오늘은 BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension에 대한 간단한 리뷰이다.
Model
BART는 손상된 문서를 원래의 문서로 복구하는 denoising autoencoder이다. encoder는 bidirectional encoder로, decoder는 left-to-right autoregressive decoder로 구성되었다.
Architecture
BART는 일반적인 seq2seq transformer 구조를 따라가는데, ReLU를 GeLU로 바꾸고 initial paramter를 에서 샘플링한다.
base 모델로는 인코더와 디코더 각각에 6개의 layer를, large model에는 12개의 layer를 사용한다. 구조는 BERT와 유사한데, 다른 점은 디코더의 각 레이어가 인코더의 마지막 레이어와 추가적인 cross-attention을 한 다는 점과 BERT는 word prediction 전에 feed-forward network가 있었는데 BARt는 없다는 점이다.
Pre-training BART
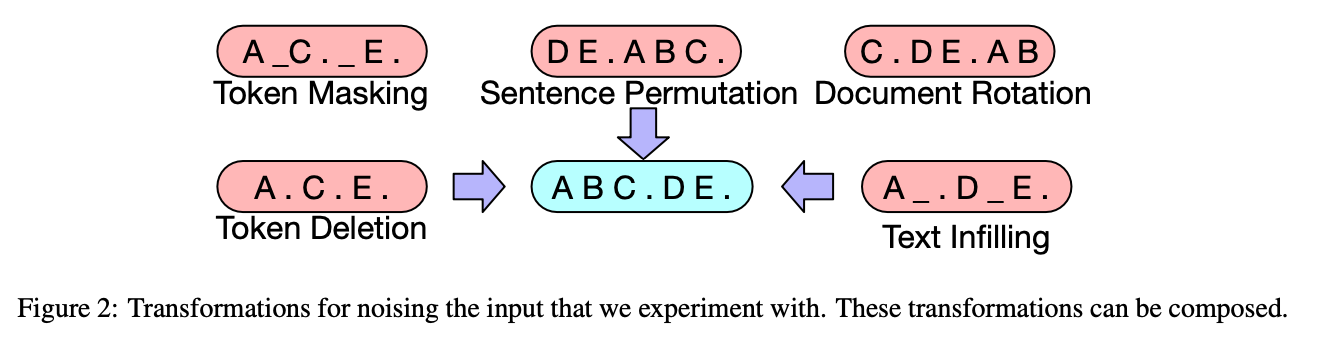
손상된 문서를 복구하는 작업을 수행하기 위해서 pretrain할 때 여러 방법이 사용되었다.
Token Masking
BERT처럼 랜덤 토큰을 MASK 토큰으로 바꾼다.
Token Deletion
랜덤 토큰을 지운다. 모델은 지워진 위치도 결정해야 한다.
Text Infilling
text span이 하나의 MASK 토큰으로 대체된다. 0-length도 허용되어서 그냥 MASK 토큰만 문장 어딘가에 들어갈 수도 있다.
Sentence Permutation
문장을 섞는다.
Document Rotation
한 개의 토큰이 선택되고, doucment는 그 토큰이 맨 앞에 오도록 rotate된다.
Fine-tuning BART
다양한 downstream task에서 활용될 수 있다.
Sequence Classification Tasks
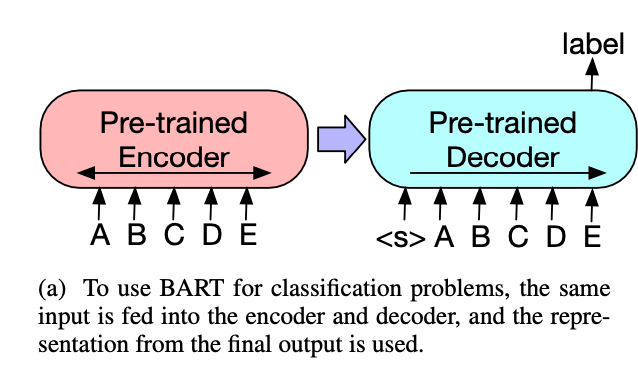
동일한 인풋이 encoder와 decoder에 들어가고, 마지막 hidden state가 multi-class linear classifier에 들어가 classification task를 수행한다. 다만 BERT와 다르게 CLS token이 문장의 맨 마지막에 들어가서 전체 문장에 attend할 수 있도록 하였다.
Token Classification Tasks
전체 문서를 encoder와 decoder에 인풋으로 주고, 마지막 hidden state를 classifier에 넣어 classification을 수행한다.
Sequence Generation Tasks
BART는 decoder가 autorgressive하기 때문에, sequence generation task에서 fine-tuning될 수 있다. 그래서 인풋으로 문장을 받으면 아웃풋으로 문장을 autoregreessive하게 생성한다.
Machine Translation
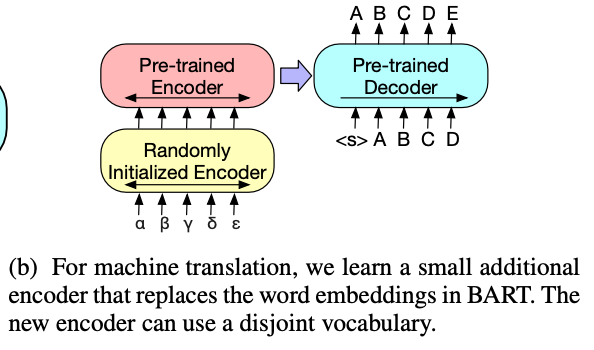
machine translation task에도 BART의 전체 모델을 사용할 수 있는데, BART encoder의 embedding layer를 다른 encoder로 바꾸고, end-to-end로 학습시켜서 새로 추가한 encoder가 외국어를 BART가 영어로 denoise할 수 있는 형태로 바꿔주도록 한다.
two-step으로 학습이 이뤄지는데, 첫 번째는 BART 파라미터의 대부분을 얼리고, 새로 추가하나 encoder와 BART의 positional embedding, BART encoder의 첫번째 layer의 self-attention projection matrix만 학습한다. 이후 모든 모델의 파라미터를 학습시킨다.
Comparing Pre-training Obejectives
Comparison Objectives
BART의 base model과 비교할 모델들이다.
Language Model
GPT와 유사한 left-to-right Transformer language model이다.
Permuted Languge Model
XLNeet을 베이스로 한 모델로, 1/6의 토큰을 샘플링해서 그것들을 autorgressive하게 랜덤한 순서로 생성한 데이터를 학습시킨 모델이다.
Masked Language Model
BERT와 유사한 모델이다.
Multimask Masked Language Model
UniLM처럼, Masked Language Model을 추가적인 self-attention mask로 학습시킨 모델이다.
Masked Seq-to-Seq
MASS에서 영감을 받아서, 50프로의 토큰을 포함하는 span을 mask하고, 이것을 예측하는 seq2seq 모델이다.
Tasks
- SQuAD: QA task
- MNLI: bitext classification task
- ELI5: long-form abstractive QA task
- XSum: summarization task
- ConvAI2: dialogue response generation task
Results
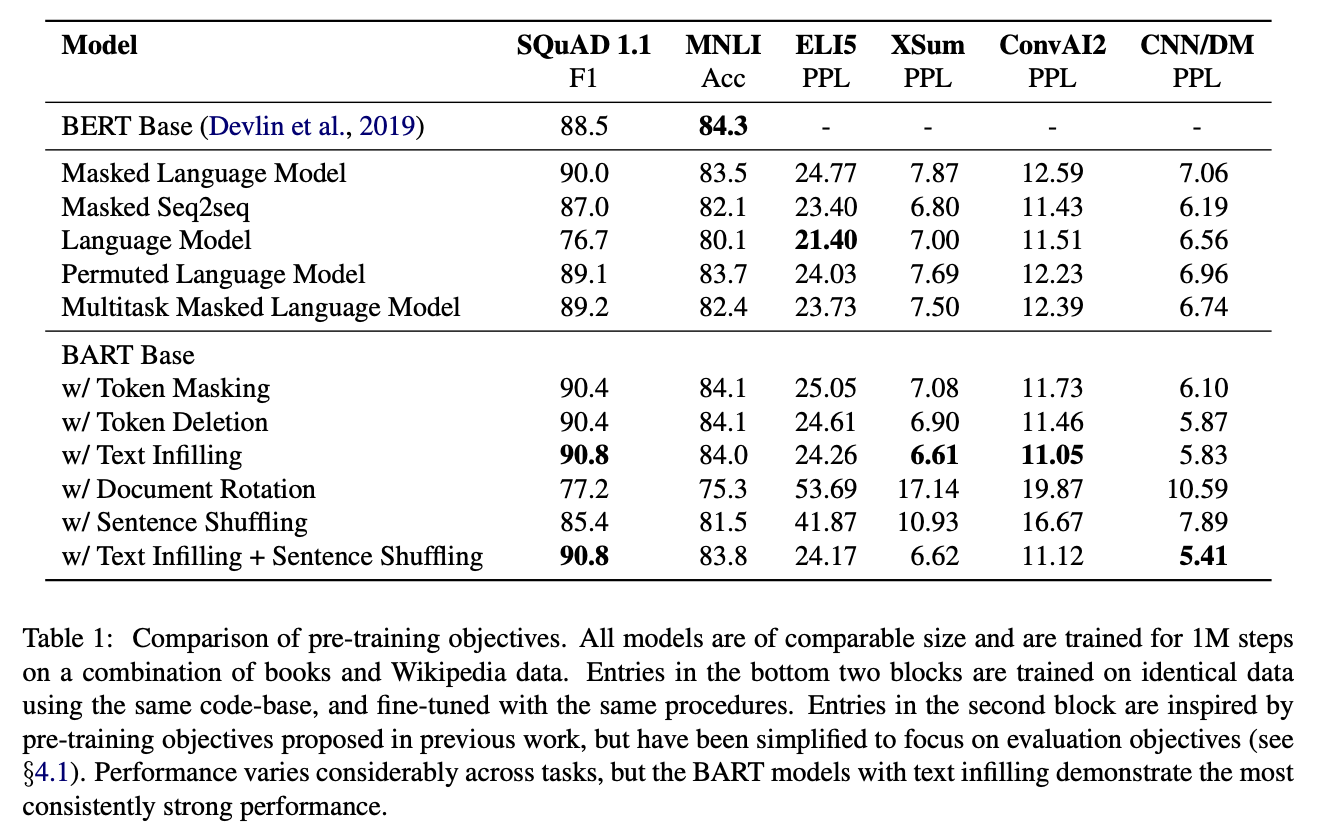
위와 같은 성능을 보여주고 있다.
Large-scale Pre-training Experiments
앞의 실험에서 가장 높은 성능이 나온 text infilling과 sentence shuffling을 학습할 때 사용하고, 모델 크기를 키워서 다시 실험을 진행하였다.
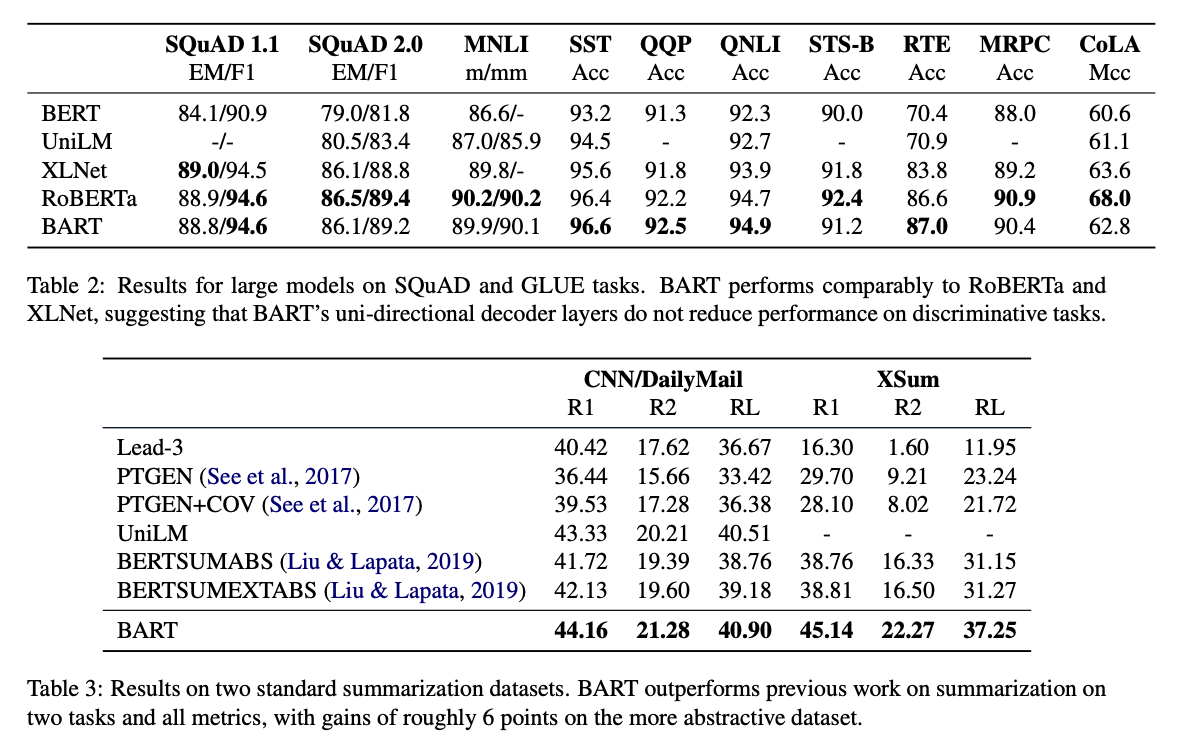
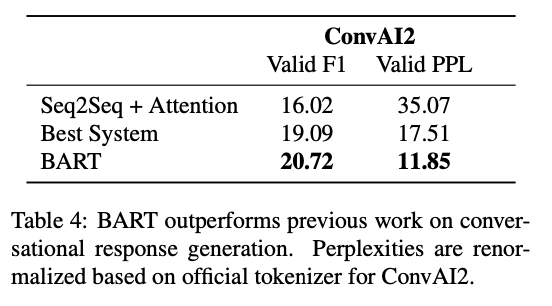
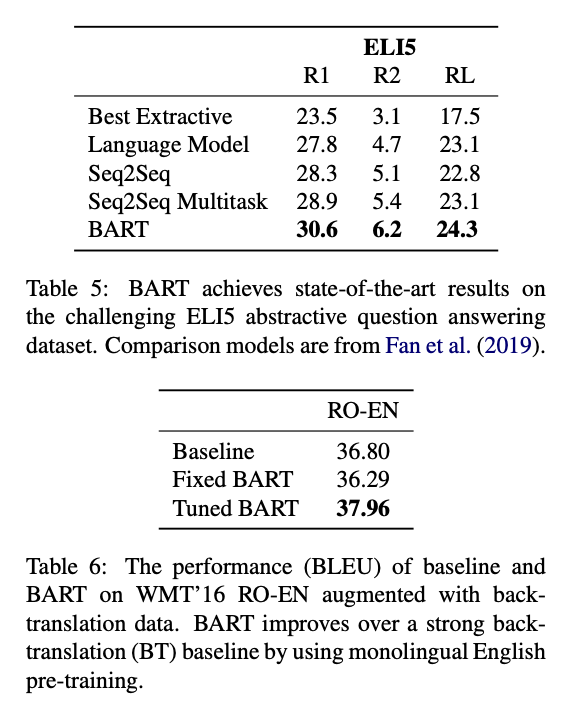
다양한 Task에서 SOTA 혹은 그에 준하는 성능을 보여주고 있다.
후기
오늘은 BART에 대해 읽어보았다. 보면 볼수록 신기한 것이 NLP 모델인 것 같다. 학습 데이터도 그냥 글만 있으면 되고, 그것으로 학습한 모델을 task에 맞게 fine-tuning 시키면 성능이 잘 나오는 것도 신기했고, 생각보다 다양한 task에 적용할 수 있는 것도 놀라웠다.
