[논문 리뷰]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (NAACL 2019)
자연어처리 논문 리뷰
Preface

Motivation
- Bidirectional 이라는 단어 자체가 단순히 LTR RTL 과정만을 읽는 것으로 만족할 수 있을까?
- 문장 읽는 방식이 너무 쉬운 건 아닌가?
1. Introduction
2018년부터 pretrain 을 통한 모델 학습은 높은 성능을 보여주었습니다. pretrained을 하는 방법으로는 2가지가 있는데 첫 번째는 feature-based 방법과 두 번째는 fine-tuning 입니다. feature-based 는 embedding과 같이 pre-trained representation을 나타내는 말이고, fine tuning은 모델의 모든 파라미터를 수정하여 donwstream task에 맞게 작업하는 것입니다.
그 당시로 최근 기술들은 pre-trained representation의 power 들을 제한하고 있습니다. 주된 제한은 pretrained 동안 undirectional 한 방식으로 학습을 하지 않았다는 것입니다. GPT와 같이 왼쪽에서 오른쪽으로 글을 읽는 아키텍쳐 구조상, 다음 토큰의 학습 방법만을 이해할 수 있기 때문에 fine tuning을 하는 과정에서 문제가 발생할 수 있습니다.
그리하여 위 논문의 저자는 BERT(Bidirectional Encoder Representations from Transformers) 구조를 제안합니다. BERT는 maksed language model (MLM)을 이용하여 undirectional한 문제점을 해결하고, pre-trained의 성능을 높여줍니다.
3. BERT
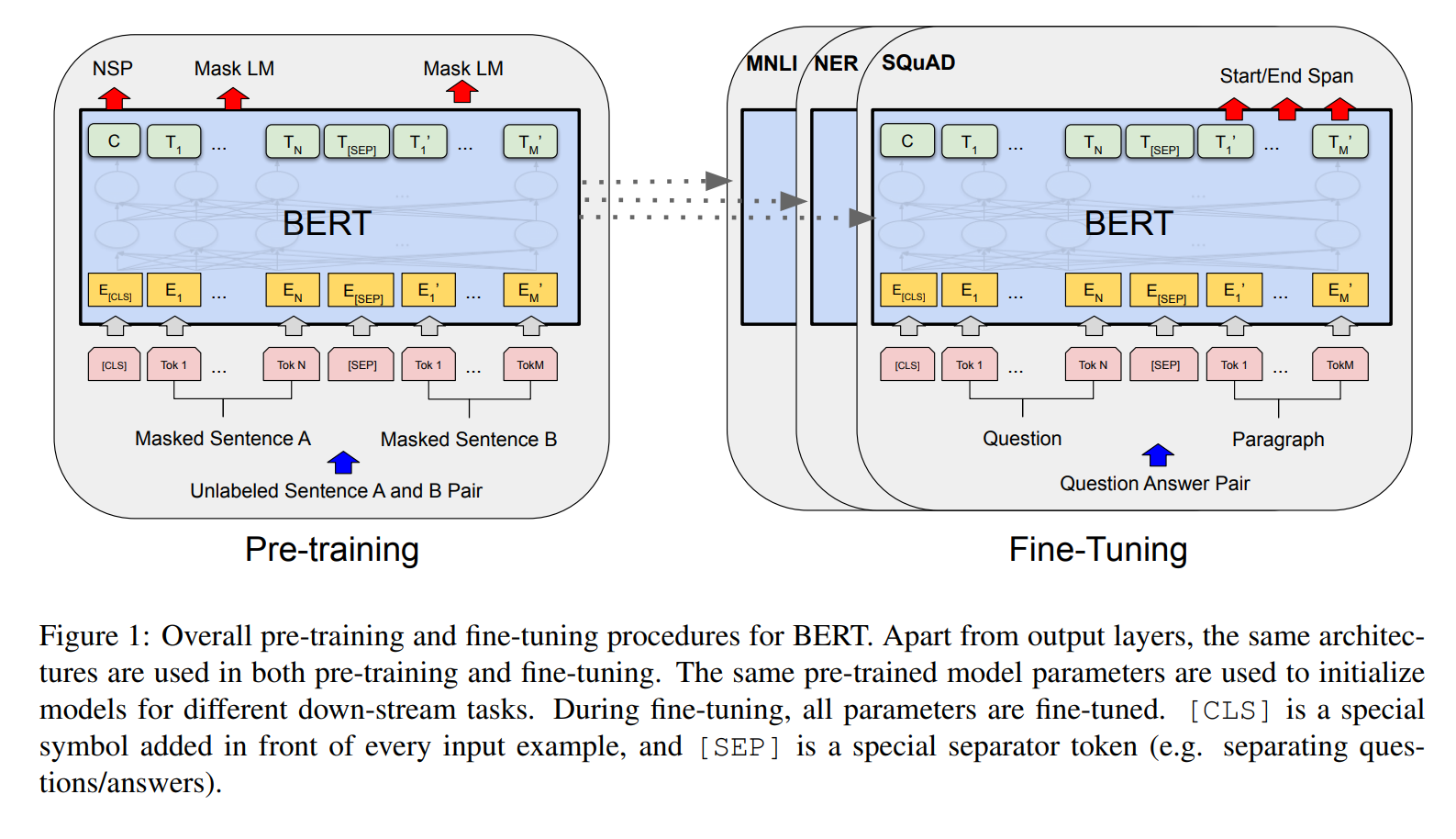
저자는 BERT 모델을 pre-training 과 fine tuning 2가지 구조로 나누어 설명하고 있습니다. 먼저 pre-training 모델은 unlabeled data를 통해서 학습을 진행하고, fine tuning 모델은 pre-trainined된 모델 학습 이후 parameter를 이용하여 down stream task에 적용을 하게 됩니다. 위 그림에서 MNLI, NER, SQuAD는 데이터 이름으로 초기 unlabeled 된 데이터를 통해 Pre training한 모델을 각 데이터에 맞게 question and answering 파트로 fine tuning 하는 과정을 보여주고 있습니다.
Model Architecture
BERT 모델의 아키텍쳐는 multi - layer bidirectional Transformer encoder입니다. BERT Base 구조는 Layer = 12, Hidden size = 768, the number of self attention = 12, total parameter = 110만개이고, BERT Large 구조는 Layer = 24, Hidden size = 1024, the number of self attention = 16, total parameter = 340만개로 구성되어 있습니다.
구조는 GPT 구조와 비교하기 위해 똑같은 설정으로 학습을 진행하였습니다. 그러나 GPT는 왼쪽에서 오른쪽으로 학습되는 제한된 self-attention을 사용하였고, BERT transformer는 양방향의 self attention을 사용하였습니다.
Input/Output Representations
BERT의 input 데이터는 sequence로 한 토큰에 2개의 문장으로 구성되어 있습니다. (ex QA). 위 모델은 WordPiece embedding을 사용하여 항상 처음 토큰은 CLS로, 문장을 구분할 때는 SEP로 구분을 하였습니다.
3.1 Pre-training BERT
BERT는 전통적인 왼쪽에서 오른쪽, 오른쪽에서 왼쪽의 구조를 사용하지 않고 양방향의 학습 과정을 둘다 사용합니다
Task #1 : Maksed LM
직관적으로, deep bidirectional model은 단순한 left to right 나 right to left 모델보다 더 강력합니다. 하지만 양방향 모델은 간접적으로 단어의 위치를 확인할 수 있고, 그 모델이 multi - layer에서 target word를 예측하기 쉬워진다. 그래서 deep bidirectional representation을 학습하기 위해, 저자는 몇개의 인풋 데이터를 mask 하여 그 mask된 방식을 예측하기로 합니다. 위와 같은 방식을 maksed LM (MLM) 이라고 부릅니다. 실험 과정 모든 모델은 15퍼센트의 마스크를 진행하여 학습하였습니다.
하지만 저자는 pre-training과 fine tuning 사이의 mismatch가 단점임을 언급합니다. mask token은 fine tuning에 등장하기 않기 때문입니다. 그리하여 저자는 항상 masked된 단어가 등장하는 것이 아니라 15퍼센트만 랜덤으로 등장하게 하는데, 만약에 i번째 토큰이 선택되면, 우리는 학습 시간중 80 퍼센트는 maksed된 token을, 10퍼센트는 random token을, 나머지 10퍼는 변환을 하지 않기로 합니다.
Task #2 : Next Sentence Prediction (NSP)
QA와 NLI 와 같은 task는 두 문장 사이의 관계를 이해하는 것이 중요합니다. 그리하여 모델이 이를 잘 판단할 수 있기 위해서 next sentence prediction task를 통해 pre - trained을 진행합니다. pre-training 문장에서 A와 B를 선택할 때, B의 50퍼센트는 A를 따르는 실제 문장이고, 나머지 50퍼센트는 random sentence로 설정합니다.
Pre-training data
BooksCorpus와 English Wikipedia corpus를 통해 pre-training을 진행하였습니다.
3.2 Fine-tuning BERT
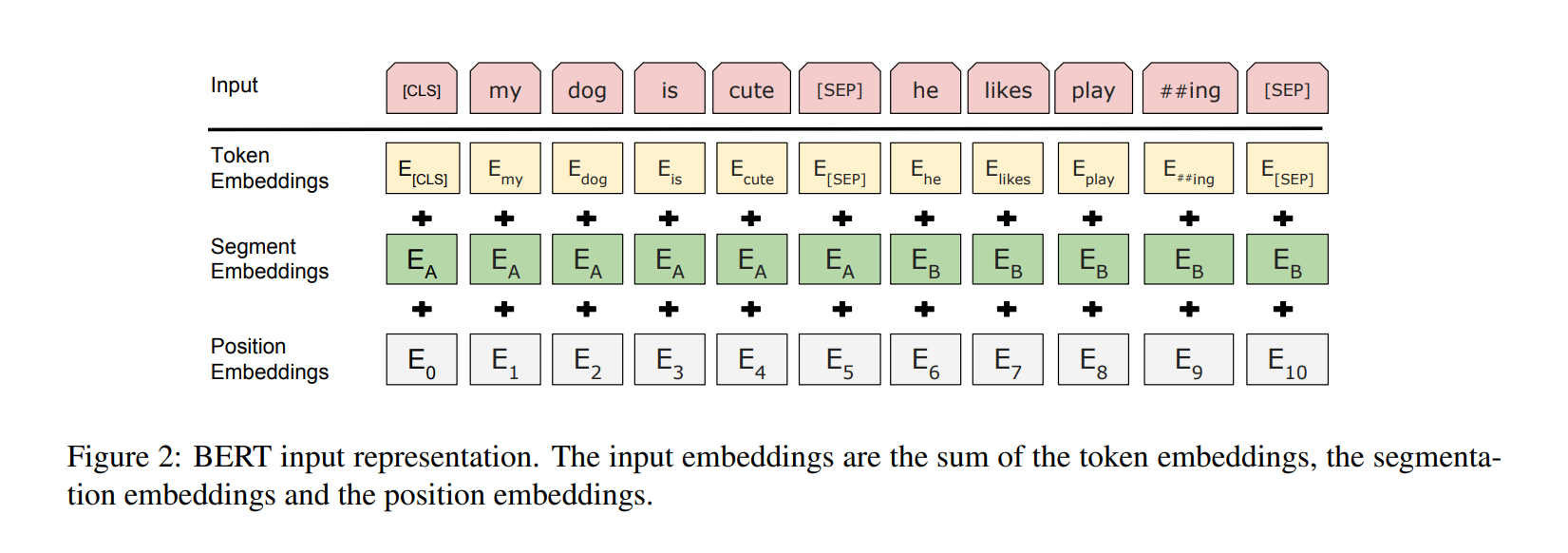
Transformer 구조 덕분에 Fine tuning은 straightforward 합니다. 이전 연구에서 common patterns는 cross attention을 하기 전에 독립적으로 text pair를 encode 합니다. BERT는 대신에 self attention mechanism을 사용하여 두 과정을 unify 합니다.
각 테스크에 맞게 학습을 할 때, input 과정에서, 문장 A와 B는 (1)sentence pair in paraphrasing이나 (2) hypothesis-premise pairs in entailments나 (3) question - passage pairs in question answering, (4) a degenerate text pair in text classification or sequence tagging 등 다양한 테스크에 적용할 수 있습니다.
output 과정에서는 token representations 들이 output layer로 token level task 나 CLS representation 에 진행될 수 있습니다. Fine-tuning 과정은 사전 훈련(pre-training) 과정에 비해 상대적으로 비용이 적게 듭니다. 논문에 나온 모든 결과는 Cloud TPU 한 대를 사용하여 최대 1시간, 또는 GPU를 사용할 경우 몇 시간 이내에 재현될 수 있으며. 이는 동일한 pre-trained 모델에서 시작됩니다.
4. Experiments
4.1 GLUE
GLUE는 General Language Understanding Evaluation으로 앞 글자를 따서 GLUE 라고 부릅니다. GLUE는 다양한 자연어 테스크를 모아서 만든 데이터를 benchmark 한 것입니다. GLUE에 fine tuning 하기 위해서, 저자는 input sentence를 이전에 section 3 에서 설명한 방식으로 표현을 하고, 새롭게 사용한 파라미터는 classification을 위한 마지막 layer weight를 표현하고 있습니다.
batch size는 32이고 3에폭 동안 데이터를 학습하였습니다. 학습률은 (among 5e-5, 4e-5, 3e-5, and 2e-5) 과정으로 진행했습니다.
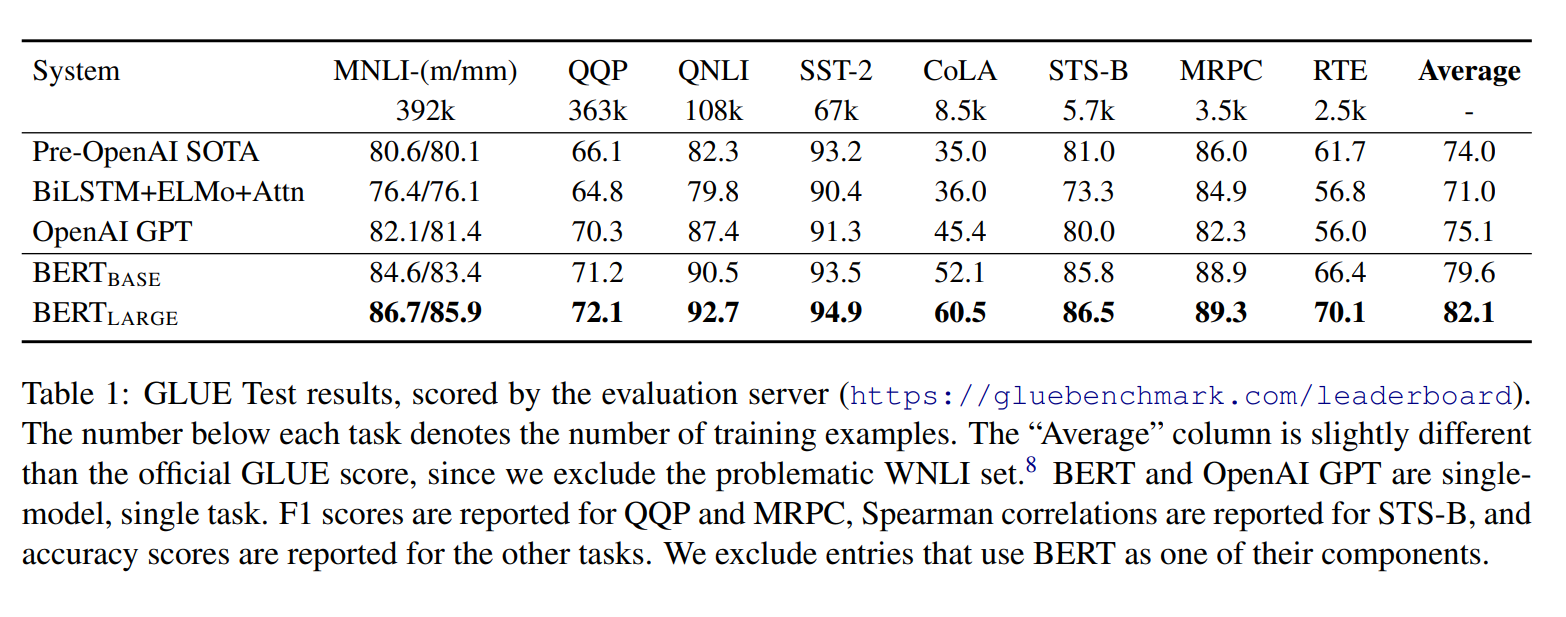
결과는 위 테이블로 BERT base와 large 모델은 다른 기존의 모델 보다 엄청나게 높은 성능을 보여주고 있습니다. 그리고 초기에 설명했듯이, GPT와 BERT base 구조는 똑같은 하이퍼 파라미터와 파라미터를 사용해서 학습을 하였지만 결국에는 BERT가 더 높은 성능을 보여주었습니다.
5.Ablation studies
5.1 Effect of Pre-training Tasks
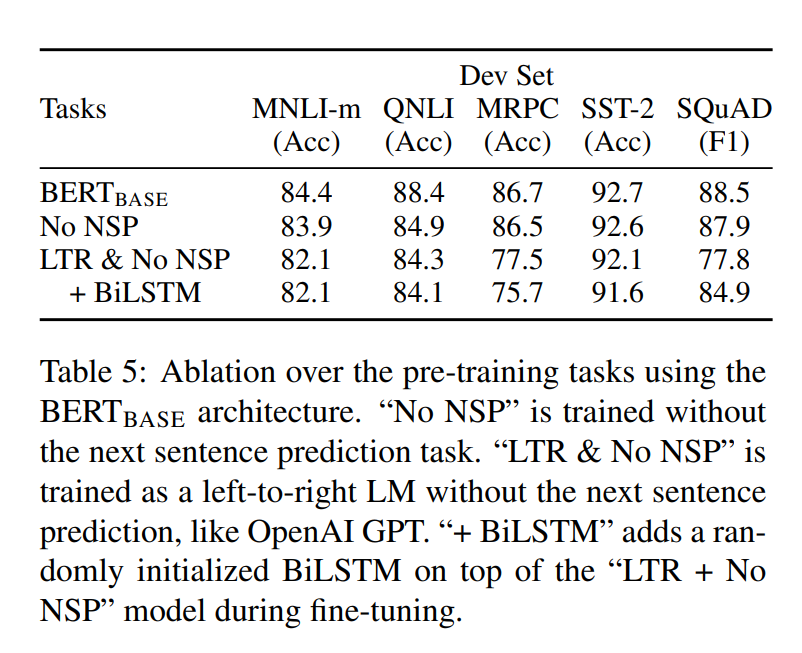
BERT 구조는 NSP와 MLM 구조를 통해 pre-training 을 진행했는데 각 과정이 만약에 빠진다면 성능이 어떻게 될 것인가? 에 대한 테이블을 위에 적었습니다. 그리하여 위 과정은 MLM은 진행되지만 NLP 작업은 진행되지 않았을 상황입니다.
- 표에서 볼 수 있듯, pre-training task를 하나라도 제거하면 성능이 굉장히 떨어지는 것을 볼 수 있습니다.
- No NSP의 경우에는 NLI계열의 task에서 성능이 많이 하락하게 되는데, 이는 NSP task가 문장간의 논리적인 구조 파악에 중요한 역할을 하고 있음을 알 수 있습니다.
- MLM대신 LTR을 쓰게 되면 성능하락은 더욱더 심해지게 됩니다. BiLSTM을 더 붙여도, MLM을 쓸 때보다 성능이 하락하는 것으로 보아, MLM task가 더 Deep Bidirectional한 것임을 알 수 있습니다.
5.2 Effect of Model Size
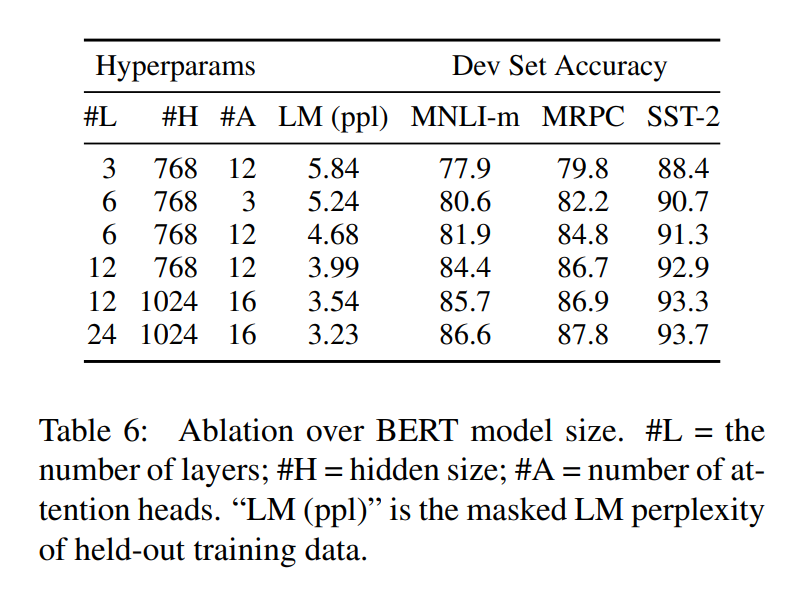
위 결과는 모델의 크기가 모델 성능에 얼마나 영향을 미치는 가? 인데 단순하게 모델의 크기가 커지면 커질수록 점점 성능이 올라감을 볼 수 있습니다. BERT는 pretrained 덕분에 학습 데이터의 양이 적어도 굉장히 높은 성능을 보여줍니다.
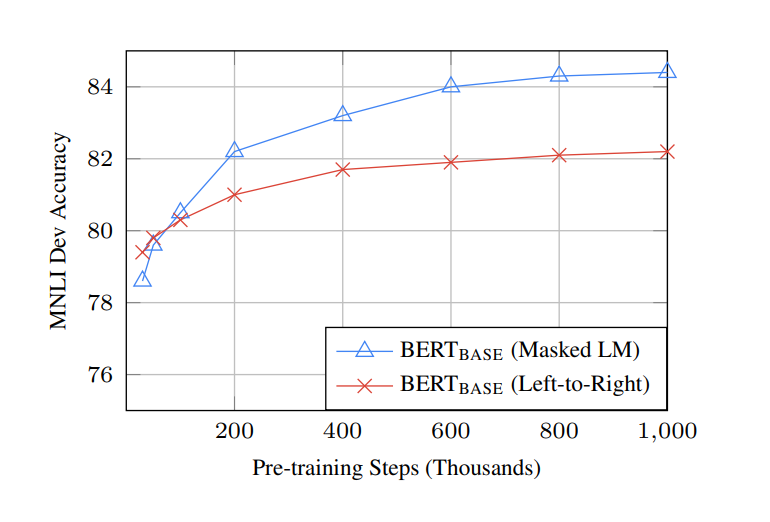
위 표를 보게 되면, MLM으로 학습하면 15%의 단어만 맞추는 것으로 학습을 진행하기 때문에, LTR보다 수렴속도가 훨씬 느리지만, LTR보다 훨씬 먼저 out-perform성능이 나오게 됩니다.
5.3 **Feature-based Approach with BERT**
위 과정까지는 Fine tuning에 대한 downstream task를 보여주었습니다. 이 챕터는 Feature-based에 대한 과정을 보여주고 있습니다. 하지만 BERT를 ELMO와 같이 feature based approach로도 사용을 할 수 있습니다. 모든 테스크가 Transformer encoder에 쉽게 표현되기는 어렵기 때문에, pretrain을 하면 비용적으로 이점을 얻을 수 있기 때문에 feature-based 모델도 필요합니다.
해당 section에서는 BERT를 ELMO와 같이 마지막 레이어에 Bi-LSTM을 부착시켜, 해당 레이어만 학습 시키는 방법론을 사용해보았습니다.
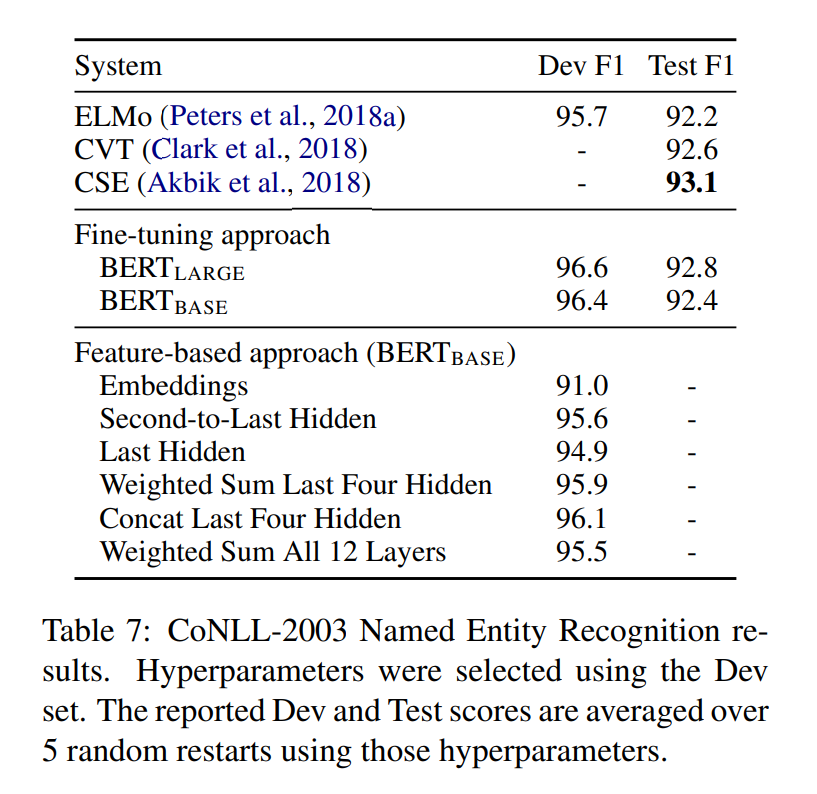
위 표를 보게 되면, BERT Large 모델이 가장 높은 성능을 보여줌을 알 수 있습니다.
6. Conclusion
적은 데이터로도 엄청난 성능을 뽑을 수 있었던 BERT는 미래에 NLP 연구에 큰 도움이 될 것이다 라고 말하시네요.
한 줄로 요약하면?
BERT는 이전에 Bidirectional 이라는 학습 방법을 조금 바꿔서 MLM와 NLS를 도입하여 학습하고, 단순히 마지막에 필요한 layer를 추가하여(Fine tuning) 높은 성능을 보여주는 좋은 모델이다.
