자연어처리 논문 리뷰
1.[논문 리뷰]Effective Approaches to Attention-based Neural Machine Translation - Luong Attention

저번 시간에는 attention 기법을 통해 NMT에서 단어의 중요도를 알고, 이를 바탕으로 모델 학습을 하여 긴 문장에도 학습이 잘 된 경우를 보았습니다. 이번 시간에는 이런 Attention 기법을 어떻게 효율적으로 이용할 수 있는지에 대해서 배워봅시다. 위 논문에
2.[논문 리뷰] Neural Machine Translation by Jointly Learning to Align and Translate - Bahdanau Attention
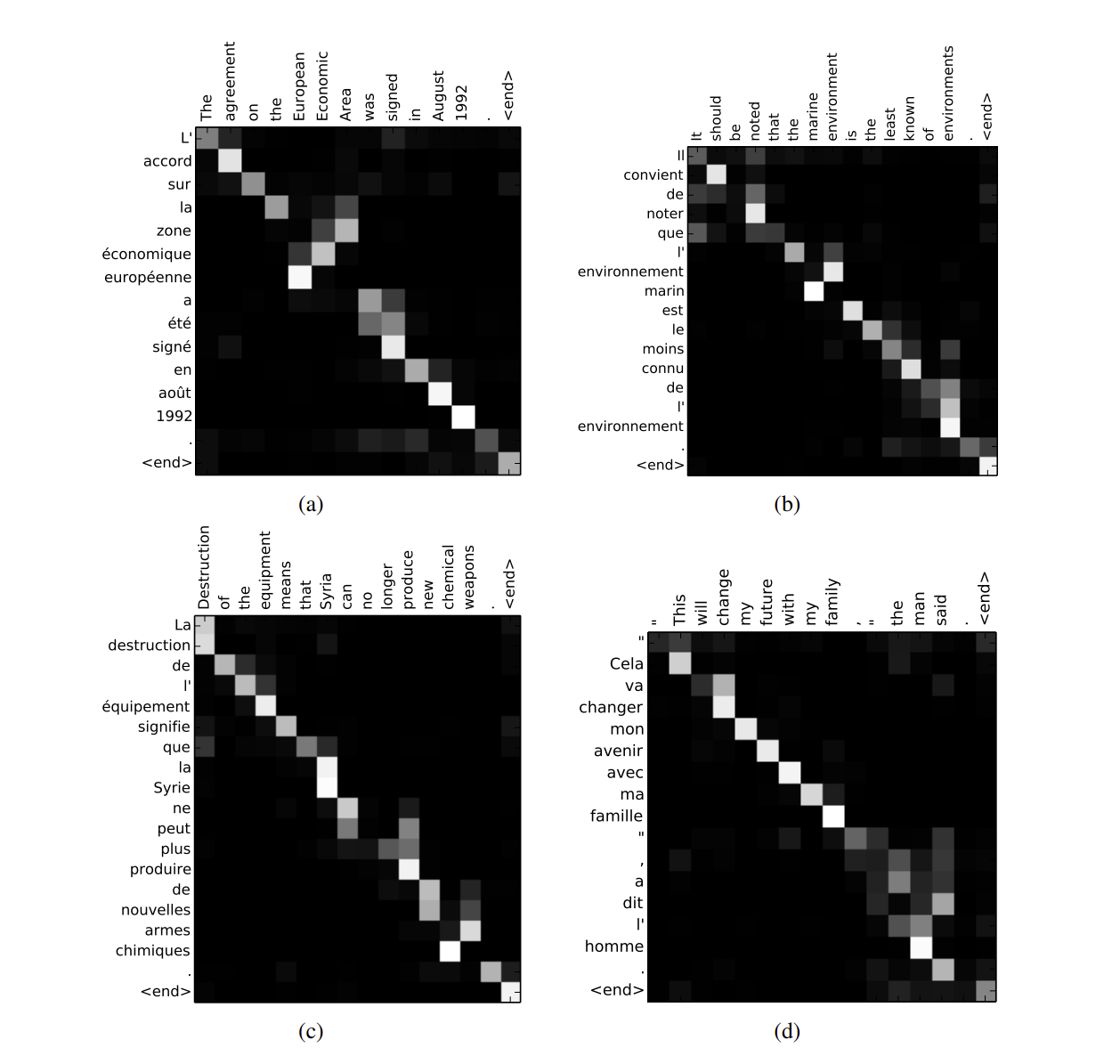
Preface 오늘은 트랜스포머 논문의 핵심 기법인 어텐션 기법이 기계 번역에 어떻게 사용이 되었는 지에 대한 논문을 읽어보겠습니다. 급하신 분들은 챕터 3부터 해보시면 될 거 같습니다! + latex를 처음 쓰는 과정이라 조금 어숙합니다.. ㅠ (2단원은 RN
3.[논문 리뷰] Attention is All you need

우리는 앞에서 딥러닝의 기초부터 시작해서 자연어처리의 기계 번역을 담당한 seq2seq와 다양한 attention의 기법에 대해서 배웠습니다. 이제는 자연어처리의 시작인 Transformer 논문을 리뷰해보겠습니다. RNN와 LSTM이 가지는 장기 의존성 문제나 기울기
4.[논문 리뷰]Improving Language Understanding by Generative Pre-Training - GPT

이번 시간에는 자연어처리에서 많이 사용하는 Open Ai의 GPT - Generative Pretrained-Transformer 의 시초를 알린 논문을 읽어보겠습니다. 이번 시간의 핵심은 'Generative Pre-Training', 즉 생성적 사전 학습 방법론에
5.[논문 리뷰] Universal Language Model Fine-tuning for Text Classification

이번 시간에는 전이학습이라고 불리는 transfer learning을 공부하고, transfer learning이 NLP 분야에 어떻게 영향을 끼쳤는지에 대해서 배워보겠습니다.Transfer learning의 주요한 문제점 중 하나는 catastrophic forget
6.[논문 리뷰] Deep contextualized word representations - ELMo(Embedding from Language Models)

기존의 word representation 모델들은 Word2Vec와 Globe 들로, 단어를 벡터로 변환하는 데 사용하였습니다. 여기서 문제점은 단어의 맥락 판단이 전혀 불가능했다는 점입니다. 예를 들어, ‘bank’ 라는 단어는 은행이지만, ‘둑’ 이라는 뜻으로도
7.[논문 리뷰]Transformer - XL : Attentive Language Models Beyond a Fixed - Length Context

언어 모델의 특징은 문장을 다루기 때문에, 문장의 길이가 모델 성능을 좌지우지 하는 경우가 매우 많습니다. 그렇기에 긴 문장을 다룰줄 아는 것은 굉장히 중요합니다. 대표적인 언어 모델로는 RNN, LSTM 등이 사용되었는데, 기울기 소실 문제 등으로 긴 문장들을 다루
8.[논문 리뷰]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (NAACL 2019)

Bidirectional 이라는 단어 자체가 단순히 LTR RTL 과정만을 읽는 것으로 만족할 수 있을까?문장 읽는 방식이 너무 쉬운 건 아닌가? 2018년부터 pretrain 을 통한 모델 학습은 높은 성능을 보여주었습니다. pretrained을 하는 방법으로는 2가
9.[논문 리뷰] Cross-lingual Language Model Pretraining(XLM)

BERT를 가지고 두 언어를 학습하면 더 좋은 성능을 낼 수 있지 않을까? 라는 생각을 시작으로 기계 번역에 굉장히 높은 성능을 보여주었습니다. 문법이 비슷한 두 언어는 비슷한 구조이니 번역을 할 때 같이 사용할 수 있지 않을까? 라는 생각도 마찬가지로 하여 소수 언어
10.[논문 리뷰]Language Models are Unsupervised Multitask Learners - GPT2

2019년 당시 머신러닝 학습은 엄청난 데이터셋과 supervised learning을 통해 진행되었습니다.. 그러나 이러한 구조는 다루기 힘들고, 약간의 변화에도 민감하다 보니 이를 일반화할 수는 없을까? 라는 생각에서 GPT2 논문이 나오게 되었습니다. ML 시스템
11.[논문 리뷰] RoBERTa: A Robustly Optimized BERT Pretraining Approach

ELMo, GPT, BERT, XLM, XLnet과 같은 모델들은 굉장히 높은 성능으로 당시 SOTA들을 기록했습니다. 하지만 어느 측면에서 어느 모델이 가장 높은지를 확인해야 했죠. 학습을 한 번 할 때마다 드는 비용은 엄청나게 많았고, 사용하는 데이터들도 제각각
12.[논문 리뷰] How multilingual is Multilingual BERT?

기존의 BERT는 영어 텍스트만을 통해서 학습해왔습니다. 그리하여 이 논문에서는, representation을 다양한 언어를 통해서 일반화를 진행하자는 취지로 조사를 시작했습니다. 저자는 새로운 BERT인 M-BERT를 제안하였습니다. 기존의 BERT는 Wikiped
13.[논문 리뷰] XLNet: Generalized Autoregressive Pretraining for Language Understanding

Pretrain의 성공적인 언어 모델 중 2개는 autoregressive (AR) 언어 모델과 autoencoding (AE) 모델입니다. AR 모델은 autoregressive model 능력으로 $X = (x{1},\\dots, x{T})$ 와 같은 텍스트에,
14.[논문 리뷰] Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of BERT

Artetex et al(2018)은 기존의 cross lingual 모델은 단어간의 연결 고리를 직접 만들어서 학습을 진행하였다. 하지만 BERT가 출시 된 이후로는 어느 alignment도 없이, 언어적 연결고리를 직접 만들지 않고도 사전적으로 이해가 가능해졌다.
15.[논문 리뷰] BART - Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension

일반적인 supervised learning과 unsupervised learning의 중간 단계라고 볼 수 있습니다. 학습 방식은 기존의 train data의 일부를 test data로 사용합니다. 그렇데 되면 일부를 누락시킨 다음에, 이를 맞추는 방식으로 학습이 되
16.[논문 리뷰] T5 - Exploring the Limits of Transfer Learning with a Unified Text_to_Text Transformers

T5 논문은 너무 길어서 최대한 논문에서 말하고자 하는 바를 위주로만 정리하였습니다…(67장 넘 길어..) 논문이 나올 당시에는, transfer learning이 명확하게는 진행되지 않았고 하나의 보조 도구로만 취급을 했습니다. 예를 들어서, Word2Vec와 같이,
17.[논문 리뷰] Language Models are Few-Shot Learners - GPT3

저자는 NLP의 역사를 읊으면서 task-specific한 모델이 아닌 task-agnostic을 제안합니다. 첫번째로, large dataset을 모으기는 힘들다는 점, 두번째로, training data의 spurious correlations(허위 상관)이 모델
18.[논문 리뷰] Extending Multilingual BERT to Low-Resource Languages

Zero shot learning을 통해서 low source language을 살릴 수 있는 방법이 점점 고안되고 있습니다. 특히 M-BERT는 소말리아어나 위구르언어와 같이 데이터가 부족한 언어들 또한 살릴 수 있다는 것이었습니다. 하지만 M-BERT가 그렇다고
19.[논문 리뷰] SCOPA : Soft Code - Switching and Pairwise Alignment for Zero-Shot Cross - Lingual Transfer

각 언어가 pretrained 을 되면서 독립적으로 학습이 되지만, 언어들 사이에는 ‘common feature’ 이 같은 weight들을 공유하면서 학습이 진행됩니다. 이러한 transfer을 더 enhance 하기 위해서, XLM-R은 Common CRawl Co
20.[논문 리뷰] Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation (2020 ACL)

Multilingual NMT가 큰 이점을 가지고 있음에도 불구하고, 너무 많은 언어들이 모델에 포함되어 있을 때, 종종 성능을 낮추게 하는 경우가 있습니다. 왜냐하면 MNMT의 언어들은 각자 언어적 특징을 가지는 게 다르기 때문에, 모델의 capacity가 굉장히
21.[논문 리뷰] Training language models to follow instructions with human feedback(InstructGPT)

GPT1은 Transformer의 Decoder 구조를 12개의 layer를 쌓아 올린 구조입니다. Pretraining을 위해서 Language Modeling을 했습니다. 이는 주어진 토큰 시퀀스를 바탕으로 다음에 올 토큰을 예측하게 하는 auto regressiv