오늘은 tensorflow playground에서 시간을 좀 보냈다.
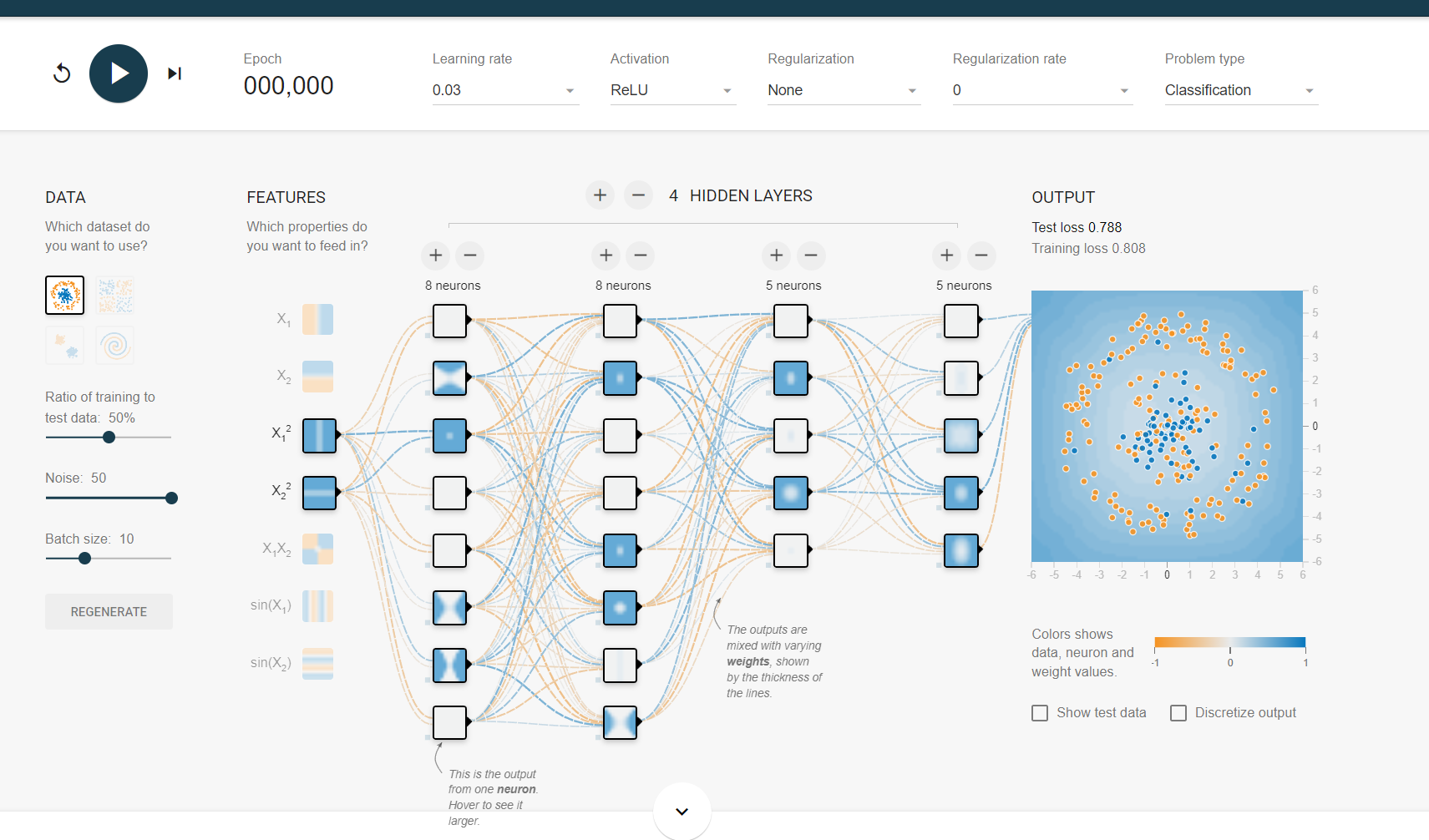
Dataset은 총 4개가 있다. 데이터 부분 중 ratio of training to test data는 50%, Noise는 50, Batch size는 10으로 고정하고 진행했다.
Feature
다음으로 Feature에서는 어떤 property를 feed in할 지 고르는 것이다. 경험상 아래와 같은 결론을 내렸다.
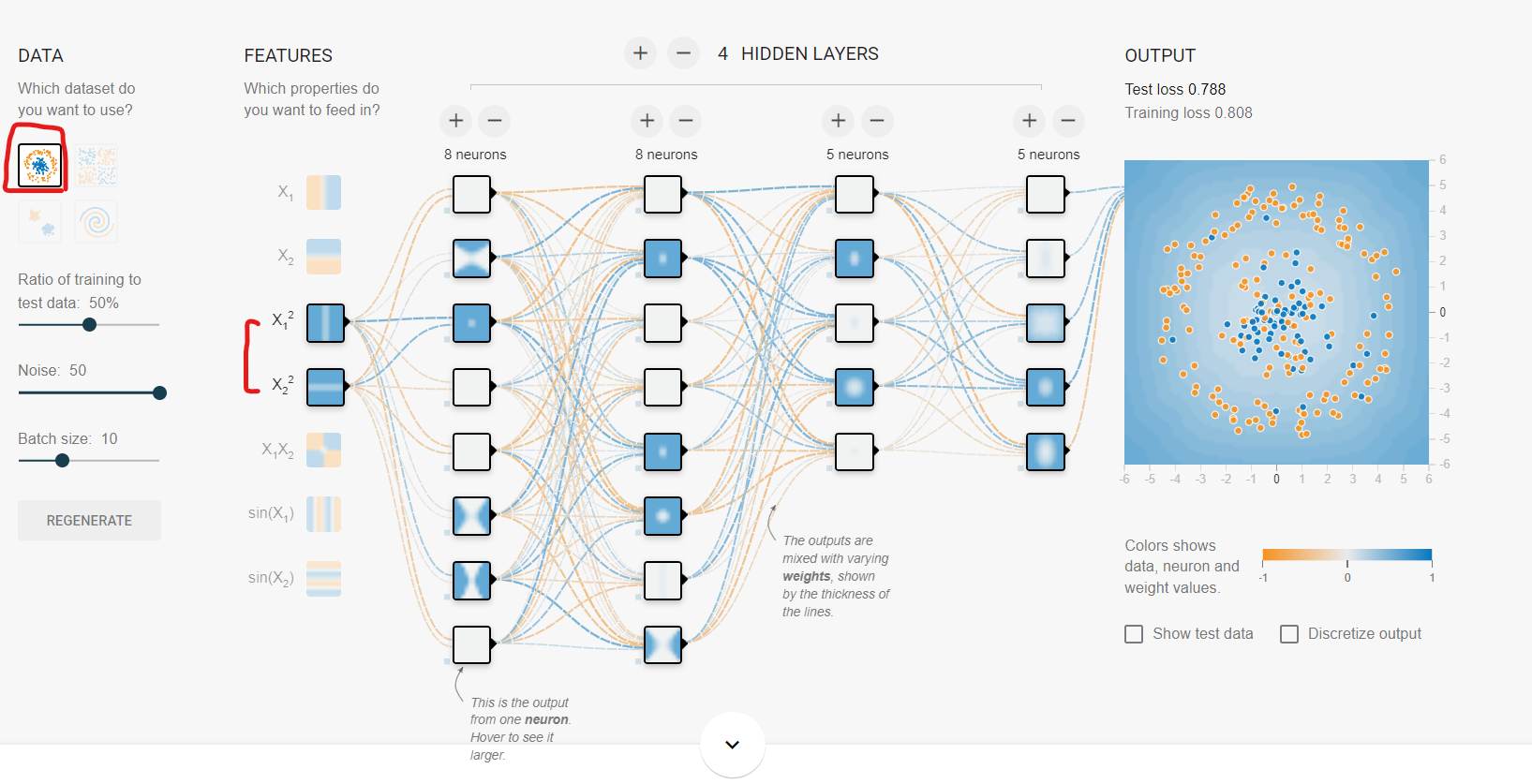
Circle에서는 제곱 2개
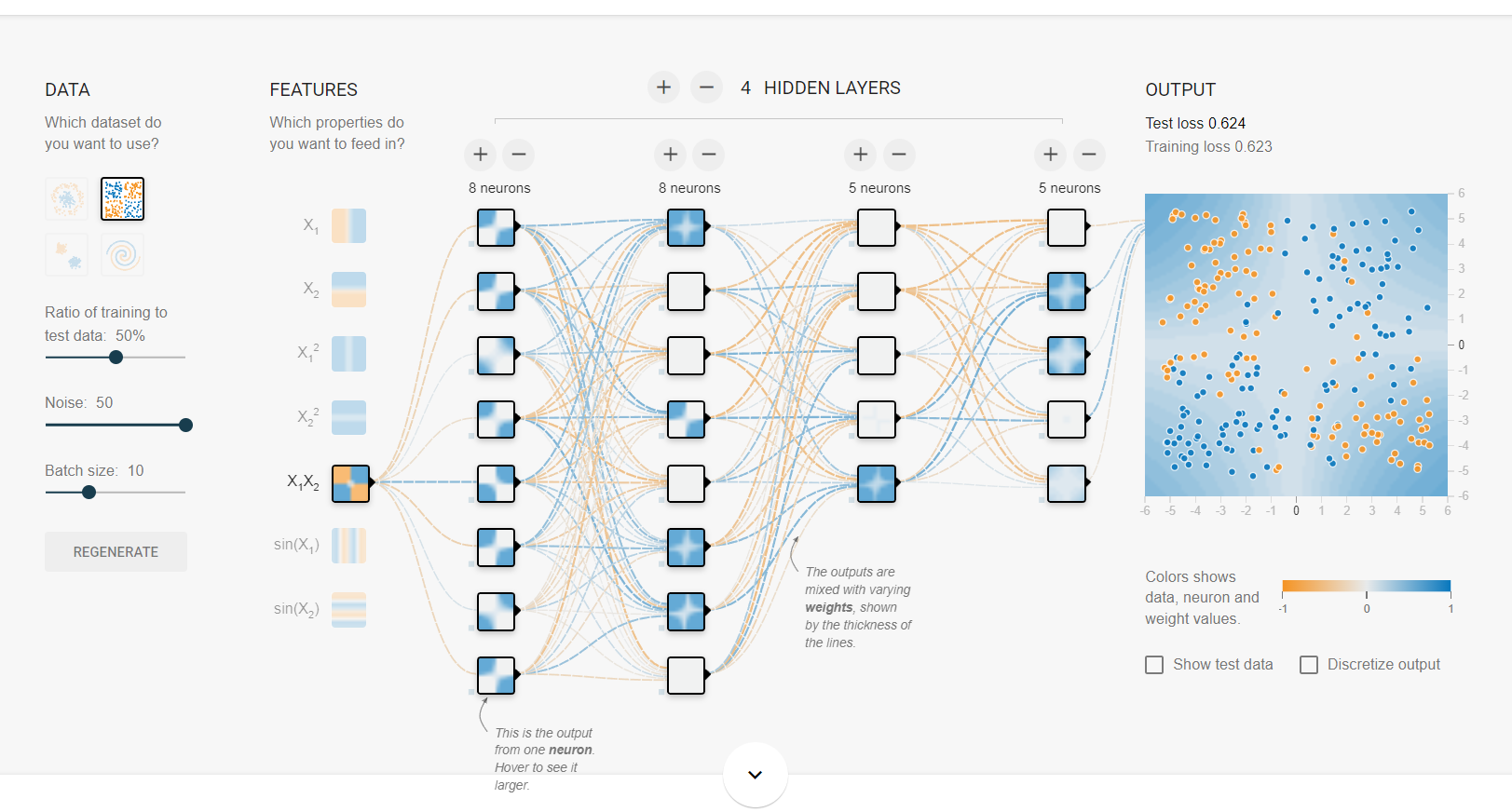
Exclusive or에서는 x1x2 1개
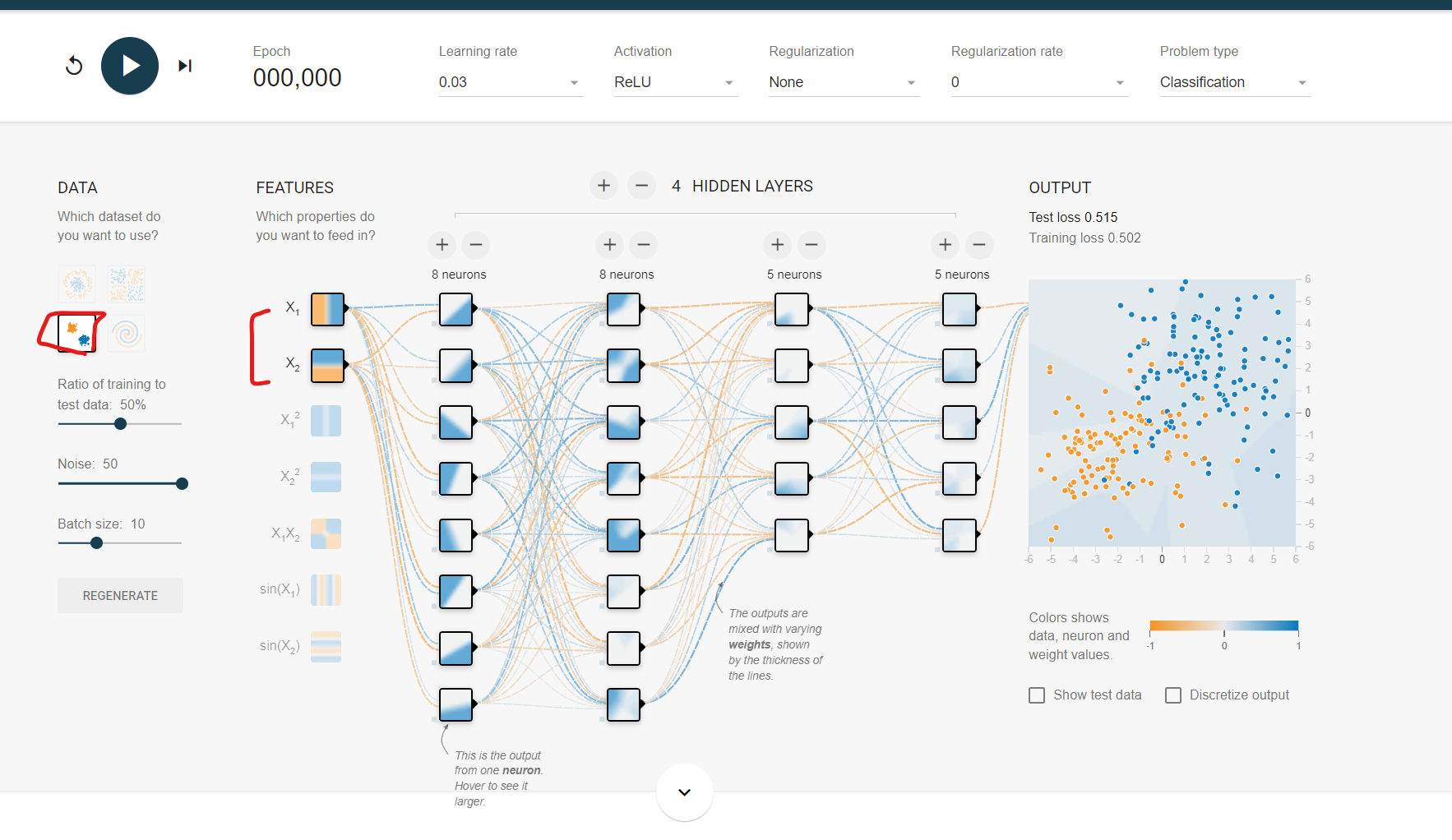
Gaussian에서는 x1, x2 2개
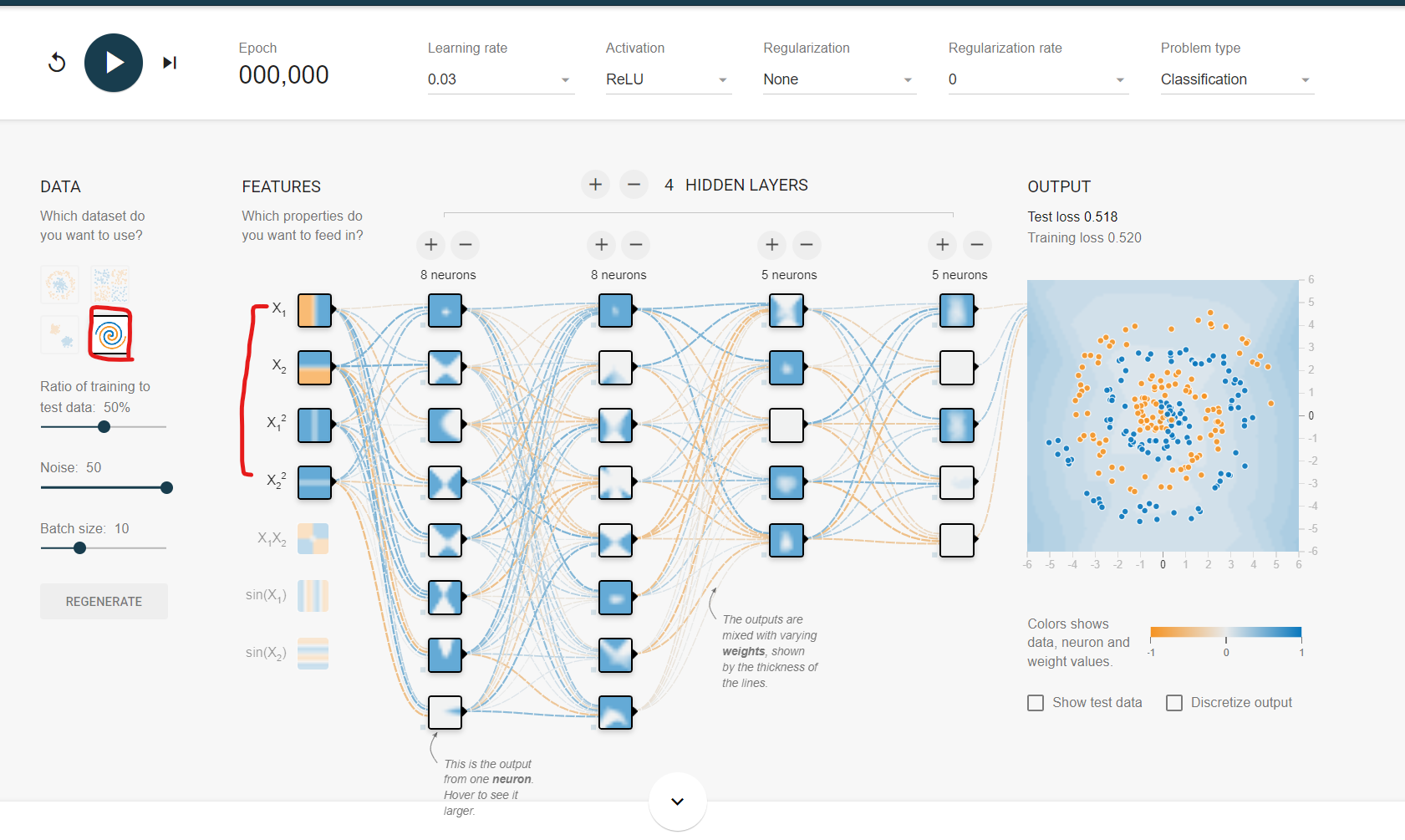
Spiral에서는 x1, x2, x1^2, x2^2 4개를 feed in하는 것이 효율적이다.
사실 노이즈가 없을 때 그래프를 그리는 방식을 생각해보면 좀 더 이해가 갈 것이다.
노이즈는 설정할 때마다 케이스가 다르며 이 때문에 결과도 항상 달라진다.
Activation
Sigmoid는 hidden layer의 수가 많아지면 값이 제대로 나오지 않는다.

열심히 성장 중인 백엔드