
오늘 배운 것
모델 저장 & 불러오기
- 매번 모델 구조를 새로 만들고 학습하는 것은 매우 비효율적이므로, 성능이 좋은 모델을 저장하고, 재사용하는 것이 필요하다.
저장
ModelCheckpoint
from tensorflow.keras.callbacks import ModelCheckpoint
mcp = ModelCheckpoint(filepath='path/file_name.h5',
monitor='val_loss',
verbose=1,
save_best_only=True,
save_weights_only=False
)- 모델 피팅 시 callbacks 함수로 선언할 수 있다.
- filepath : 모델을 저장할 경로와 파일명, 확장자를 지정한다. 케라스에서는
.h5를 사용할 것을 권장하고 있다. - monitor : 가장 좋은 모델임을 판단할 지표를 지정한다. 기본값은
val_loss이다. - verbose : 모델이 저장될 때마다 저장을 하였음을 출력한다.
- save_best_only : True - 모델 성능이 개선될 때마다 저장한다. False - 매 에포크마다 저장한다.
- save_weights_only : False - 모델의 구조와 가중치를 모두 저장한다.
model.save() 또는 save_model
- 현재 모델의 구조와 파라미터를 저장할 수 있다.
model.save('my_first_save.h5')- 경로명 및 파일명을 입력하면 현재 모델의 구조와 가중치 정보를 저장한다.
불러오기
load_model
from tensorflow.keras.models import load_model
model = load_model('./dir/file_name.h5')- 지정한 경로명/파일명의 모델을 불러온다.
구글 코랩과 구글 드라이브 연동
연동하기
- 코랩을 사용할 경우 이런 모델들을 저장하고 불러오기 위해서는 구글 드라이브에 접근하여 가져올 수 있어야 한다.
- 모델 뿐 아니라 학습에 사용할 이미지 데이터 등을 처리하기 위해서도 드라이브에 접근할 수 있어야 한다.
from google.colab import drive
drive.mount('/content/drive')-
위 코드를 실행하면 연결 절차가 실행된다.
-
내 드라이브 경로 :
/content/drive/MyDrive/
glob
- glob은 많은 파일을 다룰 때 유용한 파이썬의 내장 라이브러리 이다.
glob.glob함수를 통해 사용자가 입력한 규칙에 맞는 파일을 가져와 경로명을 리스트로 반환한다.
# 내 드라이브/my_data/images에 있는 모든 파일을 가져온다.
files = glob.glob('/content/drive/MyDrive/my_data/images/*')keras를 통한 이미지 처리
- keras의 이미지 모듈을 이용하여 이미지 처리를 할 수 있다.
tensorflow.keras.preprocessing.image.load_image()함수에 이미지 경로를 인자로 넣으면 PIL Image instance를 반환한다.- 이미지 크기, grayscale 처리, 색상 모드 등을 지정할 수 있다.
Pre-trained Model
- 직접 모델을 선언하고, 최적의 레이어, 노드 수를 찾아가며 모델링을 하는 것은 사실 매우 어려운 일이다.
- 이미 다양한 연구를 바탕으로 이미 성능까지 검증된 학습된 모델(pretrained model)을 불러와서 사용할 수 있다.
- pretrained model을 불러오려면 제공되는 API를 통해 오픈소스 모델을 들고오거나, 직접 모델을 다운 받아서 들고오는 등, 다양한 방법이 있다.
Transfer Learning
- 가져온 모델과 내가 풀고자하는 모델의 문제가 유사하면 큰 상관이 없겠지만, 보통은 Input shape, Ouput shape가 다르거나, 해결해야하는 문제의 종류가 다른 경우가 있다.
- 이 경우 모델을 그대로 사용하면 높은 성능을 기대할 수 없으므로, 모델 레이어의 일부 또는 전체를 재학습하는 과정을 거친다.
- 일반적으로 모델 레이어의 일부를 재학습 할 경우, low-level(깊이가 얕은 쪽) 레이어는 기존에 학습된 가중치를 그대로 사용하고, high-level(깊이가 깊은 쪽) 레이어의 가중치만을 업데이트 한다.
for idx, layer in enumerate(model.layers) :
if idx < 200 :
layer.trainable = False # 200층 미만의 low-level은 학습 X
else :
layer.trainable = True # 200층 이상의 high-level은 학습ReduceLROnPleateau
- 모델의 학습이 진행되지 않을 때, learning rate를 조절하여 모델 성능의 개선을 꽤하는 callbacks 함수이다.
from tensorflow.keras.callbacks import ReduceLROnPlateau
lr_reduction = ReduceLROnPlateau(monitor='val_loss',
patience=3,
verbose=1,
factor=0.5,
min_lr=0.000001)- monitor : 학습 진행 여부를 판단하는 지표이다. 기본값은
val_loss이다. - patience : 학습이 진행되지 않을 때 몇 번까지 지켜 볼 것인지를 나타낸다. 위의 예시에서 만약 3번 연속 val_loss가 감소하지 않는다면 lr을 조정한다.
- verbose : learning rate를 조절할 때마다 조절 정보를 출력한다.
- factor : learning rate를 조절할 때 기존값에 곱하는 수이다. 위의 예시에서는 3번 연속 val_loss가 감소하지 않으면 기존 learning rate에 0.5를 곱한다.
- min_lr : learning rate의 하한치를 지정한다.
Global Averagepool (GAP)
- GAP는 CNN+FC 조합에서 FC를 없애 연산량을 줄이기 위한 Pooling 기법이다.
- (h * w * channel) 형태의 feature map을 (channel, ) 형태로 바꾼다.
- 즉 h * w 전체 벡터값의 평균을 내어 하나의 값으로 요약하는 것이다.
- Pooling 후 1차원 벡터가 되기 때문에 FC Layer를 거치지 않고 그대로 output을 출력할 수 있다.
- 또한 파라미터가 폭발적으로 증가하지 않기 때문에 과대적합을 예방한다.
- 일반적으로 pretrained model을 불러와 사용할 때, 출력의 shape를 바꾸어야 한다면 GAP를 거치고, Dense로 출력 shape를 맞추어 준다.
Object Detection
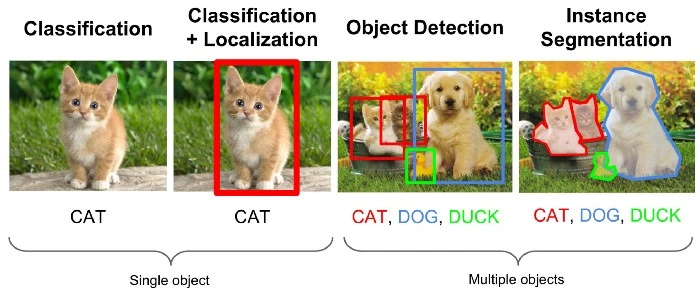
- Object detection은 기존에 이미지를 분류하는 것에 더해, object를 감싸는 bounding box를 찾아내는 문제이다.
- 다중 분류 및 회귀(bounding box 예측) 두가지 문제를 종합한 형태이다.
대표적인 데이터셋
- Pascal VOC Dataset
- 2005~2012년에 개최된 이미지 object detection 경진 대회의 데이터셋
- 2007년, 2012년 데이터셋이 벤치마크 데이터셋으로 많이 쓰인다.
- mAP(mean Average Precision)라는 성능 점수를 사용한다. -> Precision 을 기반으로 성능 예측
- COCO Dataset
- object의 크기 및 위치가 다양함
- 한 이미지 안에 여러 object가 존재 (non-iconic image)
- mAP를 사용하고, IoU를 유동적으로 적용(0.5 ~ 0.95)
- IoU(Inter section of Union) = 교집합 넓이/합집합 넓이
- 실제 정답(label)의 사각형과, 예측 경계의 사각형 사이의 IoU를 측정함. 1에 가까울 수록 성능 점수가 높다.
- IoU가 0.5 이상일 때 object를 잘 인식한 것 → IoU가 0.55 이상일 때 object를 잘 인식한 것 … → 이렇게 IoU 하한을 늘려나가면서 성능 평가 (IoU 제한이 클 수록 mAP가 감소)
Two Stage Detector
- CNN 기반의 detection
- Featrue extractor를 거친 후, 먼저 object localization을 진행, 이것이 끝나면 오브젝트 내에서 분류
2. One Stage Detector
- object localization + classification을 한번에 진행
- 투스테이지에 비해 인식률이 낮지만 최근에 많이 발전하여 해당 모델을 많이 사용
