
오늘 배운 것
딥러닝 데이터 전처리
reshape
- 전통적인 ANN(Artificial Neural Network) Fully Connected 모델은 1차원만을 입력받을 수 있기 때문에, 이미지 등 2차원 이상의 데이터는 변환과정을 거쳐야 한다.
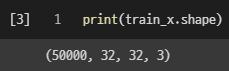
- 이 학습 데이터셋은 32 x 32 x 3의 형태를 가진 3차원 데이터 50000개를 의미한다.
- 가로세로 32px로 구성되어 있고, 각 픽셀이 RGB 데이터를 갖는 이미지 데이터이다.
- 이를 1차원으로 변환하면 32 32 3 = 3072 개의 1차원 데이터로 변환할 수 있다.
# train_x.shape[0]은 50000개의 데이터를 의미
print(train_x.reshape(train_x.shape[0], -1).shape)
>>> (50000, 3072)Flatten layer
- 사전에 reshape로 전처리하는 방법 말고, 모델에 Flatten layer를 추가함으로써 동일한 효과를 얻을 수 있다.
- reshape 없이 Input layer shape를 지정하고, 바로 다음 층에 Flatten layer를 추가하면 모델 학습 과정에서 1차원 데이터로 변환된다.
- 실제 학습이 이루어지지 않아 파라미터는 0개가 증가한다.
model.add( keras.layers.Input(shape=(32, 32, 3)) )
model.add( keras.layers.Flatten() )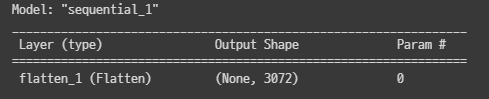
shape = (3072, ) 형태로 변환되었음을 확인할 수 있다.
scaling
- 딥러닝에서 스케일링을 하는 이유는 다음과 같다.
- 변수별로 단위가 다를 경우, 단위에 따라 중요도에 영향을 미치는 정도가 달라질 수 있는 문제를 예방
- 딥러닝에서 local minimum에 빠질 가능성을 줄여줌
- 경사하강법 사용시 수렴 속도가 빨라진다.
- sigmoid, tanh와 같은 활성함수 사용 시 미분값이 0으로 수렴하는 현상을 늦게 일어나게 한다.
- 스케일링은 다양한 종류가 있지만, 현재 단계에서는 가장 기본이되는 Minmax 스케일링을 진행하였다.
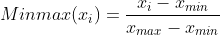
- 데이터의 범위를 [0, 1]로 맞추어준다.
One-Hot Encoding
- 클래스가 3개 이상인 멀티 클래스 문제의 경우, 범주를 명확히 구분하기 위해 One Hot Encoding을 한다.
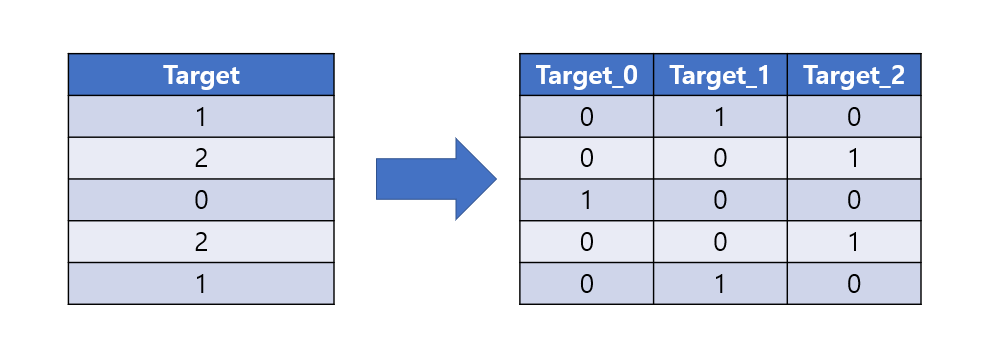
※ 컬럼명은 참고용으로 넣은 것이다. 딥러닝에서는 컬럼명이 존재하지 않는다.
Tenserflow.keras.utils모듈이 제공하는to_categorical함수를 사용할 수 있다.
# 범주 종류의 수 저장
class_n = len(np.unique(train_y))
train_y = to_categorical(train_y, class_n)
test_y = to_categorical(test_y, class_n)Functional API
- 지금까지 모델링을 진행한 방식은 Sequential API이다.
- Functional API를 통해 모델링을 진행하는 방법을 배워보자.
모델링 과정
-
세션 클리어 : Sequential API때와 동일하게 메모리를 비우는 과정이다.
-
레이어 연결 : 각 레이어를 변수로 저장한 뒤, 마치 함수처럼
소괄호()를 이용해 서로를 연결한다. -
모델 선언(Input layer와 Output layer 지정) : Input과 Output 레이어를 지정해 모델에 시작과 끝을 알려준다.
-
컴파일 : Sequential API와 동일한 과정이다.
코드
# 1. 세션 클리어
keras.backend.clear_session()
# 2. 레이어 연결
il = keras.layers.Input(shape=(8, ))
h1 = keras.layers.Dense(32, activation='swish')(il)
h2 = keras.layers.Dense(32, activation='swish')(h1)
h3 = keras.layers.Dense(16, activation='swish')(h2)
h4 = keras.layers.Dense(8, activation='swish')(h3)
ol = keras.layers.Dense(1)(h4)
# 3. 모델 선언
model = keras.models.Model(inputs=il, outputs=ol)
# 4. 컴파일
model.compile(loss=keras.losses.mse, optimizer='adam')
# 요약
model.summary()- Functional API를 이용할 경우 model.summary에 Input레이어도 표시된다.
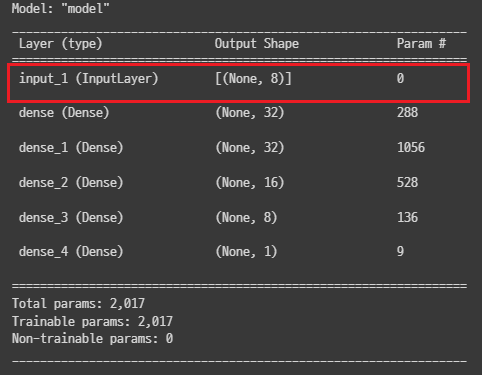
실습
Fashion MNIST
- MNIST와 동일하게 28 x 28의 흑백 이미지 60000개로 구성된 데이터 셋이다.
- 숫자 대신 10가지의 옷 종류 이미지가 들어있다.
- 기존 MNIST의 문제
- 분류가 너무 쉽다
- 이미 너무 많은 사람들이 사용하였다.
- 현대의 CV 딥러닝을 대표하지 못하는 데이터셋이다.
- 이러한 이유로 MNIST보다 심화된 분류 문제를 제공하기 위한 데이터셋이다.
CIFAR-10
- 서로 다른 10가지의 분류를 가진 32 x 32 x 3 컬러 이미지 50000개로 구성된 데이터 셋이다.
- 지금까지 배운 Fully Connected ANN으로는 분류 성능에 한계가 있다.
- 실제로 아무리 레이어를 깊게 쌓고, 노드를 늘려봐도 분류 정확도 50%를 넘을 수 없었다.
CIFAR-10으로 본 현재 모델의 문제점
- 3차원 데이터를 1차원으로 변환하고 있다.
- 변환 과정에서 3차원 데이터의 공간적 정보가 소실된다는 문제가 있다.
- 3차원 데이터를 변환 없이 모델에 넣을 수 있어야 보다 좋은 성능을 기대할 수 있을 것이다.
이러한 한계를 극복한 것이 바로 CNN(합성곱 신경망)이다.
이번 딥러닝 과정은 아니지만, 추후 컴퓨터 비전 과정에서 배우게 될 것이다.
