
오늘 배운 것
model.summary()
- 모델을 선언 한 뒤
model.summary()를 통해 만들어진 모델의 요약을 확인할 수 있다.

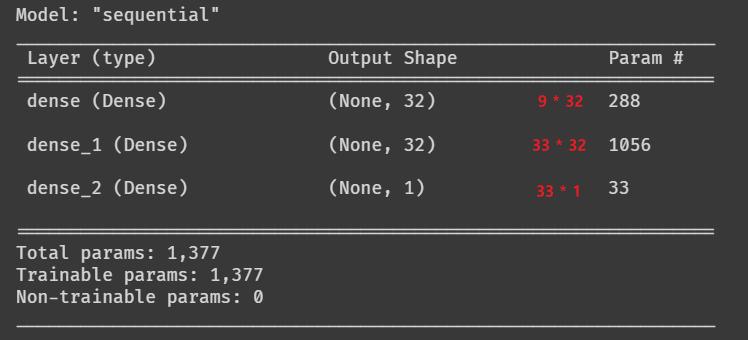
- sequential api의 경우 Input 레이어가 summary에 출력되지 않는다.
- Input의 shape가 (8, )일 경우 파라미터는 9개로 출력되는데 이는 편향 하나가 추가되었기 때문이다.
히든 레이어
솔직히 오늘 배운 내용만으로는 히든 레이어가 잘 이해가 되지 않았다.
추가로 찾아서 공부한 뒤 정리하자.
- 히든레이어는 Input과 Ouput 사이에 있는 은닉 레이어를 말한다.
- 먼저 히든 레이어 없이 Input과 Output으로만 구성된 로지스틱 회귀 모델이 있다고 하자.
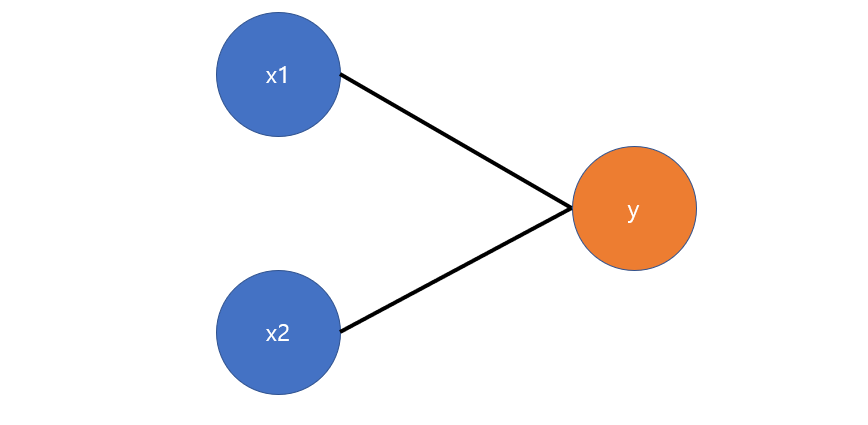
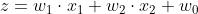
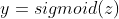
- 이 모델은 위와 같이 나타낼 수 있다.
- w는 학습에 의해 업데이트 된 가중치이며, z는 가중치를 통해 예측한 정보를 요약한 것이다.
- z는 sigmoid 비선형 함수를 통해 (0, 1)의 확률로 변환함으로써 예측값 y를 얻게 된다.
-
여기에 히든 레이어 2개 층을 사이에 끼우면 다음과 같이 된다.
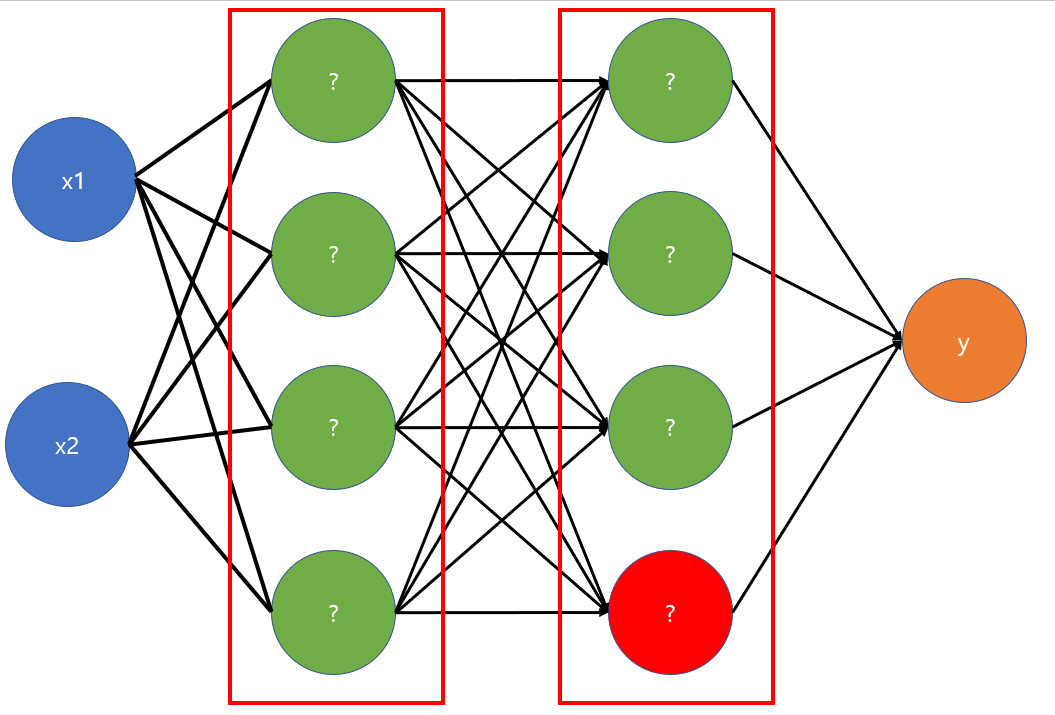
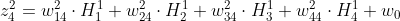
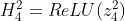
-
위 식은 빨간색으로 표시된 히든 레이어 노드에서 일어나는 일을 나타낸 식이다.
-
여기서 H는 히든 레이어를 거침으로써 새롭게 만들어진 high-level의 특징(feature)이다.
-
히든 레이어의 노드 수는 해당 level에서 추출하려는 feature의 수와 같고, 히든 레이어가 깊게 쌓일 수록 기존에 없던 더 고수준의 특징이 생성된다.
-
히든 레이어를 이용한 딥러닝 모델에서 학습이 잘 되었다는 것은 연결된 것으로 부터 새로운 feature를 잘 추출한 것이다. = Feature representation 또는 Feature Learning
-
모델링에서 히든레이어를 추가하는 방법은 활성함수로 relu, swish 등을 사용하는 Dense layer를 추가하는 것이다.
## 회
# 1. 이전 모델링 클리어
keras.backend.clear_session()
# 2. 모델 발판 만들기
model = keras.models.Sequential()
# 3. 모델 블록 쌓기
model.add( keras.layers.Input(shape=(8, )) )
model.add( keras.layers.Dense(32, activation='relu') )
model.add( keras.layers.Dense(32, activation='relu') )
model.add( keras.layers.Dense(1, activation='sigmoid') )
# 4. 컴파일
model.compile(loss='binary_crossentropy', metrics = ['accuracy'],optimizer='adam')
# 요약
model.summary()ReLU
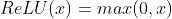
- 0보다 작은 수는 0으로, 0이 상의 수는 그대로 출력하는 비선형 함수이다.
- 기존 딥러닝에서는 sigmoid나 tanh를 사용했는데, 이 둘은 0일 때 기울기가 가장 크고 x값이 커지거나 작아짐에 따라 기울기가 0으로 수렴하는 특징이 있다.
- 이 때문에 딥러닝 학습시 층이 깊어질수록 이전 데이터의 정보(기울기)가 소실되는 문제가 발생하였고, 이로인해 층이 일정 이상 깊어지면 오히려 학습 오차가 증가하는 문제점이 있었다.
- 이를 해결한 것이 바로 ReLU 함수이다.
- 최근 자주 사용되는 swish 등의 비선형 함수도 모두 ReLU를 베이스로 한 것이 많다.
ML vs DL
- 히든레이어가 바로 머신러닝과 딥러닝을 가르는 가장 큰 차이가 된다.
머신러닝
- 데이터 분석 및 데이터 처리 과정을 통해 target에 관련이 있을 것이라 생각하는 feature를 탐색, 가공 및 생성한다. (사람이 - Feature Engineering)
- Feature를 잘 이해하고, 만들기 위해 수학적 지식보다는 도메인 지식이 더욱 중요하다.
- 이렇게 잘 가공된 데이터가 모델의 전체 성능을 좌우한다.
- 이미 잘 정제 되었고, 데이터 수가 비교적 적은 Tabular Data에서 DL과 비슷하거나 더 좋은 성능을 낸다.
- Tabular Data는 정형데이터를 말한다. 즉 df로 표현할 수 있는 데이터를 말한다.
딥러닝
- Feature의 양(노드의 수)과 수준(깊이)가 적절히 결정되면, 딥러닝 모델이 새로운 Feature를 추출해 낸다.
- (현재 우리가 배운 수준에서는) 모델에서 어떤 feature가 생성되고 어떻게 학습되는지 알기 어렵다.
- 이미지 데이터, 텍스트 데이터, 음성 데이터 등 사람이 Feature를 뽑아내기 어려운 데이터에서ML보다 훨씬 우수한 성능을 보인다.
MNIST
- MNIST는 0~9의 숫자가 손글씨로 쓰인 28x28 이미지가 담긴 대형 데이터셋이다.
- 이 손글씨를 딥러닝을 통해 분류하는 것이 딥러닝, 특히 이미지 처리 분야에서 Hello World 쯤 된다고 할 수 있다.
ANN(인공 신경망)을 이용한 MNIST 분류
데이터 전처리
- reshape
- 입력된 이미지 데이터는 28x28의 2차원이지만, 현재 우리가 배운 것은 1차원 shape을 쓰기 때문에 1차원 array로 변환해주어야 한다.
- numpy의 reshape 함수를 사용한다.
- Minmax scaling
- 클래스가 0~9의 10개인 멀티 클래스 분류 문제이므로, 선형 회귀를 위해 데이터 범위를 0~1로 변환하는 정규화를 거친다.
# 직접 수식을 입력
train_x = (train_x - min_n) / (max_n - min_n)
test_x = (test_x - min_n) / (max_n - min_n)- One-Hot Encoding
- 현재 target이 0~9의 범주값이므로, 각각 별개의 노드로 쪼개기 위해 One-Hot Encoding을 한다.
- tenserflow의 to_categorical 함수를 사용한다.
모델링
- 지금까지 배운대로 하면 된다.
# Sequential API
# 1. 이전 모델 청소
keras.backend.clear_session()
# 2. 모델 선언
model = keras.models.Sequential()
# 3. 모델 레이어 쌓기
model.add( keras.layers.Input(shape=(784, )) )
model.add( keras.layers.Dense(256, activation='relu') )
model.add( keras.layers.Dense(256, activation='relu') )
model.add( keras.layers.Dense(10, activation='softmax') )
# 4. 컴파일
model.compile(loss = keras.losses.binary_crossentropy,
metrics = ['accuracy'],
optimizer = 'adam')
# 요약
model.summary()Early Stopping
- Early Stopping은 과적합을 막기 위해 학습이 잘 진행되지 않을 경우 정해진 학습을 조기에 종료하는 방법론이다.
- epochs 값을 많이 주더라도, 적절한 epoch에서 학습을 종료하는 역할을 한다.
es = EarlyStopping(monitor='val_loss',
min_delta=0,
patience=5,
verbose=1,
restore_best_weights=True) # 가장중요한 옵션monitor: 관측 대상 지정. 이 경우에는 검증용 데이터에 대한 loss이다.min_delta: Threshold. 이전 epoch의 val_loss보다, 현재 epoch의 val_loss가 min_delta보다 많이 감소해야 학습이 이루어졌다고 판단한다.- 예시처럼 0일 경우, val_loss가 증가하지만 않으면(성능이 낮아지지만 않았다면) 학습이 된 것으로 판단한다.
patience: min_delta 를 만족하지 못한 epoch를 몇 번이나 참을지 설정한다.restore_best_weights: True로 설정하면, 전체 epoch 중 가장 학습 성능이 좋았던 epoch의 가중치 값을 모델이 사용하도록 한다.
위의 예시에서는 val_loss가 가장 낮은 epoch가 선택된다.
fitting
model.fit(train_x, train_y, validation_split=0.2, callbacks=[es],
verbose=1, epochs=50)validation_split: 학습용 데이터와 검증용 데이터를 나누는 옵션이다. val_loss를 모니터링하기 위해 꼭 필요하다.callbacks: 앞서 선언한 EarlyStopping을 현재 모델에 적용하겠다고 선언한 것이다.
소감

-
솔직히 무언가 굉장히 많이 듣고 필기도 많이 했지만 정작 이해가 되거나 딥러닝에 대해 크게 배운 것은 없는 느낌이다.
-
다행히 수업 중 이해가 안가는 것은 틈틈히 정리해 두었고, 이제 찾아서 따로 배우는 일만 남았다.
-
딥러닝 공부를 위해 좋은 강의와 책들도 많이 추천 받았으니 포기하지 말고 꼭 배울 수 있도록 하자.
