
오늘 배운 것
SHAP (SHapley Additive Explanation)
Shapley Value (기여도 점수)
- PFI는 전체 모델에서 각 Feature의 중요도를 수치화한 것이다.
- SHAP는 모델이 예측한 예측값 하나하나에 대해서 변수가 예측값에 얼마나 기여했는지를 나타내는 수치이다.
예시
서울시 집값을 예측한 모델이 있다고 하자. 전체 예측값의 평균은 10억인데, 어떤 데이터에 대해 모델은 7억이라는 가격을 예측했다.
- 위치 = 은평구가 예측값을 -2억만큼 감소 시켰다.
- 집 종류 = 아파트가 예측값을 +3억만큼 증가 시켰다.
- 평 수 = 18평이 예측값을 -3억만큼 감소 시켰다.
- 층수 = 3층이 예측값을 -1억만큼 감소 시켰다.
이런 식으로 개개의 예측값에 각 변수가 어떻게 기여했는지를 수치화 한 것이다.
계산 원리

- 먼저 구하고자하는 변수 i를 설정한다.
- i를 제외한 나머지 변수들로 가능한 모든 조합을 구성한다.
이 때 조합은 2^(n-1)개가 된다. - 각 조합별로 i를 포함하여 계산한 예측값을 구한다.
- 그 뒤 각 조합별로 i를 빼고 계산한 예측값을 구한다.
- 3의 결과와 4의 결과의 차이를 구한 뒤, 여기에 가중치를 곱하여 가중치 평균을 구한다.
시각화
shap 라이브러리
- shap 라이브러리를 통해 shapley value를 계산 및 시각화할 수 있다.
- 각 알고리즘 별로 알맞는 함수를 사용해야 한다.
- Tree 기반 : TreeExplainer
- Deep Learning : DeepExplainer
- SVM : KernelExplainer
- 그 외 알고리즘 : Explainer (sklearn, kears 기반 모델 외 사용시 정확하게 작동하지 않을 수 있다)
- Explainer 실행 결과로 학습데이터와 동일한 shape의 데이터가 반환되는데, 여기에는 실제 데이터값 대신 기여한 정도가 저장되어있다.
그래프
force_plot - 개별 데이터
summary_plot
force_plot - 데이터 전체
dependence_plot
비즈니스 관점의 모델 평가
- 우리가 모델을 만드는 본질적인 이유는 비즈니스 문제 해결이다. 그리고 모든 비즈니스 문제는 비용과 직결되어 있다.
- 비즈니스 관점의 모델 평가는 바로 수익성을 통해 이루어져야 한다.
- 이를 위해서는 모델의 평가 결과가 비즈니스에 어떤 영향을 미치는지 비용적으로 수치화해야한다.
기술 지표
- 회귀 : SSE, MSE, RMSE, MAE, MPAE
- 분류 : Accuracy, Recall, Precision, F1 Score
개발자 간에는 용이한 의사소통이 가능하나 비즈니스 문제를 나타내기에는 적합하지 않다.
비즈니스 지표
- 매출액, 이익, 비용, 회전율 등
분류 문제
| 예측-> | Negative | Positive |
|---|---|---|
| 실제 N | 0.3 | 0.1 |
| 실제 P | 0.1 | 0.5 |
- 다음과 같은 형태의 이진 혼동행렬이 있을 때 각각의 시나리오에 대해 얻을 수 있는 이익 또는 손해를 수치화할 수 있다.
- 예를들어 P/N을 대출을 잘 갚는 사람/대출을 갚지 못하는 사람이라 했을때
- P를 잘 예측했다면 이자 수익을 얻을 수 있다.
- P인데 N이라 예측하여 대출을 해주지 않았다면 기회 손실이 발생한다.
- N인데 P라 예측하여 대출을 해줄 경우 연체 등으로 인한 손실이 발생한다.
- 이러한 것을 수익률로 나타낸다고 했을 때 아래와 같이 나타낼 수 있다.
| 예측-> | Negative | Positive |
|---|---|---|
| 실제 N | 0 | -0.10 |
| 실제 P | -0.04 | 0.04 |
- 만약 평균 대출액이 1000만원이라 할 때 혼동행렬끼리 곱하면 다음의 표를 얻을 수 있다.
| 예측-> | Negative | Positive |
|---|---|---|
| 실제 N | 0 | -10 |
| 실제 P | -4 | 20 |
- 합계를 구하면 +6이 되고 이는 모델을 적용했을 때 고객 1명에게 6만원의 수익을 기대할 수 있다는 뜻이다.
회귀 문제
- 회귀 문제의 경우는 조금 더 복잡해진다.
- 간단히 설명하면 예측값 별로 후속 프로세스가 어떻게 이루어질지 시뮬레이션을 하여 어떤 수익/비용이 발생하는지를 따져야 한다.
실습
- 캘리포니아 집값 데이터를 사용할 것이다.
- MedInc median income in block group
- HouseAge median house age in block group
- AveRooms average number of rooms per household
- AveBedrms average number of bedrooms per household
- Population block group population
- AveOccup average number of household members
- Latitude block group latitude
- Longitude block group longitudeFeature Importance
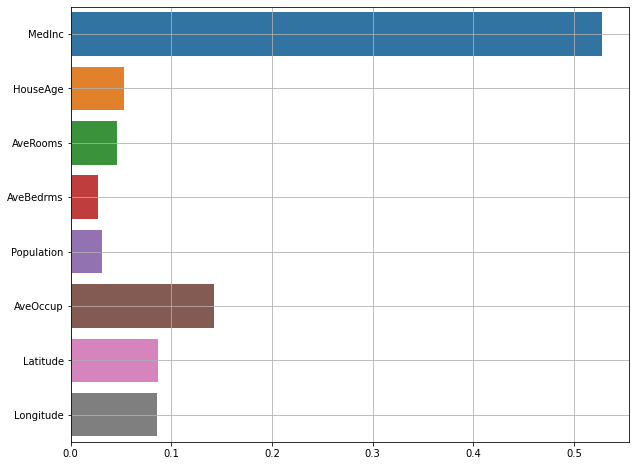
- 각 트리의 정보 이득을 통해 계산한 변수 중요도는 다음과 같다.
- 블록 별 수입의 중앙값인 MedInc의 중요도가 제일 높았다.
- 그 다음으로는 가구 당 인원수가 중요한 변수였다.
PFI
from sklearn.ensemble import RandomForestRegressor
from sklearn.inspection import permutation_importance
# 1. 모델 선언
model = RandomForestRegressor(max_depth = 15)
# 2. 학습
model.fit(x_train, y_train)
# 3. permutation_importance 함수
pfi = permutation_importance(model, x_train, y_train, n_repeats=10, scoring='r2')- permutation_importance 함수에 학습이 완료된 모델, 데이터, 랜덤성 최소화를 위한 반복횟수, 점수 기준을 매개 변수로 전달한다.
- 결과로 변수 중요도의 평균, 표준편차, 전체 중요도가 담긴 딕셔너리가 반환되어 이를 활용해 데이터화 및 시각화를 할 수 있다.
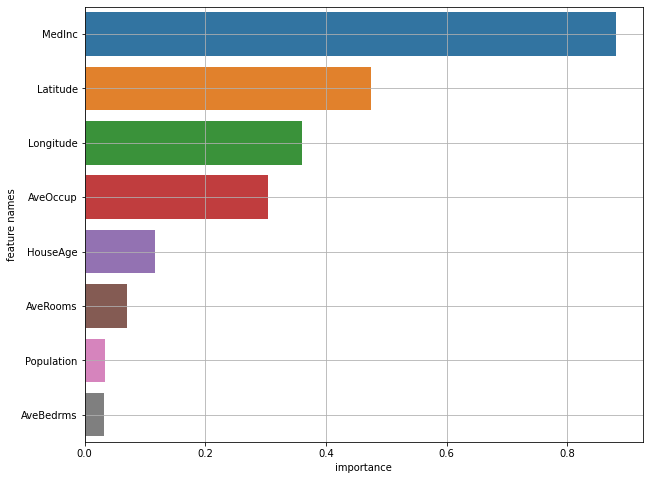
- 블록 별 수입의 중앙값인 MedInc의 중요도가 제일 높았다.
- 또한 지니 불순도에서는 비교적 낮은 중요도를 보였던 위도와 경도가 데이터를 섞었을 때는 성능에 큰 영향을 준 것으로 확인된다.
SHAP
Force Plot (개별데이터)
shap.initjs()
# force_plot(전체평균, shapley_values, input)
shap.force_plot(explainer.expected_value, shap_values[0, :], x_val_df.iloc[0,:])
- 전체 예측값의 평균(base value)은 2.069 (20만 달러)였다.
- 해당 데이터의 예측값은 24.5만달러이다.
- 집 연식의 중앙값은 16년이고, 이것이 예측값을 크게 감소시키는 요인이 되었다.
- 반면 위도, 소득 중앙값, 경도, 가구수 순서로 집값의 예측값을 증가시키는 요인이 되었다.
Summary Plot
shap.summary_plot(shap_values, x_val_df)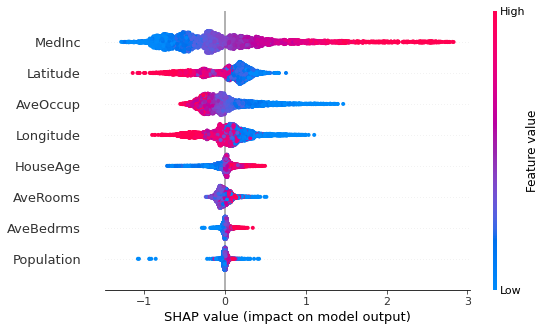
- MedInc : 소득 중앙값이 증가할수록 예측값을 증가하는 요인이 되었다.
또한 증가폭 역시 컸다. - Latitude : 위도가 감소할수록 예측값을 증가하는 요인이 되었다.
상대적으로 위도가 커진다고 해서 예측값의 감소폭이 크지는 않았다. - AveOccup : 가구 구성원이 적을수록 예측값이 증가하는 요인이 되었다.
반면 가구 구성원이 많다고 해서 감소폭이 크지는 않았다. - Population : 블록의 인구수는 예측값에 큰 영향을 주지 않았다. 다만 일부 데이터에서 Population을 기준으로 예측값을 감소시키는데 사용한 것 같다.
