오늘은 Attention Is All You Need (Transformer)에 대한 간단한 리뷰이다.
Model Architecture
Encoder and Decoder Stacks
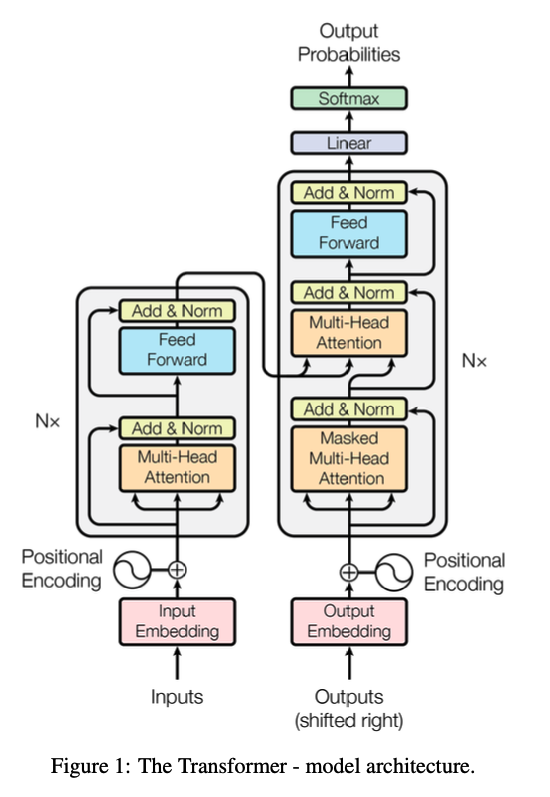
위와 같이 layer가 구성된다. 왼쪽이 Encoder, 오른쪽이 Decoder이다.
Attention
Attention은 query, key, value의 역할을 하는 세 벡터로 이루어진다. Attention의 아웃풋은 value의 weighted sume이고, value에 할당되는 weight는 query와 key를 통해 계산된다.
Scaled Dot-Product Attention
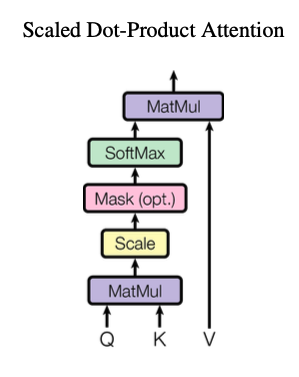
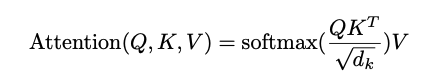
query와 key의 차원인 로 나눠줌으로써 gradient가 소실되는 문제를 막아준다.
Multi-Head Attention
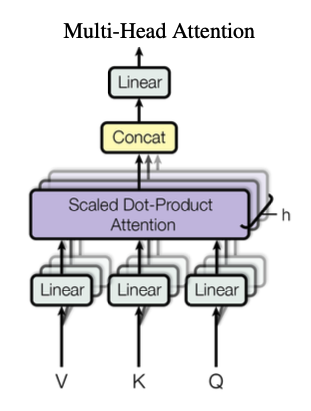

Multi-Head Attention은 각각의 다른 위치의 서로 다른 정보를 가져와 Attention에 반영할 수 있도록 한다.
Multi-Head Attention을 적용함으로써, decoder의 모든 위치가 input sequence의 모든 위치에 attend할 수 있도록 해주고, 이것은 Seq2seq 모델에서 사용된 메커니즘과 유사하다.
또한, encoder에서는 self-attention을 사용함으로써 각각의 단어가 서로 관여할 수 있도록 하였고, decoder에서는 masked self-attention을 통해 현재 단어의 뒤쪽은 보지 못하도록 하여 auto-regressive한 속성을 보존하도록 하였다.
Position-wise Feed-Forward Networks
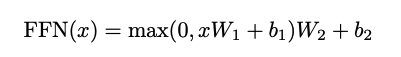
Feed-Forward Network에서는 일반적인 linear transformation을 적용한다.
Positional Encoding
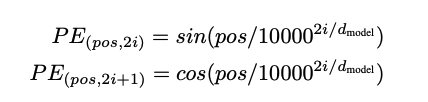
위와 같은 positional encoding을 모델에서 sequence를 임베딩할 때 더해줌으로써 위치정보를 담았다.
Why Self-Attention

Convolution과 Recurrent, Self-Attention을 비교한 표이다. 위의 장점 말고도, attention을 확인함으로써 해석가능하다는 장점도 있다.
Results
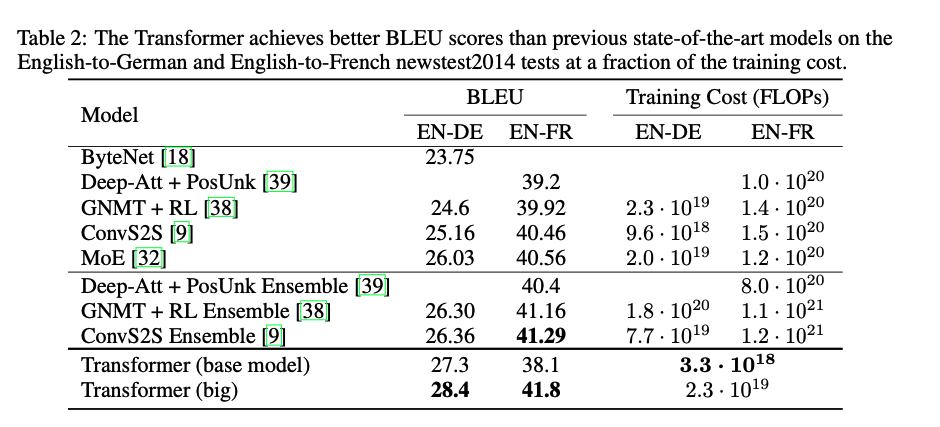
Training Cost를 고려하고도 굉장히 좋은 성능을 보여주고 있다.
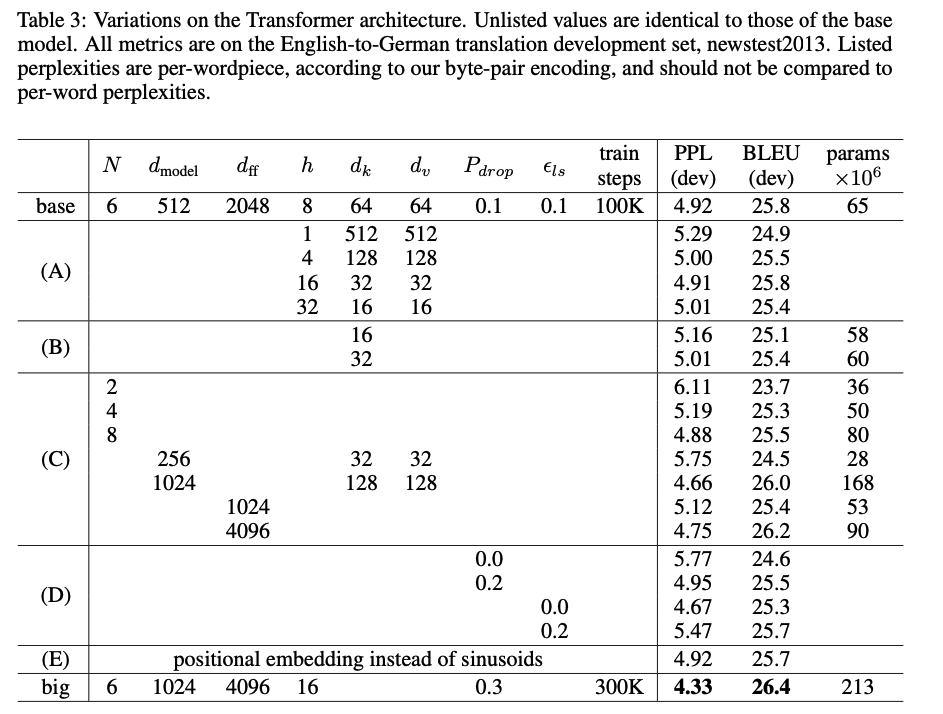
다양한 하이퍼파라미터에 대한 비교표이다.
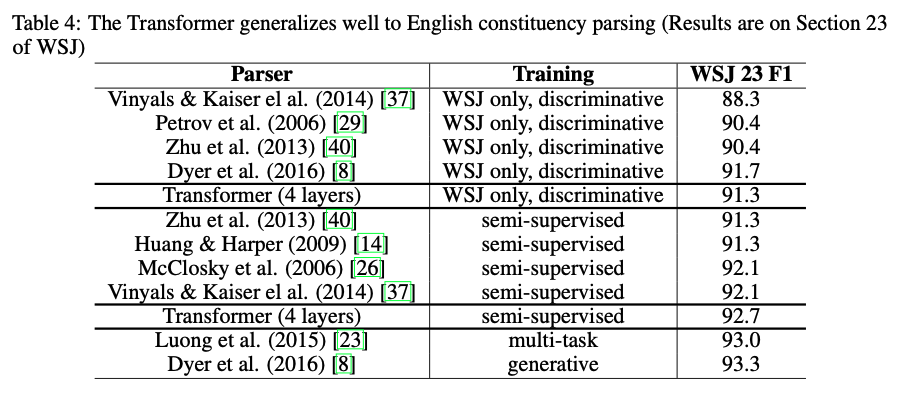
영어 구문 분석 task에서도 좋은 성능을 보여주고 있다.
후기
오늘은 그 유명한 transformer 논문을 읽어보았다. conclusion에 미래의 attention-based model과 다른 task에서의 transformer 활용이 기대된다고 작성되어 있는데, 현 상황을 생각해보면 소름돋기 그지없다. 이런 논문을 내가 사는 시대에 읽을 수 있어서 다행이라는 생각을 했다. 다음 논문은 BERT가 될 것이다.
