1. 필요 라이브러리 import
import datetime
import warnings
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
import xgboost as xgb
from math import sqrt
from xgboost import XGBClassifier
from sklearn.metrics import mean_squared_error
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.linear_model import Ridge, Lasso
from sklearn.preprocessing import PolynomialFeatures
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import accuracy_score
- 사용될 라이브러리를 가져옵니다.
warnings.simplefilter(action='ignore')- 가끔 출력 되는 에러 메세지 출력을 없애기 위한 코드입니다.
2. 데이터 확인 및 전처리
train_data = pd.read_csv("./dataset/train.csv")
print(train_data.shape)
train_data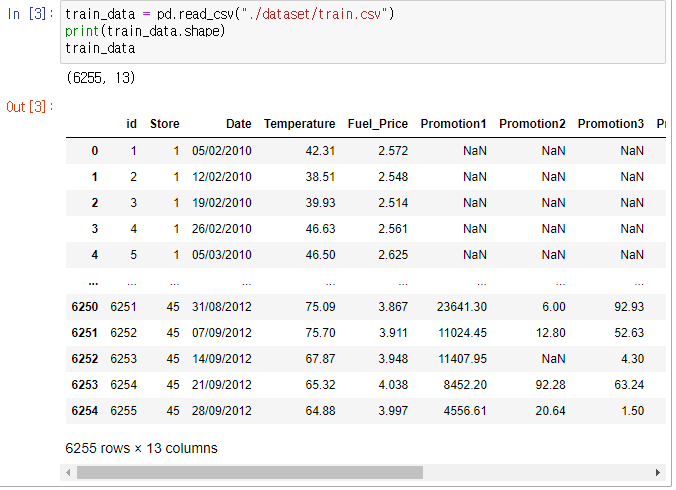
test_data = pd.read_csv("./dataset/test.csv")
print(test_data.shape)
test_data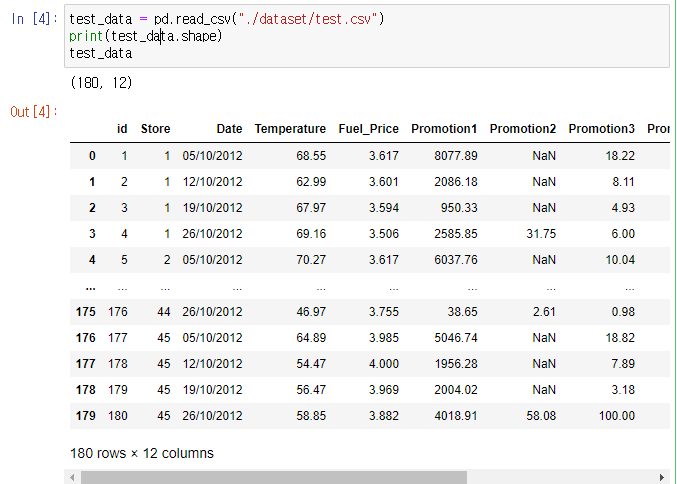
- train_data, test_data를 불러와 확인을 합니다.
train_data.isna().sum()train_data["IsHoliday"] = train_data["IsHoliday"].astype(int)
train_data = train_data.fillna(0)
train_data.isna().sum()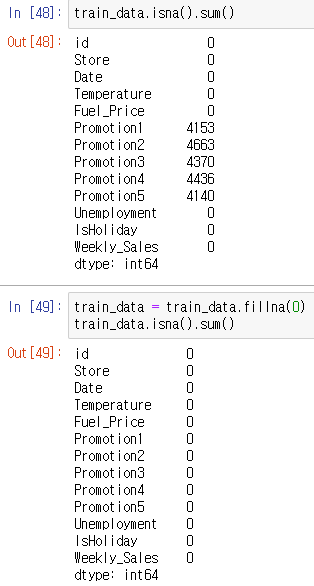
- train_data의 IsHoliday 데이터가 범주형 데이터이고, 결측치가 있는 것을 확인한 뒤 범주형 데이터는 int형으로, 결측치는 0으로 바꿔줍니다.
train_data.hist(figsize=(10, 9))
plt.show()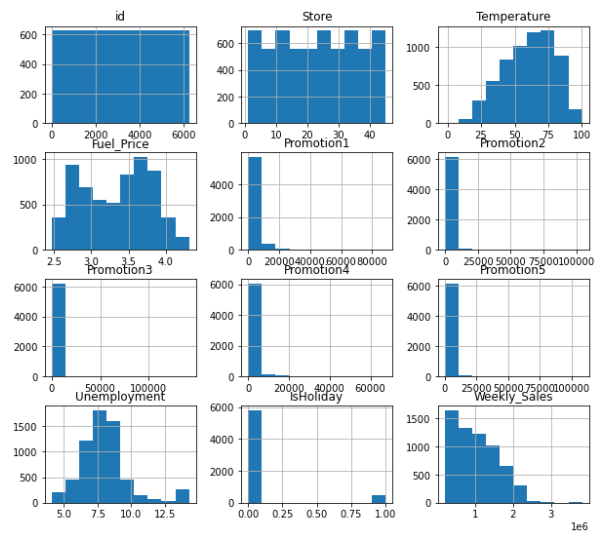
- train_data의 데이터들을 히스토그램으로 나타냅니다.
- data를 확인해보았을 때, 각 data별로 단위의 범위가 많이 다른 것을 확인할 수 있습니다.
train_data = train_data.drop(['id', 'Date'], axis=1)
train_data
- 샘플의 id와 Date는 필요 없으니 데이터에서 제외를 합니다.
scaler = preprocessing.MinMaxScaler()
normalized_data = scaler.fit_transform(train_data)
col = ['Store', 'Temperature','Fuel_Price','Promotion1','Promotion2','Promotion3','Promotion4','Promotion5','Unemployment','IsHoliday','Weekly_Sales']
normalized_df = pd.DataFrame(normalized_data, columns = col)
normalized_df
- 히스토그램으로 단위의 범위가 많이 다른 것을 확인하였으니 각 데이터의 단위의 차이를 MinMaxScaler로 줄여주었습니다.
- 또한 model의 알고리즘 속도를 빠르게 해주기 위해 MinMaxScaler()를 이용하여 Feature Scaling을 진행합니다.
plt.figure(figsize = (16, 12))
x = sns.heatmap(train_data.corr(), annot = True)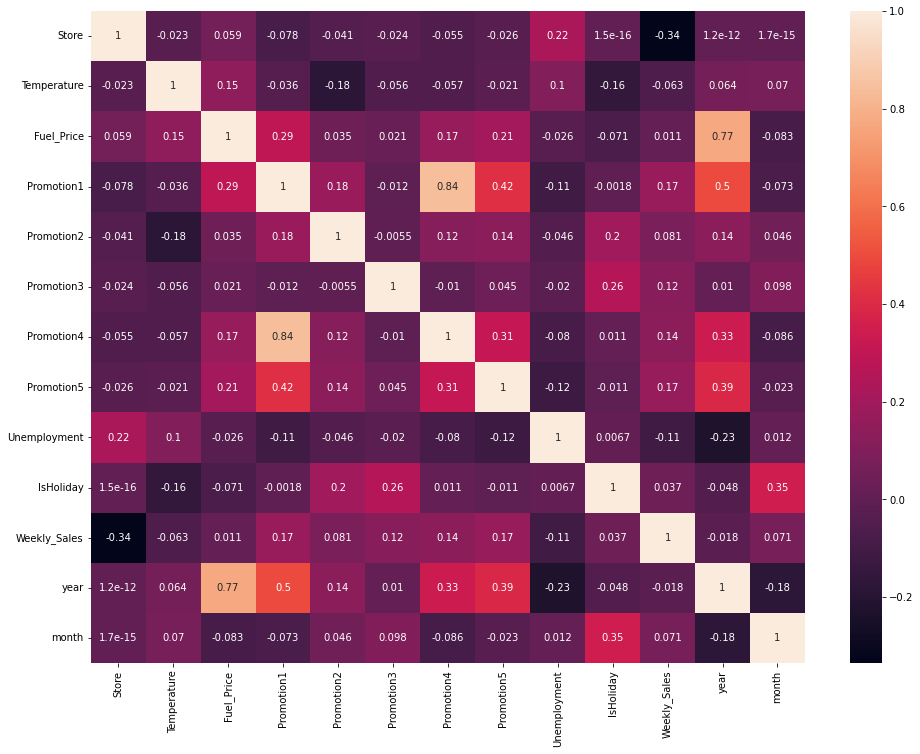
- Heatmap을 이용하여 각 data들의 correlation을 확인하였습니다.
- 대부분의 모델들이 상관관계가 없는 것을 확인할 수 있으므로, 선형 회귀 모델의 효력은 낮을 것으로 생각됩니다.
#변수 중요도 확인
xgb.plot_importance(xgb3_model, importance_type = 'weight', title = 'weight', xlabel='', grid = 'False') #모델 예측에 영향을 미친 횟수
xgb.plot_importance(xgb3_model, importance_type = 'total_gain', title = 'total_gain', xlabel='', grid = 'False') # 관련된 샘플의 상대적인 개수
xgb.plot_importance(xgb3_model, importance_type = 'total_cover', title = 'total_cover', xlabel='', grid = 'False') #노드 분기에 사용된 횟수
plt.tight_layout()
plt.show()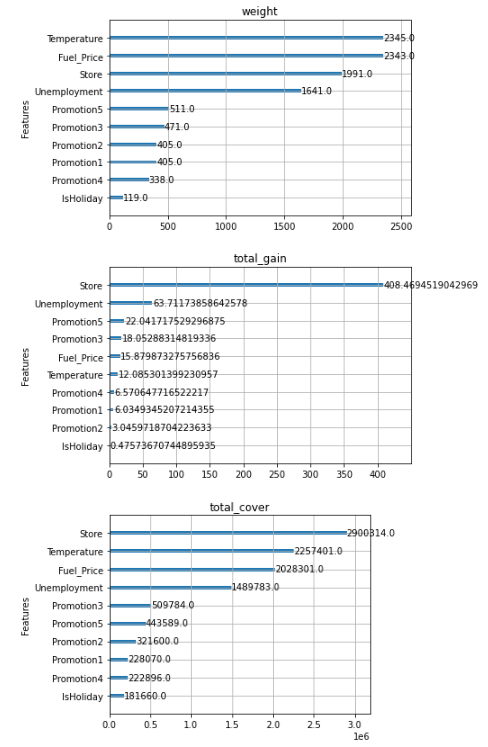
- xgboost모델을 사용할 때, 공통적으로 ‘IsHoliday’ 속성이 중요도가 제일 낮은 것을 확인하였습니다.
3. 데이터의 모델 적용
# test_size를 정할 때 사용한 코드
for k in range(0.1, 0.35, 0.05) :
x_train, x_test, y_train, y_test = train_test_split(x_data, y_target, test_size = k, random_state = 0)
# 실제 사용 코드
x_train, x_test, y_train, y_test = train_test_split(x_data, y_target, test_size = 0.15, random_state = 0)- train_data를 train_set과 test_set으로 0.85 : 0.15 비율로 split하였습니다.
- 앞서 선형회귀 모델은 적합하지 않은 것을 확인했지만, 코드잇 강의에서 배운 내용을 연습한다는 생각으로 추가로 적용을 해보았습니다.
1. 선형회귀 모델
linear_model = LinearRegression()
lin_model = linear_model.fit(x_train, y_train)
y_test_predict = lin_model.predict(x_test)
linear_mse = mean_squared_error(y_test, y_test_predict)
linear_mse = linear_mse ** 0.5
linear_mse
lin_score = lin_model.score(x_test, y_test)
y_test_predict, lin_score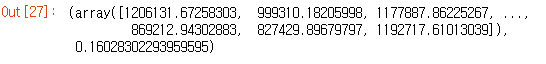
- LinearRegressor 모델을 적용한 뒤 score를 확인
2. 결정트리 모델
dec = DecisionTreeRegressor()
dec_tree_param= {
'max_depth' : [1,2,3,4,5,6,7,8,9,10]
}
reg = GridSearchCV(dec, dec_tree_param, cv = 5)
reg.fit(x_train, y_train)
reg.best_params_
decision_tree_model = DecisionTreeRegressor(max_depth = 10, random_state = 0)
decision_tree_model.fit(x_train, y_train)
dec_tree_pred = decision_tree_model.predict(x_test)
dec_score = decision_tree_model.score(x_test, y_test)
dec_tree_pred, dec_score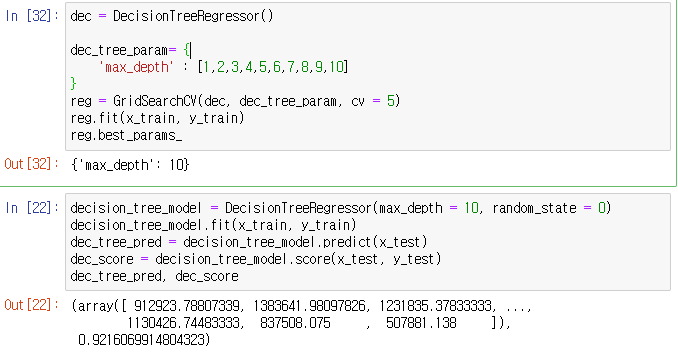
- GridSearch를 이용하여 max_depth를 확인하고, 결정트리를 적용한 뒤 score를 확인
3. Lasso, Ridge 모델
l1_model = Lasso(alpha=1, max_iter=2000, normalize=True)
l1_model.fit(x_train, y_train)
y_train_predict = l1_model.predict(x_train)
y_test_predict = l1_model.predict(x_test)
mse = mean_squared_error(y_train, y_train_predict)
print("training set에서 성능")
print("-----------------------")
print(f'오차: {sqrt(mse)}')
lasso_mse = mean_squared_error(y_test, y_test_predict)
print("testing set에서 성능")
print("-----------------------")
print(f'오차: {sqrt(lasso_mse)}')
l1_score = l1_model.score(x_test, y_test)
l1_score
l2_model = Ridge(alpha=1, max_iter=2000, normalize=True)
l2_model.fit(x_train, y_train)
y_train_predict = l2_model.predict(x_train)
y_test_predict = l2_model.predict(x_test)
mse = mean_squared_error(y_train, y_train_predict)
print("training set에서 성능")
print("-----------------------")
print(f'오차: {sqrt(mse)}')
ridge_mse = mean_squared_error(y_test, y_test_predict)
print("testing set에서 성능")
print("-----------------------")
print(f'오차: {sqrt(ridge_mse)}')
l2_score = l2_model.score(x_test, y_test)
l2_score
- Lasso, Ridge 모델을 이용하여 score를 확인해보았습니다.
4. 랜덤포레스트 모델
forest_model = RandomForestRegressor(random_state = 0, n_jobs = -1)
params = {
'n_estimators' : [10, 50, 100],
'max_depth' : [6, 8, 10, 12],
'min_samples_leaf' : [8, 12, 18],
'min_samples_split' : [8, 16, 20]
}
grid_cv = GridSearchCV(forest_model, param_grid = params, cv = 3, n_jobs = -1)
grid_cv.fit(x_train, y_train)
print('최적 하이퍼 파라미터: ', grid_cv.best_params_)
print('최고 예측 정확도: {:.4f}'.format(grid_cv.best_score_))
forest_test_model = RandomForestRegressor(random_state = 0, n_estimators = 100, max_depth = 12, min_samples_leaf = 8, min_samples_split = 8)
forest_test_model.fit(x_train, y_train)
forest_predictions = forest_test_model.predict(x_test)
forest_score = forest_test_model.score(x_test, y_test)
forest_predictions, forest_score
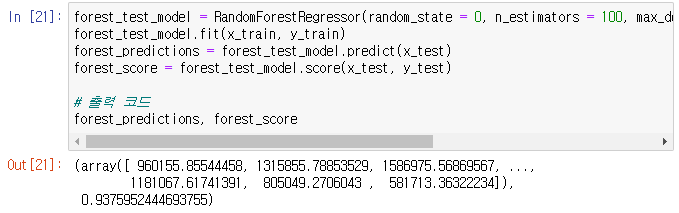
- GridSearch를 이용하여 하이퍼파라미터 튜닝을 진행한 뒤 해당 하이퍼파라미터를 이용하여 랜덤포레스트 모델에 적용한 뒤 score 확인을 하였습니다.
5. XGBoost 모델
Xgb = xgb.XGBRegressor() #0.15
xgb_param={
'n_estimators' : [300,400,500],
'min_child_weight' : [5, 6, 7, 8],
'colsample_bytree' : [0.6, 0.7, 0.8, 0.9],
'subsample' : [0.6, 0.7, 0.8],
'learning_rate' : [0.1, 0.2, 0.3],
'max_depth' : [4, 5, 6, 7]
}
xgb_grid = GridSearchCV(Xgb, param_grid = xgb_param)
xgb_grid.fit(x_train, y_train)
xgb_grid.best_params_
xgb_model = xgb.XGBRegressor(n_estimators = 500, learning_rate=0.1, min_child_weight = 8, max_depth = 7, subsample = 0.8, colsample_bytree = 0.9)
xgb_model.fit(x_train,y_train)
prediction = xgb_model.predict(x_test)
xgb_score = xgb_model.score(x_test, y_test)
prediction, xgb_score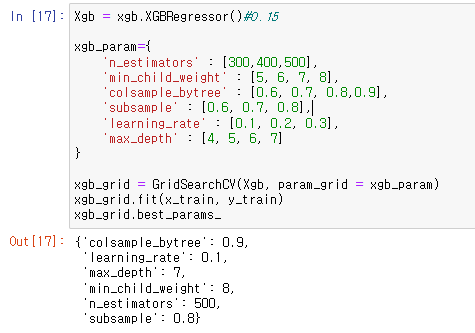
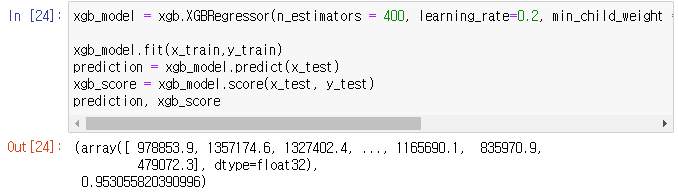
- GridSearch를 이용하여 하이퍼파라미터 튜닝을 진행한 뒤 해당 하이퍼파라미터를 이용하여 XGBoost 모델에 적용한 뒤 score 확인을 하였습니다.
- 위의 각 test_size 비율마다 GridSearch를 하였습니다.
각 모델의 비교
row = [lin_score, dec_score, l1_score, l2_score, forest_score, xgb_score]
col = ['Linear', 'DT', 'Lasso', 'Ridge', 'Forest', 'XGB']
plt.bar(col, row)
plt.show()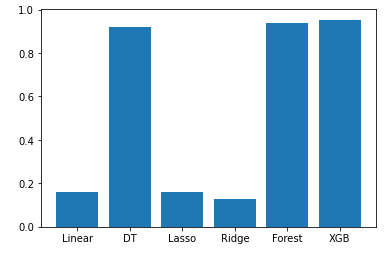
- 각 모델의 score를 비교해본 결과 XGBoost 모델의 score가 가장 높은 것을 확인한 뒤 적용을 할 것입니다.
4. Test_model 적용
test_data["IsHoliday"] = test_data["IsHoliday"].astype(int)
test_data=test_data.fillna(0)
test_x_data = test_data.drop(['id', 'Date', 'IsHoliday', 'Fuel_Price','Temperature'], axis = 1)
xgb_prediction = xgb_model.predict(test_x_data)
sample_submission = pd.read_csv('./dataset/submission.csv')
sample_submission['Weekly_Sales'] = xgb_prediction
sample_submission.to_csv('submission.csv',index = False)
sample_submission.head()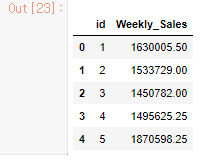
- test_data에도 데이터 전처리를 동일하게 해준 뒤, xgboost 모델을 적용하였습니다.
5. 최종 점수

느낀점
- 첫 제출보다는 점수와 등수가 많이 올라갔지만 조금 더 세밀하게 데이터를 분석하는 법을 공부해야할 것 같다. seaborn과 같은 시각화 라이브러리도 공부하고 정리해서 조금 더 데이터를 시각화하는 방법도 알아야할 것 같았다.
- gridsearch를 하이퍼파라미터를 분할해서 적용을 하면 시간이 줄어드는 것을 알게 되어서 다음 대회때는 조금 더 모델을 사용하는 데 시간을 단축할 수 있을 것 같다.
- 처음으로 Dacon 대회를 참여해봤는데, 공부했던 것들을 다양하게 적용해볼 수 있어서 재밌고 좋았던 것 같다. 다음 대회에서는 조금 더 분석을 세밀히 해서 점수를 올리고 높은 등수를 받는 것을 목표로 해볼 것이다.

안녕하세요 :) Data/AI 공부 중인 한국외대 컴퓨터공학부 조권휘입니다.