
오늘 배운 것
Object Detection
Object Detection 핵심 원리
1. Bounding Box
- 하나의 오브젝트가 포함되어 있는 최소크기의 box
- 구성요소 : (x, y) : 좌표 + (w, h) : 크기 → 위치 정보
- 모델이 구하는 Bouding box 예측 값은 예측값과 정답(x, y, w, h)의 오차(loss)를 최소화 하는 것. 즉 회귀 문제
2. Class Classification
- Bounding Box에 있는 오브젝트가 어떤 클래스에 속하는지 분류하는 것
3. Confidence score
- Bounding Box 내부에 object가 정말로 있는가에 대한 확신의 정도 (정확한 정의는 모델마다 조금씩 다르다)
- YOLO 모델에서 Confidence score를 다음과 같이 정의한다.
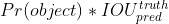
- 덧붙여 YOLO 모델에서는 class-specific confidence score라는 지표를 사용하는데, 박스안에 object가 있을 때 class가 존재할 조건부 확률에 confidence score를 곱한 것으로 정의한다.
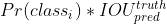
Head & Backbone
Backbone
- 이미지로 부터 새로운 특징인 Feature map을 생성하는 부분을 담당하는 구역을 말한다.
- 모델의 Conv layer에 해당하며, Conv layer는 데이터의 위치 정보를 보존하면서 기존에 없던 새로운 특징인 Feature map을 추출한다.
- Pretrained 된 모델을 그대로 사용하거나, 풀고자 하는 데이터 종류에 맞게 재학습(fine tuning)을 거친다.
Head
- feature map으로 부터 회귀 및 분류 검출 및 출력이 이루어지는 부분이다. output layer의 구조는 다음과 같다.
- bounding box 정보에 해당하는 x, y, w, h
- one-hot vector 형태의 k개 클래스
- 1개의 background (YOLO에서는 confidence score)
- Flatten, Fully Connected layer 부분을 말하며, 출력 shape에 맞게 적절히 수정하여 사용한다.
Neck
- Neck은 Backbone과 Head를 연결하는 역할을 한다.
- 주로 feature map을 정제 및 재구성하여 feature map을 조금 더 정교하게 조정한다.
- 다양한 neck 모델이 있으나 이번 과정에서는 자세히 다루지 않는다.
NMS (Non-Maximum Suppression)
- 대다수의 object detection 알고리즘은 object 위치 주변에 여러개의 bounding box를 만든다.
때문에 같은 object를 가리키는 박스가 중복되지 않도록, 하나만 선택하고 다른 박스를 제거하는 과정아 NMS 이다.
YOLO의 NMS
- YOLO는 이미지를 SxS의 그리드로 나누어 각 셀에 대해 bounding box를 구하는 알고리즘으로 일반적인 방식과 조금 다르다.
- YOLO에서 각 셀의 output은 [conf_score, x, y, h, w]의 형태로 구성된다.
- 각 셀마다
conf_thres보다 낮은 conf_score를 갖는 박스를 제거한다. - 남아있는 것 중 conf_socre가 가장 높은 박스를 선택한다.
- 선택된 박스를 기준으로 남아있는 박스의 IoU값이
iou_thres보다 높다면 제거한다. - 남아있는 박스 중 그 다음으로 높은 박스를 고르고 위 과정을 반복한다.
Anchor box
- NMS에서 bounding box를 제거할 때는 클래스를 고려하지 않으므로, 자칫하면 서로 다른 class를 가리키는 bounding box를 제거해버릴 수 있다.
- 이를 해결하기 위해 나온 방법이 Anchor box이다.
- 각 모델별로 사전 정의된 모양(정사각형이거나 가로로 길쭉하거나 등)의 anchor box가 존재하며, object detection을 할 때 object와 anchor box를 각각 대입하여 IoU가 가장 높은 anchor box로 detecting 한다.
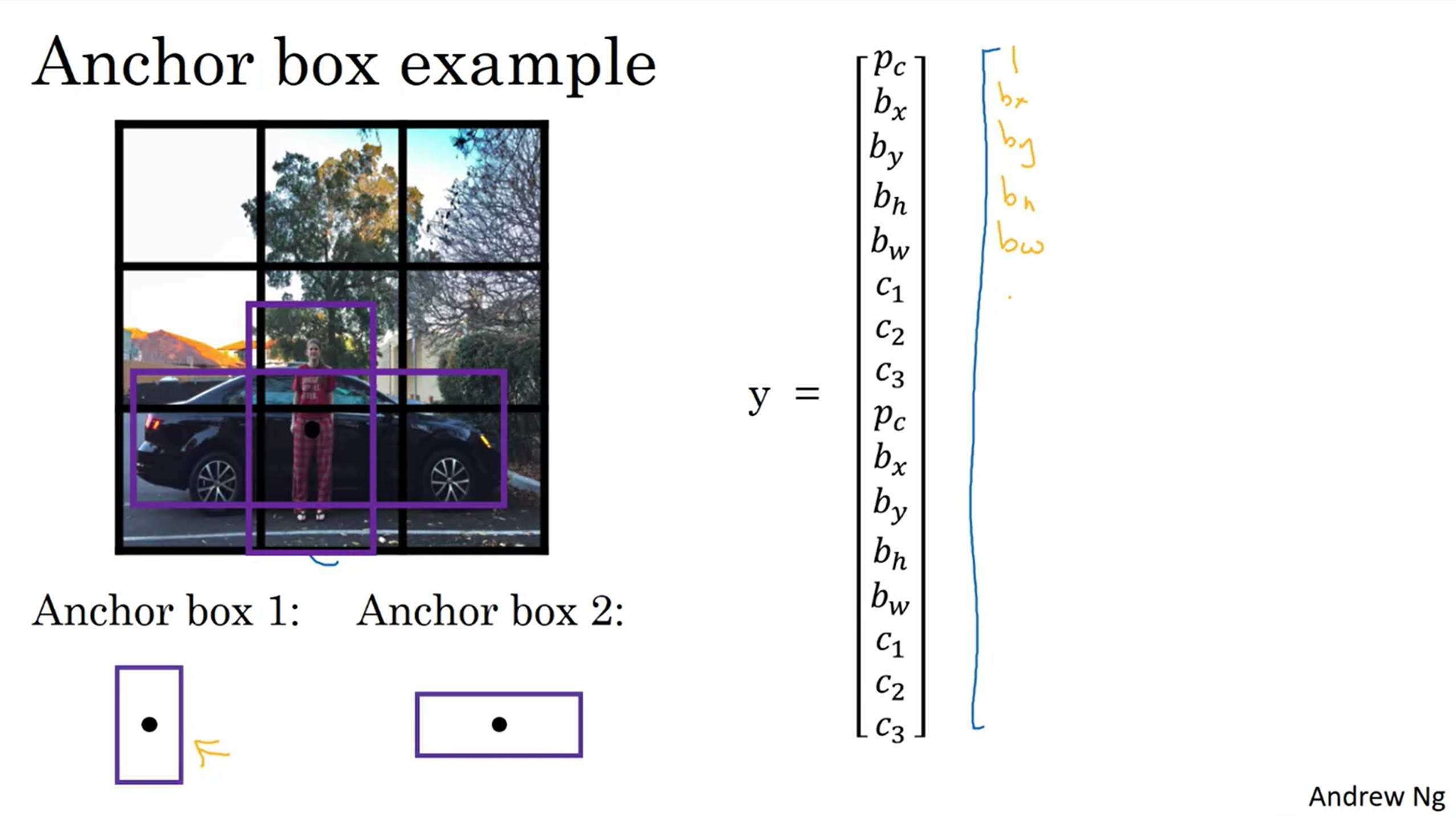
- 위의 예시에서는 가로로 길쭉한 형태인 car와 세로로 길쭉한 형태인 person 2개가 anchor box에 탐지되었다.
- 이 경우 원래 셀이 출력할 vector에서 앵커박스에 해당하는 벡터 2개를 이어붙인 형태가 된다.
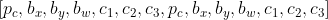
- detecting 시에는 IoU를 계산하여 높은 IoU를 갖는 anchor box 자리에 object를 할당한다.
Object Detection Metrics
IoU (Intersection over Union)
- 두 사각형 박스가 얼마나 겹치는지 나타내는 지표이다.
- 두 사각형 간의 교집합 영역을 합집합 영역으로 나눈 것이다.
- 두 사각형이 완전히 겹친다면 IoU값은 1이 된다.
- 두 사각형이 하나도 겹치지 않는다면 IoU값은 0이 된다.
Precision-Recall Curve

- Precision : 예측 P 중에서 실제 P일 확률 (TP / FP + TP)
- Recall : 실제 P 중에서 예측에 성공했을 확률 (TP / FN + TP)
- 이미지 분류 문제에서 precision과 recall은 trade-off 관계에 있다.
- conf-thres를 낮게 지정할수록 실제 object를 잘 찾아 냄 (Recall ↑)
- conf-thres를 낮게 지정할수록 object가 아닌 것까지 탐지함 (Precision ↓)

conf-thres = 0.3
dog를 더 많이 탐지했지만(recall 증가), teddy-bear로 잘못 탐지한 경우도 있다. (teddy-bear에 대한 precision 감소)

conf-thres = 0.45
dog를 적제 탐지했지만(recall 감소), 오탐지가 사라졌다 (precision 증가)
mAP
- recall과 precision의 관계를 그래프로 나타냈을 때, P-R curve라는 곡선을 그리게 된다.
- 이 곡선의 적분 범위를 area under P-R curve(AP)라고 하는데, 각 클래스별 AP를 구하여 평균을 낸 것을 mAP(mean AP)라고 한다.
- 이 mAP를 모델의 성능 평가 지표로 사용하며, 높을 수록 좋은 성능을 의미한다.
