
오늘 배운 것
자연어 데이터 처리
- 자연어를 시계열 데이터 처럼 처리하기 위해서는 자연어를 계산 가능한 숫자로 만들어야 한다.
- 이를 위해서 크게 두가지 과정을 거쳐야한다.
- Tokenization (토큰화)
- 딥러닝을 위한 전처리
- Embedding (임베딩)
Tokenization
- 문서 또는 문장을 '토큰'이라는 분석 가능한 단위로 쪼개는 과정을 말한다.
- 토큰의 단위는 상황에 따라 다르지만, 일반적으로 의미를 갖는 최소 단위를 의미한다.
토큰화에 대해서는 자연어 처리 공모전 참가를 위해 공부해 둔 것이 있으니 참조하자.
[자연어 스터디] 02. 텍스트 전처리
- 토큰화에는 어학적 지식을 고려하여 문서 및 문장을 토큰화하고, 그중 중요하지 않은 토큰을 제거하는 과정 등이 포함된다.
Basic Preprocessing
- 토큰화된 문장을 전처리하는 것에는 다양한 방법이 있지만, 현재는 기초를 다루고 있으므로 딥러닝 모델링을 위해 필요한 최소한의 것만 짚어보자.
단어 표현의 카테고리화(text to sequence)
We will rock you라는 문장이 있을 때, 이 문장의 단어는We, will, rock, you4개로 토큰화할 수 있다.- 이를
We=1, will=2, rock=3, you=4로 표기하자고 약속하면 위 문장은[1, 2, 3, 4]로 나타낼 수 있다. -> 즉 자연어를 정수 숫자로 나타낸 것이다.
- 카테고리화는 다음의 절차를 통해 수행할 수 있다.
- 1) 전체 코퍼스의 단어 목록을 바탕으로 단어와 1:1 맵핑되는 인덱스 생성
- 2) 각 문서, 문장별로 텍스트를 불러와 인덱스로 변환
- 코퍼스의 단어가 너무 많아 빈도수를 기준으로 일부 단어만 사용하기로 한다면, 사용되지 않는 단어들은 카테고리화 시 제거된다.
- 카테고리화 되어 정수로 표현되는 문장을 sequence라고 한다.
Padding, Truncate
- 딥러닝 모델에 Input으로 입력하기 위해서는 모든 sequence가 동일한 길이를 가져야 한다.
- 때문에 정해진 길이보다 짧은 문장은 0또는 PAD 토큰으로 채우고, 긴 문장은 정해진 길이가 되도록 잘라내는 과정이 바로 padding과 truncate이다.
Padding
- 길이가 짧은 문장을 의도한 길이에 맞도록 0으로 채우는 과정이다.
- 문장의 앞을 패딩할지, 문장의 뒤를 패딩할지 선택할 수 있다.
- RNN 기반 모델에서는 가장 마지막 시점의 값이 모든 문맥이 반영된 값이므로, 보통 문장의 앞을 0으로 채우는 것을 선택한다.
Truncate
- 길이가 긴 문장을 의도한 길이에 맞게 잘라내는 과정이다.
- 패딩과 마찬가지로 앞, 뒤를 선택하여 자를 수 있다.
- 데이터 셋에 따라 적절하게 자를 부분을 선택해야한다. (두괄식, 미괄식 등 고려)
- 일반적으로는 문장의 뒤를 자르는 것을 선택한다.
Embedding
- 딥러닝의 본질인 loss를 줄이는 방향으로의 학습이 가능하도록 데이터를 처리하는 과정이다.
서론
- 자연어 처리의 대표적인 예제는 바로 분류문제이다.
- 문장의 감정 분류 (화남, 기쁨 등)
- 문장의 긍정/부정 분류 등
- 이를 위해서는 단어를 단순히 숫자로 바꾸는 것으로는 부족하고, 모델에서 학습할 수 있도록 수치화된 벡터로 만들어야한다. (vectorization)
- 이를 위해 사용하는 것이 임베딩인데, 우선 임베딩 이전에 사용하던 방법들을 짚고 넘어가자
기존 방법 - Bags of Words, TF-IDF
Bags of Words
-
Bags of Words는 문서에 많이 등장하는 단어가 중요한 단어일 것이라 가정하고, 단어의 등장 빈도로 문서를 벡터화하는 방법이다.
-
모델에 넣을 하나의 문서에서 각 단어가 몇번 등장하는지 카운팅한다.
TF-IDF
- 영어를 예로 들었을 때
a, that, you, it과 같은 단어들은 모든 문서에서 빈번하게 등장할 것이다. 그러나 이는 실제로는 별로 중요하지 않은 단어들이다. Bags of Words에서는 이를 구분할 방법이 없다.
- TF-IDF의 개념만 설명하면, 전체 문서에서 자주 등장하는 단어에는 패널티를 주어 낮은 가중치를 부여하고, 전체 문서에서 자주 등장하지 않는 단어에는 높은 가중치를 부여하여 중요도를 나타내는 방법이다.
- 예를들어 어떤 문서에서 McDonald라는 단어가 많이 등장했는데, 다른 문서에서는 한번도 등장하지 않았을 경우, 이 단어를 해당 문서의 중요한 단어로 간주한다.
- 반면 'you'라는 단어가 많이 등장했는데, 'you'는 모든 문서에서 등장하므로 낮은 가중치를 주어 덜 중요한 단어로 간주한다.
기존 방법의 한계
- 공간의 비효율 : 전체 코퍼스의 단어 30000개를 맵핑하였다고 할 때, Input shape도 30000이 되어야 한다. 그런데 문서에 등장하는 단어가 수백개 수준이라면 나머지 29,000여개는 0으로 채워지는 일종의 공간 낭비가 발생한다. -> 이를 희소(sparse)하다고 한다.
- 문맥을 고려할수 없음 :
I want to change my job과Here's your change는 다른 의미를 갖지만, 단순히 빈도수로 계산하면 같은 단어로 묶이게 된다.
Word Embedding
- 토큰화 및 패딩을 거쳐
We will rock you를[0, 0, 0, 1, 2, 3, 4]로 변환했다고 하자. - 만약 전체 단어 개수가 3만개이고, 이를 벡터라이징 해야한다면 아래와 같이 희소 행렬로 표현해야 할 것이다.

- 하지만 히든 레이어와 유사한 개념으로 단어로부터 특징을 representation하여 출력하는 레이어를 거친다면, Input size가 훨씬 줄어든 일종의 밀집 벡터로 만들 수 있을 것이다.
- 이러한 역할을 하는 레이어를 Embedding Layer라고 한다.
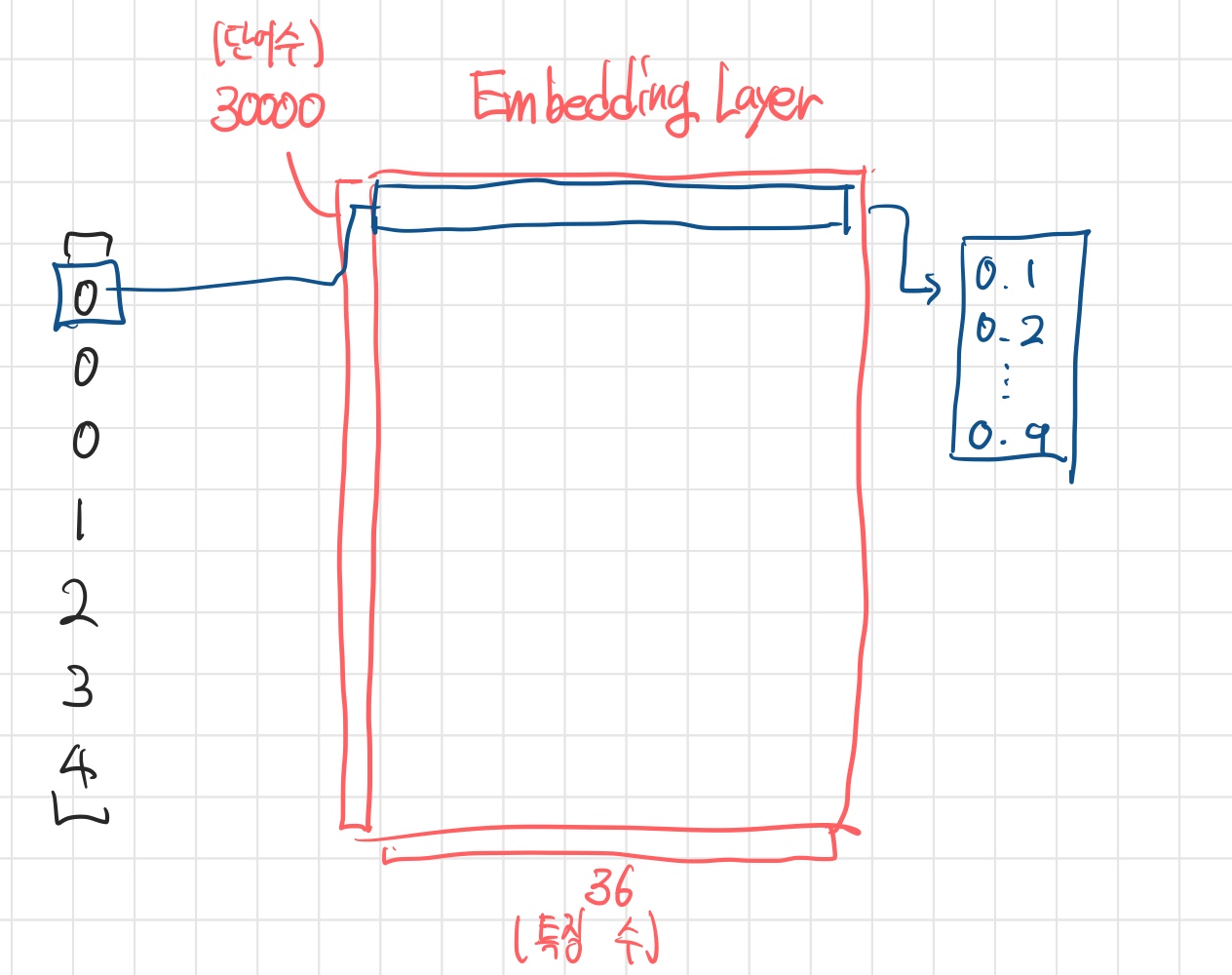
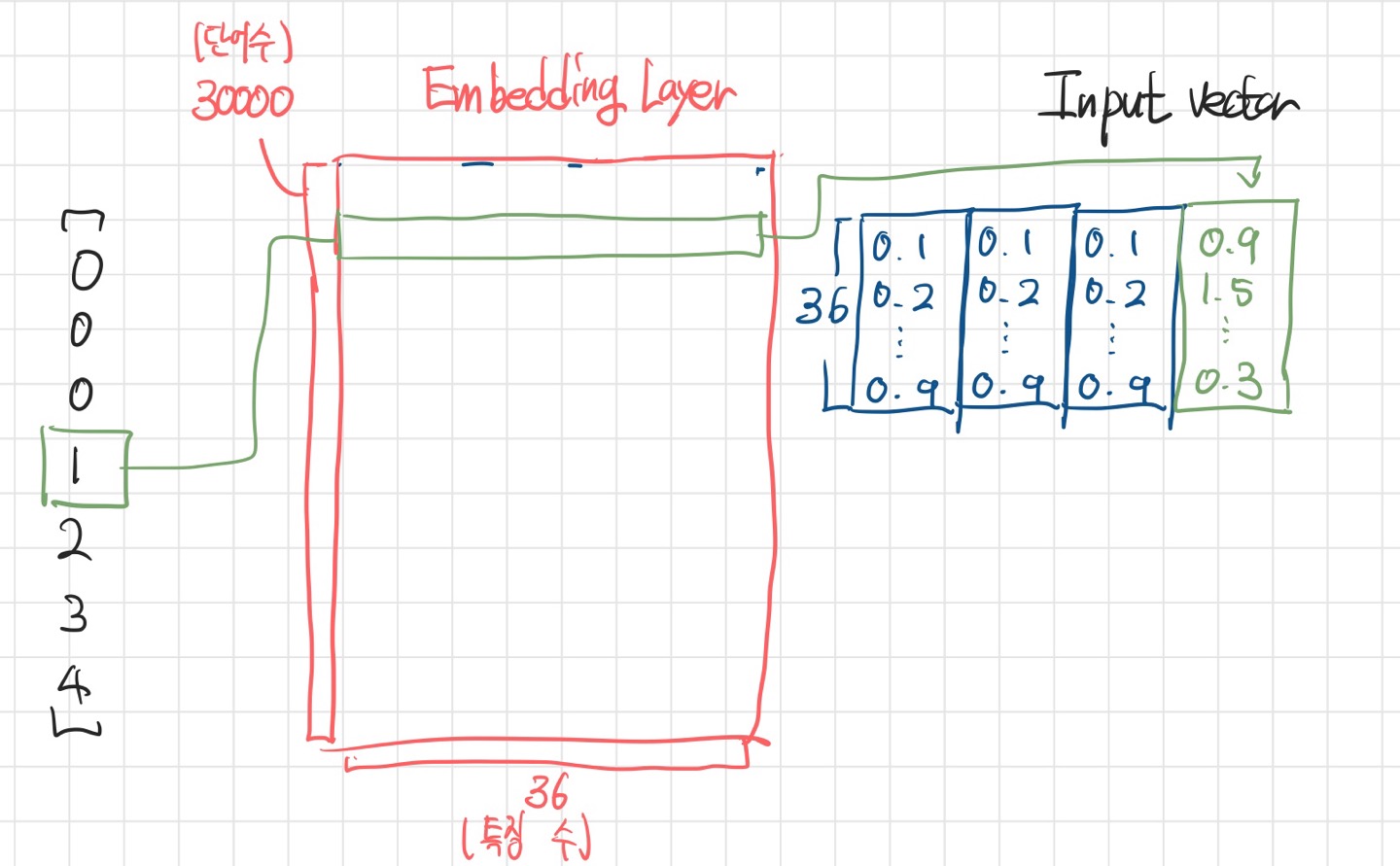
- 임베딩 레이어는 높이가 전체 단어 수, 너비가 추출할 특징 수인 이차원 행렬이며, 각 단어를 밀집벡터로 변환해주는 값을 갖는다.
- 또한 이 값은 학습에 의해 업데이트 될 수 있다. -> 유사한 단어가 비슷한 값을 갖게 됨
Embedding의 의의
- Input shape를 줄여 불필요한 자원 낭비를 줄임
- 풀고자 하는 문제에 대한 성능 향상
- 의미 분석의 가능성이 열림
- 학습에 의해 유사한 단어가 비슷한 값을 갖는다면, 벡터 연산을 통해 단어의 연산이 가능하다!
- 이러한 연산을 할 수 있는 가능성이 있다. (이 단계에서 아직 가능한 것은 아님)
실습
전처리
제공받은 한국어 데이터를 전처리 수행한 코드이다. 전처리의 방법은 무궁무진하므로 정답이 없다.
## 토큰화
from tensorflow.keras.preprocessing.text import Tokenizer
max_words = 40000
tokenizer = Tokenizer(num_words=max_words, lower=True)
# 학습 텍스트 데이터를 바탕으로 토크나이징 (띄어쓰기 기반으로 기본적인 처리)
tokenizer.fit_on_texts(x_train)
## 단어 -> 인덱스
# 텍스트 순서를 토큰화된 인덱스 순서로 변환
x_train = tokenizer.texts_to_sequences(x_train)
x_test = tokenizer.texts_to_sequences(x_test)
## Padding & Truncate
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 문장의 길이를 40으로 설정
max_length = 40
# 두괄식을 가정하여 뒷부분을 삭제
x_train = pad_sequences(x_train, maxlen=max_length, padding='pre', truncating='post')
x_test = pad_sequences(x_test, maxlen=max_length, padding='pre', truncating='post')
# 모델이 처리할 수 있도록 numpy로 변환
x_train = np.array(x_train)
x_test = np.array(x_test)임베딩 및 모델링
# 모델링에 필요한 라이브러리 불러오기
import tensorflow as tf
from tensorflow import keras
from keras.backend import clear_session
from keras.models import Model
from keras.layers import Input, Embedding, Dense
from keras.layers import Conv1D, MaxPool1D, Flatten
from keras.layers import LSTM, GRU, SimpleRNN, Bidirectional
# 0. 필요 변수
max_words = 40000
max_length = 40
# 1. 세션 클리어
clear_session()
# 2. 레이어 연결
# 인풋레이어
il = Input(shape=(max_length,))
# 임베딩 레이어 : 임베딩차원은 128
embedding = Embedding(input_dim=max_words,
output_dim=128,
input_length=max_length)(il)
# 학습을 위한 히든레이어 (Conv1D + Bidirectional LSTM)
hl = Conv1D(filters=64,
kernel_size=5,
strides=1,
padding='valid',
activation='swish')(embedding)
forward_LSTM = LSTM(32, return_sequences=True)
backward_LSTM = LSTM(32, return_sequences=True, go_backwards=True)
hl = Bidirectional(layer=forward_LSTM, backward_layer=backward_LSTM)(hl)
forward_GRU = GRU(32, return_sequences=True)
backward_RNN = SimpleRNN(16, return_sequences=True, go_backwards=True)
hl = Bidirectional(layer=forward_GRU, backward_layer=backward_RNN)(hl)
hl = Conv1D(filters=32,
kernel_size=5,
strides=1,
padding='valid',
activation='swish')(hl)
hl = MaxPool1D(pool_size=2)(hl)
hl = Flatten()(hl)
hl = Dense(1024, activation='swish')(hl)
# Output
ol = Dense(1, activation='sigmoid')(hl)
# 3. 모델 선언
model = Model(il, ol)
# 4. 컴파일
model.compile(loss=keras.losses.binary_crossentropy,
metrics=['accuracy'],
optimizer='adam')
# 요약
model.summary()Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 40)] 0
embedding (Embedding) (None, 40, 128) 5120000
conv1d (Conv1D) (None, 36, 64) 41024
bidirectional (Bidirectiona (None, 36, 64) 24832
l)
bidirectional_1 (Bidirectio (None, 36, 48) 10704
nal)
conv1d_1 (Conv1D) (None, 32, 32) 7712
max_pooling1d (MaxPooling1D (None, 16, 32) 0
)
flatten (Flatten) (None, 512) 0
dense (Dense) (None, 1024) 525312
dense_1 (Dense) (None, 1) 1025
=================================================================
Total params: 5,730,609
Trainable params: 5,730,609
Non-trainable params: 0
_________________________________________________________________