
오늘 배운 것
Bidirectional Layer
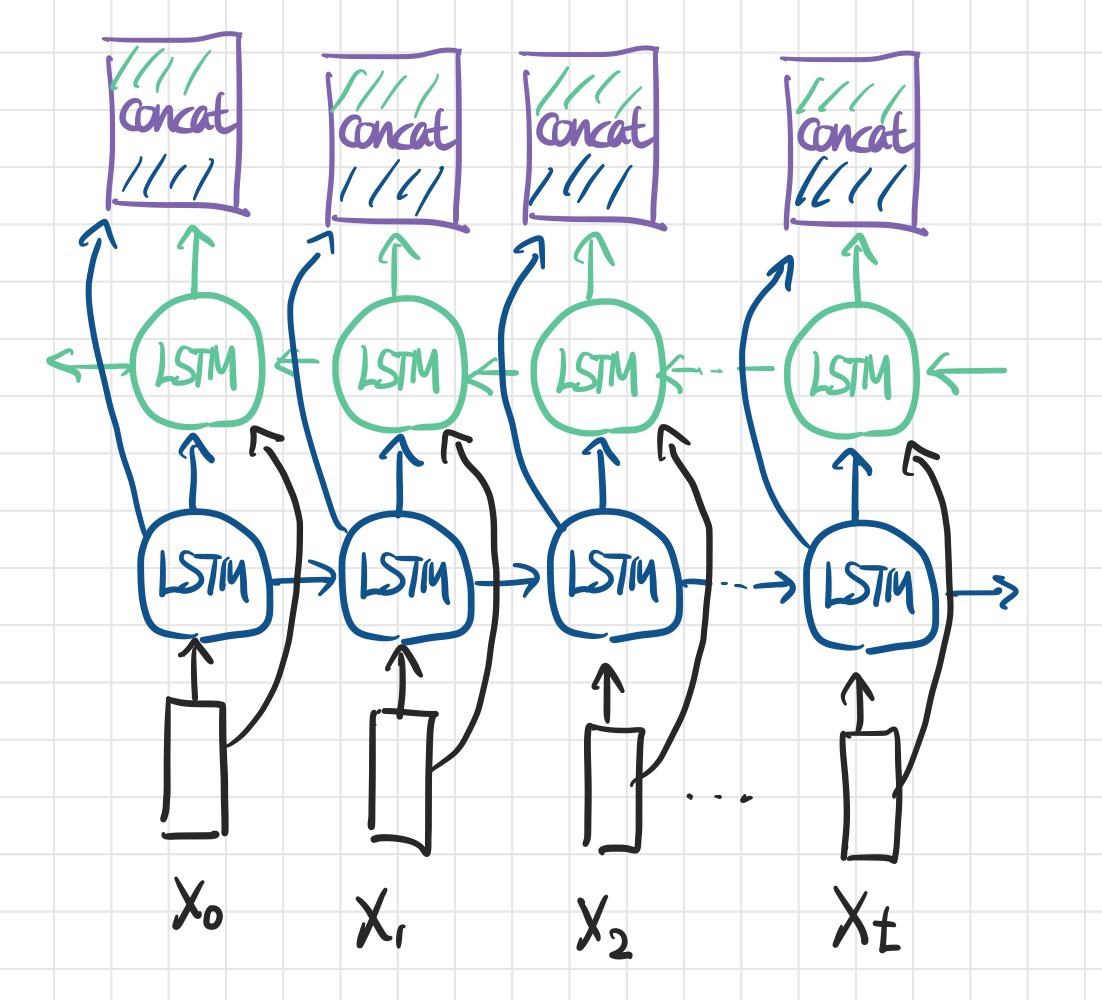
- 말 그대로 양방향의 레이어를 의미하는데, 정방향 RNN(또는 LSTM, GRU 등 시계열 데이터를 처리하는 히든레이어)과 역방향 RNN 2개의 레이어가 한 쌍이 되는 레이어이다.
- 정방향과 역방향 레이어는 서로 독립적이며, 같은 Input을 받되 memory가 전달되는 방향이 반대이다.
- 독립적이란 말은 서로 영향을 끼치지 않는다는 의미이다.
- Bidirectional Layer의 출력은 각 방향의 레이어를 concat한 것으로,
<정방향 레이어의 노드 수> + <역방향 레이어의 노드 수>이다.
역방향 레이어를 통해 얻는 이득
-
기존 정방향 레이어만 있을 때
- 마지막 시점 정보의 경우 과거 시점의 정보를 반영하여 feature representaion 진행 (맥락 고려)
- 첫 시점 정보의 경우 순수하게 Input 정보 만으로 feature representation 진행 (맥락 고려 X)
- 즉 각 시점별로 정보가 동등하지 않을 수 있다.
-
역방향 레이어와 concat 함으로써, 모든 시점에서 과거 또는 미래의 맥락을 반영하여 feature representation을 할 수 있다.
Conv1D Layer
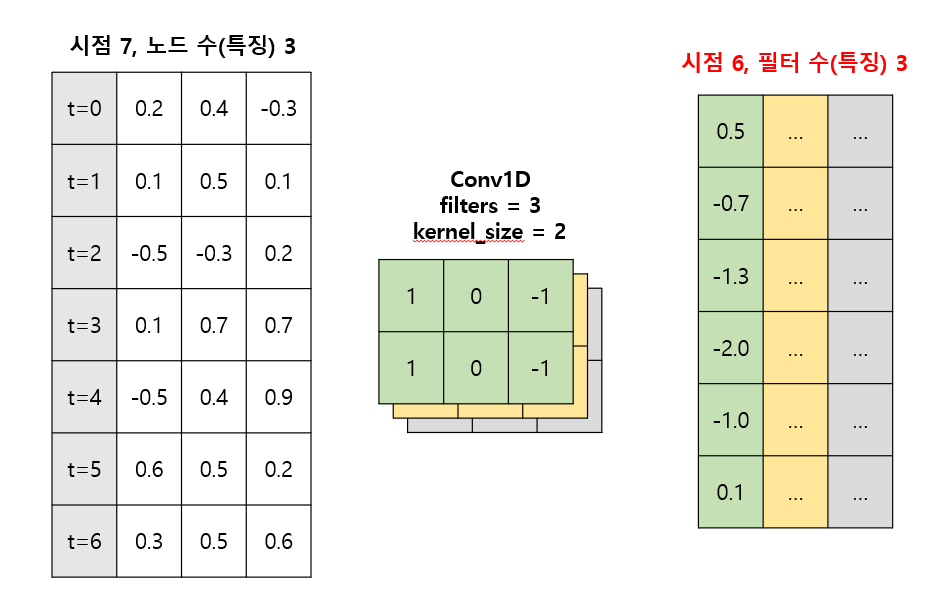
- RNN 기반 구조에서 Conv1D를 사용하면 kernel_size 만큼의 시점을 동등하게 한번에 보겠다는 의도가 있다.
- 기존 LSTM에서는 t시점의 특징에는 0, 1, 2, ..., t 까지의 정보가 모두 반영되어 있지만, Conv Layer에서는 필터의 크기만큼의 시점만 반영되어있다. (각 행이 독립적)
- Padding을 넣지 않는다면 시점을 축소하는 효과가 있다. -> 시점이 많을수록 과거 정보를 잊어버리게되는 RNN 기반 구조의 단점을 보완
대신 양쪽 끝의 시점 정보가 반영되는 정도가 감소한다는 단점이 있다 (정보의손실)
파라미터
- filters : 이전 레이어로부터 추출하고자 하는 새로운 feature 수
- kernel_size : 필터의 크기로, 한번에 추출할 시점의 수를 의미한다.
- 한 방향으로만 움직이는 1D Layer이기 때문에 한번에 고려할 노드 수는 이전 레이어의 노드 수와 항상 같다. (별도로 선언할 필요 없음)
- strides : 필터를 적용할 간격
- padding : 패딩을 하지 않는다면 차원을 축소, same padding을 한다면 시점 수는 유지되지만 모서리 쪽의 정보가 보존된다.
- activation : relu, swish 등
MaxPool1D Layer
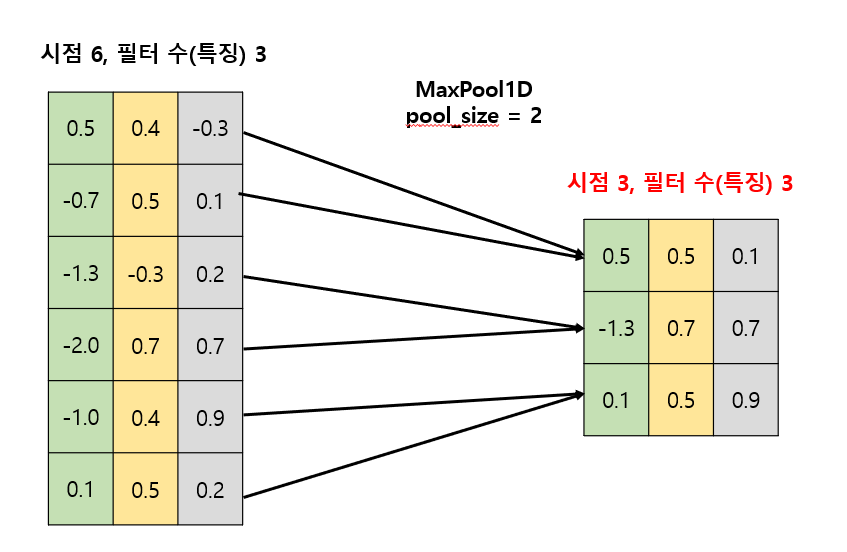
- 값이 큰(중요한) 가중치만을 남기고 나머지를 제거함으로써, 시점을 축소한다.
파라미터
- pool_size : 한번에 관찰하여 요약할 시점 수를 의미한다.
- stride : 필터를 적용할 간격으로, 보통 pool_size와 같다.
Conv1D, MaxPool1D의 의의
- Input의 시점을 축소할 수 있다. 기존 RNN, LSTM 등에서 과거 시점의 정보를 잊어버리는 문제를 개선할 수 있는 방법이다.
모델링
"""
1. 시점 수 20, 데이터의 차원이 6인 Input layer
2. Conv1D
3. MaxPool1D
4. Bidirectional 레이어
forward layer : LSTM, 히든스테이트 노드 24개
backward layer : GRU, 히든스테이트 노드 16개
5. Bidirectional 레이어
forward layer : LSTM, 히든스테이트 노드 24개
backward layer : GRU, 히든스테이트 노드 24개
6. Flatten
7. Fully Connected
8. 출력 차원이 1인 output layer
"""
# 1. 세션 클리어
clear_session()
# 2. 레이어 연결
il = Input(shape=(20, 6))
hl = Conv1D(filters=32,
kernel_size=10,
strides=1,
padding='valid',
activation='swish')(il)
hl = MaxPool1D(pool_size=2)(hl)
forward_LSTM24_1 = LSTM(24, return_sequences=True)
backward_GRU16 = GRU(16, return_sequences=True, go_backwards=True)
hl = Bidirectional( layer=forward_LSTM24_1,
backward_layer=backward_GRU16,
name='Bidirectional_1' )(hl)
forward_LSTM24_2 = LSTM(24, return_sequences=True)
backward_GRU24 = GRU(24, return_sequences=True, go_backwards=True)
hl = Bidirectional( layer=forward_LSTM24_2,
backward_layer=backward_GRU24,
name='Bidirectional_2')(hl)
hl = Flatten()(hl)
hl = Dense(256, activation='swish', name='Fully_Connected')(hl)
ol = Dense(1, activation='relu', name='output')(hl) # 음수를 0으로 처리
# 3. 모델 선언
model = Model(il, ol)
# 4. 컴파일
model.compile(loss=keras.losses.mae, optimizer='adam')
# 요약
model.summary()Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 20, 6)] 0
conv1d (Conv1D) (None, 11, 32) 1952
max_pooling1d (MaxPooling1D (None, 5, 32) 0
)
Bidirectional_1 (Bidirectio (None, 5, 40) 7872
nal)
Bidirectional_2 (Bidirectio (None, 5, 48) 10992
nal)
flatten (Flatten) (None, 240) 0
Fully_Connected (Dense) (None, 256) 61696
output (Dense) (None, 1) 257
=================================================================
Total params: 82,769
Trainable params: 82,769
Non-trainable params: 0
_________________________________________________________________-
Input에서 20개였던 시점이 kernel_size가 10인 Conv1D를 통과하여 10개로, pool_size가 2인 MaxPool1D를 통과하여 5개로 축소되었다.
-
Bidirectional_1에서 정방향 LSTM 24개, 역방향 GRU 16개가 concat되어 output의 노드 수가 40개임을 확인할 수 있다.
-
Bidirectional_2에서 정방향 LSTM 24개, 역방향 GRU 24개가 concat되어 output의 노드 수가 48개임을 확인할 수 있다.
