preface

Motivation
BERT를 가지고 두 언어를 학습하면 더 좋은 성능을 낼 수 있지 않을까? 라는 생각을 시작으로 기계 번역에 굉장히 높은 성능을 보여주었습니다. 문법이 비슷한 두 언어는 비슷한 구조이니 번역을 할 때 같이 사용할 수 있지 않을까? 라는 생각도 마찬가지로 하여 소수 언어를 발전시키는 데 큰 기여를 할 수 있었습니다.
1. Introduction
Generative pretraining of sentence encoder의 발전으로 NLP에 높은 성능을 보여주었습니다. 아무리 이들이 높은 성능을 보여줬더라도, 단일 언어(monolingual)로 적혀있다보니 특히 영어 위주로 글이 적혀있음을 알 수 있습니다. 당시에 연구였던 cross lingual sentence representation은 영어 중심의 학습 bias를 최소화하고 다양한 언어를 기반으로 한 encoder를 만들자는 의견을 내었습니다.
그리하여 위 논문에서, 저자는 XLU 데이터를 기반으로 한 effectiveness 한 cross lingual model 을 제안하였습니다.
2. Related Work
2018년에 작성된 GPT1논문에서 pretrained의 높은 성능을 보였기에 위 구조를 바탕으로 논문을 작성하였다고 합니다. 더불어 machine translation 쪽으로도 굉장히 높은 성능을 보이고 있습니다. Mikolov et al. (2013) Word2Vec를 시작으로 text representation은 굉장히 발전을 보여주었습니다.
Faruqui and Dyer, 2014은 cross lingual의 학습으로 인해 monolingual 언어 성능도 오름을 보여주었고 Xing et al . 2015는 orthogonal 한 변형으로 word distribution을 주장하기도 하였고, Am-mar et al., 2016에는 위 모든 테크닉을 합쳐서 정리하였습니다. 2017년에는 Vision 분야에서는 cross lingual의 필요성을 줄이고, 결국에는 완전히 제거하는 방향으로 나아갔습니다.
Johnson et al. (2017)의 연구는 단일 Seq2Seq 모델을 사용하여 다양한 언어 쌍의 기계 번역을 수행할 수 있음을 보여줍니다. 당시 LSTM을 가지고 학습하여 다언어 모델은 저자원 언어 쌍에서 최신 기술을 능가하고 제로샷 번역을 가능하게 했습니다.
위 연구를 바탕으로 Artetxe and Schwenk (2018)은 result-ing encoder 를 사용하여 cross lingual 문장 임베딩을 생성할 수 있음을 보여주었습니다. 이들은 2억 개 이상의 병렬 문장을 활용하여 XNLI cross lingual benchmark 에서 새로운 최고 수준을 달성했습니다.
2018년 당시 최근에는 비지도 학습을 통하여 cross lingual도 보여주고 있습니다. Lample et al. (2018)은 병렬된 문장을 사용하지 않고도 문장 표현을 완전히 비지도 방식으로 정렬할 수 있음을 보여주었습니다. 예를 들어, Lample et al. (2018b)는 WMT’16 독일어-영어에서 25.2 BLEU 점수를 달성했습니다.
3. Cross - lingual language models
저자는 3가지 구조를 제안하였습니다. 그중 2개는 단일 언어의 데이터만 필요하며(unsupervised), 나머지 하나는 언어쌍 데이터가 필요합니다. 언어의 개수는 개이며, 개의 단일 언어에 각각 코퍼스는 로 구성되어 있고, 는 에서 문장의 개수입니다.
3.1 Shared sub-word vocabuluary
저자는 BPE를 통해 만든 똑같은 사전을 활용한 언어로 진행을 하였습니다. monolingual corpora에 BPE를 진행하였고, 문장들은 multinomial distribution으로 sampled 되었습니다.
예를 들어, 영어와 독일어 번역 중 house 라는 단어에서 hou 가 자주 나오게 된다면, BPE를 통해서 두 언어가 비슷한 공통점이 있다는 것을 모델이 알게할 수 있습니다. 저자는 를 0.5로 설정하였고, 모든 단어들을 합친 다음에 이를 random sampling 합니다. random sampling을 할 때는 multinomial distribution으로 샘플링을 진행하여 저차원의 언어가 자주 나오게 하고, 고차원의 언어는 적게 나오게 합니다.
3.2 Causal Language Modeling(CLM)
CLM 테스크는 Transformer의 형태로 구성되어 있고, 이전의 단어들을 보고 이후 단어를 예측하는 구조입니다.
LSTM의 경우에, BPTT 과정시 마지막 layer를 가지고 진행을 합니다. 반면 Transformer는 이전의 hidden state들이 current batch로 통과하고 batch의 첫번째 단어에 context를 제공하는 방식입니다.
하지만 이 기술은 cross lingual setting과 맞지 않기에, context없이 각 배치에 first words를 남기는 방식을 선택하였습니다.
3.3 Masked Language Modeling (MLM)
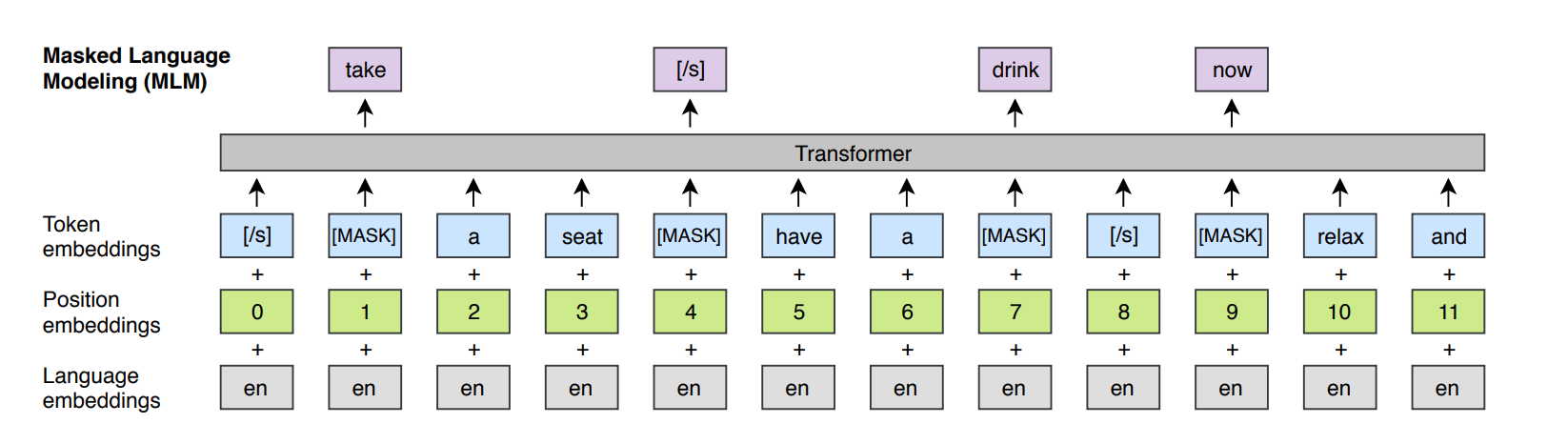
BERT에서 보였던 masked된 방식을 이용하여 text에서 15퍼센트 확률로 BPE 토큰으로 sampling 하게 설정하였습니다. 문장 중 80퍼센트는 mask 토큰으로, 나머지 10퍼는 랜덤 토큰으로, 나머지 10퍼는 유지를 하였습니다. 위 방식과 BERT 차이는 pairs of sentence 대신에 aribitrary number of sentence의 텍스트 스트림을 활용한다는 것입니다.
빈도가 잦고, 낮은 단어들의 불균형을 해결하기 위해서, 자주 나오는 결과를 subsampling 합니다. multinomial distribution에 바탕으로 text stream에 있는 토큰들을 샘플링합니다.
3.4 Translation Langugage Modeling (TLM)
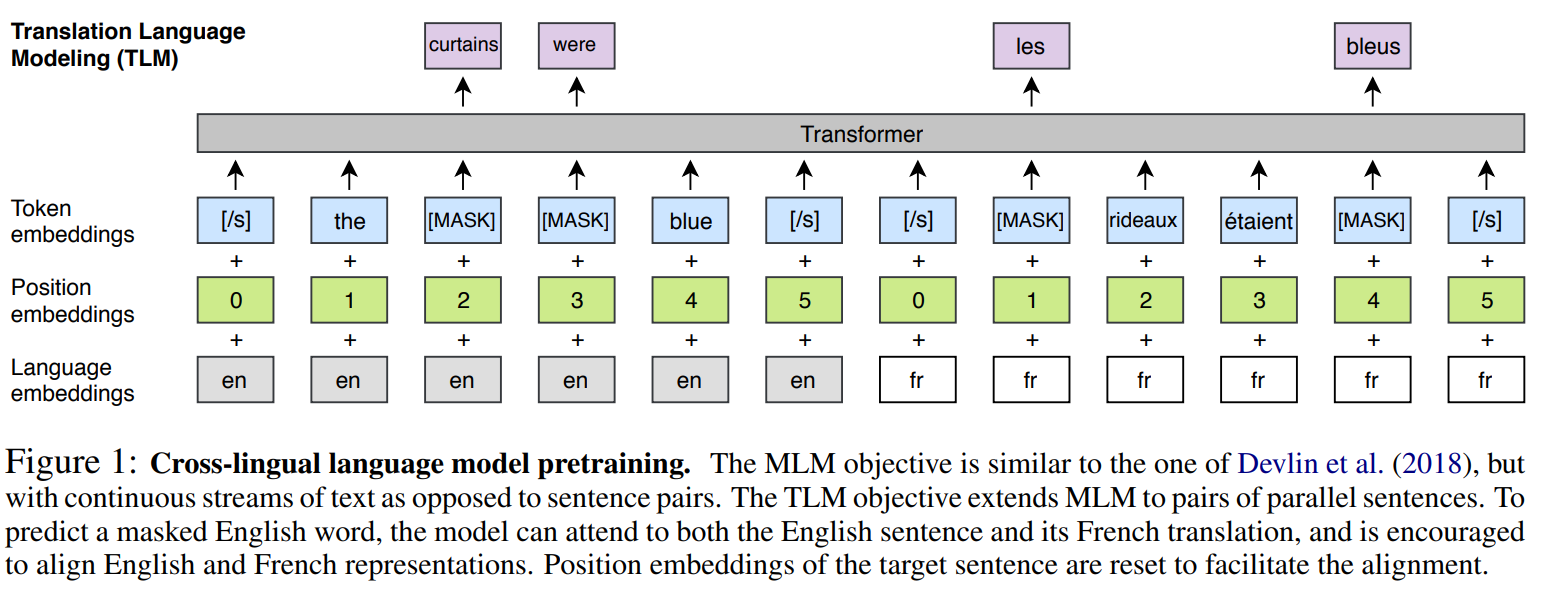
위에서 설명한 CLM와 MLM은 모두 unsupervised한 방식으로 pretrained에 해당됩니다. 그래서 오직 단일 언어만 필요합니다. 그러나 downstream task를 위해서는 supervised한 방식으로 학습을 해야 되기에, 저자는 새로운 언어 모델링 구조인 TLM을 제안합니다. TLM의 목적은 MLM을 확장한 것으로, 단일 언어 text stream을 고려하는 것 대신에, 위의 사진과 같이, 해당 언어들을 concatenate하여 학습을 하는 것입니다. 영어 문장에서 word mask를 예측하기 위해서는, 모델은 English 나 Franch 에서 surrounding 환경에서 maks된 답을 찾아볼 수 있습니다. 이는 부족한 언어 부분을 도와주어 부족한 단어를 매꿀 수 있습니다.
3.5 Cross - lingual Language Models
저자는 CLM MLM 그리고 TLM을 조합하여 학습하였습니다. CLM와 MLM을 위해, 256개의 토큰들로 구성된 연속적인 문장 64개의 배치들을 학습하였습니다. 학습을 할 때 마다, 배치는 같은 언어에서 문장들이 나오게 구성을 했고, 마찬가지로 위의 multinomial 에서 가 0.7인 값으로 샘플링을 진행하였습니다. TLM 에서는 MLM과 조합하여 학습하였습니다.
4. Cross-lingual langugage model pretraining
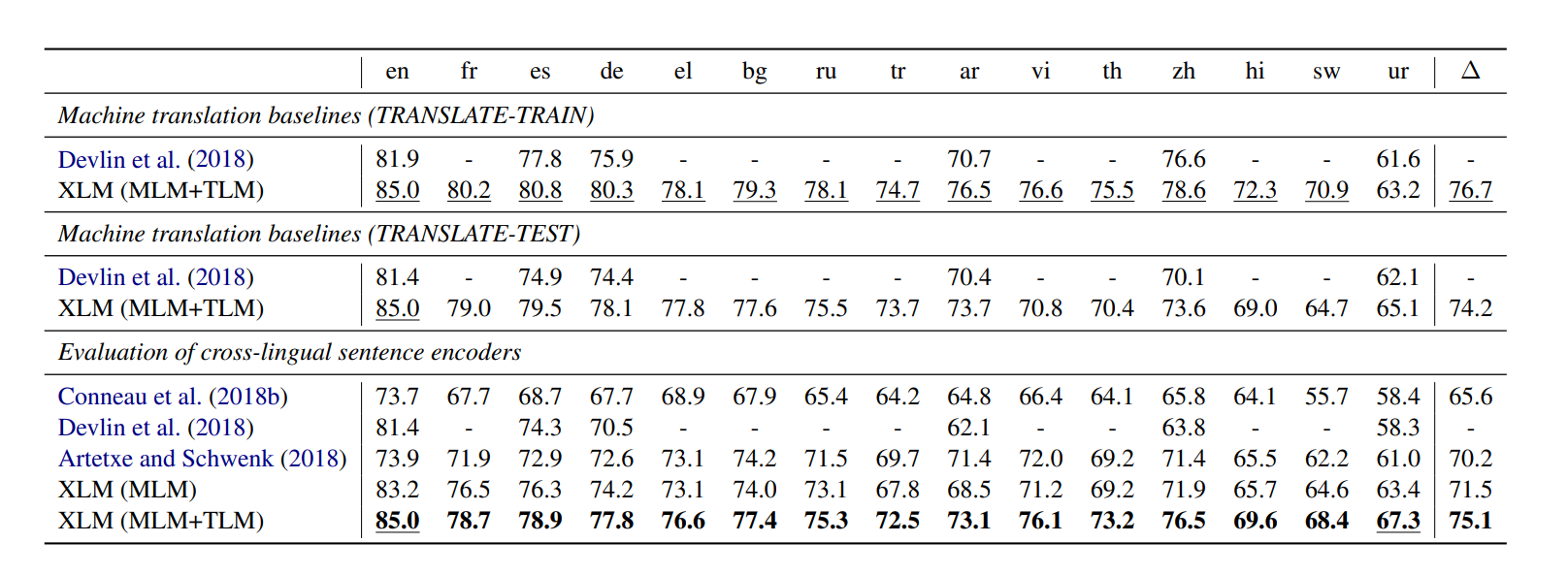
4.1 Cross-lingual classification
XLM 모델은 기존의 단일 언어 모델을 fine tuning 하여, english classification을 한 것 보다 더 좋은 퍼포먼스를 보여주었습니다. 데이터는 XNLI 데이터를 사용하였고, 분류 뿐만 아니라 machine translation도 추가하였습니다. 위 결과를 확인해보면 기존의 Devlin et al.에서 제안한 구조보다 더 높은 성능을 보여줌을 볼 수 있었습니다.
4.2 Unsupervised Machine Translation
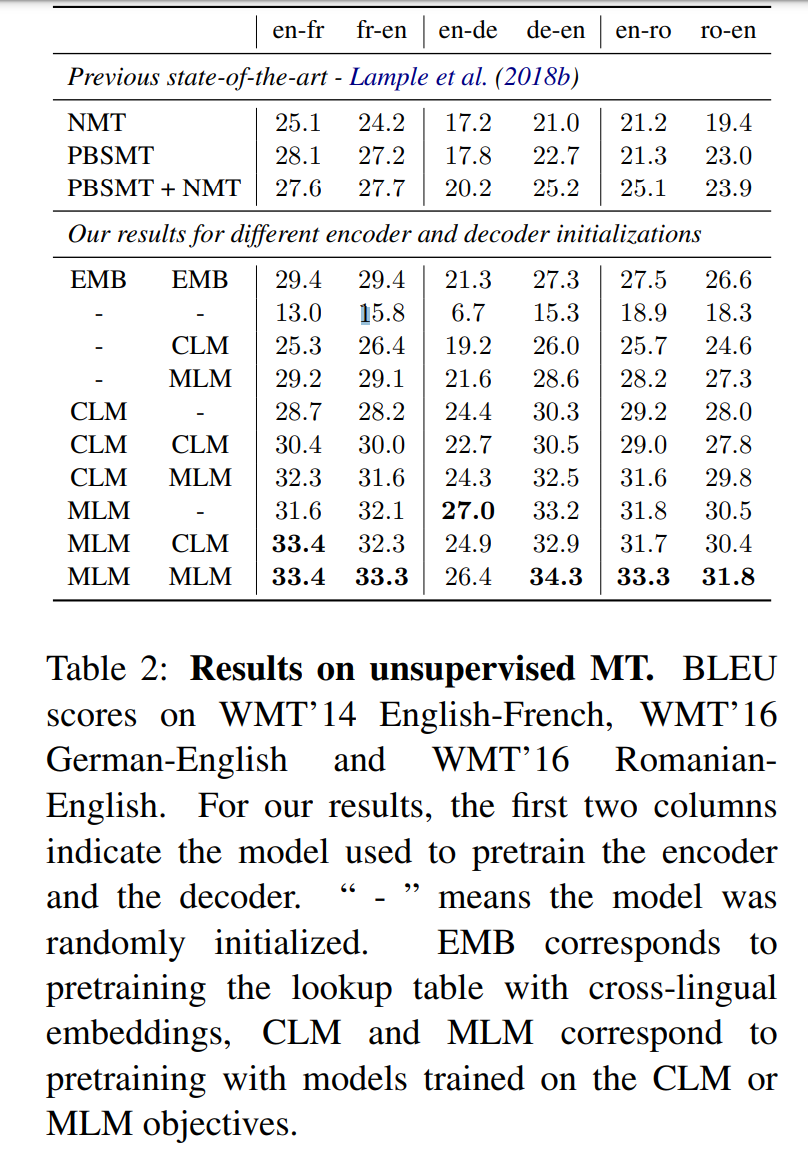
Pretraining은 NMT에서 엄청 중요한 재료입니다. Lample et al 에서 제안한 pretrained된 모델은 cross lingual word embedding을 이용하여 unsupervised machine translation에서 매우 높은 성능을 보여주었습니다. 저자는 cross-lingual model들과 인코더, 디코더들을 모두 학습한 다음에, 이 아이디어를 참고하여 더 높은 성능을 보여주었습니다. 위의 표는 WMT14 english - french 학습을 통한 BLEU가 굉장히 높다는 것을 보여주었습니다.
4.3 Supervised Machine Translation
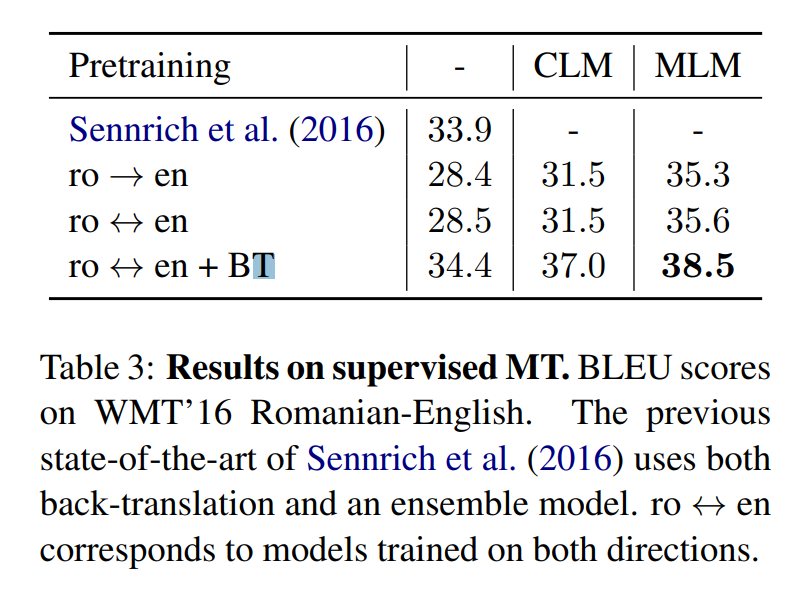
또한 CLM와 MLM을 적용한 구조에서도 높은 성능을 보여주었습니다.
4.4 Low - resource language modeling
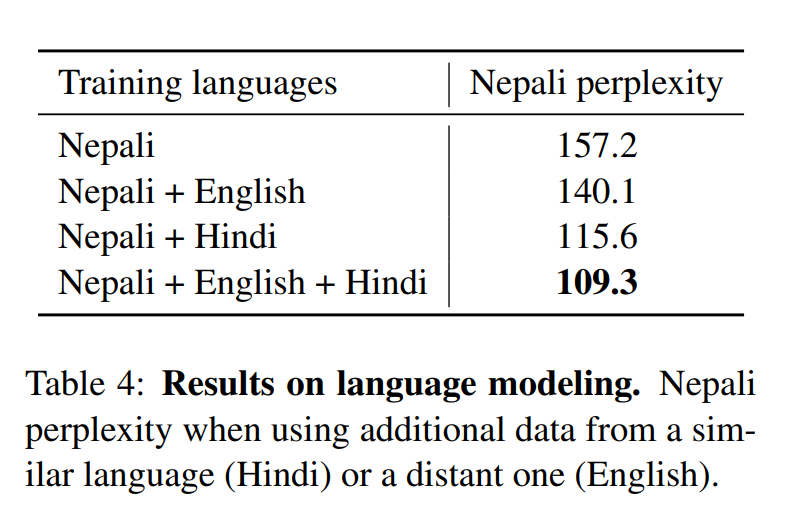
resource가 적은 언어에 대해서, 문법 구조가 비슷하지만 자료가 많은 언어 데이터를 가지고 학습을 진행하면 굉장히 이점이 많습니다. 예를 들어서, 네팔어는 위키피디아에 10만개의 문장이 있지만 힌도는 그것보다 6배나 많습니다. 이러한 두 언어는 80퍼센트의 같은 BPE 구조를 보이고 있습니다. 그리하여 학습을 한 결과를 보면, 확실히 비슷한 구조를 가지고 학습을 하게 되면 매우 높은 성능을 보여줍니다. 네팔어와 힌디어는 비슷하고, 네팔어와 영어가 비슷하기에 마지막에 이를 추가하여 학습하니 가장 높은 성능을 보여주었습니다.
4.5 Unsupervised cross - lingual word embeddings
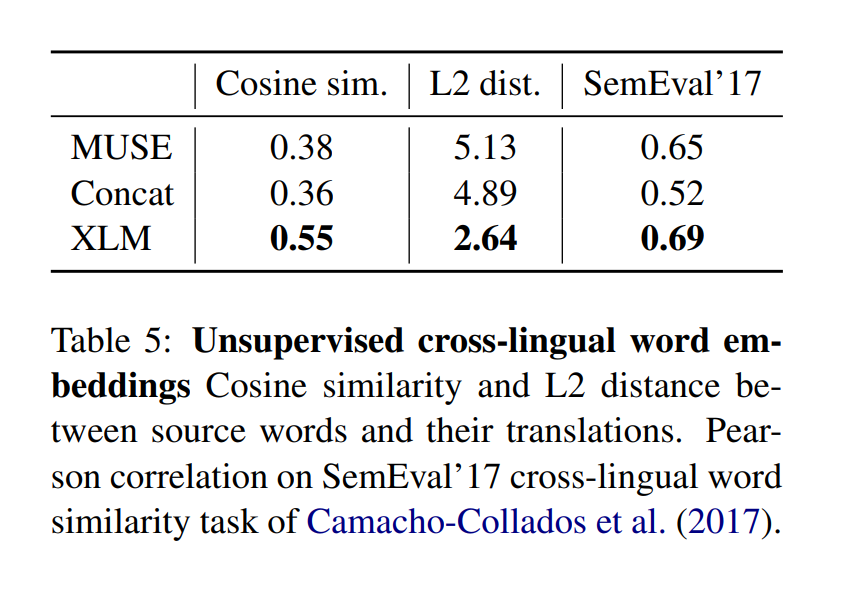
Conneua et al (2018a)에서는 단일 언어 워드 임베딩 스페이스를 align 하여 단어 번역을 어떻게 하는지 보여주었고, Lample et al (2018a)에서는 두 언어 사이의 shared vocab을 이용하여 fastText에 적용하는 과정을 보여주었습니다. 이 논문에서도 마찬가지로 shared vocab을 만들었지만 임베딩 방식이 XLM 방식으로 나왔기 때문에 저자는 위와 같은 3가지 방식을 코사인 유사도, L2 유사도, 그리고 언어 유사도를 이용하여 section 5에서 비교를 하였습니다. 확실히 XLM 구조가 더 높은 성능을 보여주었습니다.
5. Experiments and results
5.1 Training details
모든 구조는 Transformer를 사용, 1024개의 hidden unites, 8개의 head, GELU benchmark를 적용, dropout rate는 0.1로 구성하여 학습하였습니다. Adam 을 사용하고, linear warm up 방식솨 learning rate는 점점 줄어드는 구조를 활용하였습니다.
5.2 Data preprecessing
언어는 영어와 비슷한 언어를 활용하였고, WikiExtractor를 활용하여 부족한 위키피디아 정보를 뽑았습니다.
6. Conclusion
이 논문에서는 MLM와 CLM을 통해 cross - lingual 적인 학습 방법의 높은 퍼포먼스를 보여주었습니다. 그리고 BERT 방식을 따라한 MLM 방식은 굉장히 높은 성능을 보여주었고, 특히 당시 SOTA에도 도달할 수 있었습니다.
한 줄로 요약하면?
GPT와 BERT의 구조를 바탕으로 다양한 언어를 학습하여 더 높은 성능을 보일 수 있었고, 소수 언어를 살릴 수 있는 방법을 제안한 논문이다.
