
무엇을 했나?
과제 설명
문제
- UCL이 제공하는 데이터 셋을 이용한 다중 문제 풀이
- Feature : 허리에 찬 스마트폰 센서(가속도 센서, 자이로 센서)의 측정값을 이용해 추출한 특징으로, 약 560여개의 특징이 주어진다.
- Label : 6개의 클래스 (서기, 앉기, 눕기, 걷기, 계단 오르기, 계단 내려가기
프로젝트 수행의 주 목적
- 데이터의 수는 5000여개로, 데이터 수에 비해 특징이 매우 많기 때문에 모델이 무거워지고, 과적합의 발생 위험이 크다. 때문에 중요하지 않은 변수를 잘 제거하여 학습 속도를 높이고 일반화 성능 향상을 꽤한다.
- 단순히 6개 클래스의 다중 분류 문제로만 보지 않고, 특정 행동을 그룹화하여 이진 분류 문제를 만들어 다양한 관점으로 문제를 바라볼 수 있도록 한다.
- 궁극적으로, 낯선 도메인과 데이터를 마주했을 때 문제 해결 역량을 기른다.
변수 중요도(Feature Importance) 추출
- 이번 프로젝트에서는 변수 중요도(이하 FI)를 추출하기 위해 RandomForest 모델을 이용해 지니 불순도 기반의 변수 중요도를 추출하였다.
RF 모델 기반의 변수 중요도
- RandomForest 모델을 사용한 이유는 다음과 같다.
- 하이퍼파라미터 튜닝 없이 Default 값으로도 준수한 성능을 낼 수 있다. 성능이 중요한 이유는 FI를 추출해봤자 모델 성능이 엉망일 경우 추출된 결과를 신뢰할 수 없기 때문이다.
- 견줄만한 다른 모델(XGBoost 등)에 비해 빠르다.
- 하지만 RandomForest 모델의 FI는 회귀 문제나 클래스 수가 많은 분류 문제를 풀 때 편향이 발생할 확률이 높다고 한다. 특히 이번 문제와 같이 중복되는 특징이 많을 경우 이러한 경향이 심해진다고 한다. 이를 방지하기 위해서는
Permutation Importance,Drop-Column Importance와 같이 다른 중요도와 함께 보는 것이 좋다고 한다.
FI 추출 및 시각화
-
우선 raw 데이터 그대로 RF 모델에 학습시켰다. validation_data에 대한 학습 성능은 0.97 정도로 우수하여 FI 추출 결과를 신뢰할 수 있었다.
-
model.feature_importance_를 받아 시각화 그래프를 출력하고, 결과를 DataFrame으로 반환하는 함수를 이용해 FI 추출 결과를 저장하였다. -
그리고 kdeplot을 이용해 FI 상위 변수와 하위 변수를 시각화 하였다.
상위 변수
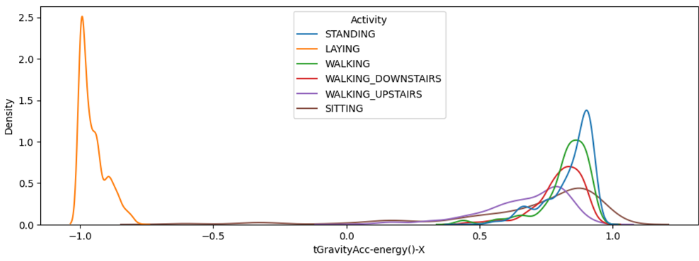
- 주관적인 판단을 해도 LAYING 변수를 구분하기 아주 좋은 특징이다.
- 차이가 적긴해도 클래스별로 조금씩 다른 밀도 분포를 보이고 있기 때문에 타 클래스 예측에도 중요하게 작용한 것 같다.
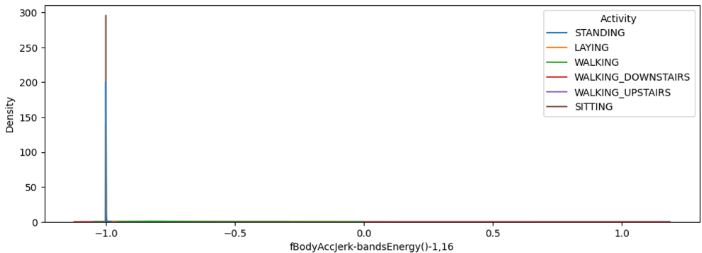
- 주관적인 판단으로는 어떻게 모델에 기여했는지 알기 어려운 경우이다.
하위 변수
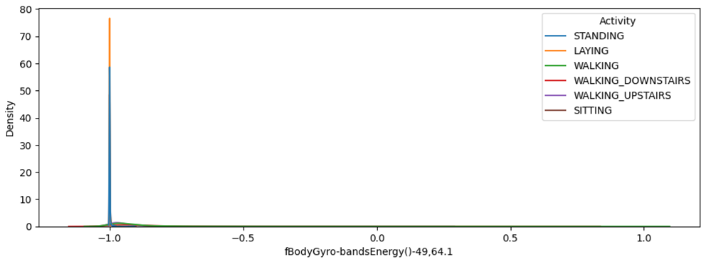
- 상위 변수에 있던 변수와 어떤 차이가 있는지 이해하기 힘들었다.
- 또한 이러한 분포를 보이는 경우가 상위, 하위 모두 많았는데, 확실히 중복이 많이 발생한 것 같다.
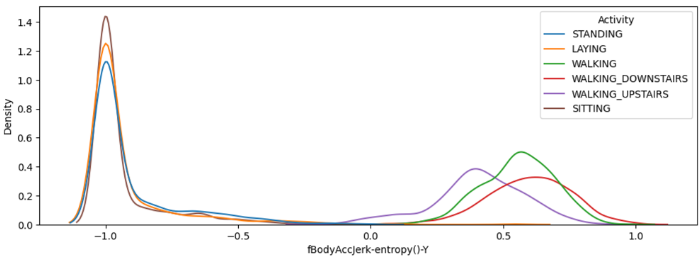
- 좌축에 있는 분포는
WALKING,WALKING_UPSTAIRS,WALKING_DOWNSTAIRS로 모두 동적인 행동을 하는 클래스 들이다. - 분명 주관적 판단으로는 중요하게 사용되었을 변수이지만, 하위 10위 안에 있었는데, 아마 이것 역시 유사한 분포의 중복 특징이 많이 존재하고, 그 중 하나일 것으로 추측하였다.
결론
- 중복되는 분포가 많아 컬럼의 적절한 제거가 필요하다.
이진 분류
- 클래스를 정적 동작, 동적 동작으로 그룹화하여 이진 분류 문제로 풀 수 있다.
- One vs rest 전략을 사용하여 하나의 클래스에 대해 이 클래스 인지 아닌지의 이진 분류 문제로 풀 수 있다.
- 각 클래스 별로 이진 분류 학습을 하였으며, 결과로 얻은 변수 중요도를 각각 저장한 다음 하나의 컬럼으로 만들었다.
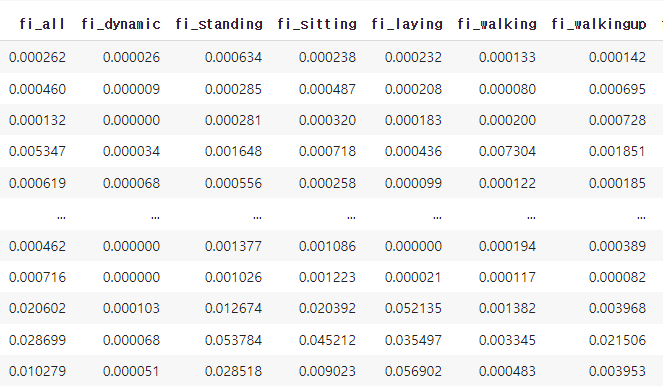
FI 활용
- 우선 모델 성능에 영향을 주지 않으면서도, 컬럼을 확실하게 줄일 수 있도록 특징을 제거하기로 했다.
평균 활용
- 컬럼별 FI의 평균을 구하여
fi_avg라는 값을 얻어내었다. 해당 값이 일정 값 이하일 경우 해당 변수를 제거하는 전략을 취했다.
- 기본 모델 성능
Accuracy: 0.9813084112149533
F1 macro: 0.9814958659585066fi_avg > 0.005
- 컬럼 수 : 52
Accuracy: 0.9770603228547153
F1 macro: 0.977340045063964`fi_avg > 0.01
- 컬럼 수 : 17
Accuracy: 0.9719626168224299
F1 macro: 0.9719635976512006fi_avg > 0.01인 컬럼만을 선택했을 때 가장 적은 컬럼 수가 되었지만 기존 대비 성능이 1% 이상 감소하여 중간값인 0.005를 취하였다.
최대값 활용
- 다른 문제에서는 중요도가 낮지만, 특정 문제에서 높은 중요도를 보이는 특징이 있을거라 생각하여 최대값을 이용래
fi_max값을 얻어내었다.
fi_max > 0.005
컬럼 수 : 178
Accuracy: 0.9762107051826678
F1 macro: 0.9771547813332093fi_max > 0.015
컬럼 수 : 77
Accuracy: 0.9796091758708582
F1 macro: 0.979519851719974fi_max > 0.02
컬럼 수 : 49
Accuracy: 0.9762107051826678
F1 macro: 0.9767385707780653- 0.015를 기준으로 했을 때 컬럼수가 비교적 적으면서도 준수한 성능을 얻을 수 있었다.
앞으로 할 일
- 중요하다고 판단된 변수만을 이용하여 모델링 (딥러닝 고려)
- 문제를 다중 분류 한번으로 풀지 않고 이중 분류를 거쳐 2단계 학습
- 클래스별로 다른 모델을 사용할 수 있어 잔차를 줄이는 것에 효과적일 듯 하다.
