프로젝트 개요
자연어 이해 - FAQ 챗봇 모델링
자연어 이해(NLU)
- 자연어 이해는 사용자의 자연어 데이터를 바탕으로 기계가 사용자의 의도를 파악할 수 있도록 하는 것을 말한다.
문제 정의
- 이메일을 통해 들어오는 문의는 대체로 FAQ에 이미 작성되어있는 경우가 많다. 그러나 들어온 문의를 무시할 수는 없기에 운영자가 일일히 답신 메일을 보내야 하므로, 업무 효율이 낮아진다.
- 설상 가상으로 점점 지원자가 많아지면서 문의량이 폭증하는데 반해 인력과 시간은 제한되어있어 문의자 역시 답변이 지연되어 불편함을 겪고 있다.
- 때문에 사용자의 질문을 바탕으로 답변을 출력하는 챗봇 서비스를 통해 이를 해결하려 한다.
- 문의 처리의 자동화로 운영자의 업무 효율 증가
- 문의자는 답변을 즉시 확인할 수 있어 편의성 증가
문제 해결 Process
- 챗봇의 형태이지만 사실상 다중분류 형태로 문제를 해결한다.
- 문의 내용을 바탕으로 어떤 문의 유형인지에 대해 다중 분류를 진행하고, 해당 유형에 대해 정해진 답변을 출력한다. (FAQ 내용)
데이터 탐색
데이터 수
- 데이터 수는 약 1300여개로, 적은 편에 속한다.
- 머신러닝 SOTA 모델 중 하나인 LightGBM도 과적합의 위험 때문에 종종 10,000개 이상 데이터에 사용하는 것을 권장하곤 하는데, 이정도로 데이터가 적다면 딥러닝 보다 오히려 머신러닝에서 더 뛰어난 성능을 보일수도 있다.
데이터(문자열) 길이
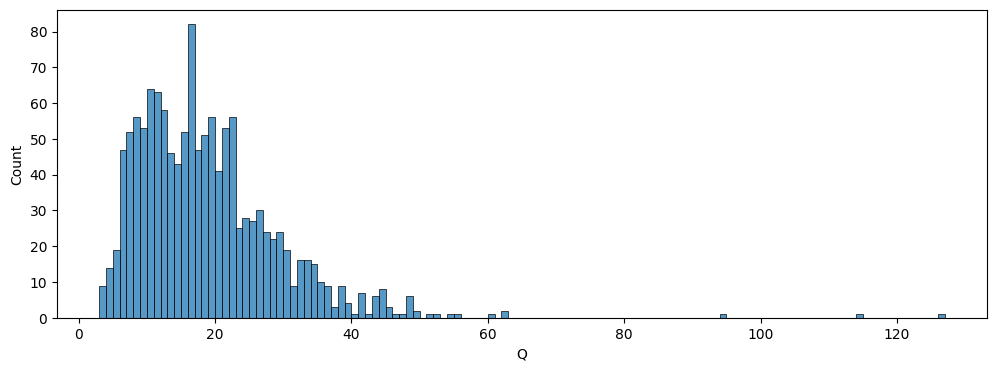
- 데이터의 길이도 상당히 짧은 편에 속한다.
- 40자를 넘어가는 데이터가 거의 없고, 평균 18자 정도의 짧은 길이를 갖고 있다.
- 즉 만약 해당 문자열을 바탕으로 단어 사전을 만들어도 많은 단어를 포함하지 못할 우려가 있다. (사전 학습된 사전 활용 필요)
클래스 수
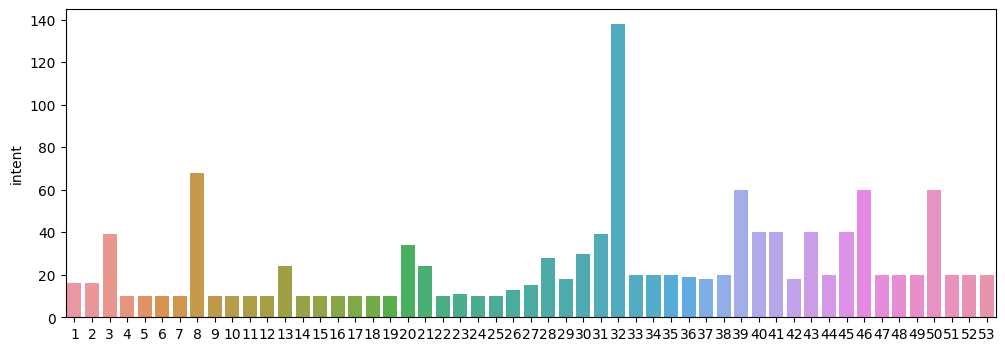
- 일부 클래스의 데이터가 많은 불균형 데이터 형태이다.
- 이런 경우 데이터가 적은 클래스는 학습이 제대로 이루어지지 않을 우려가 있어, 언더 샘플링을 하거나 클래스가 많은 쪽만 따로 분류한 뒤 나머지 데이터에 대해 다중 분류를 하는 방법 등을 고려할 수 있다.
데이터 전처리 (Word2Vec)
- 지난 미니프로젝트 시에는 자연어의 머신러닝 처리를 위해 문자열을 시퀀스로 변환하여 사용하였다.
- 이번 과정에서는 문장 시퀀스를 문자열로 변환하여 머신러닝에 사용할 것이다.
토큰화
- 가장 성능이 좋다고 알려진 바른 형태소 분석기 API를 사용하고자 하였으나, 회원가입을 진행할 수 없어 konlpy의 Mecab 형태소 분석기를 사용하였다.
gensim.models.Word2Vec
- gensim은 자연어 처리에 중점을 둔 파이썬 오픈소스 라이브러리이다. 자연어 처리를 위한 다양한 모델을 제공하는데, Word2Vec은 단어를 임베딩 벡터로 바꾸는 모델이다.
from gensim.models import Word2Vec
wv_model = Word2Vec(sentences=x_train_sent, size=256, window=5, min_count=2, sg=1)
- sentences : 학습할 문장(또는 문서)을 넣어주면 된다.
- size : 임베딩 벡터의 크기를 말한다. 클 수록 단어를 더 많은 Feature로 표현할 수 있지만, 더 많은 연산을 필요로하고, 공간도 많이 사용한다.
- window : 학습 시 앞뒤로 고려하는 단어의 수 (문맥 고려)
- 값이 클수록 단어의 의미적 정확도를 잘 파악할 수 있지만, 연산량이 증가한다.
- min_count : 등장 빈도수가 min_count보다 작으면 해당 단어를 무시함
- 기본값은 5이지만, 데이터 크기와 길이가 작은것을 고려해 2로 지정하였다.
- max_vocab_size : 고려할 단어의 최대 갯수
- 별도로 선언하지 않으면 모든 단어를 고려한다.
- 마찬가지로 데이터가 작은 것을 고려해 별도로 선언하지 않았다.
- sg : 학습 알고리즘을 지정한다.
- 0(기본값) :
CBOW - 중심단어를 바탕으로 주변 단어(window 수 만큼)를 예측하면서 학습
- 1 :
skip-gram - 주변 단어를 바탕으로 중심 단어를 예측하면서 학습
- 여러 논문에서 성능 비교를 했을 때 skip-gram이 비교적 더 나은 성능을 보인다고 한다.
참고 : https://wikidocs.net/22660
Sent2Vec
- RNN 시퀀스 딥러닝 모델에서는 문장의 각 단어를 순차적으로 모델에 입력할 수 있지만, 머신러닝에서는 문장 전체를 모델에 한꺼번에 입력해야 한다.
- 즉 단어 하나를 벡터화 하는 것이 아니라 문장 전체를 벡터화 하여 Input으로 사용해야 한다.
- 이 때 Word2Vec는 단어간의 유사도를 고려하여 단어를 벡터화하므로, 단어의 연산을 통해 문장을 표현할 수 있다.
- 우선 가장 기본적인 방법으로 문장 내의 모든 벡터를 더하는 방법을 사용할 수 있다.
index2word_set = set(model.wv.index2word)
sent_vec = np.zeros((embedding_size,), dtype='float32')
count_word = 0
for word in tokenized_words:
if word in index2word_set:
n_words += 1
sent_vec = np.add(sent_vec, model[word])
sent_vec = np.devide(sent_vec, n_words)
- 이러한 과정을 통해 문장을 벡터로 표현할 수 있다.
데이터 모델링 (머신러닝 기반)
머신러닝 모델
- 기본값으로 선언된 몇가지 모델에 대해 성능을 테스트 한 뒤 튜닝을 많이 할 수 있으면서 준수한 성능을 나타낸 LightGBM 모델을 사용하였다.
하이퍼 파라미터 튜닝 (Optuna)
Optuna 공식 홈페이지
- Optuna는 최적의 파라미터를 찾는 블랙박스 최적화 프로그램으로, 반환된 성능값을 통해 다음 시험에 샘플링 할 파라미터를 결정한다.
- 베이지안 최적화에 비해 넓은 범위를 비교적 빠르게 튜닝할 수 있으며, 직관적인 API를 제공한다.
탐색 함수 선언
- 정해진 문법에 따라 모델의 탐색 범위를 지정할 수 있다. (
scikit-optim 라이브러리의 BayseSearchCV와 유사하였다)
- 모델의 성능 지표를 return 해주어야 한다.
import optuna
import lightgbm as lgb
from sklearn.model_selection import cross_val_score
def objective(trial):
dtrain = lgb.Dataset(x_train, label=y_train)
params = {
'learning_rate' : trial.suggest_float('learning_rate', 0.01, 0.3, log=True),
'max_depth' : trial.suggest_int('max_depth', 3, 20),
'num_leaves' : trial.suggest_int('num_leaves', 2, 31),
'min_data_in_leaf' : trial.suggest_int('min_data_in_leaf', 2, 20),
"min_child_samples": trial.suggest_int("min_child_samples", 2, 20),
'feature_fraction' : trial.suggest_float('feature_fraction', 0.5, 1.0),
'bagging_fraction' : trial.suggest_float('bagging_fraction', 0.5, 1.0),
'lambda_l1' : trial.suggest_float('lambda_l1', 1e-8, 10, log=True),
'lambda_l2' : trial.suggest_float('lambda_l2', 1e-8, 10, log=True)
}
model = lgb.LGBMClassifier(**params)
score = cross_val_score(model, x_train, y_train, cv=3, scoring='accuracy').mean()
return score
- 아래와 같이 학습할 모델을 만들어 준 뒤,
.optimize() 메서드를 통해 학습을 시작한다.
- n_trials는 탐색 횟수이며, direction은 클 수록 좋은 성능인지, 작을 수록 좋은 성능인지를 지정한다.
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)

