오늘은 Binge Watching: Scaling Affordance Learning from Sitcoms에 대한 간단하지 않은 리뷰이다.
Sitcom Affordance Dataset
Affordance learning task를 위한 데이터셋을 모으기 위해서 같은 이미지에 사람이 있는 것과 없는 것 둘 다 있어야 한다. 시트콤은 프로그램의 특성상 같은 장면이 여러 에피소드에서 자주 나오기 때문에, 여기서 아이디어를 얻는다.
저자는 7개의 시트콤에서 1억개 이상의 프레임을 전처리하여 데이터셋을 구성한다. 이때 세 가지 스텝을 거친다.
1. 얼굴과 사람을 찾는 detector를 결합한 empty scene classifier를 통해 1억개의 프레임에서 사람이 없거나 조금 있는 이미지를 찾는다.
2. 1에서 찾은 이미지와 같은 장면인데 사람이 행동을 취하고 있는 이미지를 찾는다.
3. manual하게 걸러내어서 데이터의 질을 높인다.
Extracting Empty Scenes
사람이 없는 이미지를 찾기 위해 세 개의 모델을 사용한다: face detection, human detection, scene classification. 이 중에서 face detection을 가장 주요한 지표로 삼는다.
이미지에서 가장 크게 나온 얼굴 크기를 기준으로 필터링하고, Fast-RCNN을 통해 human detection을 하여 또 걸러낸다. 마지막으로는 empty scene에 대한 CNN classifier를 다른 데이터셋을 통해 학습시키고, 이 모델로 sitcom dataset을 추론한 후 가장 점수게 높게 나온 1000개의 장면을 hard negative로 삼아 다시 fine-tuning한다. 이렇게 했을 때 일반화 성능이 증가하였다고 한다.
People Watching: Finding Scenes with People
이제 사람이 있는 장면을 찾는 단계이다.

첫 번째 방법은 global matching으로, 사람이 없는 장면을 쿼리로 삼고 나머지를 retrieval dataset으로 삼아서 consine distance를 계산하는 것이다. 이때 사용된 feature는 pre-trained된 AlexNet의 pool5 feature이다.
두 번째 방법은 local matching으로, 사람이 없는 장면의 5초 전부터 5초 후까지의 이미지에서 매 프레임마다 pose estimation을 수행한다. 그런 다음 optical flow를 통해 사람이 없는 이미지에 대한 현재 이미지의 카메라 움직임을 계산하고, 이 정보를 바탕으로 사람이 없는 장면에 pose estimation한 결과를 붙여넣는다.
Manual Annotations
앞의 과정으로 만들어진 데이터가 완벽하지는 않을 것이기 때문에, human annotator가 manual하게 pose joint를 수정한다. 그리고 이상하게 나온 포즈들은 아예 지워버려서 데이터의 질을 높였다.
VAEs for Estimating Affordances
주어진 장면과 위치에 대해서 가장 적합한 포즈를 생성하기 위해, 그냥 pose estimation처럼 CNN을 학습시켜서 heatmap을 뽑아내는 방식도 있겠지만, 학습 데이터의 input은 사람이 없기 때문에 힘들 수 있다.
따라서 두 개의 stage로 나눠 추론한다.
1. categorical prediction: 데이터셋의 모든 포즈를 30개의 클러스터로 클러스터링하고, 30개 중 어떤 포즈가 가장 좋을지 예측
2. 1에서 예측한 클러스터에서, 주어진 인풋에 맞게 포즈의 크기와 deformation을 예측
Pose Classification
먼저 포즈 카테고리를 만들기 위해서, 데이터에서 10K개의 포즈를 샘플링해서 procrustes analysis를 활용해 각 포즈의 거리를 계산한다. 그리고 k-medoid clustering을 통해 30개의 클러스터로 클러스터링을 진행한다.
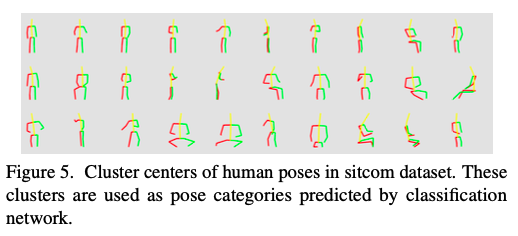
클러스터링 된 30개의 포즈는 위와 같다.
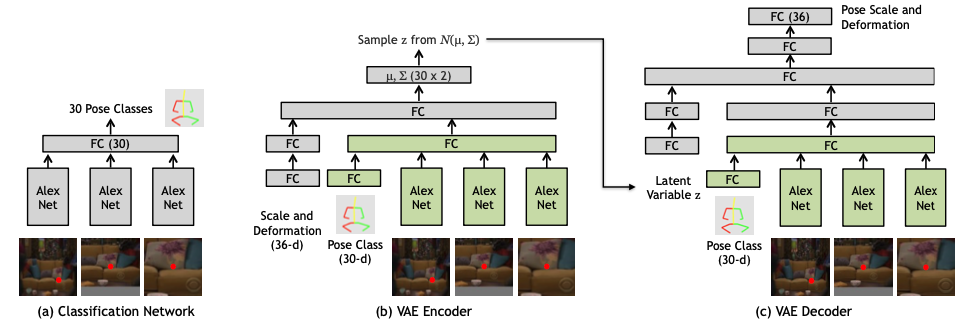
이후 classification Convnet을 구성한다. 인풋으로는 위치와 이미지를 받고, 가장 적합할 것 같은 pose class를 예측한다.
Technical Details
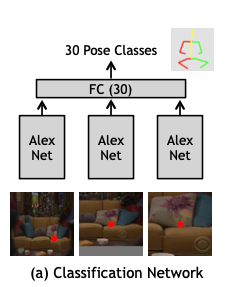
ConvNet의 input은 이미지와 위치이다. 이때 이미지는 정사각형의 패치로, 한 변의 길이는 이미지의 높이와 같다. 또한 한 변의 길이가 이미지 높이의 절반인 정사각형 패치도 잘라내고, 전체 이미지도 인풋으로 넣어준다. 위와 같이 총 3개의 이미지가 인풋으로 들어가는 것이다. 이 이미지들은 모두 227x227로 리사이즈된다.
3개의 이미지는 파라미터를 공유하는 AlexNet으로 들어가고, fc7을 거치고 나온 각각의 아웃풋은 concat되어 크기가 30인 fc layer에 들어가 확률값을 내뱉게 된다.
Scale and Deformation Estimation
베이스가 되는 포즈 클래스를 예측했으니, 이제 크기와 포즈의 변화를 예측해야 한다. 하지만 이것들이 딱 결정되는 것이 아니기 때문에 regression으로 풀기에는 애매한 부분이 있다. 그래서 conditional VAE를 사용하여 pose class와 인풋 이미지를 조건부로 하여 scale과 deformation을 생성한다.
Formulations for the conditional VAE

일반적인 Conditional VAE에서 볼 수 있는 식이다. x는 인풋 이미지와 포즈 클래스이고, y는 scale과 deformation이다.
Encoder
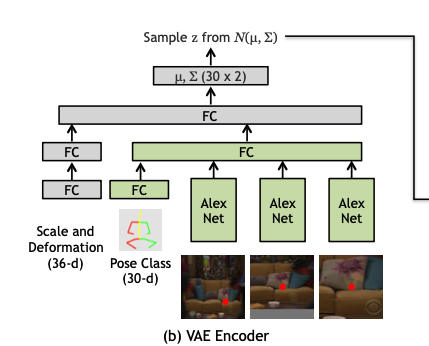
encoder의 인풋은 stage1에서 넣었던 세 개의 이미지와 pose class, 그리고 정답 scale과 deformation이다. 모델은 위의 사진같이 구성되고, AlexNet은 stage1에서 쓴 것이랑은 다른 것이다. fc layer의 크기는 모두 512이다. 모든 아웃풋은 concat되어 fc layer에 들어가고 크기가 30인 벡터 두 개, 각각 평균과 분산이 나오게 된다.
ground truth의 height scale은 포즈의 높이를 클러스터 포즈의 높이(0~1)로 나눠준다. ground truth의 width scale도 동일하다. 따라서 ground truth scale이 주어지면, 클러스터 포즈를 rescale하여 이미지에 배치할 수 있다.
deformation은 (dx, dy)형태로 나눠지고, scale된 클러스터 포즈와 ground truth 포즈의 거리로 구해질 수 있다. 포즈 joint가 17개기 때문에, x y 해서 34개 + scale 2개해서 총 36개의 벡터가 나중에 아웃풋으로 나오게 된다.
Decoder
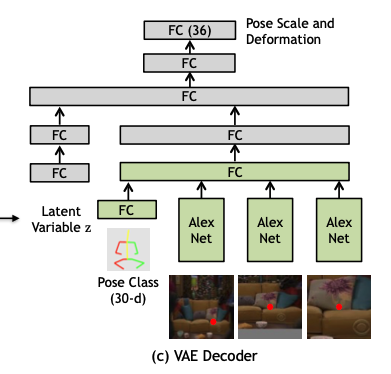
decoder는 encoder와 유사한 구조를 가지고 있다. encoder에서는 ground truth scale과 deformation을 input으로 받았지만, decoder를 latent vector를 받는다. 또한 image와 포즈 클래스에서 feature 추출하는 부분은 encoder와 동일한 것을 사용한다.
Training

VAE는 두 개의 Loss를 가진다. 첫 번째는 reconstruction loss로, gt와 output의 L2 Norm이고, 두 번째는 KLD이다. 일반적인 VAE의 학습 방식과 동일하다.
Inference
학습된 모델로는, 두 가지 task를 수행한다.
1. 주어진 이미지의 주어진 위치에 맞게 포즈 생성
2. 이 포즈가 이미지에 맞는지 안 맞는지 추정
첫 번째 task는 위에서 본 대로 모델 구조에 따라 인풋을 넣으면 아웃풋이 나오고, scale과 deformation을 적용하면 포즈가 생성된다.
두 번째 task는, 첫 번째 task처럼 똑같은 프로세스로 다른 latent vector를 사용하여 10번 진행한 후, 첫 번째 task에서 생성된 포즈와 거리를 재서 평균을 내 특정 threshold 이하면 그 포즈를 합리적인 포즈로 선택한다.
Experiments and Results
두 가지 task에서 평가를 진행한다.
1. 주어진 이미지와 위치에서 포즈가 잘 생성되었는가
2. 주어진 포즈가 가능한 포즈인가 아닌가
학습 이미지로는 Friends를 제외하고 약 25000개의 포즈와 약 10000장의 이미지, 테스트 데이터로는 Friends에서 뽑은 데이터(포즈 약 4000개, 이미지 약 1490개)와 임의로 생성한 negative sample(현실적으로 있을 수 있는 것, 일어나기 힘든 것) 9572 포즈를 사용하였다.
Generating poses in the scenes
Qualitative results

실제 추론 결과이다. ground truth와 달라도 나름 합리적인 포즈를 생성하는 것을 볼 수 있다.

또한 다른 latent vector를 사용했을 때 다른 포즈를 생성하는 모습을 확인할 수 있다.
Quantitative results
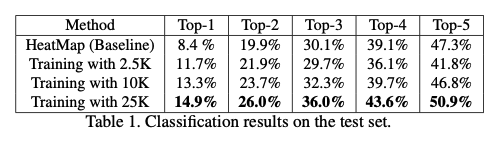
classification의 성능을 측정해보았다. 한 클래스만 정답이 아닐 수도 있기 때문에 Top-1부터 Top-5까지 측정했는데, baseline을 넘었고 데이터를 많이 넣을수록 좋은 성능을 보여줬다.
Human evaluation
설문조사도 진행했는데, 같은 이미지에 ground truth 포즈와 생성된 포즈를 각각 놓고 어느 것이 더 현실적인지 물어보는 것이었다. 결과는 46프로의 사람들이 생성된 포즈가 더 현실적이라고 답변했고, 랜덤 guess가 50프로인 것을 감안했을 때, 실제 ground truth와 생성된 포즈를 구별하기 힘들다고 볼 수 있다. 그만큼 자연스럽게 생성하는 것이다.
Classifying given poses in the scenes
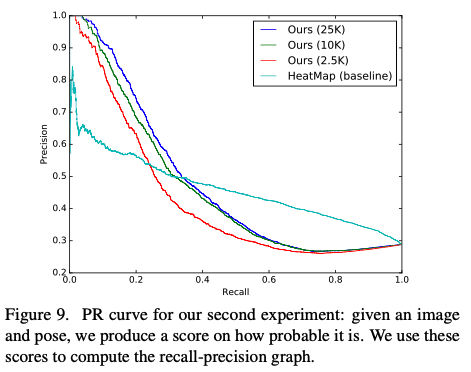
학습 중에는 negative sample이 없다는 것을 감안하고 봐야한다. 위의 그래프가 PR curve인데, 25k dataset으로 학습한 것이 가장 좋은 성능을 보여주고 있다. 또한 high-recall regimes에서는 baseline이 더 좋게 나오는데, 이는 heatmap 기반의 baseline은 euclidean loss로 train되서 평균적인 output을 잘 뽑아내기 때문이다.
Conclusion
큰 데이터셋 구성에 기여를 하였고, classification과 VAE로 이루어진 two stage approach를 제안하였다. 그리고 생성된 포즈 또한 꽤 현실적이었다.
후기
오늘은 내가 진행중인 프로젝트에 참고 논문으로 사용되는 논문을 읽고 리뷰하였다. 프로젝트 두 개를 진행하는데 어쩌다보니 pose affordance learning이라는 공통된 개념을 두 프로젝트가 가지고 있어서 겹치는 부분이 생겼다. 아무튼 저번에 한 번 자세히 읽어봤는데 글로 또 정리하니 못 봤던 부분도 보이고 더 자세히 알게 된 것 같다. 상당히 재밌는 주제이고, 데이터셋도 시트콤에서 만들 줄은 상상도 못했어서 그 점이 많이 인상깊었다. classification과 VAE로 이어지는 two-stage inference도 참신했고, 성능도 잘 나와서 새삼 대단하다고 느꼈다. 여담이지만 CVPR 2017에 accept되었으니 말 다했긴 했다.
다음 논문은 여기서 좀 더 발전하여 3D 공간의 pose affordance learning을 다룬 논문이다. 이 논문의 1저자가 참여한 논문이기도 하고, 그 논문 또한 CVPR 2019에 accept되었다. 기대가 된다.
