값으로 나뉜다.
- 리스트를 입력할 경우 리스트 내의 값을 경계값으로 사용한다.
- ex)
bins = [0, 20, 40, 60]: 20이하, 40이하, 60이하 3개의 범위로 나뉜다.
-
labels는 범주형 값을 리스트로 입력한다.
데이터프레임 결합
pd.concat
인덱스와 열 이름을 기준으로 두개 이상의 데이터 프레임을 합치는 함수이다.
`pd.concat([df1, df2, ...], axis, join)
방향 선택
axis 옵션을 통해 결합 방향을 선택할 수 있다.
axis = 0 : 행을 추가하는 방향으로 데이터프레임을 합친다 (위아래로 합침)
컬럼의 구조가 서로 같아야 온전하게 합칠 수 있다.
axis = 1 : 열을 추가하는 방향으로 데이터프레임을 합친다 (좌우로 합침)
인덱스가 서로 같아야 온전하게 합칠 수 있다.
방법 선택
join 옵션을 통해 데이터프레임을 합치는 방법을 선택할 수 있다.
이미지 출처 : 판다스 공식문서
-
join = 'outer'(기본값) : 결측치에 상관 없이 그대로 합친다.
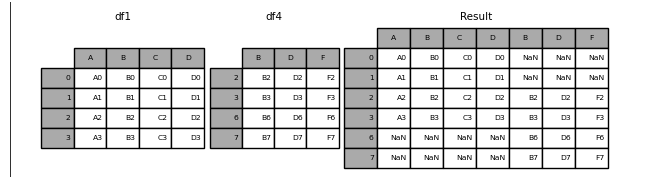
-
join = 'inner': 서로 일치하는 인덱스/열 이름에 대해서만 합친다.
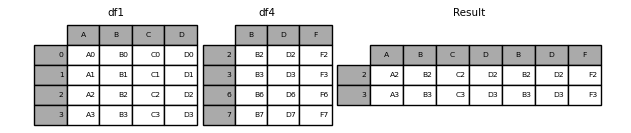
인덱스
concat을 통해 합치는 경우 인덱스, 열 이름이 중복되게 합쳐지게 되는 경우가 있어 별도로 처리해주어야 한다.
pd.merge()
두 데이터프레임이 공통으로 갖는 키(열 이름)의 값을 기준으로 병합한다.
반드시 2개의 데이터프레임만을 합칠 수 있고, 좌우로만 데이터프레임을 붙일 수 있다.
pd.merge(df_left, df_right, on, how)
방법 선택
how 옵션을 통해 결합 방법을 선택할 수 있다.
-
how = 'inner'(기본값) : 값이 일치하는 행 끼리만 합친다. -
how = 'outer': 모든 행을 합친다. -
how = 'left': 왼쪽 데이터프레임은 온전히 놔두고, 왼쪽 키 값과 일치하는 행만 오른쪽에서 가져온다. 만약 일치하지 않는 행이 있다면 결측치가 된다.
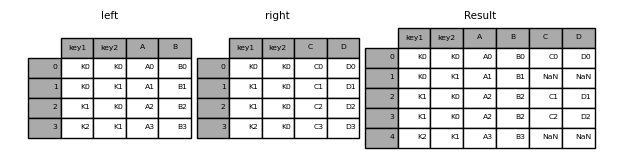
right에는 [K0, K1]의 키값을 갖는 행이 2개 있으므로 둘로 나뉜다.
right에는 [K2, K1]의 키값을 갖는 행이 없으므로, 결측치가 된다.
how = 'right: 오른쪽 데이터프레임은 온전히 놔두고, 오른쪽 키 값과 일치하는 행만 왼쪽에서 가져온다. 만약 일치하지 않는 행이 있다면 결측치가 된다.
정렬 기준 선택
on 옵션을 통해 key가 될 열을 선택할 수 있다.
생략하면 key가 될 수 있는 열(열 이름이 같은 열)을 모두 선택한다.
리스트로 키를 2개 이상 선택할 수 있으며, 이 경우 inner라면 모든 키값이 서로 같아야 결합이 이루어진다.
df.pivot()
데이터 프레임을 재구성하여 피벗테이블을 만들 수 있는 메서드이다.
데이터프레임 결합이 중요한 이유
기본적으로 모든 비즈니스는 판매 제품(서비스), 고객, 거래의 세 가지 데이터가 존재한다.
만약 각각의 거래에 고객에 대한 모든 자질구레한 정보(주소, 전화번호, 이름, 선호품목 등)나 제품에 대한 모든 자질구레한 정보를 매번 저장한다면 성능면이나 메모리 면에서 모두 비효율 적이다.
때문에 거래 테이블에는 고객번호, 제품번호와 같은 최소한의 정보만 남겨놓고, 고객 테이블, 제품 테이블과 같은 별도의 DB를 만들어 관리하게 된다.
이렇게 중복을 줄이는 과정을 '정규화'라고 하며, 데이터가 DB 곳곳에 분산 저장되어있는 이유이다.
분석을 위해 이렇게 분산된 데이터를 합치기 위해서는 데이터프레임 결합을 잘 하는 것이 필수적이다.
실습
타이타닉 데이터 다루기

titanic2 = titanic.copy()
# 4-1) PassengerId, Name, Ticket, Cabin 열 삭제
titanic2.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 4-2) 열 이름 변경: Sex --> Male
titanic2.rename(columns={'Sex':'Male'}, inplace=True)
# 4-3) Male 열 값 변경: male --> 1, female --> 0
titanic2['Male'].map({'male':1, 'female':0})
# 4-4) Family = SibSp + Parch
titanic2['Family'] = titanic2['SibSp'] + titanic2['Parch']
# 4-5) SibSp, Parch 열 삭제
titanic2.drop(['SibSp', 'Parch'], axis=1, inplace=True)
# 4-6) 확인
titanic2.head()
