
무엇을 했나?
tensorflow.keras를 사용한 모델링
- 직접 레이어를 설계하는 것도 좋았을 것 같지만, 레이어 하나하나에 의미를 담기에는 아직 지식이 부족하고, 무작정 쌓기에는 의미도 없을 것 같았다. 구조를 보는 방법을 조금이라도 익히기 위해 저명한 모델을 직접 구축하기로 하였다.
AlexNet (mini ver)
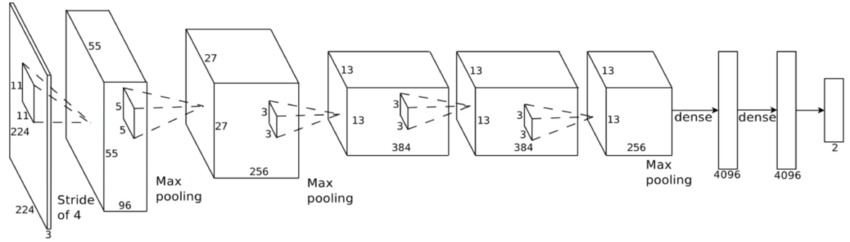
Glomerulus Classification with Convolutional Neural Networks
- AlexNet은 2012년 이미지넷 대회는 ILSVRC에서 우승을 하여, CNN 부흥에 아주 큰 역할을 한 모델이다.
- 원본은 레이어를 둘로 나누어 병렬처리를 하도록 하였으나, 이를 하나로 간소화한 구조를 짰다.
# 1. 세션 클리어
clear_session()
# 2. 레이어 연결
il = Input(shape=(280, 280, 3))
# 280 -> 45
hl = ZeroPadding2D(padding=(3,3))(il)
hl = Conv2D(filters=96,
kernel_size=13,
strides=(3,3),
activation='relu')(hl)
hl = MaxPool2D(pool_size=(3, 3),
strides=(2, 2))(hl)
# 45 -> 22
hl = Conv2D(filters=256,
kernel_size=5,
strides=(1,1),
padding='same',
activation='relu')(hl)
hl = MaxPool2D(pool_size=(3, 3),
strides=(2, 2))(hl)
# 22 -> 11
hl = Conv2D(filters=384,
kernel_size=3,
strides=(1,1),
padding='same',
activation='relu')(hl)
hl = Conv2D(filters=384,
kernel_size=3,
strides=(1,1),
padding='same',
activation='relu')(hl)
hl = Conv2D(filters=256,
kernel_size=3,
strides=(1,1),
padding='same',
activation='relu')(hl)
hl = MaxPool2D(pool_size=(2, 2))(hl)
hl = Flatten()(hl)
hl = Dense(128, activation='relu')(hl)
hl = Dense(128, activation='relu')(hl)
ol = Dense(1, activation='sigmoid')(hl)
# 3. 모델 선언
model = Model(il, ol)
# 4. 컴파일
model.compile(loss=keras.losses.binary_crossentropy,
metrics=['accuracy'],
optimizer='adam')
# 요약
model.summary()
"""
Total params: 7,742,721
Trainable params: 7,742,721
Non-trainable params: 0
"""- Input이 224가 아닌, 280이기 때문에 다소 뒤틀린? 모델 구조가 만들어졌다.
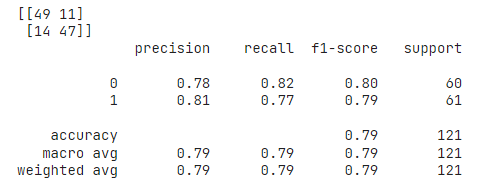
- 주어진 데이터에 대한 예상성능은 위와 같았다.
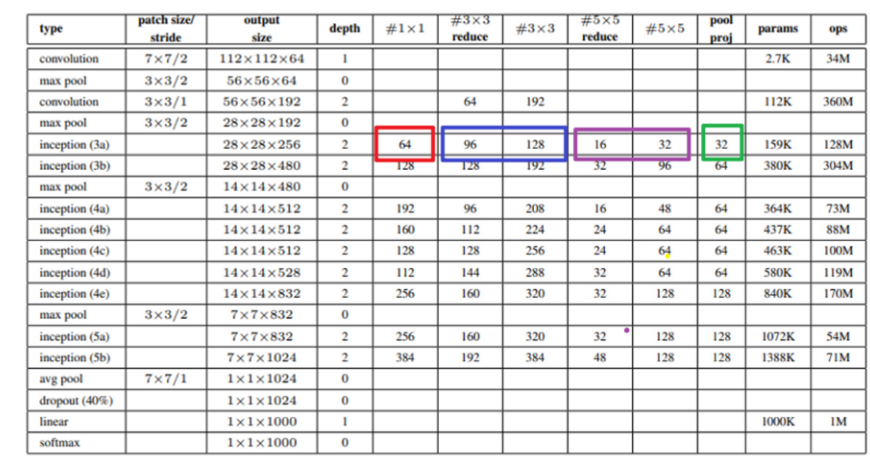
GoogLeNet
- GoogLeNet은 2014년 ILSVRC에서 우승하였다.
- GoogLeNet만의 차이점은 바로 레이어를 매우 깊게 쌓았다는 것이다. 일반적으로 딥러닝 모델의 성능은 레이어가 깊을수록 증가하는데, 이로인해 연산량이 증가한다는 것이 기존의 문제점이었다.
- 하지만 GoogLeNet은 Inception이라는 모듈을 이용해 연산량(또는 파라미터)를 크게 늘리지 않으면서 이를 해결하였다.
주요 컨셉
- 1x1 Convolution으로 기존 Feature map 구조를 유지하면서 채널 수를 줄이는 것으로 파라미터수를 감소시켰다.
-
1x1, 3x3, 5x5 convolution, 3x3 max pooling으로 구성된 inception 모듈을 이용하였다. 서로 다른 크기의 필터를 통해 다른 scale의 필터를 추출하기 위함이다.
일반적으로 3x3, 5x5 필터는 모델의 연산량을 크게 늘리지만, 1x1 Convolution으로 채널을 축소함으로써 연산량을 대폭 감소시켰다는 것이 특징이다. -
마지막으로 Auxiliary classifier인데, Back propagation 시 중간에 합류하여 원래의 결과를 변환시켜, 미분값이 0으로 수렴하는 문제를 막아주는 역할을 한다.
- 원래는 학습시에만 이를 적용하고, 테스트 시에는 제외해야했지만 이번 실습 중에는 구현하지 못했다.
# Inception 하나의 구조
def inception(hl, filters_1x1, filters_3x3_red, filters_3x3, filters_5x5_red, filters_5x5, filters_pool):
hl_1 = Conv2D(filters=filters_1x1,
kernel_size=(1, 1),
padding='same',
strides=(1, 1),
activation='relu')(hl)
hl_2 = Conv2D(filters=filters_3x3_red,
kernel_size=(1, 1),
padding='same',
strides=(1, 1),
activation='relu')(hl)
hl_2 = Conv2D(filters=filters_3x3,
kernel_size=(3, 3),
padding='same',
strides=(1, 1),
activation='relu')(hl_2)
hl_3 = Conv2D(filters=filters_5x5_red,
kernel_size=(1, 1),
padding='same',
strides=(1, 1),
activation='relu')(hl)
hl_3 = Conv2D(filters=filters_5x5,
kernel_size=(5, 5),
padding='same',
strides=(1, 1),
activation='relu')(hl_3)
hl_4 = MaxPool2D(pool_size=(3, 3),
strides=(1, 1),
padding='same')(hl)
hl_4 = Conv2D(filters=filters_pool,
kernel_size=(1, 1),
padding='same',
strides=(1, 1),
activation='relu')(hl_4)
return Concatenate()([hl_1, hl_2, hl_3, hl_4])
"""
Total params: 11,560,835
Trainable params: 11,560,835
Non-trainable params: 0
"""
- 위 코드는 인셉션 하나의 구조이다.
- inception 3a 레이어를 쌓으러면
inception(hl, 64, 96, 128, 16, 32, 32)로 선언할 수 있다.
- inception 3a 레이어를 쌓으러면
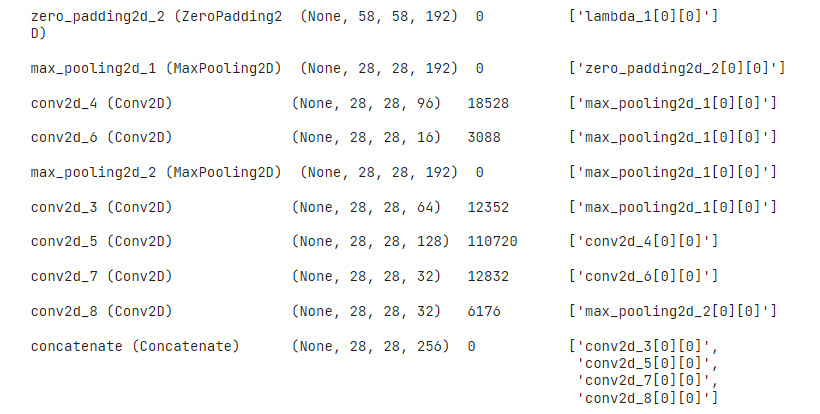
- 따로 name을 선언하지 않아 다소 지저분하지만, Inception 3a에 해당하는 층이다.
- 파라미터를 전부 더하면 164K로 159K에 근접한다. (Input이 224가 아닌 280이기 때문에 다소 차이가 있다)
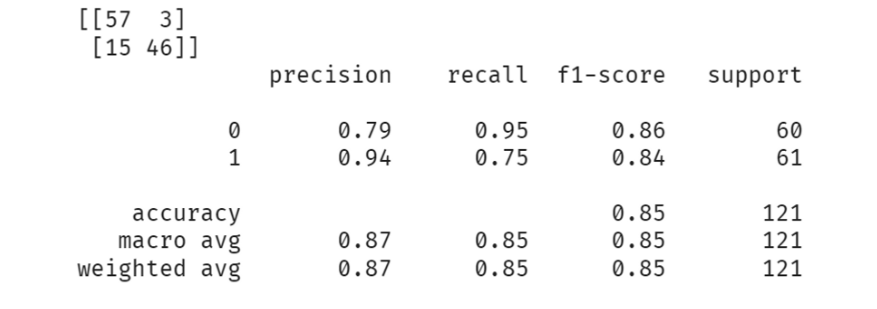
- 예측 성능은 다음과 같았다. 경우에 따라 다르지만 0.9 이상의 예측 성능을 보이기도 하였다.
2. Pretrained Model
- 우리가 학습에 사용할 수 있는 이미지가 충분하다면 더할나위 없이 좋지만, 일반적으로 학습에 사용할 수 있는 데이터는 턱없이 부족하다.
- 이럴 때 대용량의 데이터셋(ImageNet, CIFAR-1000 등)을 통해 가중치가 학습된 모델을 그대로 가져와 사용하는 것이 좋은 대안이 될 수 있다.
Transfer learning
- 가져온 모델이 우리가 풀려는 문제와 정확히 맞아 떨어지지 않기 때문에, 가져온 모델을 우리 문제에 맞게 재학습시키는 과정이 필요하다.
- 크게 4가지 경우로 나눌 수 있다.
1. 학습 데이터가 충분하고, 모델과 우리의 문제가 비슷한 경우
- 가장 이상적인 경우로, 가져온 모델을 그대로 사용하거나, 일부만 학습시키거나, 전부 학습시키는 등 할 수 있는 모든 시도가 가능하다.
2. 학습 데이터는 적지만, 모델과 우리의 문제가 비슷한 경우
- Feature map을 추출하는 Backbone(Conv Layer) 부분의 가중치는 그대로 사용하고, 우리 문제에 맞도록 말단 레이어를 추가하여 이부분에 대해 학습을 진행할 수 있다.
3. 학습 데이터는 충분하지만, 모델과 우리 문제가 많이 다른 경우
- 학습데이터가 충분하다면, 모델의 구조만 유지한채 모든 가중치를 업데이트 할 수 있다.
4. 학습 데이터도 부족하고, 모델과 우리 문제가 많이 다른 경우
- 가장 좋지 않은 경우로, 섣불리 학습을 진행하면 과적합 발생의 우려가 크다. 때문에 Input과 가까운 backbone의 일부 레이어의 가중치를 그대로 사용하고, 나머지 레이어 및 말단의 가중치에 대해 업데이트를 할 것을 권장한다.
- 특정 epoch 이전/이후로만 업데이트를 하도록 하는 방법도 있다.
- 또한 부족한 데이터 보충을 위해 Data Augmentation 등의 방법을 고려해야한다.
-
이번 실습은 4번에 해당하는 케이스로, Input과 가까운 일부 레이어를 제외하고 나머지 레이어에 대한 학습을 진행했다.
-
레이어를 정교한 방법으로 탐색하고, 나누어야할 것 같지만 우선은 이런 방법도 가능하다는 것 정도를 익히기 위해 임의의 레이어를 기준으로 나누었다.
-
현재 imagenet 데이터 벤치마크 성능에서 우수한 스코어를 기록한 davit 모델을 이용하였다.
!pip install -U keras-cv-attention-models
from keras_cv_attention_models import davit
# Will download and load pretrained imagenet weights.
base_model = davit.DaViT_T(pretrained="imagenet", input_shape=(280, 280, 3), num_classes=0)- 우리가 풀고자하는 모델은 이진 분류이므로 이에 맞도록 말단을 생성했다.
- 연산량 문제로 FC layer를 더 추가하지는 않았다.
from tensorflow.keras.layers import GlobalAveragePooling2D
base_model.trainable = True
# 0. 세션 클리어
clear_session()
# 1. 레이어 연결
il = Input(shape=(280, 280, 3))
hl = base_model(il)
hl = GlobalAveragePooling2D()(hl)
hl = Dropout(0.3)(hl)
ol = Dense(1, activation='sigmoid')(hl)
# 2. 모델 선언
model_vit = Model(il, ol)
# 3. 컴파일
model_vit.compile(loss=keras.losses.binary_crossentropy,
metrics=['accuracy'],
optimizer='adam')
# 요약
model_vit.summary()
"""
=================================================================
Total params: 27,591,937
Trainable params: 27,591,937
Non-trainable params: 0
_________________________________________________________________
"""- 임의의 레이어를 기준으로 골라 학습하지 않을 레이어를 정해주었다.
- 212 -> 168로 학습되는 variables가 감소한 것을 확인할 수 있다.
len(model_vit.trainable_variables)
>>> 212
for idx, layer in enumerate(base_model.layers) :
if idx < 80 :
layer.trainable = False
else :
layer.trainable = True
len(model_vit.trainable_variables)
>>> 168- 모듈에서 모델에 맞는 전처리 함수를 제공해주기 때문에 아주 편하게 전처리가 가능하다.
- 추가로 EarlyStopping과 ReduceLR을 적용하여 학습을 진행했다.
x_train_vit = base_model.preprocess_input(x_train)
x_val_vit = base_model.preprocess_input(x_val)
x_test_vit = base_model.preprocess_input(x_test)
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
es = EarlyStopping(monitor='val_loss',
min_delta=0,
patience=7,
verbose=1,
restore_best_weights=True)
lr = ReduceLROnPlateau(monitor='val_loss',
factor=0.5,
patience=3,
verbose=1,
min_delta=0,
min_lr=0.00001)
history = model_vit.fit(x_train_vit, y_train, validation_data=(x_val_vit, y_val), verbose=1, epochs=1000, callbacks=[es, lr])plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train','test'], loc = 'upper left')
plt.show()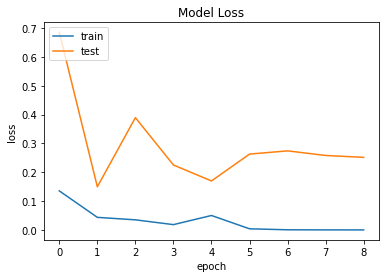
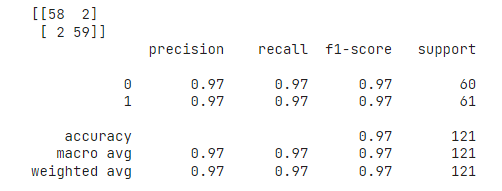
- 매우 높은 정확도를 얻을 수 있었다.
소감
좋았던 점
-
그림으로 쓱 훑고 이해도 잘 안되었던 모델구조를 직접 재현해보면서 모델 구조를 보는 능력이 어느정도 생긴 것 같다.
-
점점 예측 성능이 개선되는 것을 확인할 수 있었다.
아쉬운 점
-
좀 더 복잡하고 세부적인 기능을 이용하는 코드는 torch를 사용해야하는 경우가 많았는데, 아직 torch는 전혀 다루지 못하는 것이 아쉬웠다.
-
VIT, EffiNet과 같은 모델에 대한 지식이 없어 되는대로 가져다 사용한 것에 무언가 죄책감을 느꼈다.
공부하고 싶은 것
- torch (코드보고 이해할 수 있는 수준이라도)
