
mlflow
mlflow는 머신러닝 및 딥러닝 모델링의 전 수명 주기에 걸쳐 관리하는 기능을 제공하는 오픈소스 플랫폼이다.
mlflow 개요
mlflow의 기능
- 모델의 실행 결과 관리
- 모델 버전 관리 및 추적
- 모델 배포 관리
일반적으로 머신러닝 모델을 API 형태로 제공할 때, API는 클라이언트에서 동작하게 하고, 모델은 AWS 서버에 저장하여 요청에 따른 응답(모델 예측값)을 받는 형식으로 관리한다.
mlflow는 버전 관리 및 배포될 모델을 쉽게 지정할 수 있도록 해준다.
mlflow의 관리 단위
실험(Experiments)
- 실행(Runs)의 상위 단위
- 하나의 실험에 여러번의 실행이 포함된다.
- 하나의 실험은 하나의 케이스를 뜻한다.
- 예시) 수어 예측 모델이 하나의 실험이 되고, 수어 예측을 위해 딥러닝 CNN 모델, RandomForest 모델 등 다양한 모델 알고리즘이나 파라미터를 사용할 수 있다.
실행(Runs)
- mlflow의 추적 작업 단위
- 하나의 알고리즘을 여러번 실행할 수 있다.
모델(Models)
- 모델을 등록할 수 있는 지정된 모델 이름
- 서로 다른 모델이라도 동일한 모델 이름을 사용할 수 있다. (버전으로 관리)
- '실험'과는 별개의 단위이며,
registered_model_name옵션을 통해 사용자가 동일한 이름을 지정했을 때만 같은 모델 이름으로 관리된다.
버전(Versions)
- 모델의 관리 단위
- 같은 모델 이름을 가진 모델이 실행될 때마다 자동으로 버전이 증가
- 버전에 따른 배포 관리가 가능
mlflow 설정
- 매번 커널을 실행할 때마다, 어떤 db에 mlflow가 관리하는 모델, 로그 데이터 등을 저장할지 지정해야한다.
mlflow_url = "sqlite:///mlflow.db"
# sqlite:// + /mlflow.db (현재 디렉토리의 mlflow.db 파일)
mlflow.set_tracking_uri(mlflow_url)- 프롬프트 명령어의 경로가 db와 동일한 경로에 있을 때 위와같이 입력하면 된다.
- db의 종류는 상관없으며, 이번 경우에는 아나콘다 환경이 기본적으로 sqlite를 지원하기 때문에 sqlite를 사용하였다.
mlflow 사용
- with문에
mlflow.start_run()을 선언하고 블럭 안에서 모델링을 하면 해당 과정이 mlflow에 의해 추적된다.- with문 없이도 사용가능하지만,
start_run()과end_run()을 각각 선언해주어야 한다.
- with문 없이도 사용가능하지만,
- 해당 파일을 실행하면 db파일, mlruns, artifacts 디렉토리 등이 생성되어있는데, 이곳에 결과가 저장되어 있다.
- mlflow를 리셋하고 싶다면 해당 파일들을 삭제하면 된다.
with mlflow.start_run(): # 추적 시작 지정
model = DecisionTreeClassifier()
model.fit(x_train, y_train)
pred = model.predict(x_val)
accuracy = accuracy_score(y_val, pred)
mlflow.log_metric("accuracy", accuracy)
# mlflow_uri에 성능과 모델이 로그로 기록 됨
mlflow.sklearn.log_model(model, "model", registered_model_name="Test_Model")mlflow UI
- mlflow는 결과 확인 및 시각화, 모델 관리 등 다양한 기능을 아주 편하게 이용할 수 있는 웹페이지 UI를 제공한다.
mlflow server --backend-store-uri sqlite:///mlflow.db --default-artifact-root ./artifacts
위 명령어를 이용하면 로컬에서 작동하는 mlflow UI 서버를 만들 수 있다.
수동 로깅
- mlflow가 자동으로 로깅해주는 것 이외의 정보를 추가로 로깅하고 싶다면 mlflow 블록 내에서 선언해주면 된다.
실험 추적
mlflow.log_param: 하이퍼 파라미터 값mlflow.log_metric: 성능 지표 값mlflow.log_tag: 관리를 위해 필요한 정보mlflow.sklearn.log_model: sklaern 모델 등록mlflow.keras.log_model: keras 모델 등록
mlflow.log_artifact: 산출물 (그래프, 환경, csv 등)
실험 지정하여 mlflow 실행
from sklearn.ensemble import RandomForestRegressor
with mlflow.start_run(experiment_id = exp_id):
model = RandomForestRegressor()
model.fit(x_train, y_train)
pred = model.predict(x_val)
rmse = mean_squared_error(y_val, pred, squared=False)
mae = mean_absolute_error(y_val, pred)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("mae", mae)
mlflow.sklearn.log_model(model, "model1", registered_model_name="CarSeat")mlflow.start_run(experiment_id = exp_id): 실험의 id를 지정해주어야 한다.- 지정하지 않을 경우 default 실험으로 간주
mlflow.log_metric("rmse", rmse): 어떤 성능지표를 사용할지 지정한다.mlflow.sklearn.log_model(model, "model1", registered_model_name="CarSeat")- “model1” : 산출물들을 담을 폴더 이름을 지정할 수 있다.
- “
registered_model_name" : 모델을 구분하는 모델 이름이다. (같은 이름을 사용해야 버전 관리가 가능)
자동관리 (autolog)
autolog
- mlflow가 제공하는 모델의 오토로깅 기능
fit()메서드가 호출될 때 fitting 과정에서 일어나는 모든 중간 단계(학습 과정)과 결과를 자동으로 로그로 남길 수 있다.
# 자동 로깅
with mlflow.start_run():
mlflow.sklearn.autolog()
# ... 모델링 및 fit 코드 ...
mlflow.sklearn.autolog(disable=True)autolog()로 시작을 선언하여,autolog(disable=True)로 로깅을 중단한다.- sklearn, xgboost, keras 등 지원하는 모델이 다양하다 (공식문서 참조)
- autolog로 기록된 로그는 파일 형태로 저장이 될 뿐, 등록되지는 않는다. mlflow 페이지에서 등록 버튼을 누르는 과정을 거쳐야 등록까지 완료된다.
autolog가 필요한 실험
- 튜닝 : GridSearchCV, RandimizedSearchCV
- 반복작업 : iteration이 포함된 알고리즘들의 중간 단계 성능 기록관리
- XGBoost, Deep Learning 등
하이퍼 파라미터 튜닝
- 기본적으로 GridSearchCV, RandomizedSearchCV를 사용할 때 autolog를 통해 자동 기록되는 부분은 파라미터, 성능지표 및 성능평가 결과(
.cv_results)이다. - 그 외의 것은 수동으로 등록해주면 된다.
- 각 파라미터 당 모델
- 그래프
- 추가적인 fitting 함수 등
plt.plot('param_n_estimators', 'mean_test_score', data = result, marker = '.' )
plt.title('RF GridSearch Tuning')
plt.ylabel('r2 score')
plt.xlabel('n_estimators')
plt.grid()
plt.savefig('RF_GridSearch_Tuning.png')
mlflow.log_artifact("RF_GridSearch_Tuning.png")예를 들어 이 코드를 autolog 블럭 안에 포함시키면 plt로 그린 그림을 이미제로 변환하여 mlflog로그에 저장할 수 있다.
예시
with mlflow.start_run(experiment_id=exp_id, run_name = 'gridsearch_tuning01'):
# autolog 시작!
mlflow.sklearn.autolog()
# 튜닝 코드
params = {
"n_neighbors": range(1, 51),
"metric": ("euclidean", "manhattan"),
}
model = KNeighborsRegressor()
grid = GridSearchCV(model, param_grid=params, cv=5)
grid.fit(x_train_s, y_train)
# 수동등록 : 그래프
result = grid.cv_results_
sns.lineplot(x='param_n_neighbors', y='mean_test_score', data=result, hue='param_metric')
plt.title('KNN Grid Search Tuning')
plt.xlabel('n_neighbors')
plt.ylabel('r2 score')
plt.grid()
plt.savefig('KNN_GridSearch.png')
mlflow.log_artifact('KNN_GridSearch.png')
# 수동등록 : best 모델 기록하기
mlflow.sklearn.log_model(grid.best_estimator_, "model", registered_model_name="KNN_Tuning_Model")
# autolog 종료
mlflow.sklearn.autolog(disable=True)Keras Autolog
자동 로깅 범위
- 지금까지 사용한 코드에서
sklearn대신keras를 선언하면 된다. - train error, val error, 학습곡선, 모델 summary 등
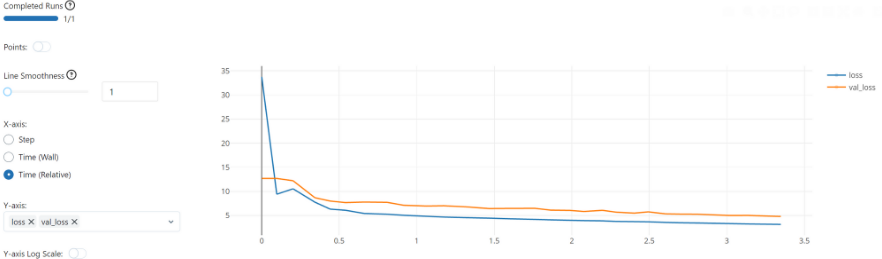
- 만약 성능 지표에 대해 자동/수동으로 남는 로그가 있다면 이를 학습 곡선으로 시각화 하는 것이 가능하다.
배포 관리
모델 라이프사이클 관리
- MLflow에서 모델의 라이프사이클은 네 가지 단계로 관리된다.
None
- 모델을 처음 등록한 상태
Staging
- 개발 중이거나 실험 진행 중인 모델이 저장되는 단계
- 모델을 운영환경에서 사용하기에는 부적합할 수 있다.
- 운영 환경에서 사용될 모델의 후보가 등록되어있는 단계이다.
Production
- 실제로 운영 환경에서 사용되는 모델을 저장하는 단계
- 여러가지 버전 중 Production 단계에 등록된 버전이 운영 시 적용된다.
Archived
- 운영 환경에서 더 이상 사용하지 않는 모델을 저장하는 단계
- 이전 버전을 추적 및 검토하기 위해 사용
- Archived의 모델을 꺼내어 다시 사용하는 것도 가능하다 (복구
현재 모델 상태 확인
- mlflow UI에서 상단의
Models메뉴를 통해 어떤 버전의 모델이 어떤 상태에있는지 확인할 수 있다.

- 마찬가지로 상태의 변경도 UI를 통해 쉽게할 수 있다.
모델 가져오기
- 파일 경로명을 입력해 파일을 읽어오듯이 mlflow에서 모델을 불러올 수 있다.
models:/<등록된 모델이름>/<버전>: 특정 버전을 불러온다models:/<등록된 모델이름>/상태: 특정 상태를 불러온다 (주로 운영상태인 것을 가져옴)- 가장 많이 사용되며 권장하는 방식
models:/<등록된 모델이름>/latest: 최신 버전을 불러온다
# 운영중인 버전 가져오기
model_uri = "models:/CarSeat/production"
model3 = mlflow.sklearn.load_model(model_uri)코멘트
그동안 모델의 결과를 체계적으로 저장하지 못하거나, 이전에 학습시켰던 모델을 저장하지 않아 오랜기간에 걸쳐 재학습해야하는 등 문제가 많았는데, mlflow를 사용하면 정말 편리하게 관리할 수 있겠단느 것을 깨달았다.
다만 아직 어떻게 서버에 무거운 모델을 탑재하지 않고 API를 이용해 모델을 돌릴 수 있을 지 모르겠다.
남은 미니프로젝트 과정에서 이를 배울 수 있으면 좋겠다.
