
오늘 배운 것
딥러닝 복습
- 뉴런(노드) 하나는 각각의 feature(요인, 특징)을 나타낸다.
- 하나의 노드는 앞 레이어의 노드로부터 기존에 없던 새로운 feature를 생성한다.
- 새로운 특징이 문제 해결과 연결된 것인지는 장담할 수 없다.
- 노드가 여러개가 모여 한 계층을 이룬 것을 Layer라고 한다.
- 신경망의 아래 계층에 있는 레이어일 수록, 레이어가 깊어진다고 하고 각 레이어에서 추출된 특징들은 이전 레이어보다 더 고수준(high-level)의 특징이다.
- 딥러닝 구조에는 엔지니어의 의도를 담을 수 있다.
- 노드의 수 : 하나의 레이어에서 어느정도의 특징을 추출하기를 바라는지
- 레이어 수 : 어느정도의 계층으로 특징을 추출하기를 바라는지
Dropout
- 학습 과정에서 일정 비율의 노드를 랜덤하게 사용하지 않도록 하는 기법이다.
- Overfitting을 방지해서 보다 general한 모델을 만들기 위해 사용한다.
- general의 의미는 특정 상황에 치우치지 않고, 보다 일반적인 상황에서 두루 성능을 낼 수 있는 모델을 말한다.
- 학습 시 랜덤한 초기값에 의해 학습이 특별히 더 잘된 노드가 생길 수 있는데, 레이어가 깊어져도 다른 노드의 특징이 영향을 주지 못하는 문제가 생길 수 있다. Dropout은 이를 방지하는 효과가 있다.
- 일반적으로 히든 레이어 뒤에만 사용하는 것이 좋다고 알려져 있다.
Batch Normalization
- 딥러닝 학습시 모든 데이터를 한번에 메모리에 올리는 것이 아니라, 미니 배치를 사용해서 배치 단위로 학습을 진행한다.
- 그런데 각 배치별로 데이터의 분포가 급격하게 바뀔 수 있다. 이를 internal covariate shift 현상이라고 한다.
- Batch Normalization은 이를 방지하기 위해 각 미니 배치별로 평균 0, 표준편차 1의 정규화를 진행하는 기법이다.
Computer Vision
목표
- 컴퓨터가 이미지를 이해하게 하는 것
- 이미지에 무엇이 있는가?
- 무엇을 하고 있는 사진인가?
- 사진을 묘사할 수 있는가?
CV의 어려움
경계값 찾기
- 이미지 데이터를 숫자로 변환하는 것은 쉽지만, 연속값을 갖기 때문에 명확한 경계를 알기 어렵다.

만약 하얀 정도를 나타내는 1~100의 척도가 있다고 했을 때, 눈이 90, 동물이 80 정도라고 하자, 이런 경우 경계를 구분하기가 매우 어려울 것이다.
데이터 부족
- 페이페이 리 교수님에 의하면, 3살 어린이는 200밀리 초마다 사진을 한장 씩 찍고 있으며, 이미 수억장의 현실 데이터 사진을 학습했다.
- 반면 모델이 학습할 수 있는 사진은 많아야 수만~수십만 장 수준이다.
- 즉 CV의 문제점은 알고리즘 보다도 학습할 수 있는 데이터가 적기 때문이다. -> 이를 해결하기 위해 라벨링 된 이미지를 확보하는 ImageNet 프로젝트를 진행하였다.
CNN
기존방식 - Fully Connected Layer
- 이미지 데이터를 FC에 Input으로 넣기 위해서는 2D 흑백 이미지(N x N x 1)나 컬러 이미지(N x N x 3)을 1차원 벡터로 변환하는 과정을 거쳐야 했다.
- 이 과정에서 이미지의 구조가 파괴되고, 위치 정보가 손실된다는 단점이 있었다.
- 이러한 문제로 복잡한 이미지 분류 문제에서 성능 상의 한계가 있었다.
CNN의 컨셉
- CNN의 주요 컨셉은 Filter라고 부르는 커널 행렬과, Input의 합성곱을 통해 Input의 shape는 보존하면서, 정보를 요약한 축소된 Feature map을 생성한다는 것이다.
- Filter의 값은 가중치인데, 초기에는 랜덤으로 결정되고 학습을 통해 조정된다.
- 서로 다른 가중치를 갖는 Filter를 n개 사용하면, n개의 새로운 feature map을 생성할 수 있다.
- 이렇게 만들어진 feature map의 레이어를 Convolutional Layer라고 한다.
Convolutional Layer
Convolution 과정은 vdumoulin / conv_arithmetic 깃헙 저장소에 잘 시각화 되어있다.
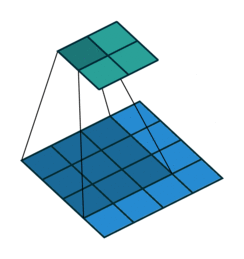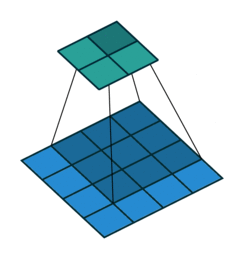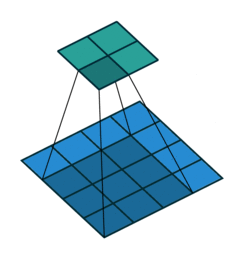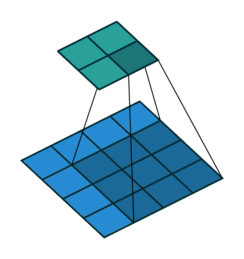
- 위 그림은 4 x 4의 데이터를 3 x 3 필터로 convolution하는 과정이다.
- 네이버 프리코스 공부 당시 작성했던 TIL에서도 다루었다.
Stride
- 필터가 추출을 끝내고 다음 데이터로 이동할 때 shift 간격이다.
- 기본값은 1이며, 추출 후 바로 다음 행/열로 이동한다는 뜻이다.
- stride = 2일 경우 두 칸씩 건너 뛰면서 필터 convolution을 적용한다.
- 일반적인 경우에, shift 간격이 데이터 크기와 맞지 않는다면 학습을 할 수 없다.
단 keras 라이브러리에서는 이러한 경우 빈 공간을 자동으로 채워주기 때문에 학습을 할 수 있다. (원칙상 안된다는 것을 기억하자)
- stride를 사용하는 이유는 파라미터를 줄여 연산을 줄이는 효과가 있다.
Zero Padding
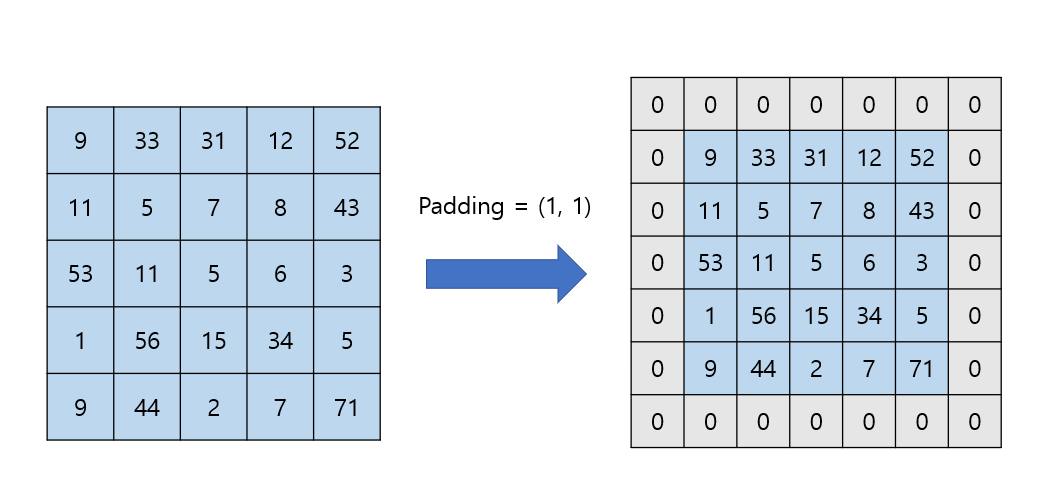
- 0값을 기존 데이터 외곽에 추가하는 것을 Zero padding이라 한다. 보통 padding이라 하면 모두 zero padding을 말한다.
- 효과
- 필터를 거친 후에도 데이터 사이즈를 유지할 수 있다. (same padding)
- 외곽에 있는 정보가 추출되는 횟수가 증가한다.
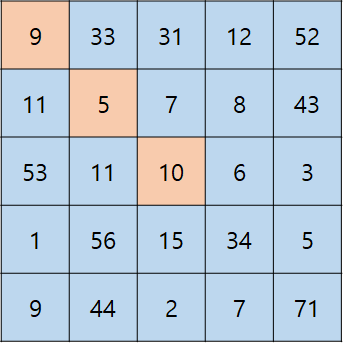
- 5 x 5 행렬에 3 x 3 필터를 적용한다고 했을 때, 주황색 음영 표시에서
- 가장 외곽에 있는 9는 필터가 1번만 지나간다.
- 두번째 외곽에 있는 5는 필터가 4번 지나간다.
- 중앙에 있는 10은 필터가 9번 지나간다.
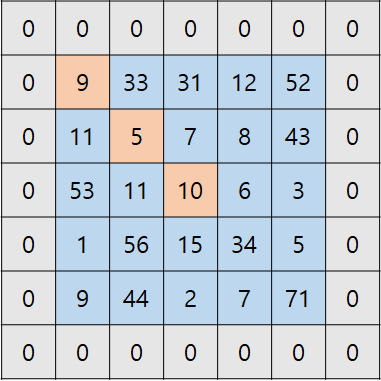
- 패딩을 적용한 경우
- 가장 외곽에 있는 9는 필터가 4번 지나간다.
- 두번째 외곽에 있는 5는 필터가 9번 지나간다.
- 중앙에 있는 10은 필터가 9번 지나간다.
- 이렇게 패딩을 적용하면 외곽에 있는 정보의 추출 횟수가 증가해 정보 손실을 최소화 할 수 있다.
- 위 예시에서 padding = 2를 적용하면 가장 외곽에 있는 9도 9번 추출이 이루어지는데, 이렇게 모든 데이터가 골고루 추출되도록 하는 padding을 fully padding이라 한다.
Pooling Layer
- Pooling Layer는 정보를 축약하여 다운 샘플링하는 기법이다.
- 가장 큰 목적은 depth를 유지한 채로, 데이터 사이즈를 줄여 연산량을 줄이는 것이다.
Average pooling
- 원본 데이터의 평균값으로 축약을 진행한다.
- CNN 초창기 모델에서 많이 쓰였던 방식이다.
Max pooling
- 원본 데이터에서 가장 큰 값만을 남기고 나머지를 제거하여 축약한다.
- 여기서 가장 큰 값은 가장 영향을 많이 주는 값이라는 의미이다.
- 신호가 강한것만을 가져오는 relu함수와 비슷한 맥락이다.
- 현재 CNN은 대부분 max pooling을 사용한다.
코드 실습
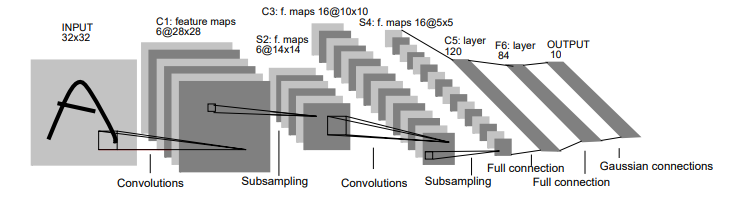
- 위 모델 구조는 CNN 개념을 최초로 제시한 Yann LeCun이 개발한 모델이다.
- 그림에서 말하는 Subsampling 이 pooling layer를 말한다.
- 위 모델을 keras의 sequential API로 재현하면 다음과 같다.
# Sequential API
# 1. 세션 클리어
clear_session()
# 2. 모델 발판 생성
model = Sequential()
# 3. 모델 레이어 조립
model.add( Input(shape=(28, 28, 1)) )
model.add( Conv2D(filters=6, kernel_size=(5, 5), strides=(1, 1), padding='valid', activation='relu') )
model.add( AvgPool2D(pool_size=(2,2)) ) # pooling filter 사이즈
model.add( Conv2D(filters=16, # 제작하려는 Feature map의 수
kernel_size=(5, 5), # 필터의 사이즈
strides=(1, 1), # strides
padding='valid', # padding의 종류 (valid는 패딩을 주지 않는다는 것을 의미)
activation='relu') ) # activation 함수
model.add( AvgPool2D(pool_size=(2,2)) ) # pooling filter 사이즈
model.add( Flatten() )
model.add( Dense(128, activation='relu') )
model.add( Dense(84, activation='relu') )
model.add( Dense(10, activation='softmax') )
# 4. 컴파일
model.compile(loss=keras.losses.sparse_categorical_crossentropy, # y 원핫 인코딩 없이 적용가능
metrics=['accuracy'],
optimizer='adam')
# 요약
model.summary()- 기존 FC 신경망 모델에서는 MNIST 문제의 정확도가 96% 정도에서 상승하지 않았는데
- LeNet을 적용한 결과 약 98%의 테스트 정확도를 얻을 수 있었다.
