오늘은 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding에 대한 간단한 리뷰이다.
BERT
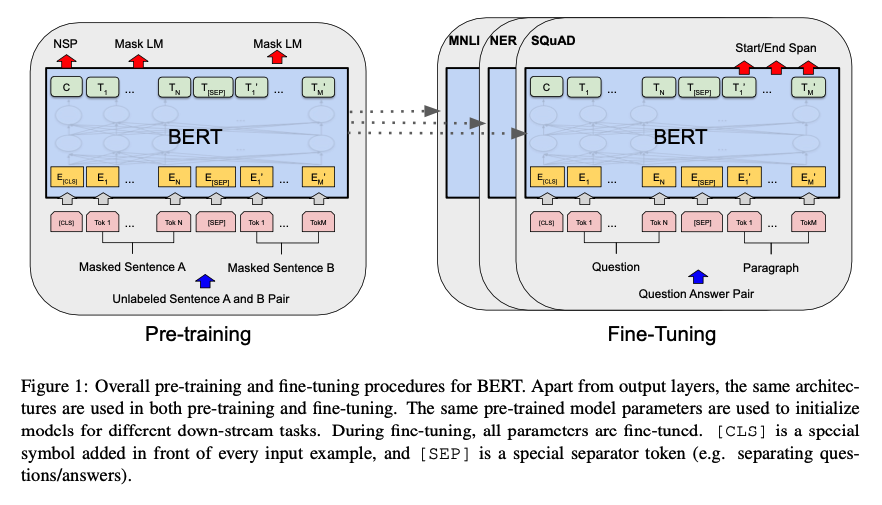
pretrained와 fine-tuning 두 가지로 이뤄진다.
Model Architecture
multi-layer bidirectional Transformer encoder이다.
Input/Output Representation
WordPiece embedding을 사용하고, 모든 sequence의 첫 번째 토큰은 special token은 [CLS]가 들어간다. 이 토큰은 나중에 아웃풋으로 나왔을 때는 classification task를 위한 aggregate sequence representation으로 사용된다. 또한 문장 페어의 경우, 또다른 special token인 [SEP]으로 나눠진다. 또한 모든 토큰에 learned embedding을 추가하여 어떤 문장에 종속되어 있는지를 표현한다.
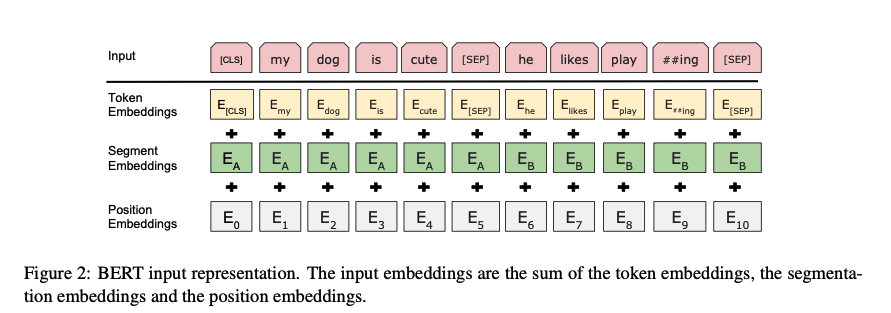
정리하자면 위와 같이 token embedding과 segment embedding, position embedding의 합으로 표현된다.
Pre-training BERT
BERT는 두 가지 task로 pretrain된다.
Task #1: Masked LM
bidirectional한 representation을 학습시키기 위해서, input token의 일부분을 지우고 그것을 예측하도록 학습시킨다. 하지만 fine-tuning에서는 mask가 없기 때문에, pretrain할 때 토큰 위치 중 15%를 랜덤으로 선택하고, 그 중 80프로를 [MASK] 토큰으로 대체, 10프로는 다른 랜덤 토큰으로 대체, 나머지 10프로는 바꾸지 않은 채로 놔둔다.
Task #2: Next Sentence Prediction (NSP)
문장 관계를 학습시키기 위해서, next sentence prediction task를 적용한다. 문장 A와 B가 있을 때, 샘플의 반은 실제 B 문장으로, 나머지 반은 무작위 문장으로 채운다. 간단한 방식이지만, QA와 같은 task에서 성능 향상에 기여했다고 한다.
Fine-tuning BERT
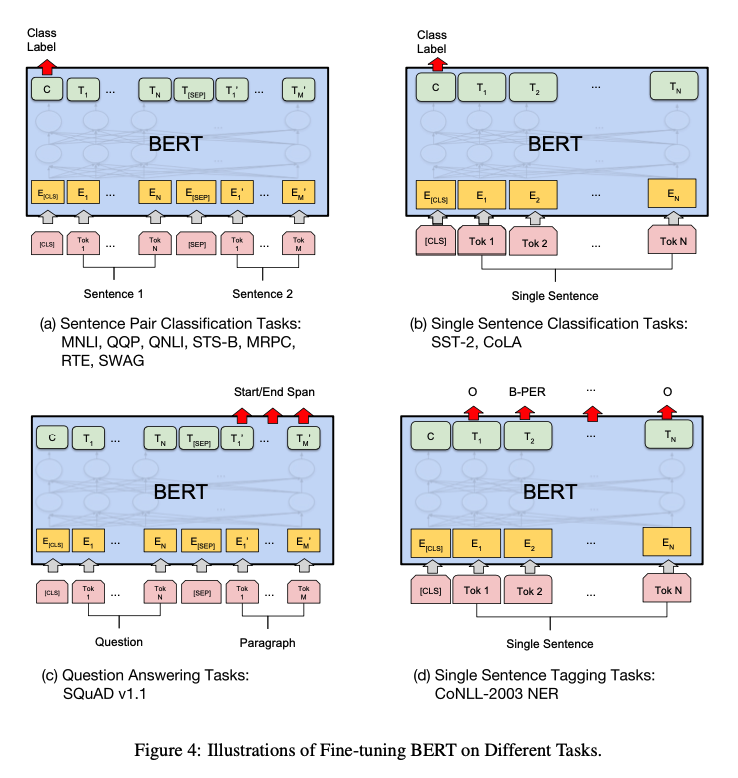
Fine-tuning을 할 때는 pretrained된 BERT 모델에 task-specific한 input과 output을 붙이고 모든 파라미터를 fine-tuning 시킨다.
Experients
GLUE
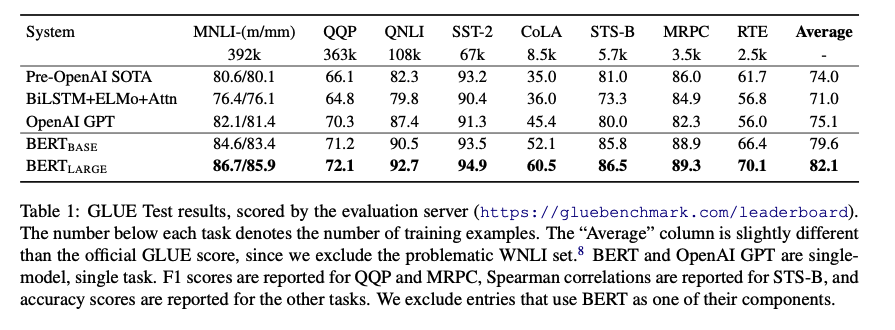
다양한 NLP task를 다루는 GLUE 벤치마크에서 기존 모델 대비 상당히 좋은 성능을 보여주고 있다.
SQuAD v1.1, SQuAD v2.0
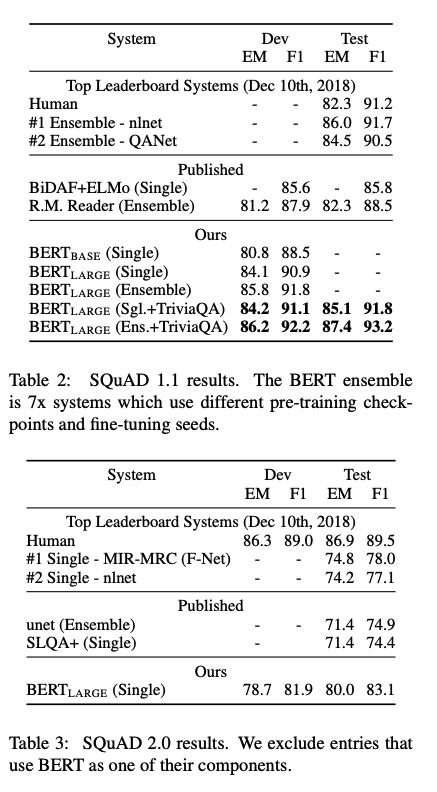
QA task에서도 sota 성능을 보여주고 있다.
SWAG

sentence-pair completion task인 SWAG dataset에 대해서도 상당한 성능을 보여준다.
Ablation Studies
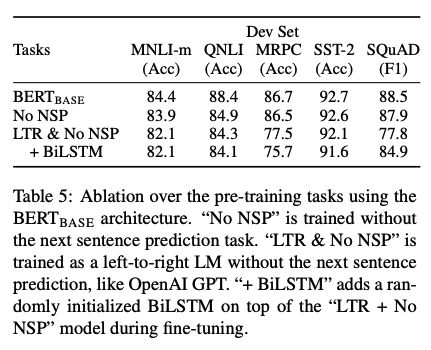
bidirectionality에 대한 성능, NSP task를 pretrain 과정에 반영한 것에 대한 성능을 비교할 수 있다.
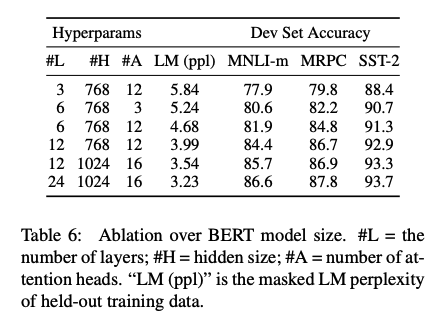
모델 사이즈에 따른 성능 변화이다.
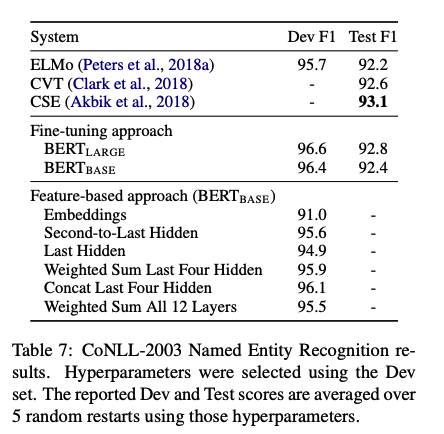
또한 fine-tuning 방식에 비해 몇 가지 장점을 가지는 feature-based approach에도 BERT를 적용해보았는데, 괜찮은 성능을 보여줬다고 한다.
후기
오늘도 굉장히 유명한 모델인 BERT를 알아보았다. bidirectional을 적용했고, next sentence prediction을 pretrain에 반영한 것이 특징인 모델이었다. pretrain에서 언어에 대한 특징을 학습하고, fine-tuning 과정에서 task에 알맞게 적응해가는 과정이 신기했고, NLP에 관심이 CV만큼 있지는 않았는데 굉장히 많은 생각을 하게 되는 논문이었던 것 같다. 다음 글은 BART이다.
