
서론
LRM(Large Reconstruction Model)은 이름 그대로 '큰' 3D Reconstruction 모델이다.
이전의 single image to 3D reconstruction 모델들은 주로 특정 카테고리에 대해서만 prior를 학습하여 새로운 카테고리를 생성하기 어려운 모델이거나, Stable Diffusion과 같은 pre-trained 2D 생성형 모델에 의존하여 3D를 생성하는 접근 방식을 취했다. 하지만 성능이 너무 떨어지거나, 너무 많은 연산이 필요하거나 하는 등 2D 이미지나 자연어 처리 분야에 비해 발전이 덜 이루지고 있었다.
LRM의 저자들은 2D 이미지, 자연어 처리가 지금처럼 큰 성공을 할 수 있었던 것은 아래의 세 가지 요인이 있다고 보았다.
Transformer와 같이 확장성이 크고, 효율이 좋은 모델 아키텍처- 학습을 위한 막대한 양의 데이터셋
- 새로운 data structure를 학습할 수 있는 높은 확장성의 self-supervised-like 학습
LRM의 저자들은 이를 3D 분야에도 동일하게 적용한다면, 즉 충분한 3D 데이터를 갖고 large-scale training 프레임워크로 학습한다면 single image만으로도 3D reconsturction을 할 수 있는 충분한 3D prior를 학습 할 수 있다는 가정을 바탕으로 LRM을 제안했다.
Triplane Representation
LRM을 알아보기에 앞서 먼저 Triplane Representation에 대해 간략히 알아보자
이는 Efficient Geometry-aware 3D Generative Adversarial Networks 논문에서 제시된 3D 데이터를 표현하는 방법이다.
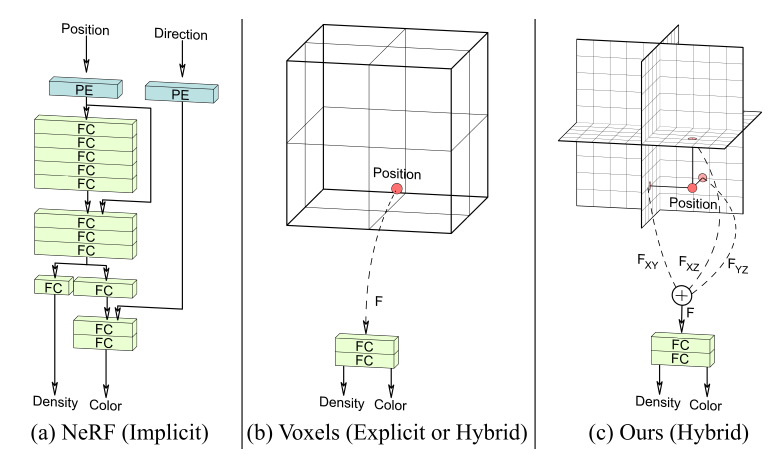
기존의 Explicit representation(Voxel, Point Cloud 등)은 2D 이미지에 비해 사실상 하나의 차원이 더 필요한 방법이기 때문에 너무 많은 메모리가 필요하다는 문제가 있었다. 반면 Implicit representation(NeRF 등)의 경우 Network Parameter만 저장하면 되지만 매 시점을 렌더링 할 때마다 MLP 연산을 거쳐야 해서 실시간 렌더링이 어렵다는 문제가 있다.
Triplane representation은 이 둘의 장점을 합쳐 Explicit에 비해 적은 메모리를 사용하면서, 렌더링에 필요한 연산 역시 실시간 렌더링이 가능할 정도로 줄이고자 한 Hybrid representation 방법이다.
렌더링 과정
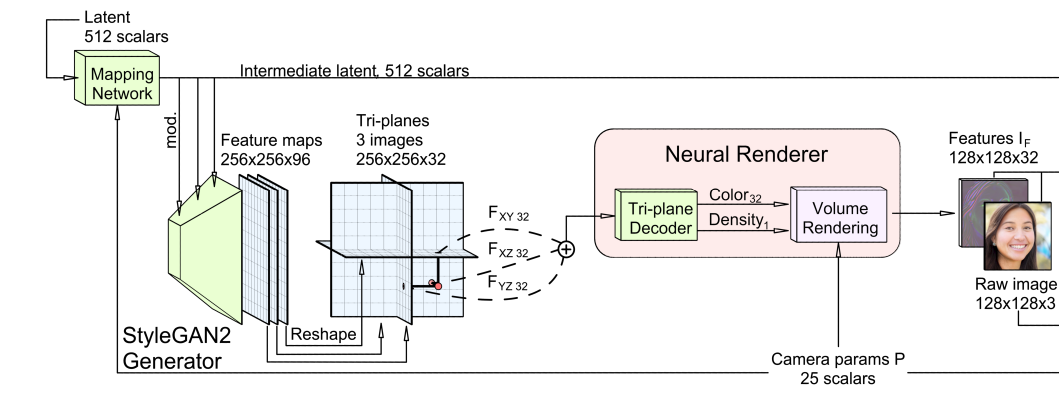
기본적으로 NeRF와 같은 Volumetric rendering 과정이지만, input으로 Triplane feature를 사용한다.
0-1. 렌더링에 앞서 triplane이 될 feature map(triplane)을 생성한다. 각 평면의 크기는 이다.
0-2. feature map을 3개의 직교 평면으로 나눈다. 실제로 나누는 것은 아니고 feature map에 투영하는 각 평면의 투영 행렬(기저 벡터)을 정의한다.
// 투영 행렬 정의
def generate_planes():
return torch.tensor([[[1, 0, 0],
[0, 1, 0],
[0, 0, 1]],
[[1, 0, 0],
[0, 0, 1],
[0, 1, 0]],
[[0, 0, 1],
[1, 0, 0],
[0, 1, 0]]], dtype=torch.float32)- 3D position과 같은 explicit feature를 투영 행렬을 이용해 투영하여 2D 좌표값을 얻는다.
- 2D 좌표값을 바탕으로 각 triplane feature map에서 feature 값을 얻는다. 예를 들어 feature map의 크기가 이고 2D 좌표값이 (17.56, 101.71)과 같이 주어진다면
featuremap[17][101], featuremap[18][101], ...등의 값을 선형 보간 하는 방식으로 얻을 수 있다.
이렇게 얻은 feature 벡터의 크기는 이며, 세 개의 triplane으로 부터 각각 3개의 특징()을 얻을 수 있다.
// 투영 및 feature vector 연산
def sample_from_planes(plane_axes, plane_features, coordinates, mode='bilinear', padding_mode='zeros', box_warp=None):
assert padding_mode == 'zeros'
N, n_planes, C, H, W = plane_features.shape
_, M, _ = coordinates.shape
plane_features = plane_features.view(N*n_planes, C, H, W)
coordinates = (2/box_warp) * coordinates # TODO: add specific box bounds
projected_coordinates = project_onto_planes(plane_axes, coordinates).unsqueeze(1)
output_features = torch.nn.functional.grid_sample(plane_features, projected_coordinates.float(), mode=mode, padding_mode=padding_mode, align_corners=False).permute(0, 3, 2, 1).reshape(N, n_planes, M, C)
return output_features- 3개의 특징을 합산하여 하나의 Feature Vector()를 만든다.
- Feature Vector 입력으로 color, density를 출력하는 decoder를 통해 Volume Rendering을 수행해 2D 렌더링 이미지를 얻는다.
전체 코드는 eg3d github에서 확인할 수 있습니다.
LRM

LRM으로 돌아와서 LRM의 프로세스는 크게 아래와 같이 구성된다.
- Image encoder를 통해 input image의 feature vector 생성
- Transformer 구조의 모델을 통해 feature vector를 의 feature map으로 표현. (여기서 feature map이 앞서 설명한 triplane의 역할을 함)
- Triplane 기반의 Volumetric Rendering (앞서 설명한 렌더링 과정과 유사)
1. Image Encoder

Image는 DINO라는 ViT(Vision Transformer) 기반의 사전 학습된 모델을 사용한다.
ViT는 이미지를 일정 크기의 patch로 쪼개어 Transformer가 문장 시퀀스를 학습하듯이, patch 단위로 이미지 시퀀스를 학습하는 모델이다.
구체적으로는 입력 이미지를 feature token 으로 인코딩한다.
- : 총 패치의 개수
- : i번째 패치임을 나타냄
- : 인코더의 latent 차원 크기
또한, 기존 ViT와 달리 이미지를 대표하는 [CLS] 토큰만 사용하는 대신 전체 feature token을 사용하여 정보를 더 잘 보존한다고 한다.
아마 이미지와 달리 3D 정보를 나타내야 하기 때문에 더 큰 크기의 feature를 사용하기 위해 이렇게 한 것으로 추정된다.
2. Image to Triplane Decoder

최초에는 랜덤한 값으로 positional embeddings를 초기화한다. 단순히 랜덤한 값으로 초기화하지는 않고, scaling factor를 사용해 파라미터가 일정 범위를 갖도록 하여 학습 안정성과 효율성을 높인다고 한다.
이 positional embeddings은 학습 가능한 파라미터로써, 입력된 image feature와 camera feature가 투영되고, 이것이 DeConv 및 Reshape 과정을 거쳐 Triplane representation으로 변환된다.
Camera Feature
Camera feature ()는 다음과 같다.
- : 4x4 camera extrinsic matrix를 flatten한 것
- : normalized focal length
- : normalized principal point
여기서 similarity transformation을 통해 모든 카메라가 동일한 축에서 z축 방향을 바라보도록 를 normalize한다.
이는 학습 때만 적용되며, optimization space를 줄이고, 수렴을 용이하게 하기 위함이라고 한다.
이 camera feature를 그대로 사용하지 않고, MLP를 통해 보다 고차원의 camera embedding 으로 만들어 사용한다.
Triplane Representation
앞서 설명한 것과 같다.
LRM에서는 각 triplane이 ()의 크기를 갖도록 하였다. triplane의 차원 크기(가 정보를 얼마나 디테일하게 저장할지를 결정한다고 볼 수 있는데, 여기서는 으로 사용하였다.
이를 위해 () positional embedding을 초기화하여 transformal 네트워크를 통과한 후, 최종적으로 upsampling을 거쳐 triplane representation 가 된다.
Modulation with Camera Feature
이전 레이어의 출력값은 곧바로 다음 레이어의 입력값으로 사용되지 않고 modulation 과정을 거친다.
이는 Diffusion Transformer(Peebles & Xie, 2022) 논문에서 adaptive layer norm(adaLN) 기법을 통해 image latent를 modulate하는 것에 영감을 받았다고 한다.
자세히는 알아보지 못했지만, 기존에 사용되는 layer normalization 기법에서 learnable한 값을 사용하는 대신 camera embedding을 활용해 scale(), shift() 값을 얻는다.
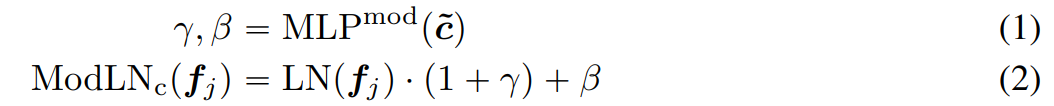
camera embedding 를 modulation을 위한 에 통과시켜 scale, shift 값을 얻어 layer normalization에 사용한다.
이렇게 정규화된 feature ()가 다음 서브 레이어의 입력으로 사용된다.
adaLN을 적용하면 기존의 LN에 비해 어떤 장점이 있는걸까? 이건 차차 공부해봐야 할 것 같다.
Transformer layer

각 레이어는 3개의 서브 레이어로 구성된다.
cross-attention sub layer
image encoder를 거쳐 만들어진 image feature와 cross attention을 수행하는 layer
2D 이미지와 3D triplane간의 관계를 학습하도록 의도된 레이어이다.
self-attention sub layer
self-attention을 통해 공간적으로 구조화된 triplane entries의 intra-model 관계를 더욱 모델링한다고 한다.
transformer에 대한 이해가 부족해서 그런지 아직 어떤 역할을 하는지 잘 이해되지 않는다.
MLP sub-layer
original transformer 구조를 따라 MLP를 통과하여 다음 레이어로 전달될 최종 output triplane feature()을 출력한다.
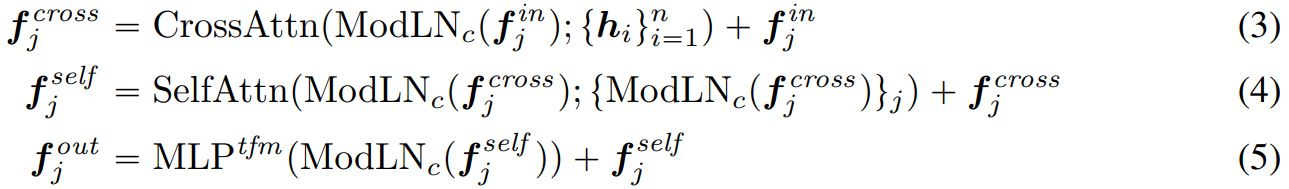
이러한 구조는 Perceiver network (Jaegle et al., 2021)에서 영향을 받았다고 하며, input feature를 latent bottleneck 투영하는 대신 attention 레이어만을 거쳐 고차원 구조를 유지한다.
이는 차원 압축으로 인한 정보 손실을 최소화 하기 위한 것으로 보인다.
Triplane-NeRF

이는 앞서 설명한 렌더링 과정과 동일하다.
학습 구현
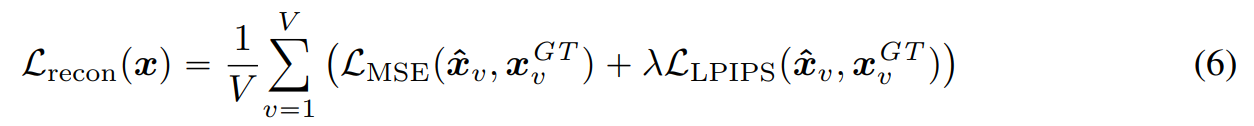
최종적으로는 위와 같은 과정을 거쳐 렌더링한 이미지 ()와 GT 이미지()와의 이미지 loss를 통해 학습이 이루어진다.
각 training data마다 V-1개의 랜덤한 side view를 선택하여 지도 학습을 진행한다.
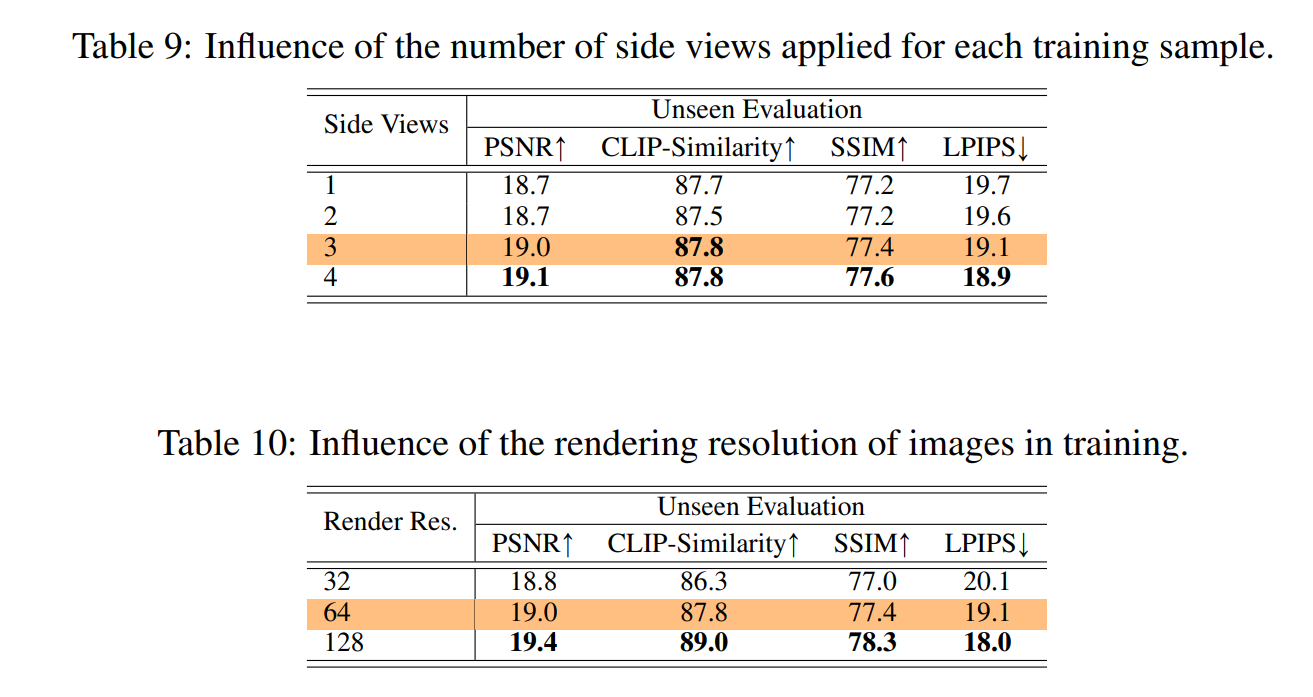
논문에서는 3개의 side view를 이용해 총 샘플 당 4개의 이미지를 사용했다고 한다.
더 많은 side view를 사용하면 어떨까 싶은데 아마 학습 시간 및 필요한 메모리가 증가하기 때문에 3개로 타협한게 아닌가 싶다.
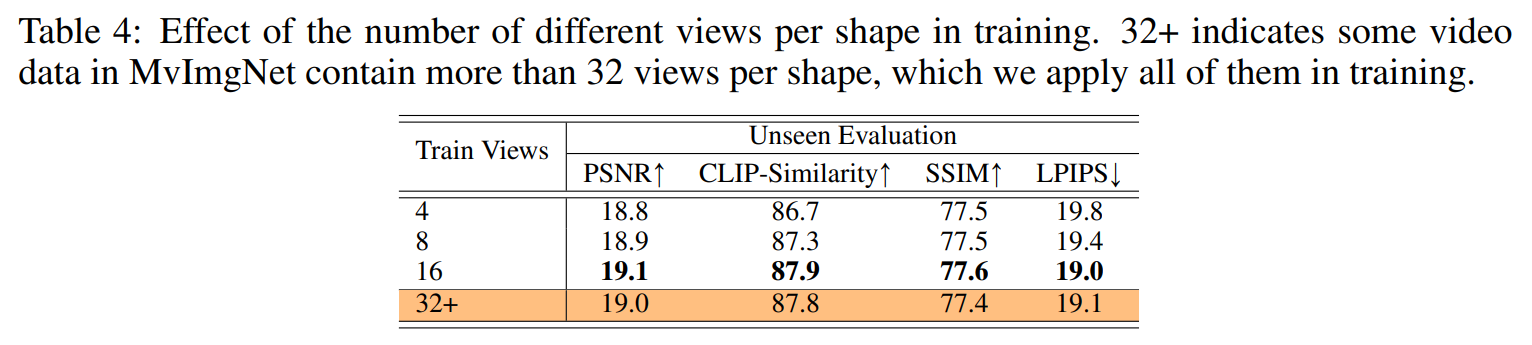
정확히는 4개의 이미지만 이용한 것은 아니고, 32+개의 이미지 중 매 학습 시에 4개를 샘플링하는 방식을 사용했다고 한다.
이는 view 후보가 많을 수록 더 다양한 시점을 학습할 수 있기 때문이라고 생각한다.
모델은 128개(!?)의 A100 GPU를 사용해 3일 동안 30 에포크를 학습했다고 한다.
결과

추론 시에는 A100 GPU하나로 5초 내에 모든 과정이 끝난다고 한다.
휴대폰 사진과 같은 wild한 이미지에도 비교적 잘 동작하는 것으로 보이며, single image임에도 5초라는 짧은 시간에 이정도 수준의 모델이 나온다는걸 보면 정말 발전이 빠른 것 같다.
참고 자료
LRM 공식 프로젝트 페이지
glorious_purpose - LRM: LARGE RECONSTRUCTION MODEL FOR SINGLE IMAGE TO 3D
kyujinpy - [Diffusion Transformer 논문 리뷰3] - Scalable Diffusion Models with Transformers

안녕하세요, 훌륭한 포스트 잘 보았습니다. 구조적으로 잘 설명해주셔서 감사합니다 👍🏻
혹시 중간에 나오는 cross attention에 관해서는, Q가 learnable positional encoding map으로부터 출발한 feature가 쓰이고, K및 V는 image feature가 쓰이는지 궁금합니다. 2D와 3D간의 관계를 잘 학습하기 위해서라고 하셨는데, 정확히 어떤 의미로 사용하신 말인지도 여쭙고 싶습니다. 감사합니다!