[논문 리뷰] Deep contextualized word representations - ELMo(Embedding from Language Models)
자연어처리 논문 리뷰
Preface

Motivation
기존의 word representation 모델들은 Word2Vec와 Globe 들로, 단어를 벡터로 변환하는 데 사용하였습니다. 여기서 문제점은 단어의 맥락 판단이 전혀 불가능했다는 점입니다. 예를 들어, ‘bank’ 라는 단어는 은행이지만, ‘둑’ 이라는 뜻으로도 사용됩니다. 그리하여 이런 맥락적 차이를 표현할 수 없었을까? 라는 생각으로, ELMo는 양방향 학습을 통해서 맥락을 기반으로 한, 단어 표현 방법을 제안했습니다.

<우리 귀여운 엘모~>
1. Introduction
학습된 pre-trained 모델들은 neural language model의 성능을 높이는 데 큰 기여를 했습니다. one hot encoding 을 시작으로 ,Word2vec, Glove 등 다양한 방식으로 단어를 벡터로 변환하려고 했습니다. 하지만 이 모델들은 1. 단어들의 특성을 잘 살리지 못하거나, 2. 언어적 맥락을 반영하지 못하였습니다. 그리하여 위 저자는, 위 두 가지 방식을 통해서 SOTA를 달성하였고, word representation의 새로운 구조를 제안합니다.
End task 마다 input word 들을 stacked 하여 모델을 학습시키거나, biLM의 internal layer로 모델 구조를 구성합니다. ELMo는 실용적으로 모델 성능을 높이고, 6개의 분야에서 SOTA를 보여주었습니다.
2. Related Work
이전에 제안된 논문들은 단순히 단어들을 벡터로 변환하여, 문장 간의 맥락을 반영하지 못하였습니다. 그리하여 최근에 나온 논문들은 이전의 문제점을 개선하려고 했습니다. 1. ELMo는 subword 단어들로, 다양한 의미를 가진 정보들을 통합시키는 과정으로 큰 이점을 가지려고 했습니다. 2. 더불어, large dataset으로 학습하고, 단일 언어로 학습하여 큰 이점을 가지려고 했습니다. 3. 다운 스트림 테스크에 학습하기 좋습니다.
즉, ‘ELMo 이전에 나온 논문들이 가지는 모든 장점을 합쳐서 ELMo에 녹였다’라고 볼 수 있습니다!!
3. ELMo : Embeddings from Language Models
이전의 word representation 구조는 단어를 벡터로 변환하였지만, 저자가 제안한 ELMo는 전체의 input sentence를 넣는 구조입니다.
3.1 Bidirenctional Language models
모델 학습은 양방향 LSTM 구조로 forward 방향과 backward 방향으로 pretrained을 합니다.
forward 방식으로는 개의 토큰들로 구성된, 문장들을 lauguage model은 확률 계산을 통해, 다음 문장이 무엇이 나올 지에 대하여 확률을 계산합니다.
위 식은 들에 대한 값이 있을때, 의 확률의 곱들을 표현한 것으로, 여기서 제일 높은 값으로 pretrained을 합니다.
그 당시의 SOTA 신경망 모델은 문맥과 독립된 token representation 을 계산하는 것으로 이 값을 L개의 LSTM forward layer에 넘겨서 계산합니다. 각 마다, 각 LSTM은 문맥에 의존하는 를 만들어, 다음 당시의 값을 softmax를 이용하여 예측합니다.
Backward 방식으로는 forward 방식의 LM과 비슷합니다.
번째 문장을 예측하기 위해서 번째 문장을 시작으로 주어진 번째 문장들이 주어졌을 때의 가장 높은 확률을 계산하여 pretrained을 진행합니다. forward 방식과 비슷하게 LSTM j번째 layer를 가지고 를 만듭니다.
그리하여 biLM은 이를 구조화하여 학습을 진행하고 forward와 backward의 log likelihood를 최댓값으로 맞추려고 합니다.
여기서 는 token representation이고, 는 Softmax Layer를 의미합니다.
3.2 ELMo
ELMo는 biLM에서 중간 layer를 이용한 task specific combination입니다. 각 token 에서, L번째 biLM layer들은 representation을 계산하게 됩니다.
위 식에서 으로 위에 집합의 값들을 다 합친 표현으로 이해하면 된다.
ELMo에서는 에서의 모든 layer들을 single vector로 구성하여, 라고 적을 수 있습니다.
더 일반적으로는 모든 biLM layer들에서 가중치를 이용하여 적을 수도 있습니다.
여기서 는 softmax를 이용하여 가중치를 normalized 시킨 것이고, 는 ELMo 모델을 scaling 하는 역할 입니다. 는 최적화 과정에도 도움을 주고, layer normalization을 활용하여 모델 성능을 높이는 역할을 합니다.
3.3 Using biLMs for supervised NLP tasks
위 섹션에서는 모델 학습과 ELMo를 다운 테스크에 어떻게 적용하는 지를 설명하고 있습니다. 모델 학습은 굉장히 쉬운 구조로 되어 있습니다. 먼저, 대부분의 supervised NLP model들은 가장 아래 layer에서는 공통의 아키텍쳐를 공유하고 있습니다. 여기에 ELMo를 넣어 공통된 구조를 만드는 것입니다.
기존의 모델들은 이 주어졌을 때, 문맥과 독립적인 token을 표현한 을 만드는 것이 기본입니다. 그리고 모델은 context와 연관있는 를 만듭니다. 기존의 ELMo를 넣기 위해서, 다음과 같은 순서로 모델을 학습합니다.
- pretrained했던 biLM의 가중치를 고정한 뒤, ELMo vector에서 나온 를 와 합칩니다.
- 이를 RNN layer에 태워서 학습을 진행합니다.
위 논문에서는 L2 와 같은 Regularization을 통해서 모델 성능을 높일 수 있다고 합니다.
3.4 Pre-trained bidirectional language model architecture
위 논문은 다른 논문들과 다르게 bidirectional 학습 구조에 맞추어 학습을 하고, LSTM 사이에 residual connection을 추가했다는 점이다.
4. Evaluation
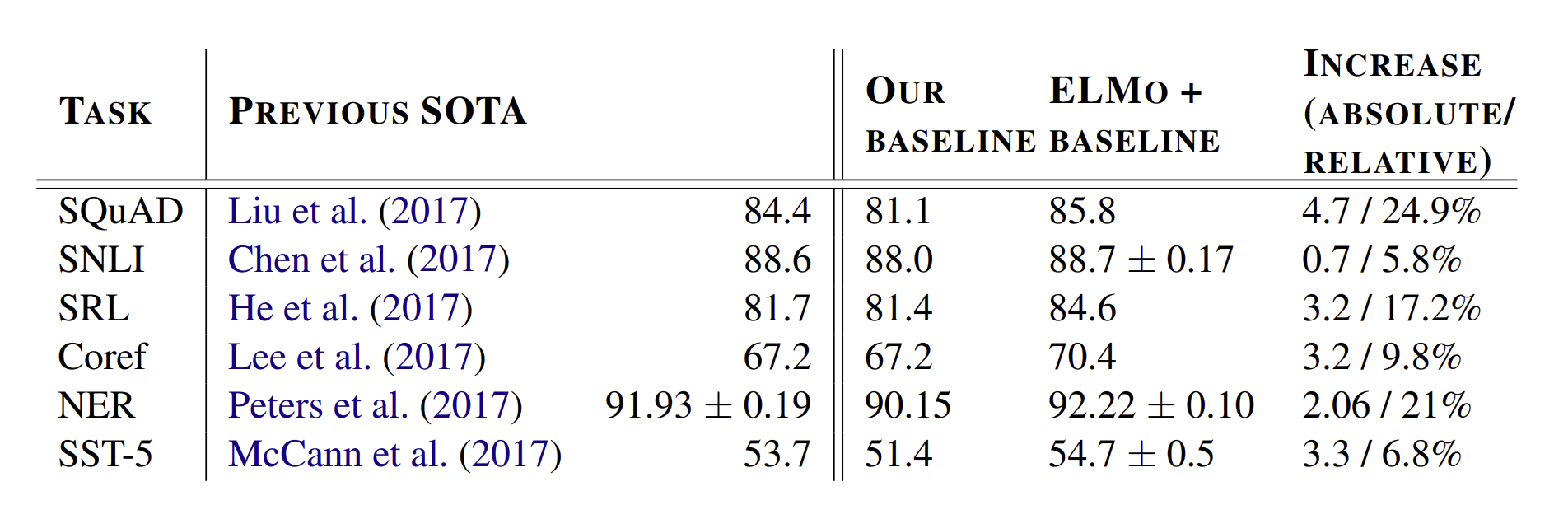
위 그림은 ELMo의 성능 결과표이다. 위에서 볼 수 있듯이, ELMo를 추가한 것만으로도 SOTA를 달성한 것을 볼 수 있다.
5. Analysis
5.1 Alternate layer weighting schemes
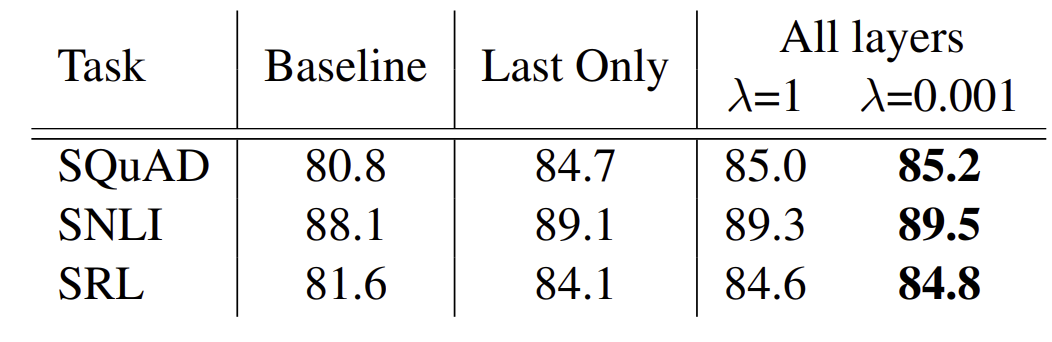
위 섹션은 가중치를 조절하는 를 어떻게 조정할 것인지에 대한 부분이다.
SQuAD, SNLI, SRL의 구조들을 비교하는 것으로, 기존의 구조들을 마지막의 layer 들에서 나온 값들만을 가지고 결과를 만드는 경우였다. 하지만 모든 layer의 representation 결과를 다 합쳐서 성능을 평가하는 것은 마지막 layer 만을 사용하는 것 보다 높은 결과를 보여주었다.
5.2 Where to include ELMo?
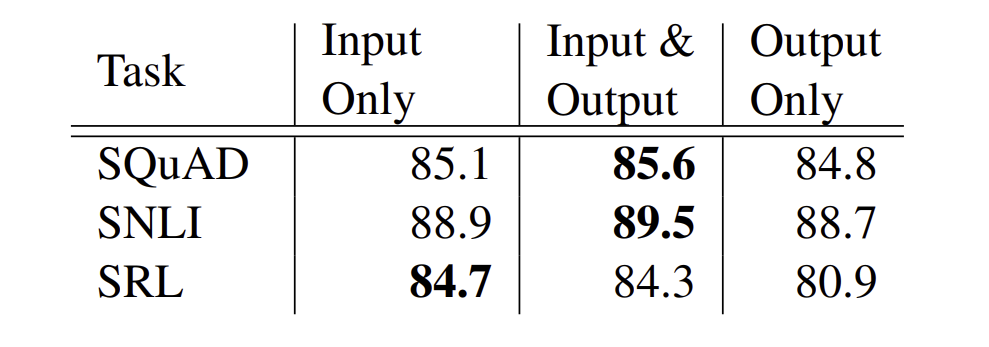 )
)
위 논문에서는 biRNN의 첫 layer에 ELMo를 넣었는데, 몇 테스크에는 마지막에 ELMo를 집어넣게 되면, 성능이 더 올라가는 것을 확인할 수 있었다고 한다. 예를 들어, SQuAD와 SNLI는 input과 output에 넣었을 때, 성능이 올라갔지만, SRL은 첫 부분에만 넣었을 때, 성능이 더 올라갔다고 한다.
이 결과에 대해서 위 저자는 SNLI와 SQuAD 구조는 어텐션 layer를 biRNN 이후에 사용했기 때문이라고 한다. 이는 모델이 biLM의 internal representation을 알아내기 쉽게 해줬다고 한다.
5.3 What information is captured by the biLM’s representations?

위 그림은 ELMo가 play는 축구나 운동에서 사용한 play, 연극에서 활용한 play로 구분할 수 있다는 점을 보여준다.
6. Conclusion
ELMo를 추가함으로써, 높은 성능을 보여주었으며, context 별로 syntactic 하고 semantic한 정보들을 encode할 수 있게 되면서 이는 성능을 향상시켰다.
한마디로 요약하면?
ELMo는 bidirection 방식으로 학습한 pretrained 모델을 이용하여 맥락을 고려하게 될 수 있는 구조를 만들었습니다.
