오늘은 Improving Language Understanding by Generative Pre-Training (GPT 1.0)에 대한 간단한 리뷰이다.
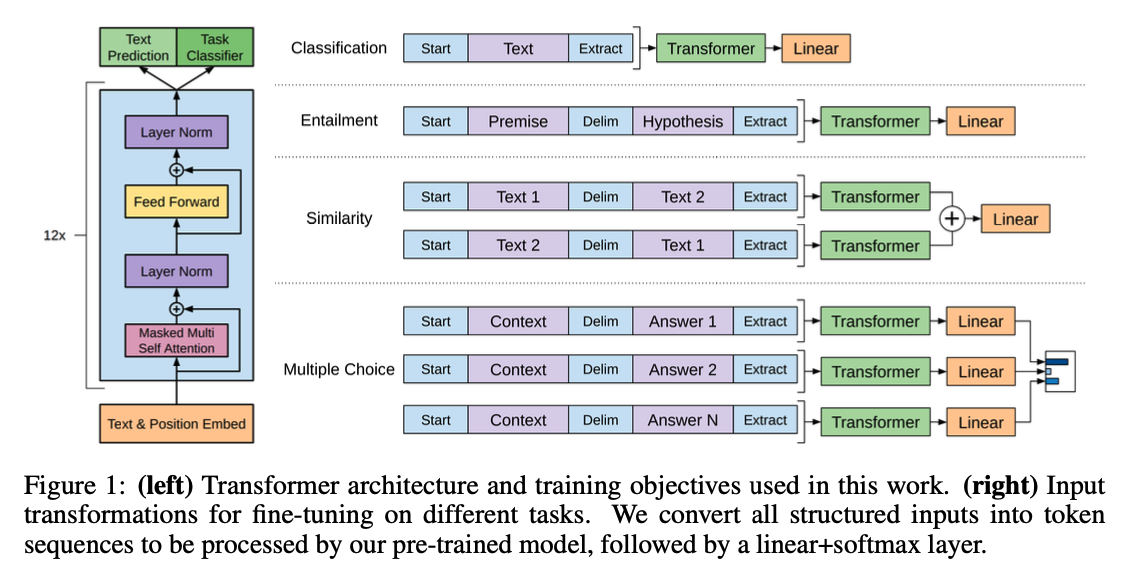
Framework
Unsupervised pre-training

token들이 주어졌을 때, 다음 토큰이 나올 확률을 최대화하는 방식으로 objective가 구성되어 있다. 구조로는 multi-layer Transformer decoder를 사용한다.
Supervised fine-tuning

pretrain을 하고 난 후 fine-tuning을 할 때는 주어진 데이터에 맞게 추가적인 output layer를 넣어서 학습시킨다. 또한 pretrain할 때 사용했던 loss를 가중치를 줘서 넣어주면 일반화 성능이 올라가고 수렴이 빠르게 되기 때문에 최종 loss에 반영하였다.
Task-specific input transformations
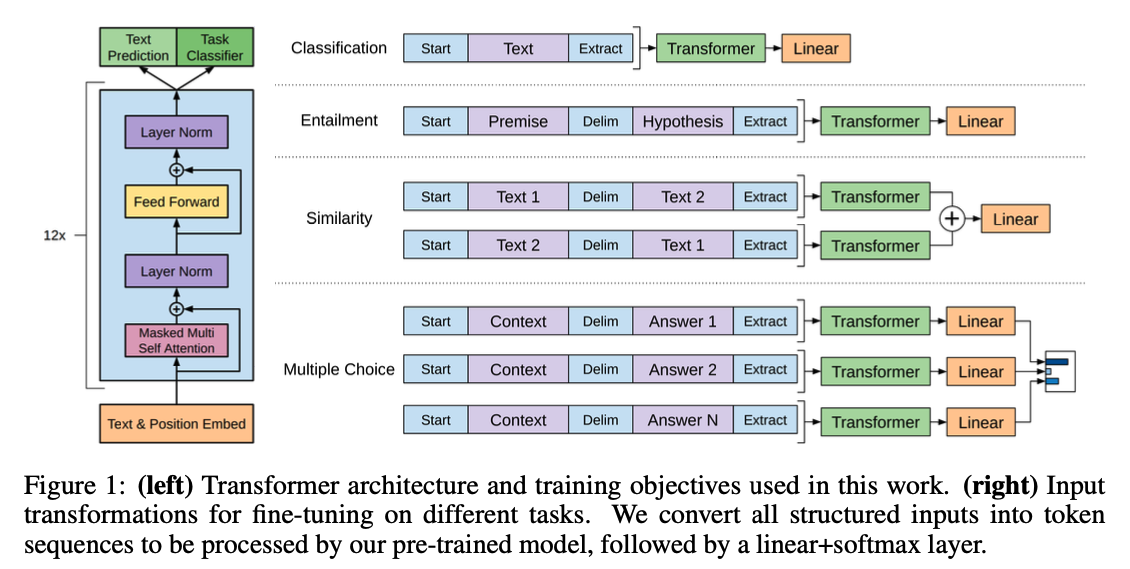
task에 따라 input과 output이 달라진다.
Experiments
Supervised fine-tuning
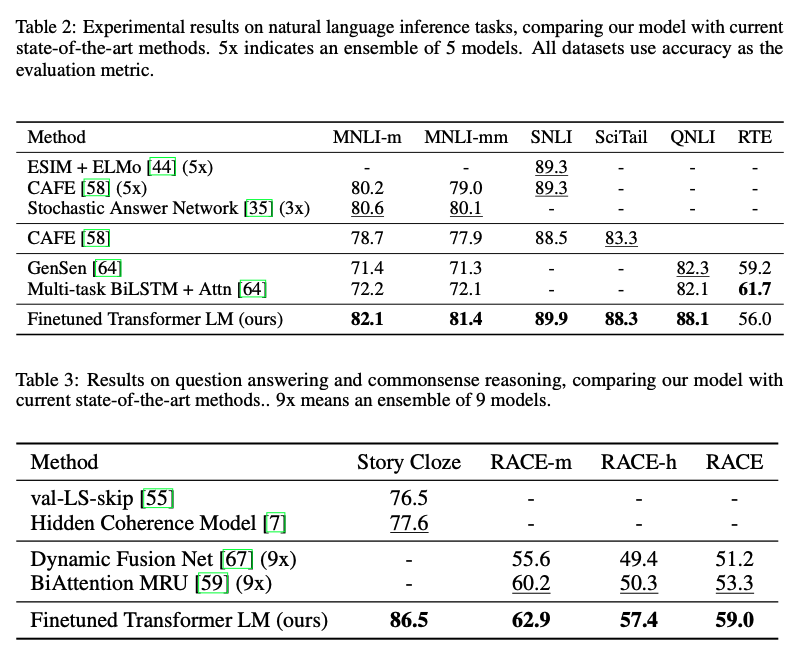
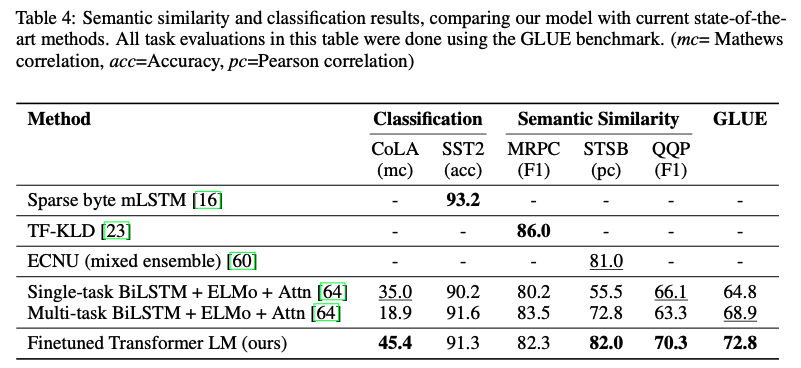
여러 task에서 괜찮은 성능을 보여준다.
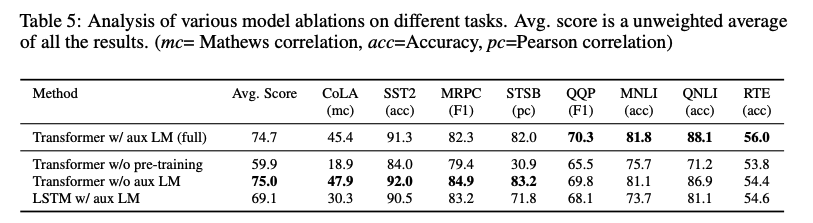
ablation study이다. 먼저, auxiliary objective를 사용하는 것이 NLI와 QQP task에 적합했고, 전반적으로 데이터가 크면 클수록 얻는 이득이 많았다. 두 번째로, 한 가지 데이터셋을 제외하고는 LSTM보다 Transformer가 성능이 더 좋았고, pre-training을 진행했을 때가 더 좋은 성능을 보여줬다.
후기
오늘은 ChatGPT의 조상, GPT 1.0에 대해 알아보았다. BERT와 BART를 먼저 읽어서 그런지 감흥이 그렇게 크진 않았지만, 그래도 재밌게 읽었던 것 같다.
오늘이 3월의 마지막 날인데, 아마 내일부터는 진행하는 프로젝트에 관련된 논문을 위주로 리뷰할 것 같고, 조만간 중간고사 기간이기도 해서 매일 올리진 않을 것이다. 중간고사가 끝난 4월 말부터 다시 지금까지 했던 것처럼 주요한 논문, 아마도 vision 관련 trasnformer와 GAN, Diffusion 등이 다뤄질 것 같은데 그렇게 진행될 것 같다.
