
1. 필요 라이브러리 import
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warningswarnings.simplefilter(action='ignore')- 가끔 출력 되는 에러 메세지 출력을 없애기 위한 코드입니다.
2. 데이터 확인
Data Dictionary
- PassengerId : 승객 ID
- HomePlanet : 출발 행성(거주지)
- CryoSleep : 취침 방식 여부
- Cabin : 객실 종류 및 번호 (port : 좌현, starboard : 우현)
- Destination : 목적지
- Age : 승객의 나이
- VIP : 승객의 VIP 서비스 유무
- RoomService, FoodCourt, ShoppingMall, Spa, VRDeck : 승객이 해당 서비스에 대해 지불한 금액
- Name : 이름
- Transported : 도착 여부
train_data = pd.read_csv("./train.csv")
print(train_data.shape)
train_data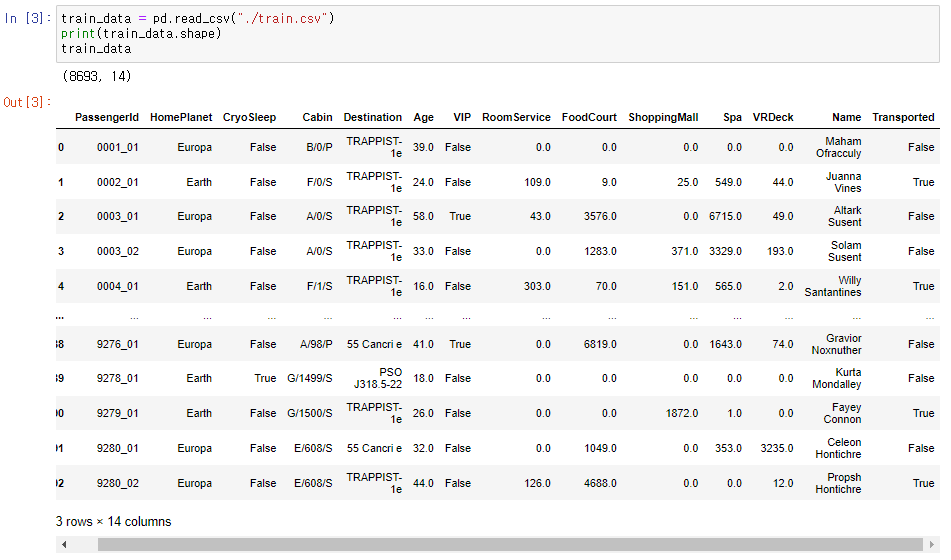
test_data = pd.read_csv("./test.csv")
print(test_data.shape)
test_data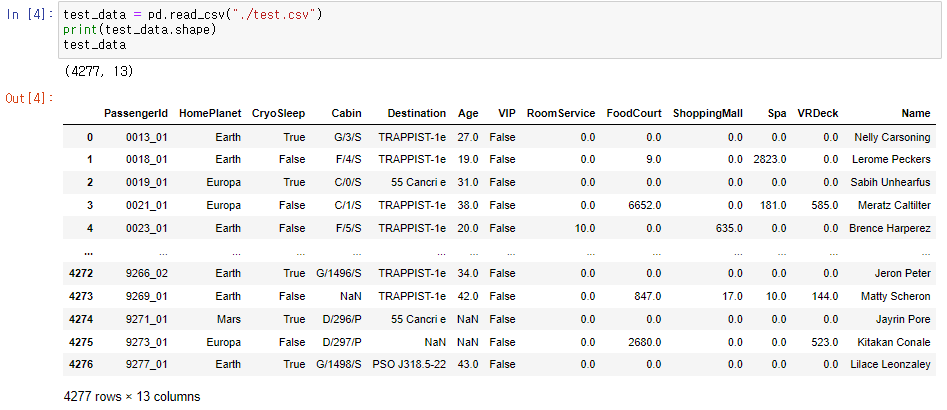
- train_data와 test_data를 불러와 내용 및 shape을 확인합니다.
→ train_data : (8693, 14) / test_data : (4277, 13)
train_data.info() #데이터 자료형 확인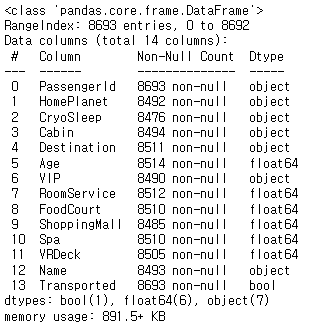
- train_data의 전반적인 정보를 확인합니다.
- Id, Transported를 제외하고는 Nan값 존재하는 것을 알 수 있고, 각 feature의 type을 볼 수 있습니다.
train_data.isna().sum() #데이터 결측치 확인
- train_data의 결측치 수를 확인합니다.
- 결측치가 전체적으로 train_data의 5%내외인 것을 확인할 수 있습니다.
train_data.describe() #수치형 데이터 확인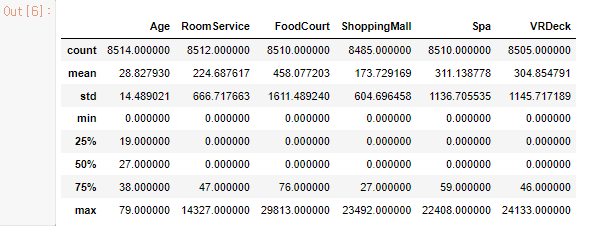
- train_data의 수치형 데이터를 확인합니다.
- 나이를 제외한 spaceship의 서비스에는 25%, 50%값이 0인 것을 볼 수 있습니다.
train_data.describe(include=['O']) #범주형 데이터 확인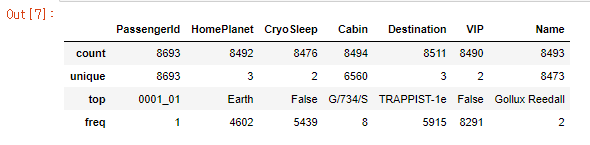
- train_data의 범주형 데이터를 확인합니다.
- 각 범주형 데이터 feature의 최빈값, 종류의 개수 확인할 수 있습니다.
train_data.hist(figsize=(10, 9))
plt.show()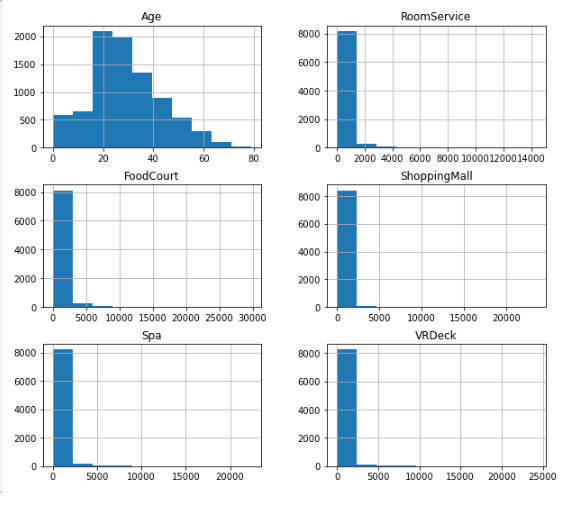
- train_data의 수치형 데이터를 히스토그램으로 표시합니다.
- 표와 히스토그램을 확인해보았을 때, 5가지의 서비스는 대부분 0으로 치우쳐져 있습니다.
- 서비스들의 max 값은 크지만 평균이 낮은 것과 25%, 50% 값이 0인것으로 보아 대부분의 승객들은 서비스를 이용하지 않지만, 서비스를 이용하는 소수의 사람들은 금액을 많이 사용한 것으로 유추해볼 수 있을 것 같습니다.
3. 데이터 전처리 및 분석
# 결측치 처리
train_data['CryoSleep'] = train_data['CryoSleep'].fillna(0)
train_data['VIP'] = train_data['VIP'].fillna(0)
train_data['Cabin'] = train_data['Cabin'].fillna(train_data['Cabin'].mode()[0])
train_data['HomePlanet'] = train_data['HomePlanet'].fillna(train_data['HomePlanet'].mode()[0])
train_data['Destination'] = train_data['Destination'].fillna(train_data['Destination'].mode()[0])
train_data['ShoppingMall'] = train_data['ShoppingMall'].fillna(train_data['ShoppingMall'].median())
train_data['VRDeck'] = train_data['VRDeck'].fillna(train_data['VRDeck'].median())
train_data['FoodCourt'] = train_data['FoodCourt'].fillna(train_data['FoodCourt'].median())
train_data['Spa'] = train_data['Spa'].fillna(train_data['Spa'].median())
train_data['RoomService'] = train_data['RoomService'].fillna(train_data['RoomService'].median())
train_data['Age'] = train_data['Age'].fillna(train_data['Age'].median())- 결측치의 비중이 5% 내외인 것을 위에서 확인할 수 있었습니다.
- CryoSleep, VIP, Cabin, HomePlanet, Destination과 같이 bool형 또는 object는 최빈값으로 전처리하였습니다.
- 이 외 수치형 데이터는 중앙값으로 전처리하였습니다.
- 평균값 말고 중앙값으로 전처리를 한 이유는 예외값에 영향을 거의 받지 않기 때문입니다.
# Cabin 분할
cab = train_data["Cabin"].apply(lambda x: x.split("/"))
train_data["Cab_1"] = cab.apply(lambda x: x[0])
train_data["Cab_3"] = cab.apply(lambda x: x[2])
train_data["Cab_2"] = cab.apply(lambda x: float(x[1]))- Cabin의 값을 객실의 종류, 호수, 방 위치로 분할합니다.
#필요 없는 column drop
train_data.drop(['PassengerId', 'Name', 'Cabin'], axis = 1, inplace = True)- Cabin은 위에서 분할하여 사용하기 때문에 drop을 하고, Id와 Name은 도착여부와 상관이 없을 것이라고 예상하기 때문에 train_data에서 drop하였습니다.
# bool형 int로 변경
train_data["VIP"] = train_data["VIP"].astype(int)
train_data["CryoSleep"] = train_data["CryoSleep"].astype(int)- bool형 feature는 int형으로 자료형 변경을 하였습니다.
train_data.isna().sum() #데이터 결측치 확인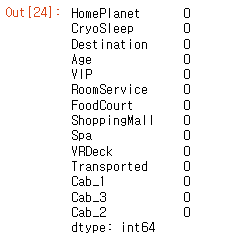
- 전처리를 진행한 후 결측치가 존재하는가 확인한 결과 결측치가 없는 것을 확인할 수 있습니다.
1. Vip
train_data[['VIP', 'Transported']].groupby(['VIP'], as_index=False).mean().sort_values(by='Transported')
arrived = train_data[train_data['Transported'] == 1]['VIP']. value_counts()
not_arrived = train_data[train_data['Transported'] == 0]['VIP']. value_counts()
df = pd. DataFrame([arrived, not_arrived])
df. index = ['arrived','not_arrived']
df. plot(kind= 'bar',stacked= True , figsize= (6,4))
plt.title('VIP')
plt. show()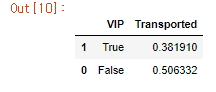
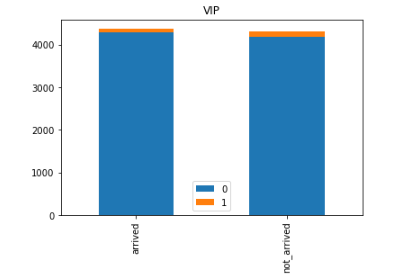
- vip를 신청한 사람 중 제대로 도착을 한 인원의 비중이 약 38퍼센트, 신청하지 않은 사람 중 도착한 인원의 비중이 약 50퍼센트인 것을 확인할 수 있습니다.
- 그래프로 나타내었을 때 약 1.3배의 차이가 있지만 신청을 하지 않은 사람의 비중이 압도적으로 크므로 크게 영향이 있다고 보기는 어렵습니다.
2. CryoSleep
train_data[['CryoSleep', 'Transported']].groupby(['CryoSleep'], as_index=False).mean().sort_values(by='Transported')
arrived = train_data[train_data['Transported'] == 1]['CryoSleep']. value_counts()
not_arrived = train_data[train_data['Transported'] == 0]['CryoSleep']. value_counts()
df = pd. DataFrame([arrived, not_arrived])
df. index = ['arrived','not_arrived']
df. plot(kind= 'bar',stacked= False, figsize= (6,4))
plt.title('CryoSleep')
plt. show()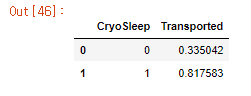
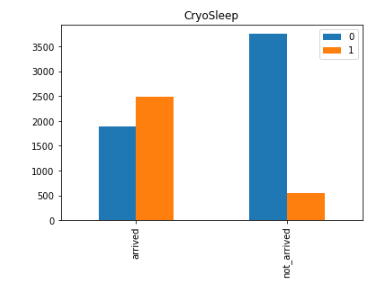
- Cryosleep을 신청한 사람 중 80퍼센트가 도착한 것으로 보아 어느정도 관계가 있다고 볼 수 있을 것 같습니다.
- 신청하지 않은 사람이 많지만 신청을 한 사람중 대부분이 도착한 것으로 확인됩니다.
3. HomePlanet
train_data[['HomePlanet', 'Transported']].groupby(['HomePlanet'], as_index=False).mean().sort_values(by='Transported')
arrived = train_data[train_data['Transported'] == 1]['HomePlanet']. value_counts()
not_arrived = train_data[train_data['Transported'] == 0]['HomePlanet']. value_counts()
df = pd. DataFrame([arrived, not_arrived])
df.index = ['arrived','not_arrived']
df.plot(kind= 'bar',stacked= False , figsize= (6,4))
plt.title('HomePlanet')
plt. show()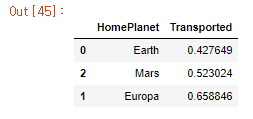
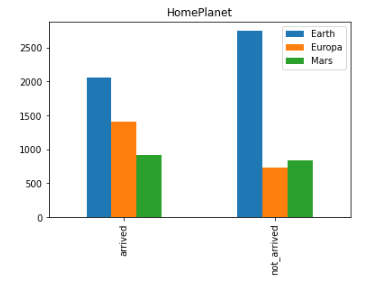
- 출발행성은 지구가 가장 많은 것으로 확인됩니다.
- 하지만, 화성과 유로파에서 출발한 인원은 절반 이상이 도착에 성공한 것으로 확인할 수 있습니다.
4. Destination
train_data[['Destination', 'Transported']].groupby(['Destination'], as_index=False).mean().sort_values(by='Transported')
arrived = train_data[train_data['Transported'] == 1]['Destination']. value_counts()
not_arrived = train_data[train_data['Transported'] == 0]['Destination']. value_counts()
df = pd. DataFrame([arrived, not_arrived])
df. index = ['arrived','not_arrived']
df. plot(kind= 'bar',stacked= False , figsize= (8,4))
plt.title('Destination')
plt. show()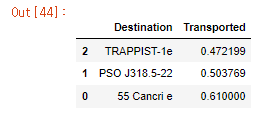
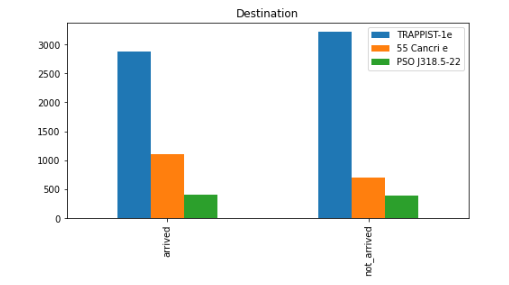
- 도착지는 대부분 약 50퍼센트에 가깝지만, 55 Cancri e가 도착지인 경우 다른 도착지보다 10퍼센트 더 높은 것을 확인할 수 있습니다.
5. Age
train_data.loc[(train_data['Age'] >= 0) & (train_data['Age'] < 10), 'Age'] = 0
train_data.loc[(train_data['Age'] >= 10) & (train_data['Age'] < 20), 'Age'] = 10
train_data.loc[(train_data['Age'] >= 20) & (train_data['Age'] < 30), 'Age'] = 20
train_data.loc[(train_data['Age'] >= 30) & (train_data['Age'] < 40), 'Age'] = 30
train_data.loc[(train_data['Age'] >= 40) & (train_data['Age'] < 50), 'Age'] = 40
train_data.loc[(train_data['Age'] >= 50) & (train_data['Age'] < 60), 'Age'] = 50
train_data.loc[(train_data['Age'] >= 60) & (train_data['Age'] < 70), 'Age'] = 60
train_data.loc[(train_data['Age'] >= 70) & (train_data['Age'] < 80), 'Age'] = 70
Arrived = train_data[train_data['Transported'] == 1]['Age']. value_counts()
Not_Arrived = train_data[train_data['Transported'] == 0]['Age']. value_counts()
df = pd. DataFrame([Arrived, Not_Arrived])
df. index = ['Arrived','Not_Arrived']
df. plot(kind= 'bar',stacked= False , figsize= (6,4)). legend(loc = 'lower center')
plt.title('Age')
plt. show()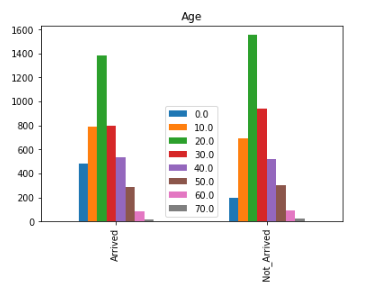
- 연령대는 0세부터 79세까지 분포하기 때문에 10대, 20대와 같이 범위를 나누었습니다.
- 0~19세까지는 도착률이 더 높고, 20~39세는 도착률이 더 낮으며 40세 이후로는 도착률이 거의 동일한 것을 확인할 수 있습니다.
6. Cabin
arrived = train_data[train_data['Transported'] == 1]['Cab_1']. value_counts()
not_arrived = train_data[train_data['Transported'] == 0]['Cab_1']. value_counts()
df = pd. DataFrame([arrived, not_arrived])
df. index = ['arrived','not_arrived']
df. plot(kind= 'bar',stacked= False , figsize= (8,4))
plt.title('Cab_1')
plt. show()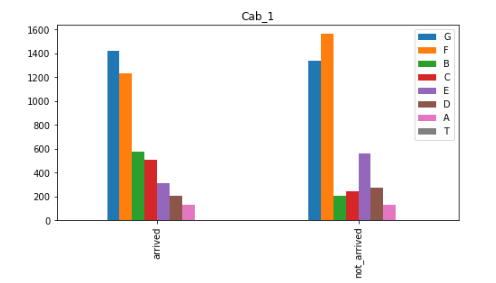
- 특별하게 B, C 호실이 도착률이 두배가 높은 것을 볼 수 있습니다.
- 반대로 E 호실은 도착률이 두배가 낮은 것도 확인할 수 있습니다.
arrived = train_data[train_data['Transported'] == 1]['Cab_3']. value_counts()
not_arrived = train_data[train_data['Transported'] == 0]['Cab_3']. value_counts()
df = pd. DataFrame([arrived, not_arrived])
df. index = ['arrived','not_arrived']
df. plot(kind= 'bar',stacked= False , figsize= (8,4))
plt.title('Cab_3')
plt. show()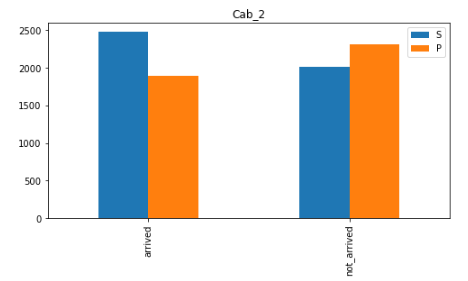
- spaceship의 우현에 앉은 사람이 도착률이 조금 더 높은 것을 알 수 있습니다.
Heatmap을 이용한 상관관계 및 선형성 확인
plt.figure(figsize = (16, 12))
x = sns.heatmap(train_data.corr(), cmap = 'Blues', linewidths = '0.1',annot = True)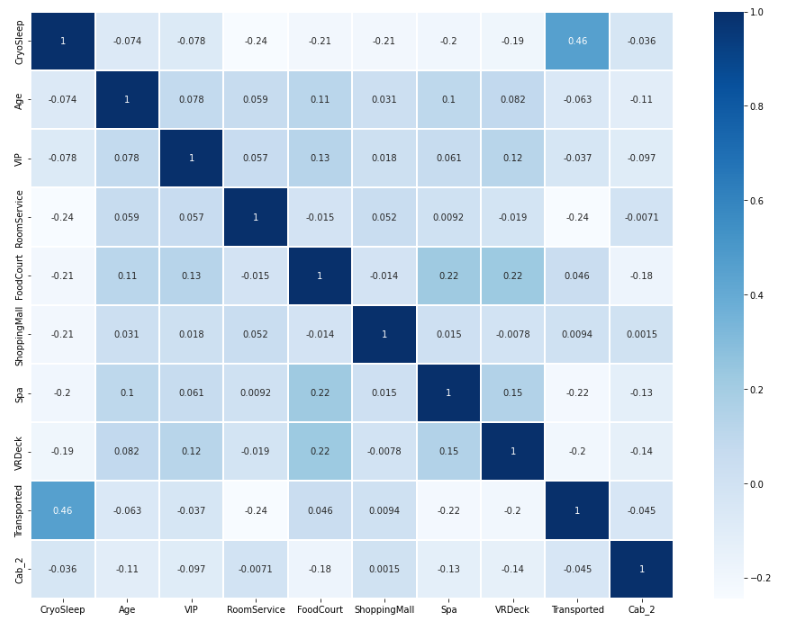
- 수치형 데이터의 상관관계를 heatmap을 이용하여 확인하였습니다.
- 위에서 예상해본 cryosleep과 도착여부가 그나마 상관관계가 있는 것 같지만, 이 또한 0.5 이하로 전체 데이터가 선형성이 없는 것을 확인할 수 있습니다.
One-Hot-Encoding
input_data = train_data.drop(['Transported'], axis = 1)
encoding_train_data = pd.get_dummies(input_data)
encoding_train_data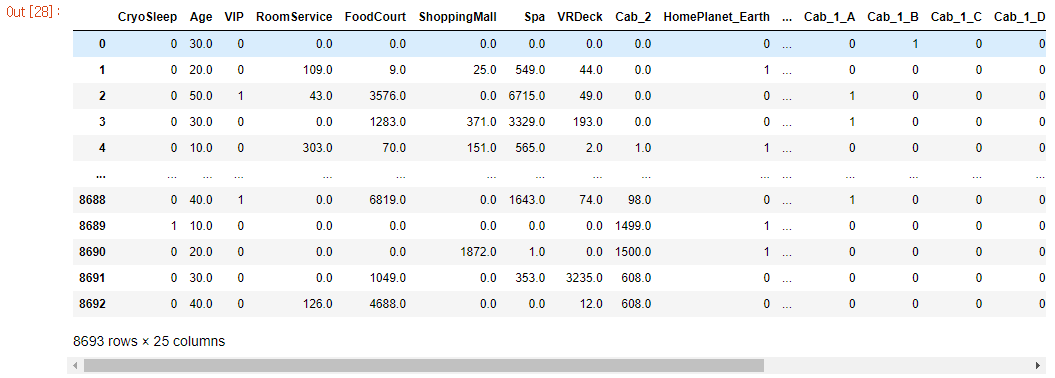
- one-hot-encoding을 이용하여 범주형 데이터를 수치형 데이터로 전환합니다.
encoding_train_data.columns
- one-hot-encoding을 한 뒤 data의 column을 확인해봅니다.
추가 데이터 확인
analysis = pd.merge(encoding_train_data, train_data['Transported'], left_index = True, right_index=True)
sns.pairplot(analysis[['CryoSleep', 'Age', 'VIP', 'RoomService', 'FoodCourt', 'ShoppingMall', 'Transported']],hue='Transported', palette='husl', markers=['o','s'])
plt.show()
sns.pairplot(analysis[['Spa', 'VRDeck', 'Destination_55 Cancri e', 'Destination_TRAPPIST-1e', 'Destination_PSO J318.5-22', 'Transported']],hue='Transported', palette='husl', markers=['o','s'])
plt.show()
sns.pairplot(analysis[['HomePlanet_Earth', 'HomePlanet_Europa', 'HomePlanet_Mars', 'Cab_2', 'Transported']],hue='Transported', palette='husl', markers=['o','s'])
plt.show()
sns.pairplot(analysis[['Cab_1_A','Cab_1_B', 'Cab_1_C', 'Cab_1_D', 'Cab_1_E', 'Transported']],hue='Transported', palette='husl', markers=['o','s'])
plt.show()
sns.pairplot(analysis[['Cab_1_F', 'Cab_1_G', 'Cab_1_T', 'Cab_3_P', 'Cab_3_S', 'Transported']],hue='Transported', palette='husl', markers=['o','s'])
plt.show()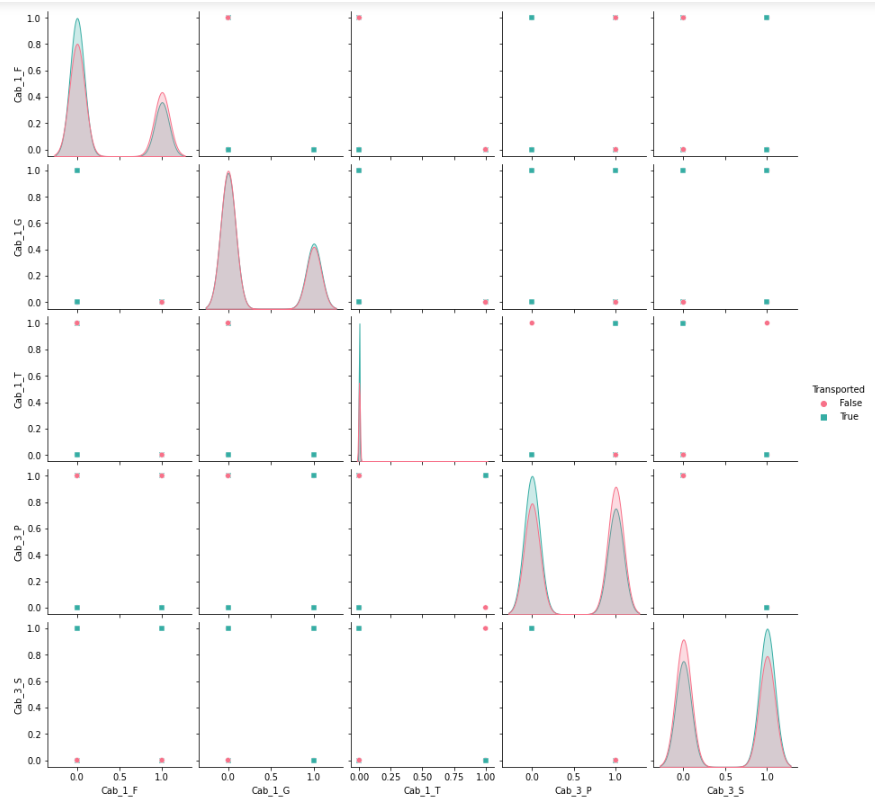
- 그래프를 통해 Transported와의 관계를 알아보았지만, 다른 feature들과의 관계를 한번 더 알아보았습니다.
- 각 feature과의 관계는 pairplot을 통해 알아보았습니다.
- 거의 동일한 형태의 feature들은 drop을 한 뒤 model을 적용할 예정입니다.
4. Model 적용
1. pca를 이용한 RandomForestClassifier
y_target = train_data['Transported']
x_data = encoding_train_data.drop(['Cab_1_A', 'Cab_1_G', 'Cab_1_T', 'Cab_1_D', 'Cab_1_C', 'VIP', 'HomePlanet_Mars', 'Destination_PSO J318.5-22'], axis = 1)
pca = PCA(n_components = 10)
pca.fit(encoding_train_data)
pca_train_data = pca.transform(encoding_train_data)
pca_train_data
pca_cols = []
for i in range(0, 10) :
x = 'pca_col' + str(i)
pca_cols.append(x)
pca_cols
pca_df = pd.DataFrame(pca_train_data, columns = pca_cols)
pca_df
- 이전 단계에서 유사한 feature를 drop을 하였지만, 대다수 유사한 형태의 feature가 있었기 때문에 pca를 통해 feature를 줄이고 overfitting을 방지하기 위해 pca를 이용해보았습니다.
- feature를 5개~15개로 확인해본 결과 10개가 적당하다는 결론이 나와서 10개로 pca를 진행하였습니다.
x_train, x_test, y_train, y_test = train_test_split(pca_df, y_target, test_size = 0.2, random_state = 0)- train_test_split을 이용하여 train_data와 test_data를 분할하였습니다.
params = { 'n_estimators' : [50, 100, 200, 300, 400],
'max_depth' : [4, 6, 8, 10, 12, 16],
'min_samples_leaf' : [4, 8, 12, 16, 20], #과적합 제어
'min_samples_split' : [4, 8, 12, 16, 20] #과적합 제어
}
grid_re_clf = RandomForestClassifier(random_state = 5, n_jobs = -1)
grid_cv = GridSearchCV(grid_re_clf, param_grid = params, cv = 5, n_jobs = -1)
grid_cv.fit(x_train, y_train)
print('최적 하이퍼 파라미터: ', grid_cv.best_params_)
print('최고 예측 정확도: {:.4f}'.format(grid_cv.best_score_))
- RandomForestClassifier 모델의 하이퍼 파라미터 튜닝을 GridSearchCV를 이용하여 진행하였습니다.
- n_estimators = 모델에서 사용할 트리 개수
- max_depth = 트리의 최대 깊이
- min_samples_split : 내부 노드를 분할하는데 필요한 최소 샘플 수
- min_samples_leaf : 리프 노드에 있어야 할 최소 샘플 수
# 모델 학습
pca_model = RandomForestClassifier(n_estimators=100, random_state=5,
max_depth=10, min_samples_leaf = 4, min_samples_split = 16, oob_score=True)
pca_model.fit(x_train, y_train)
pred = pca_model.predict(x_test)
# 평가
print("훈련 세트 정확도: {:.3f}".format(pca_model.score(x_train, y_train)) )
print("테스트 세트 정확도: {:.3f}".format(pca_model.score(x_test, y_test)) )
print("OOB 샘플의 정확도: {:.3f}".format(pca_model.oob_score_) )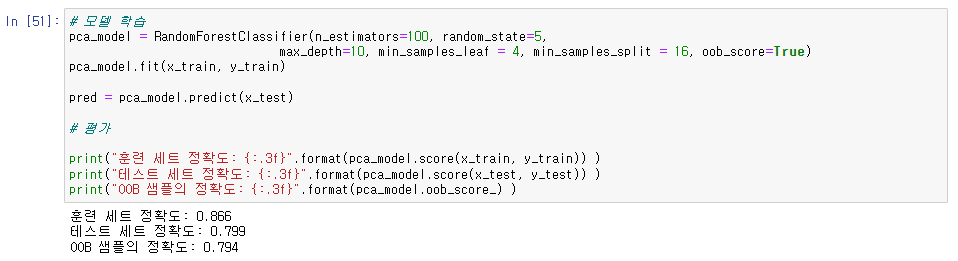
- 하이퍼 파라미터 튜닝을 통해 나온 best parameter를 가지고 RandomForestClassifier 모델을 사용하였습니다.
- oob_score : out-of-bag의 약자로, bootstrap sampling을 할 때 선택되지 않은 샘플을 의미한다. True로 설정하면 훈련 종료 후 oob샘플을 기반으로 평가를 한번 더 수행한다.
2. RandomForestClassifier
y_target = train_data['Transported']
x_data = encoding_train_data.drop(['Cab_1_A', 'Cab_1_G', 'Cab_1_T', 'Cab_1_D', 'Cab_1_C', 'VIP', 'HomePlanet_Mars', 'Destination_PSO J318.5-22'], axis = 1)
x_train, x_test, y_train, y_test = train_test_split(x_data, y_target, test_size = 0.15, random_state = 0)
params = { 'n_estimators' : [50, 100, 200, 300, 400],
'max_depth' : [4, 6, 8, 10, 12, 16],
'min_samples_leaf' : [4, 8, 12, 16, 20], #과적합 제어
'min_samples_split' : [4, 8, 12, 16, 20] #과적합 제어
}
grid_re_clf = RandomForestClassifier(random_state = 5, n_jobs = -1)
grid_cv = GridSearchCV(grid_re_clf, param_grid = params, cv = 5, n_jobs = -1)
grid_cv.fit(x_train, y_train)
print('최적 하이퍼 파라미터: ', grid_cv.best_params_)
print('최고 예측 정확도: {:.4f}'.format(grid_cv.best_score_))
- 이전과 동일하게 필요없는 columns를 drop한 뒤 train_test_split으로 train_data와 test_data를 분할합니다.
- 이 후 동일하게 GridSearchCV를 이용한 하이퍼 파라미터 튜닝을 진행합니다.
# 모델 학습
model = RandomForestClassifier(n_estimators = 200, random_state=5, max_depth = 16, min_samples_leaf = 8, min_samples_split = 4, oob_score=True)
model.fit(x_train, y_train)
pred = model.predict(x_test)
# 평가
print("훈련 세트 정확도: {:.3f}".format(model.score(x_train, y_train)) )
print("테스트 세트 정확도: {:.3f}".format(model.score(x_test, y_test)) )
print("OOB 샘플의 정확도: {:.3f}".format(model.oob_score_) )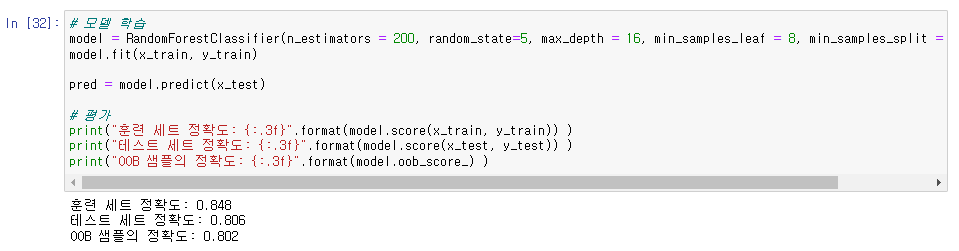
- 하이퍼 파라미터 튜닝을 진행하며 도출한 best parameter로 모델 학습을 진행하였습니다.
# feature importance
ftr_importances_values = model.feature_importances_
ftr_importances = pd.Series(ftr_importances_values, index = x_train.columns)
ftr_sort = ftr_importances.sort_values(ascending=False)
plt.figure(figsize=(12,10))
plt.title('Feature Importances')
sns.barplot(x=ftr_sort, y=ftr_sort.index)
plt.show()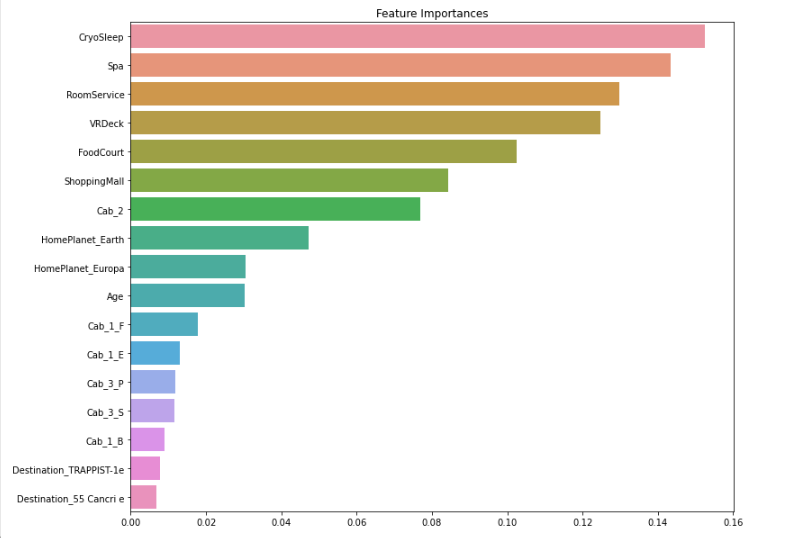
- 모델을 적용해본 뒤 feature importances를 확인해보았습니다.
- 앞서 데이터 분석 때 생각했던 cryosleep이 중요도가 가장 높게 나온 것도 확인할 수 있었습니다.
5. Test data 적용
1. test_data 전처리
test_data.isna().sum() #데이터 결측치 확인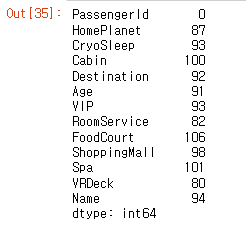
- test data의 결측치를 확인합니다.
# 결측치 처리
test_data['CryoSleep'] = test_data['CryoSleep'].fillna(0)
test_data['VIP'] = test_data['VIP'].fillna(0)
test_data['Cabin'] = test_data['Cabin'].fillna(test_data['Cabin'].mode()[0])
test_data['HomePlanet'] = test_data['HomePlanet'].fillna(test_data['HomePlanet'].mode()[0])
test_data['Destination'] = test_data['Destination'].fillna(test_data['Destination'].mode()[0])
test_data['ShoppingMall'] = test_data['ShoppingMall'].fillna(test_data['ShoppingMall'].median())
test_data['VRDeck'] = test_data['VRDeck'].fillna(test_data['VRDeck'].median())
test_data['FoodCourt'] = test_data['FoodCourt'].fillna(test_data['FoodCourt'].median())
test_data['Spa'] = test_data['Spa'].fillna(test_data['Spa'].median())
test_data['RoomService'] = test_data['RoomService'].fillna(test_data['RoomService'].median())
test_data['Age'] = test_data['Age'].fillna(test_data['Age'].median())# Cabin 분할
cab = test_data["Cabin"].apply(lambda x: x.split("/"))
test_data["Cab_1"] = cab.apply(lambda x: x[0])
test_data["Cab_3"] = cab.apply(lambda x: x[2])
test_data["Cab_2"] = cab.apply(lambda x: float(x[1]))#필요 없는 column drop
test_data.drop(['PassengerId', 'Name', 'Cabin'], axis = 1, inplace = True)# bool형 int로 변경
test_data["VIP"] = test_data["VIP"].astype(int)
test_data["CryoSleep"] = test_data["CryoSleep"].astype(int)encoding_test_data = pd.get_dummies(test_data)
test_x_data = encoding_test_data.drop(['Cab_1_A', 'Cab_1_G', 'Cab_1_T', 'Cab_1_D', 'Cab_1_C', 'VIP', 'HomePlanet_Mars', 'Destination_PSO J318.5-22'], axis = 1)- train_data에서 했던 데이터 전처리를 동일하게 test_data에도 적용합니다.
- 결측치 채우기, cabin 분할, 자료형 변경, one-hot-encoding까지 진행해줍니다.
2. PCA를 이용한 모델 적용
pca = PCA(n_components = 10)
pca.fit(encoding_test_data)
pca_test_data = pca.transform(encoding_test_data)
pca_cols = []
for i in range(0, 10) :
x = 'pca_col' + str(i)
pca_cols.append(x)
pca_df = pd.DataFrame(pca_test_data, columns = pca_cols)
pca_rf_pred = pca_model.predict(pca_df)
sample_submission = pd.read_csv('./sample_submission.csv')
sample_submission['Transported'] = pca_rf_pred
sample_submission.to_csv('submission.csv',index = False)
sample_submission.head()- PCA를 진행한 뒤 RandomForestClassifier model을 적용하고 submission.csv 파일에 저장합니다.
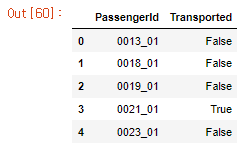

- PCA를 함께 이용했을 때 제출 결과입니다.
3. RandomForestClassifier 모델
rf_predict = model.predict(test_x_data)
sample_submission = pd.read_csv('./sample_submission.csv')
sample_submission['Transported'] = rf_predict
sample_submission.to_csv('CKH_submission_2.csv',index = False)
sample_submission.head()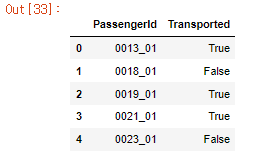
- PCA를 사용하지 않고 RandomForestClassifier 모델만 적용한 뒤 submission.csv 파일에 저장하였습니다.


- 제출한 결과 PCA를 이용하였을 때보다 1.5배 가량 점수가 향상이 된 것을 확인하였습니다.

안녕하세요 :) Data/AI 공부 중인 한국외대 컴퓨터공학부 조권휘입니다.