오늘 배운 것
딥러닝을 이용한 자연어 처리 서론
Text Mining과 NLP
- 텍스트 마이닝 : 거대한 텍스트 데이터로부터 언어학, 통계학, 컴퓨터공학 등을 이용해 목적에 맞는 유의미한 정보를 추출하는 방법
- 딥러닝이 등장하면서 현재는 거의 딥러닝을 위한 코퍼스 수집 및 전처리 단계 정도의 의미로 사용한다.
- 자연어 처리 : 분석을 통해 비즈니스 의사결정에 유의미한 도움이 되는 문장을 도출하는 것
- 컴퓨터가 자연어를 처리하기 위해서는 우선 자연어를 계산 가능한 형태로 변환하는 작업을 해야한다.
- 아직까지도 문맥, 문법 등의 어려움으로 사람이 훨씬 쉽게 풀 수 있는 문제이다.
End2End : Deep Learning
- Fully Connected Layer를 사용하는 ANN 모델은 Input 부터 Ouput까지 모든 구조가 하나로 연결되어있는 End2End 모델이다.
- 또한 모든 구조에서 단일 loss와 optimizer을 사용한다.
- 이것이 대단한 이유는 그림을 문장으로 표현하고, 문장을 바탕으로 그림을 생성하는 서로 다른 차원의 문제조차 단 하나의 loss를 minimize하는 관점으로 해결할 수 있다는 것이다.
RNN
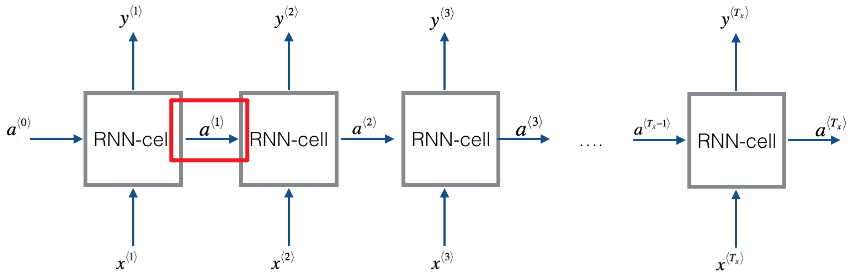
Kulbear / deep-learning-coursera 깃허브
- Input → Hidden Layer(RNN-cell) → Output으로 이어지는 하나의 신경망을 시계열 구조로 연결한 것이다.
- t-1 시점(과거)의 히든 레이어에서 만들어진 새로운 feature와 t시점 (현재)의 Input을 연결하여 이를 바탕으로 다시 새로운 feature를 생성해 다음 layer 또는 t+1 시점으로 전달한다.
핵심 개념
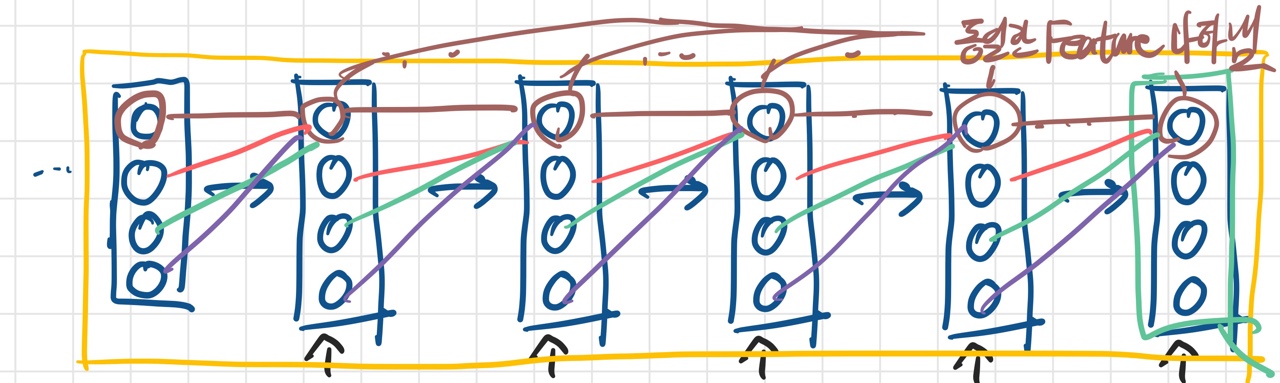
- 그림이 다소 난잡한데, 동일한 색의 선은 모두 같은 값을 갖는 가중치이다. (Input이 다르기 때문에 가중치를 곱한 결과가 동일하다는 것은 아님)
- 과거의 정돈된 정보와 현재의 Raw 정보를 동시에 고려하여, 모델의 목적에 맞는 새로운 특징을 생성한다.(Feature Representation)
- 그리고 이를 일관된 규칙으로 반복할 수 있다.
- 여기서 말하는 일관된 규칙이란, 시점에 관계 없이 동일한 위치에 있는 노드는 동일한 Feature를 나타낸다는 개념이다. 이를 위해 동일한 위치의 가중치는 모두 동일한 값을 사용한다.
RNN의 문제점
- t시점의 Input은 t시점의 Raw 정보와 0~t-1 시점을 고려하여 생성된 정돈된 정보이다. 즉, RNN은 두 정보를 동등하게 취급하는데, 한 쪽 정보는 0~t-1 시점까지가 모두 섞여있는 정보이므로 결국 현시점의 정보를 가장 중요하게 취급한다고 할 수 있다.
- 이러한 경향은 t-2, t-3, ...과 같이 현시점에서 먼 정보일수록 심해진다.
- 이로 인해 RNN은 초기 시점의 정보(자연어 처리라면 문맥 등)를 굉장히 빠르게 잊어버린다는 한계가 있다.
RNN 모델링
전처리
데이터 차원 조정
- RNN은 시계열 구조로 이루어져있기 때문에, 0~t 시점만큼 Input이 필요하다. ANN의 Input에 시점 수 차원이 추가된 데이터를 입력하여야 한다.
- 만약 시계열 데이터가 해당 구조로 이루어져 있지 않다면, reshape나 별도 처리를 통해 데이터의 shape을
(#, t, n) - # : 데이터 개수, t : 시점 수, n : 입력 특징 수 로 만들어 주어야 한다.
Sequential API
- 시점이라는 새로운 차원이 있으므로, Input 레이어 선언 시
shape=(t, n)으로 모델에 알려주어야 한다.
SimpleRNN
- 케라스가 제공하는 RNN 구조를 위한 레이어이다.
- 선언시 중요한 하이퍼파라미터는 다음과 같다.
- 히든레이어의 노드 수 : 생성하고자 하는 feature 수
- Activation Function : RNN은 에포크 한번에 굉장히 많은 가중치 업데이트가 이루어져 미분 기울기의 소멸 또는 폭주 발생 위험이 크다. 때문에 실험적으로 가장 좋은 성능을 보인 tanh 함수를 일반적으로 사용한다.
- return_sequences : 만약 다음 레이어가 출력층이라면, 가장 마지막 시점의 feature만을 전달해야 할 수 있다. 반면 다음 레이어가 또다른 RNN 구조이거나, flatten 레이어라면 모든 시점의 output을 전달해야할 수 있다. 이를 조절하는 파라미터이다.
- 그외 학습을 조금이라도 더 잘되게 하기 위한 다양한 파라미터가 있지만, 모델이 돌아가는데 필수적인 것은 위 세가지이다.
Dense
- 기존 ANN과 동일하다. 이진분류, 다중분류, 회귀 등 문제에 맞는 출력층 shape을 정하면 된다.
코드
- 2개의 RNN layer로 구성된 기본적인 RNN 구조를 keras sequential API를 이용해 구현했다.
keras.backend.clear_session()
model = keras.models.Sequential(name='my_first_rnn')
model.add( (keras.layers.Input(shape=(21, 1), name='input_layer')) )
model.add( (keras.layers.SimpleRNN(16, return_sequences=True, name='hidden1_rnn')) )
model.add( (keras.layers.SimpleRNN(32, return_sequences=True, name='hidden2_rnn')) )
model.add( (keras.layers.Flatten(name='hidden3_flatten')) )
model.add( (keras.layers.Dense(1, activation='linear', name='output_layer')) )
model.compile(loss='MAE', optimizer='adam')
model.summary()
"""
Model: "my_first_rnn"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hidden1_rnn (SimpleRNN) (None, 21, 16) 288
hidden2_rnn (SimpleRNN) (None, 21, 32) 1568
hidden3_flatten (Flatten) (None, 672) 0
output_layer (Dense) (None, 1) 673
=================================================================
Total params: 2,529
Trainable params: 2,529
Non-trainable params: 0
_________________________________________________________________
"""

