
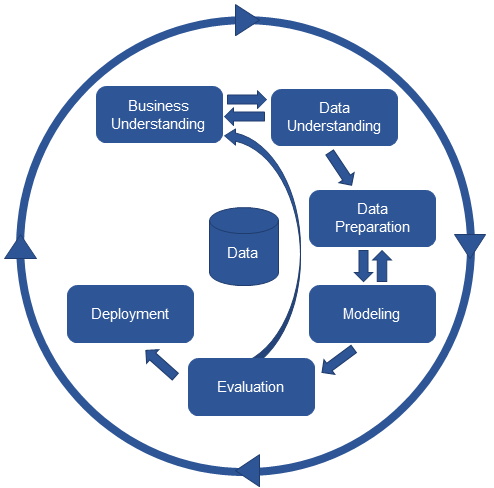
1. CRISP-DM Review
2. MLOps와 Pipeline
- ML 코드는 ML 시스템의 극히 일부분
- ML을 배포하여 운영하기 위해 필요한 주변 인프라는 방대하고 복잡
→ 이를 관리할 체계가 필요하다. (MLOps)
MLOps란
- MLOps = Machine Learning + Dev + Ops
- 기계 학습 운영을 위한 프로세스, 도구 및 방법론을 적용하여 기계 학습 모델의 전체 생명주기를 지원
MLOps 구성 요소
- 데이터 관리
- 데이터 수집 및 전처리 과정의 자동화
- 일관된 데이터 사용
- 모델 개발
- 모델 배포
- 모델의 안정성, 보안성을 유지
- 이전 버전의 모델을 관리
- 모니터링 및 유지보수
- 모델 성능 모니터링 및 필요에 따른 조정
- 필요시 모델에 따른 재학습 진행
- 모델 감사 및 해석을 위한 도구 제공
AI 엔지니어와 AI 개발자
실무에서는 딱딱 나눠 떨어지지 않는다는 것에 유의하자
데이터 관리
- AI 엔지니어
- 데이터 수집 및 전처리
- AI 개발자
- 전처리된 데이터 바탕으로 모델 개발 시작
모델 개발
- AI 엔지니어
- 모델 개발에 필요한 인프라 구성
- 모델 빌드 및 테스트 수행
- AI 개발자
- 모델의 알고리즘 및 하이퍼파라미터 선택
- 모델 학습 및 검증 수행
모델 배포
- AI 엔지니어
- 모델 배포 인프라 구성
- 모델 API 설계
- 모델 배포 및 운영
Pipeline
- 운영시스템에서는 데이터 발생부터 예측 결과까지 거의 사람의 개입 없이 물 흐르듯이 흘러가야 한다. 이런 구성을 pipeline이라고 부른다.
- 본 과정에서는 파이프라인 시스템을 구성해볼 것이다.
파이프라인 시스템 구성도
- 실험 단계
- 데이터 분석
- 모델링 진행
- 모델링에 사용된 코드들은 코드 저장소에 저장
- 데이터 전처리 단계
- 데이터 파이프라인 구축
- 데이터 검증 - 유효한 데이터인지 확인
- 모델링을 위한 데이터 전처리
- 서비스 단계의 모델에 데이터를 전달
- 모델 관리 단계
- 실험이 끝난 모델을 모델 저장소에 저장
- 사용할 모델을 검증
- 검증이 끝날 문제는 배포되기 전 대기 단계(staging)을 거침
- 모델 제작
- 서비스 단계
- 3-d의 제작된 모델을 서빙
- 2-d 단계에서 전달받은 데이터를 바탕으로 예측값 반환 → 데이터 저장소에 저장
- 모델 모니터링
3. 파이프라인을 위한 데이터 전처리
파이프라인 구축을 위해 가장 중요한 것
- 모델에 넣는 새로운 데이터(raw data)는 모델이 학습될 때의 구조와 값의 의미가 동일해야 한다.
- 학습때는 10~100 범위의 데이터를 사용했는데, 새로운 데이터의 범위가 -5 ~ 80이라면?
- 똑같이 0~1 범위로 스케일링하면 기존엔 10 = 0 이었는데, -5 = 0이 되어버리므로 값의 의미가 틀어진다.
- 즉 학습때 사용했던 스케일러를 이용해 -0.XX ~ 0.8의 범위가 되도록 스케일링 해야한다.
주요 단계
- 불필요한 변수 제거
- 데이터 분할 (x, y)
- train, val 분할
- Feature Engineering
- 가변수화
- NaN 조치
- 스케일링
3. train, val 분할
- 성능에 대한 객관적인 평가를 위해 검증용 데이터를 분할 → 일반화된 성능을 얻게 됨
- train data의 size가 클 수록 성능에 긍정적인 영향 (일반적으로 성능 증가량이 미미해지는 Elbow 구간에 들어가도록 traindata를 나눈다)
- 데이터의 종류
- 학습용 데이터 : 모델 학습에 사용
- 검증용 데이터 : 학습한 모델의 일반화 성능을 검증
- 테스트 데이터 : 모델에 대한 최종 평가용, Raw Data 그대로 두고 학습 및 모델링 단계에서는 전혀 사용하지 않아야 한다.
Raw Data인 점을 이용해 Data Pipeline 테스트에도 사용된다.
train_test_split을 통해 데이터셋을 분리할 수 있다.
4. 가변수화 (dummy variable)
- 범주형 데이터를 숫자로 변환하는 과정
- 가변수를 만드는 과정을 One-Hot Encoding이라 부르기도 한다.
pd.get_dummies
- 그러나 학습용 데이터에는 a~b 4개가 있어 4개 범주에 대해 가변수화를 진행했는데
검증용 데이터에는 a~b 3개 밖에 없어 범주의 크기가 달라질 수 있다 → 오류 발생 - 이를 방지하기위해 변수의 데이터 타입을
category로 변경해야한다. - category를 get_dummies에 지정하면 무조건 지정된 데이터에 맞추어 가변수화를 진행한다.
예를 들어 위 사례에서 검증용 데이터에 a~b 3개밖에 없어도 컬럼은 a_d까지 생성된다.
pd.Categorical
- 해당 컬럼의 자료형을 category로 바꾸는 함수
- 범주형 데이터의 자료형은 일단 category로 바꾸어야 한다고 생각하자
- 예시
x1컬럼을 가변수화 하고 싶을 때, info를 확인해보면 데이터 타입이 문자열(object)로 되어 있다.<class 'pandas.core.frame.DataFrame'> RangeIndex: 5 entries, 0 to 4 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 x1 5 non-null object 1 x2 5 non-null int64 dtypes: int64(1), object(1) memory usage: 208.0+ bytesCategorical을 사용할 때는 가변수화할 컬럼과 어떤 범주값이 존재하는지를 지정해주어야 한다.x1컬럼의 자료형을 category로 전환하면 판다스가 해당 컬럼을 범주 데이터로 간주한다.
train['x1'] = pd.Categorical(train['x1'], categories = ['a','b','c'])
train.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x1 5 non-null category
1 x2 5 non-null int64
dtypes: category(1), int64(1)
memory usage: 305.0 bytes- 이제
get_dummies()함수를 사용할 때 사용할 컬럼을columns=옵션으로 지정한다. 이때 사용할 컬럼의 데이터 자료가category여야 한다. - 출력결과를 보면 test의
x1컬럼에는c값이 없었음에도 불구하고 train 데이터와 동일하게 가변수화 되었다.
test['x1'] = pd.Categorical(test['x1'], categories = ['a','b','c'])
pd.get_dummies(test, columns = ['x1'])x2 x1_a x1_b x1_c
0 7 True False False
1 8 False True False
2 9 False True False5. 스케일링
- 거리를 계산하는 알고리즘(KNN, SVM 등)에서 범위가 큰 변수가 알고리즘에 더 큰 영향을 끼치는것을 방지하기 위해 동일한 범위를 갖도록 스케일링을 해주어야 한다.
- 일반적으로 스케일링을 하면 분포는 변하지 않고 범위만 맞춰진다. (정규분포와 상관없음)
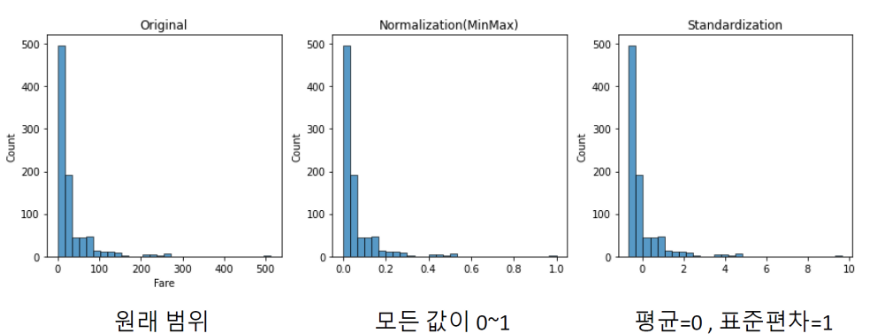
- 스케일링 방법 (Minmax, Standard 등)에 따라 성능값이 조금씩 달라줄 수 있다. 이는 실험을 통해 최적의 스케일링 방법을 찾는 것이 좋다.
6. 결측치(NaN) 처리
- NaN 조치의 3가지 방법
- 제거하기
- 추가하기
- 분리하기
제거하기
dropna()메서드를 통해 결측치 제거가 가능하다.- 운영환경을 고려해야 한다. (대개 비즈니스 관계자의 의사에 따라 결정한다)
- 행 삭제
- NaN이 있는 비율이 적을 때
- 운영과정에서 NaN이 발생되지 않을 때, 혹은 해당 NaN이 있는 데이터를 무시해도 될 때 (또는 그렇게 해도 된다고 합의 되었을 때)
- 열 삭제
- NaN이 있는 비율이 많을 때
- 중요하지 않은 feature 일 때
채우기
- 특정 값으로 채우기
- 범주형 데이터 : 최빈값, 기본값,
sklearn.impute.SimpleImputer - 숫자형 데이터 : 평균값, 중앙값, fillna,
sklearn.impute.SimpleImputer
- 범주형 데이터 : 최빈값, 기본값,
- 앞, 뒤 값으로 채우기 : 시계열 데이터에서 사용
- 추정하여 채우기 : 결측치를 추정하는 모델을 만들어 모델의 예측값으로 채우기
- 숫자형 데이터 :
sklearn.impute.KNNImputer
- 숫자형 데이터 :
SimpleImputer
- 전략을 정하여서 특정 값으로 채울 수 있다.
- 전략에는 최빈값, 기본값, 평균값, 중앙값 등을 지원한다.
KNNImputer
- KNN 알고리즘을 이용해 결측치를 추정 (숫자형 변수에만 가능)
- 예측을 통해서 값을 채우기 때문에 Target을 포함해서 채우면 안된다.
- K 값을 지정하여 사용할 수 있으며 default는 5이다.
가변수화 조치 시점
- 결측치 조치는 조치 방법에 따라 처리 시점이 달라진다.
- 단일 값
- 범주형 : 가변수화 전까지
- 숫자형 : 스케일링 전까지
- 추정 값
- 스케일링 이후 수행 (거리기반 알고리즘이므로)
데이터 딕셔너리
- 데이터 원본을 식별한 후, 데이터 딕셔너리를 만든다.
- 데이터 딕셔너리란 데이터가 어떤 구조를 갖는지 등의 데이터 스키마를 정리해 놓은 메타 정보 집합이다.
- 각 컬럼이 어떤 정보를 담는지, 컬럼의 값이 무슨 의미를 나타내는지에 대한 정보가 정리되어있다.
번외, random_state
- 모델의 실험 단계에서는 실험 결과간의 비교 및 재현을 위해 랜덤성이 있는 과정에서 random_state를 고정하여 사용한다.
- 하지만 이 경우 어떤 특정 상황에 모델이 고정되기 때문에 일반적으로 운영단계에서는 random_state를 사용하지 않는다.
- 이 때문에 모델의 실제 성능을 얘기할 때에는 성능값의 평균과 신뢰구간을 말해주어야 한다.
파이프라인 구축
이제 모든 과정을 하나의 함수로 만들면 된다.
joblib 라이브러리를 이용하면 함수에 필요한 매개변수나 함수 자체, 학습된 모델 등을 pkl 파일로 저장할 수 있다.
실습
-
실습 주제 : 수어 번역 AI 모델 파이프라인 구축
-
과제
- 28*28의 흑백 수어 사진이 주어지면 어떤 알파벳인지 예측하는 모델 구현
- 새로운 데이터가 주어졌을 때 전처리부터 예측결과 반환까지 파이프라인으로 실행되도록 구현
모델링
※ 학습 데이터, 검증 데이터의 전처리 과정은 생략한다.
# 1. 세션 클리어
clear_session()
# 2. 레이어 쌓기
il = Input(shape=(x_train.shape[1], x_train.shape[2], x_train.shape[3]))
# 컨볼루션 레이어 1
x = Conv2D(32, (3, 3), activation='swish')(il)
x = MaxPooling2D((2, 2))(x)
# 컨볼루션 레이어 2
x = Conv2D(64, (3, 3), activation='swish')(x)
x = MaxPooling2D((2, 2))(x)
# Flatten 레이어
x = Flatten()(x)
# Dense 레이어 1
x = Dense(128, activation='swish')(x)
x = Dropout(0.2)(x)
# 출력 레이어
ol = Dense(24, activation='softmax')(x)
# 모델 선언
model = Model(il, ol)
# 컴파일
model.compile(loss=tf.keras.losses.categorical_crossentropy,
metrics=['accuracy'],
optimizer='adam')
# 요약
model.summary()Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 26, 26, 32) 320
max_pooling2d (MaxPooling2D (None, 13, 13, 32) 0
)
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
max_pooling2d_1 (MaxPooling (None, 5, 5, 64) 0
2D)
flatten (Flatten) (None, 1600) 0
dense (Dense) (None, 128) 204928
dropout (Dropout) (None, 128) 0
dense_1 (Dense) (None, 24) 3096
=================================================================
Total params: 226,840
Trainable params: 226,840
Non-trainable params: 0
_________________________________________________________________코랩 환경이 아닌 로컬에서 돌아가는 모델이므로 가볍게 구성하였다.
학습 결과
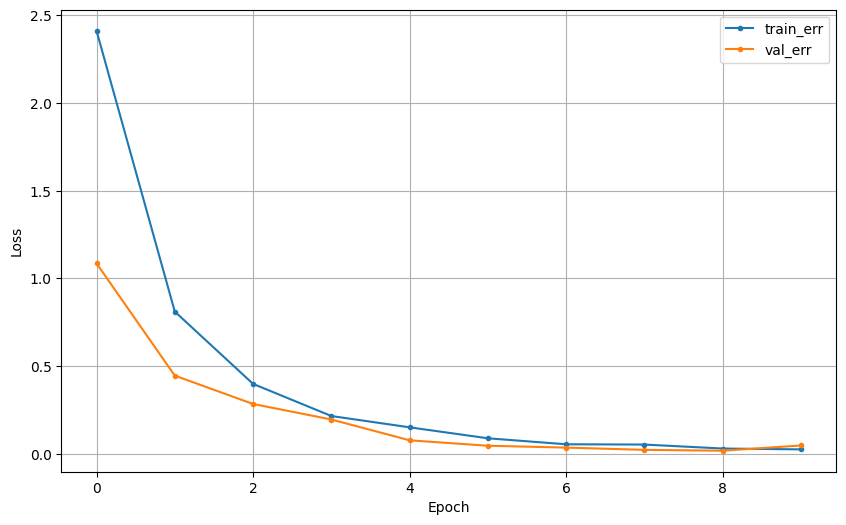
검증용 데이터에 대해서는 아주 우수한 성능을 보였다.
파이프라인 구축
1. 테스트 데이터 로딩
- 이미지 데이터이므로 이미지 처리를 위한
cv2라이브러리를 사용하였다.
import cv2
data_path = 'test image/'
data_file = 'v.png'
filename = data_path + data_file
# 파일 로딩
img = cv2.imread(filename, cv2.IMREAD_GRAYSCALE)2. 테스트 데이터 전처리
- 모델의 Input shape
(1 * 28 * 28 * 1)에 맞도록 reshape하는 과정, 스케일링 과정을 진행한다.
# 이미지 크기 조정
img = cv2.resize(img, (28, 28))
# input shape 맞추기
img = img.reshape(1, 28, 28, 1)
# Minmax 스케일링
img = img / 2553. 모델 불러오기 및 예측
- 앞서 joblib을 통해 pkl파일로 만들었던 모델을 불러온 뒤 예측한다
model_path = 'exercise1/model.pkl'
# 모델 로딩
model = joblib.load(model_path)
# 예측
pred = model.predict(img)
pred = pred.argmax()4. 파이프라인 구축
- 이 모든 과정을 함수 호출 하나로 실행할 수 있도록 함수를 만든다.
def pipeline(img, model):
# 크기 조정
img = cv2.resize(img, (28, 28))
# input shape 맞추기
img = img.reshape(1, 28, 28, 1)
# 스케일링
img = img / 255
# 모델 로딩
model = joblib.load(model_path)
# 예측
pred = model.predict(img)
pred = pred.argmax()
return pred