
무엇을 했나?
구글 드라이브 + colab에서 작업했는데, 어째서인지 작업 내용이 전혀 저장되지 않아 코드 대부분이 날아갔다. 때문에 코드보다는 어떤 작업을 했고, 어떤 인사이트를 얻었는지 위주로 작성할 것이다.
DataAugmentation
-
학습데이터, 검증데이터, 테스트데이터 전체를 합쳐도 600장 남짓밖에 되지 않기 때문에, 학습과정에서 과대적합이 발생하기 쉽다. 때문에 ImageDataGenerator를 이용한 데이터 증강을 통해 보다 좋은 성능을 얻어보고자 하였다.
-
기준 모델로, 직접 모델링을 진행한 GoogLeNet 기반 모델을 이용하였다.
train_datagen = ImageDataGenerator(
rotation_range = 30,
shear_range=0.3,
horizontal_flip=True,
fill_mode='nearest',
rescale=1./255. ,
)
valid_datagen = ImageDataGenerator(
rescale=1./255. ,
)
test_datagen = ImageDataGenerator(
rescale=1./255.
)- 최초 설정은 위와 같이하였다.
- rotation_range, shear_range : 차량 사진에서 손상 부위를 찾는 문제이므로, 카메라 각도에 따라 손상 부위가 다르게 보일 수 있을 것이라 생각하여 지정
- horizontal_flip : 좌우 반전 역시 흔한 케이스일 것이라 생각하여 지정 (거꾸로 뒤집어 찍는 경우의 수는 없을 것이라 예상하여 vertical_filp은 False로 함)
- valid_datagen, test_datagen : 학습 데이터와 동일하게 전처리 하기 위해 지정
train_generator = train_datagen.flow_from_directory(train_path,
target_size=(280, 280),
class_mode='binary',
batch_size=32,)
valid_generator = valid_datagen.flow_from_directory(val_path,
target_size=(280, 280),
class_mode='binary',
batch_size=32,)
test_generator = test_datagen.flow_from_directory(test_path,
target_size=(280, 280),
class_mode='binary',
batch_size=64
shuffle=False)- test_generator의
shuffle=False를 지정하지 않으면, 순서가 뒤섞인 채로 예측을 하기 때문에, test label(y_test)과 순서가 일치하지 않게 되어 잘못된 평가 결과가 나오게 된다. 때문에 제너레이터를 사용할 경우 반드시 지정해야 한다. - 이미 numpy array로 변환된 이미지 데이터가 있다면,
flow_from_directory대신flow를 사용하여 이미지 데이터를 가져와도 된다.
- 어제 진행하였던 합습과 동일하게 Earlystopping, ReduceLR을 적용하여 학습을 진행하였다.
결과
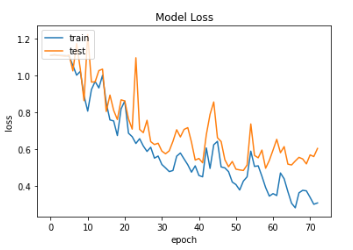
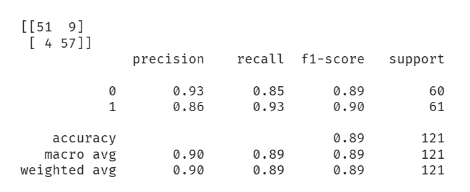
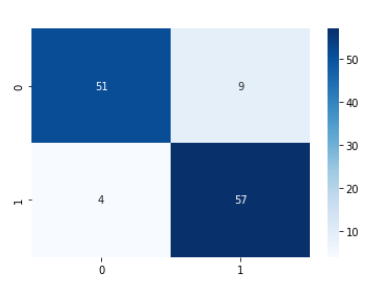
- Augmentation을 적용하였을 때 0.85의 Accuracy Score를 기록했는데 0.89로 상승하였다. 특히 1(abnormal)에 대한 recall이 크게 증가하였다.
- 학습데이터가 부족할 때 적절한 DataAugmentation이 모델 성능에 긍정적인 영향을 준다고 할 수 있다.
극단적인 데이터 변형
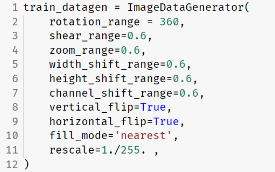
- 결과 비교를 위해 일부러 극단적으로 이미지 변형을 하도록 제너레이터를 설정하였다.
- 결과 Accuracy Score는 0.84로 이미지 증강이 없을 때보다 오히려 감소하였음을 확인할 수 있었다.
- 이러한 결과를 바탕으로 이미지 성격에 맞는 적절한 변형이 필요하다는 것을 추론할 수 있었다. 아마 실제로 이렇게 변형을 심하게 할 경우 abnormal 데이터에서 손상된 부분이 아예 데이터에서 벗어나 보이지 않게되거나 할 수 있을 것 같다.
그 외 Data Augmentation의 필요성
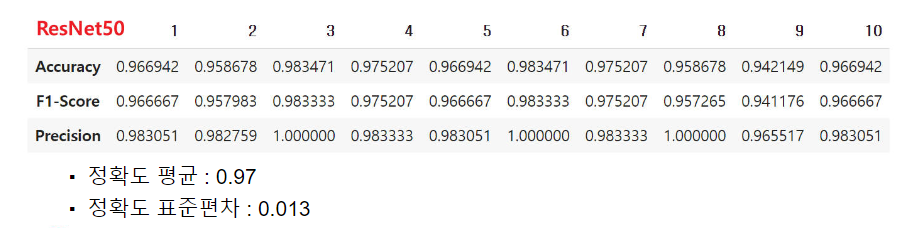
- 위 표는 pretrained ResNet50 모델 테스트 데이터를 증강하지 않고 평가한 결과이다.
- 데이터 증강이 없었을 때의 10회 평균 정확도는 0.98로 성능이 소폭 감소하였다.
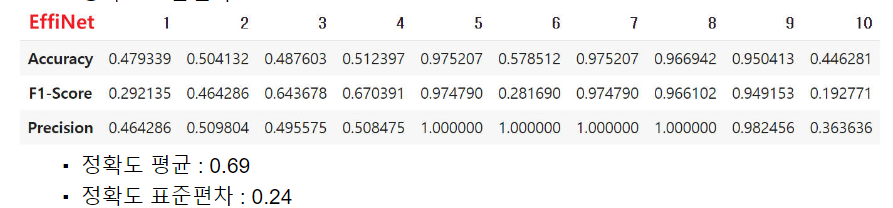
- EffiNet의 경우는 데이터를 증강하지 않았을 때, 학습이 제대로 진행되지 않아 Accuracy가 0.5로 수렴하는 경우가 있었다. 이는 아마 적은 데이터 수로 인해 과대적합이 발생한 것으로 보인다.
- 이렇게 학습 데이터가 적음에도 불구하고, 데이터 증강을 하지 않는다면 데이터 부족으로 인한 성능 저하 및 과대적합 발생 우려가 높음을 확인할 수 있었다.
문제해결 - 과대적합

문제 발생
- 이번 모델링을 진행하면서 val_accuracy 및 테스트 정확도가 0.5에 수렴하는 현상이 자주 발생하였다.
- 이는 다양한 원인이 있을 수 있지만, 주로 적은 데이터 수로 인해 과대적합이 발생한 것이 주 원인으로 추정된다.
- 이유1 : 레이어가 깊은 모델에서 이러한 현상이 자주 발생함
- 이유2 : Batch Normalization 레이어를 제거했을 때 문제가 해결되는 경우가 많았음 (데이터 수가 부족할 때 Batch Normalization은 과대적합의 가능성을 높일 수 있다)
문제 해결
- Learning Rate(학습률) 조절
- optimizer로 Adam을 사용했을 때 학습률의 기본값은 0.001인데, 0.005 또는 0.0001 등으로 낮추어 시작하여 과대적합을 해소하였다. ReduceLR 적용도 좋은 방법이다.
model.fit()에서shuffle=True를 설정하여 매 epoch마다 학습 데이터가 섞이도록 하였다. 이를 통해 학습때마다 서로 다른 배치로 학습하여 과대적합 위험을 줄였다.- 모델의 파라미터 감소
- 일부 레이어 제거, 노드 수 조절, 필터 채널 수 조절 등으로 학습 파라미터의 수를 줄여 과대적합 위험을 줄였다.
- 특히 파라미터 증가의 주 원인이 되는 Dense Layer대신 GlobalAveragePooling을 이용하는것도 방법이 될 수 있다.
소감
좋았던 점
-
그동안 프로젝트를 마무리할 때 시간에 쫓겨 내용을 잘 정리하지 못하고, 발표자료를 빈약하게 만드는 경우가 많았는데 이번엔 다양한 시도를 하였고 내용도 잘 정리할 수 있었다.
-
발생한 문제를 해결하고 원인을 분명하게 알고 넘어갈 수 있었다.
아쉬운 점
-
발표자료를 정말 열심히 만들었는데, 발표를 하지는 못하였다.
-
오늘 진행한 코드의 대부분이 날라갔다. 앞으로는 클라우드를 너무 믿지말고 저장이 잘 되었는지꼭 확인하자.
공부하고 싶은 것
- ResNet, EffiNet, VGG16 등 사용한 모델들의 구조 및 원리
