
Preface
이번 시간에는 전이학습이라고 불리는 transfer learning을 공부하고, transfer learning 방법 중 Inductive transfer이 NLP 분야에 어떻게 적용이 되었는지에 대해서 배워보겠습니다.
Motivation
Transfer learning의 주요한 문제점 중 하나는 catastrophic forgetting 입니다. Catastrophic forgetting은 기존에 pre-trained 했던 데이터 학습 이후, 새로운 데이터를 학습하는 과정에서 이전의 데이터를 잊어버리는 경우 입니다. NLP분야에서 fine tuning을 했을 때, Catastrophic forgetting 현상이 발생합니다. 그래서 이 문제를 어떻게 해결할 수 있을까? 라는 생각으로 위 논문에서는 새로운 방법 2가지를 제안하고 있습니다.
0. Transfer learning이란?
Transfer learning이란 한 분야의 정보를 다른 분야에 전이(transfer)시키는 학습 방법입니다. 앞에서 리뷰했던 Fine tuning은 Transfer learning의 포함관계로 사전에 학습된 모델을 특정 작업이나 데이터셋에 맞추어 추가적으로 학습시키는 것을 의미합니다. 그럼 이러한 관계를 자연어 모델에서는 어떻게 더 효율적으로 할 수 있을까요?
0.1 Inductive transfer vs transductive transfer
<Inductive transfer>
- Pre_training : unlabeled 된 데이터로 미리 언어에 대한 패턴 학습.
- Fine - tuning : 단순한 supervised learning과 같음.
<Transductive transfer>
- Pre-training : unlabeled 된 데이터로 미리 언어에 대한 패턴 학습.
- Application : 'train' 데이터셋에서 모델을 훈련시키고, unlabeled 한 'test' 데이터셋에 적용하여 이 데이터셋의 특정한 구조나 패턴을 바탕으로 예측을 수행. 모델이 'test' 데이터셋을 보고 특정 패턴을 학습하고, 이 데이터셋에 대한 성능 최적화에 집중한다. (ex → zero shot learning)
1. Introduction
기존에는 CV(Computer Vision) 분야에서 transfer learning은 다양한 task(Text classification)를 수행하기 위해 사용되었습니다. 당시 SOTA를 달성하던 많은 자연어처리 모델은 기존의 train 데이터 만을 가지고 처음부터(scratch) 학습을 진행했습니다. 그리고 위 자연어처리 모델에서 많이 사용하는 Word Embedding과 같은 방식은 굉장히 큰 호평을 받을 수 있었습니다. 이러한 Inductive transfer 방식은 굉장히 호평을 받았지만 그 당시의 학습 방법은 Transductive transfer이었습니다. 특히, CV 분야와는 다른 NLP 분야에서 CV 방식의 fine tuning(Inductive transfer)은 NLP 데이터에 잘 맞지도 않았으며, catastrophic forgetting을 일으키기도 하였습니다.
그리하여 위 논문에서는 catastrophic forgetting을 해결할 수 있는 Universal Language Model Fine-tuning(ULMFiT)을 제안합니다.
- ULMFiT를 제안함.
- 이전의 지식을 유지하고 catastrophic forgetting 문제를 해결하는 방법에 대해서 제안함.
- classification 분야에서 SOTA를 달성.
2. Related Works
Transfer learning in CV
CV에서 기존의 Transfer learning 방식은 일반적인 task에서 어떤 specific task로 변경해주는 작업이었습니다. 최근에는 Fine tuning 의 방식이 선호되거나 pre-trained된 마지막 layer들을 바꿔주기도 합니다.
Hypercolumns
NLP 분야에서 transfer learning인 Word Embedding으로 학습을 진행합니다. Hypercolumns은 다른 임베딩 벡터들과 데이터를 붙이거나, 중간 layer의 input을 붙여서 방식을 의미합니다. 이는 CV에서 나온 것으로, 최근에는 Fine - tuning에게 밀리게 됩니다.
3. Universal Language Model Fine - tuning
저자는 large general - domain corpus를 이용하여 Pre-trained 시키고, 새로운 방식으로 fine-tuning을 시키는 Universal Language Model Fine, ULMFiT을 제안합니다.
먼저 4가지의 조건을 만족한 상태로 학습을 시킵니다.
<조건>
- 문서의 크기, 수, 라벨 유형에 관계없이 다양한 작업에서 작동합니다.
- 단일 구조와 훈련 과정을 사용합니다.
- 맞춤형 특징 엔지니어링이나 전처리 과정이 필요하지 않습니다.
- 추가적인 도메인 내 문서나 라벨이 필요하지 않습니다.
이들은 즉 다양한 NLP task 에서 사용될 수 있음을 내포합니다.
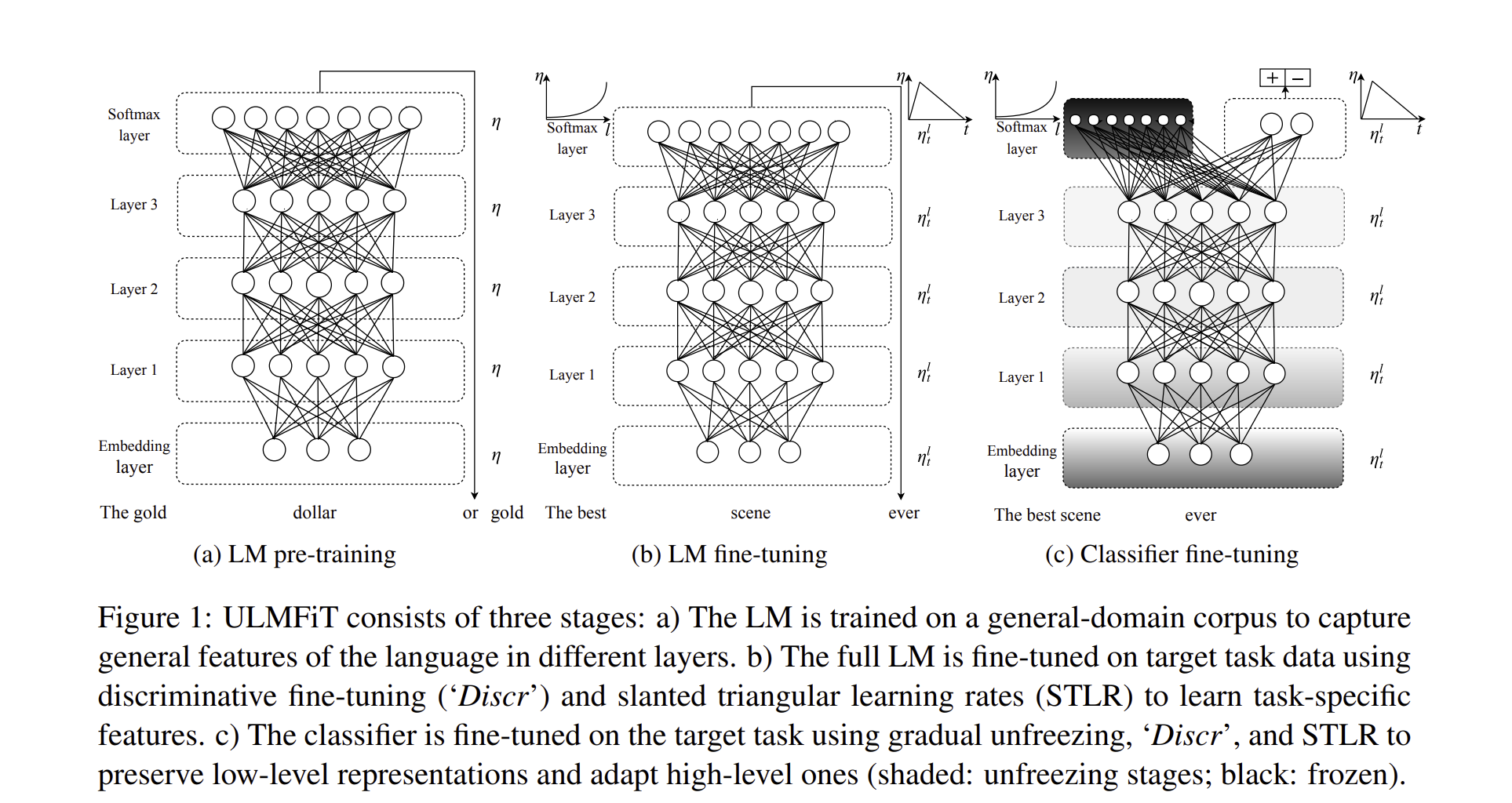
ULMFiT는 3가지의 모델로 구성되어 있으며, 첫 번째는 General - domain LM, 두 번째는 target task LM fine tuning, 세 번째는 target task classifier fine-tuning 으로 구성되어 있습니다. ****
3.1 General - domain LM pretraining
위 모델 General - domain LM은 Wikitext-103 파일로 학습을 진행하였습니다. 이 단계에서는 대규모의 일반 텍스트 데이터셋을 사용하여 언어 모델을 사전학습합니다. 목표는 모델이 언어의 일반적인 구조와 패턴을 학습하는 것입니다.
3.2 Target task LM fine-tuning
3.1에서 학습했던 data의 분야가 무엇이든 간에, target task의 분야는 달라도 됩니다. 기존의 LM 데이터로 학습을 해놓았기 때문에, target task 분야의 학습은 굉장히 빨라지며, 특히 특이한 점(idiosyncraises)를 학습하기 좋습니다. 이 단계에서는 특정 도메인 또는 작업과 관련된 텍스트 데이터셋을 사용하여 사전학습된 언어 모델을 미세조정합니다. 이렇게 하면 모델이 특정 도메인의 언어적 특성을 더 잘 이해하게 됩니다.
위 논문에서는 target task에 학습하는 2가지의 방식을 제안합니다. 과 제안합니다.
Discriminative fine - tuning
Discriminative fine - tuning 방식은 fine - tuning을 진행할 때, 각 layer 마다 다른 learning rate를 부여하는 것입니다. 원래 다른 분야를 학습할 때는 다른 종류의 데이터를 사용합니다.
위 논문에서는 SGD 방식을 예로 들어, 와 같은 방식에서 에 같은 값을 두는 것이 아닌 각각의 다른 값을 제안하여 학습을 진행합니다.
그리하여 값을 각 layer에 맞게 나누고, 학습률인 값을 얻을 수 있습니다.
Slanted triangular learning rates
각 모델마다 같은 learning rates를 사용하는 건 비효율적이기에, 을 제안합니다. 이 방식은 처음에는 선형적으로 학습률을 증가시키다가, 점차 감소시키는 방식으로,
위와 같이 써집니다. 여기서 는 iteration number, 은 learning rate를 증가시키는 부분, 은 learning rate를 증가시키다가 감소시키는 횟수, 는 learning rate를 각각 증가시켰다가 감소시키는 부분, 는 가장 작은 LR이 가장 큰 LR보다 얼마나 작은지에 대한 비율
위 논문에서는 로 사용을 하였다.
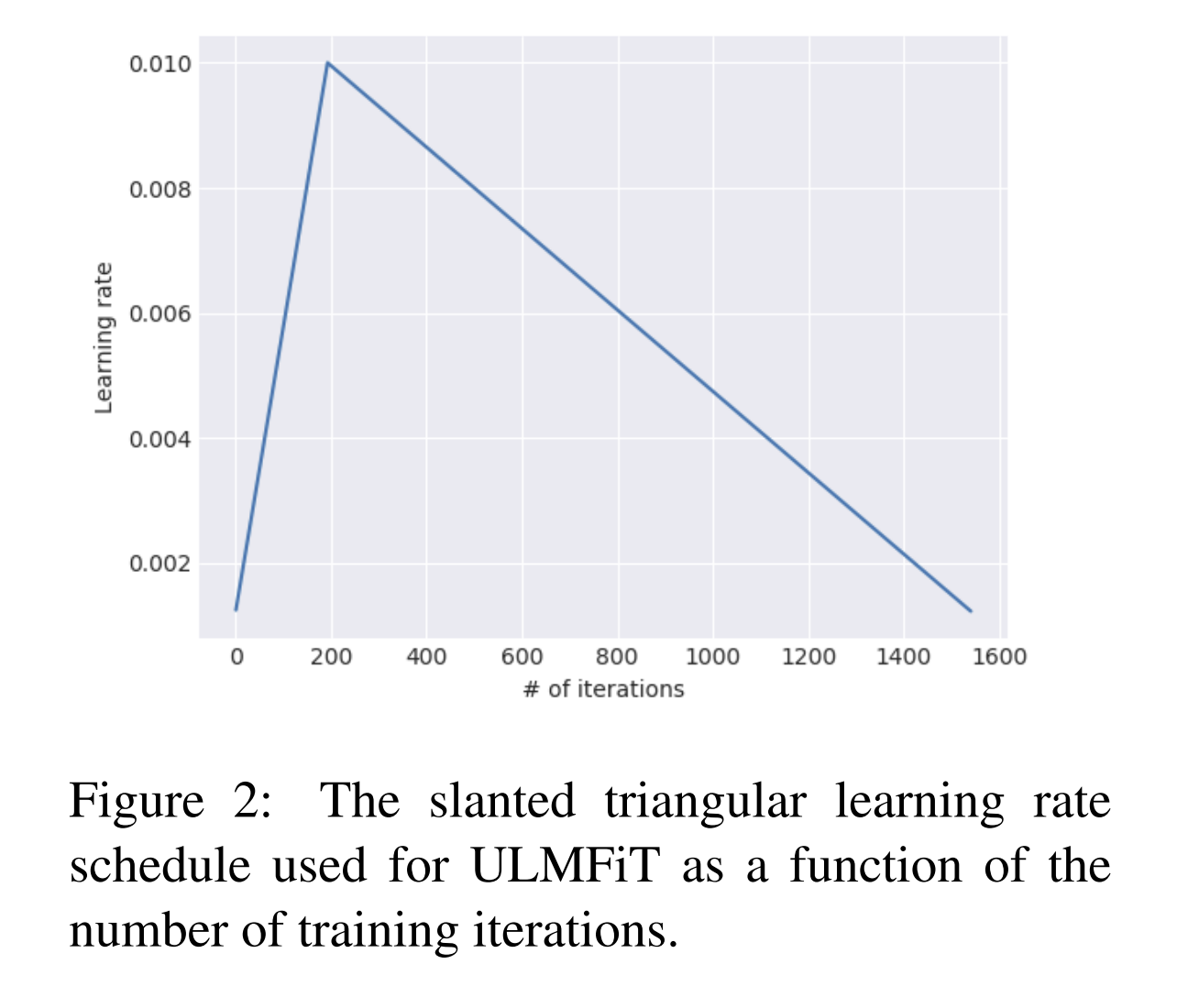
논문에서도 보이듯, STLR 값은 처음엔 증가했다가 iteration이 증가하면서 점차 감소됨을 알 수 있다.
3.3 Target task classifier fine - tuning
최종적으로, batch normalize와 dropout 하는 block을 2개 추가하고, 학습을 진행하였다. 마지막 단계에서는 동일한 도메인의 데이터를 사용하여 특정 작업(예: 감정 분석, 텍스트 분류)을 수행하기 위한 분류기를 학습합니다. 이때, 언어 모델의 최상위 레이어에 분류에 필요한 추가 레이어를 추가하고, 전체 모델을 특정 작업에 맞게 미세조정합니다.
Concat pooling
text classification에서는 signal이 중요합니다. 각각 분류를 할 때, 결정적으로 판단하는 signal들을 잘 찾아 분류를 하는게 일반적입니다. input 데이터의 양이 너무 많아 마지막 hidden state 만으로 판단을 하게 되면, information를 잃어버릴 수 있습니다.
이러한 이유로, last hidden layer와 전체 hidden layer의 maxpool과 meanpool을 넣어서 concatenate 해버립니다.
aggressive한 fine tuning 방식은 catastrophic을 일으킬 수도 있고, too cautious fine - tuning은 학습속도가 낮을 수 있기에 위 논문에서는 분류 모델을 위한 Gradual unfreezing 방식을 제안합니다.
Gradual unfreezing
원래 fine - tuning 할 때는, 순전파로 layer를 학습한 뒤에, 역전파 과정에서 가중치를 한번에 업데이트 합니다. 이는 catastrophic forgetting을 야기하는 경우가 있는데, 위 논문에서는 가장 마지막 layer 부터 가동을 하여(unfreeze) 가장 작은 정보가 있는 layer를 먼저 학습시키고, 그 앞 layer를 점점 학습시키면서(unfreeze) 이를 반복합니다.
BPTT for text Classification(BPT3C)
LM에서 역전파 과정을 진행하기 위해서는 BPTT(BackPropagation Through Time) 을 진행합니다. (위 모델은 Transformer가 아닌 LSTM으로 학습을 진행하였습니다.) 위 논문에서는 text Classification을 위한 BPT3C를 제안합니다.
Batch를 fixed_size b로 나누고 각 batch 별로, 학습을 할때 이전 batch size에서 사용했던 마지막 state를 사용하여 학습합니다.
Bidirectional language model
Fine tuning 모델 시, bidirectional language model을 고려하여 학습을 진행하였다.
4. Experiments
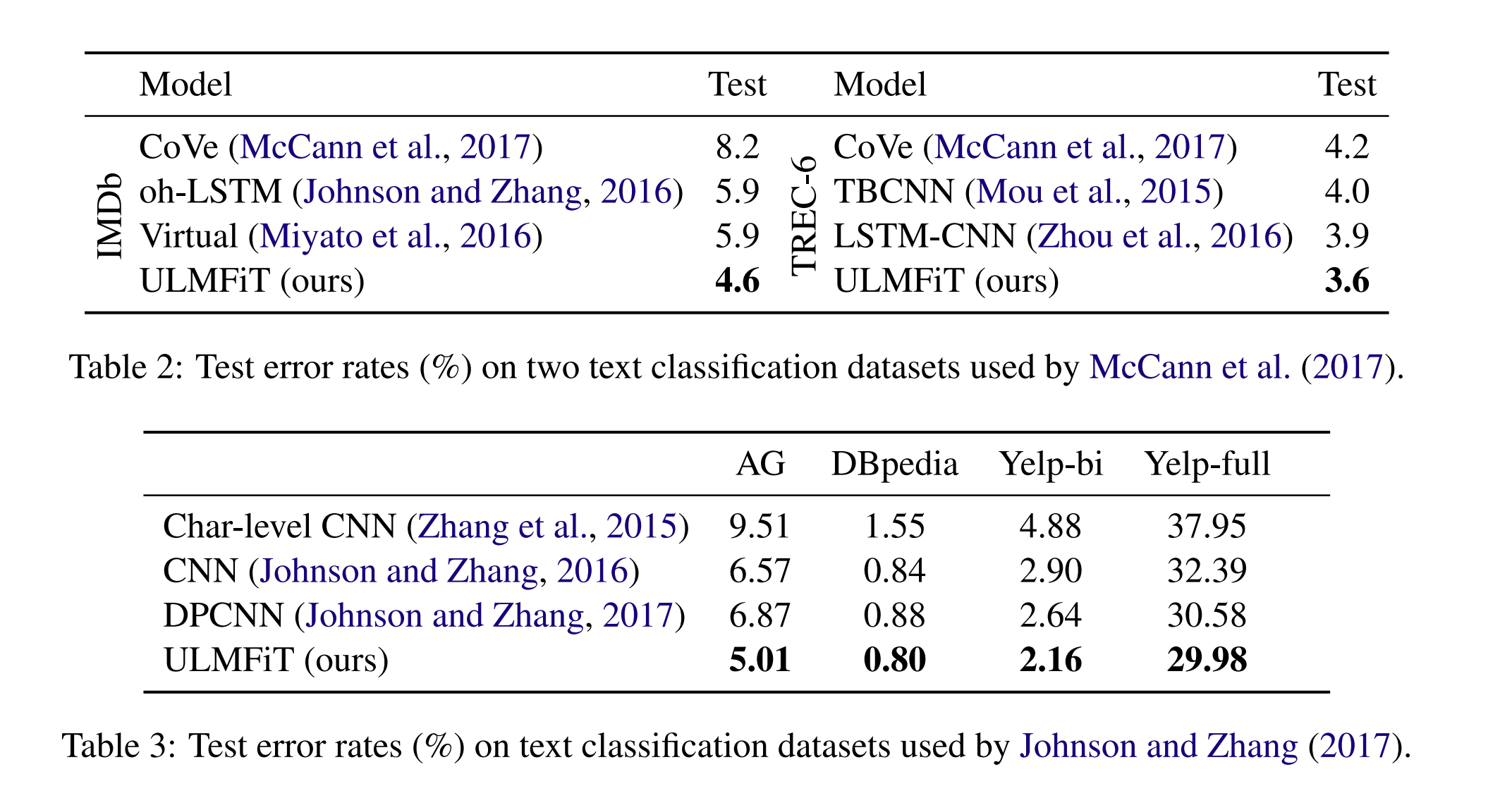
위와 같은 데이터를 사용하고, Model을 통해 당시의 SOTA 논문들 보다 높은 성능을 보임을 입증하였습니다. 복잡한 모델을 사용하기 보다는 단순한 LSTM 모델을 활용하여 높은 성능을 보였다는 점이 좀 놀라웠다.
5. Analysis
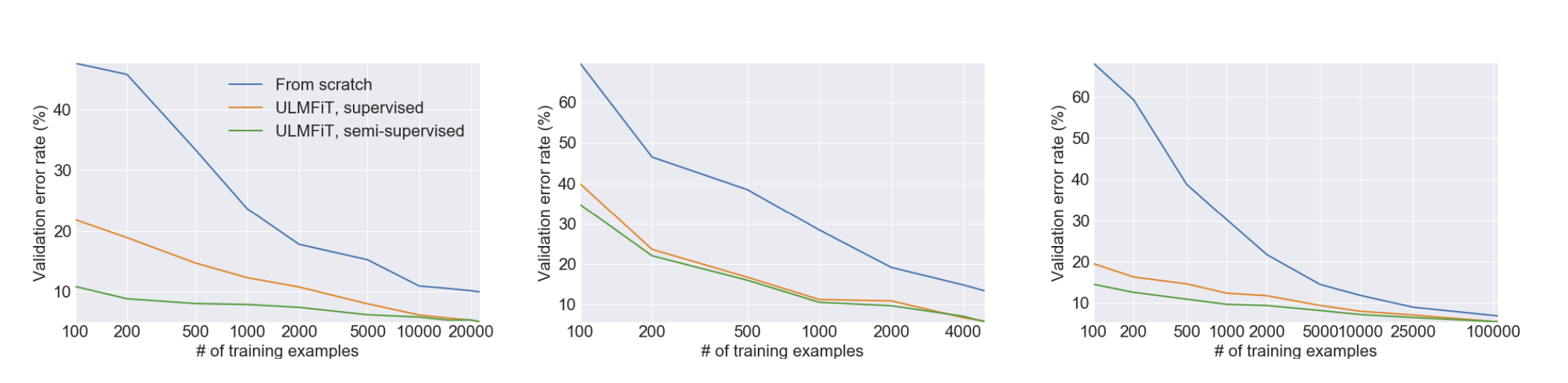
위 논문에서는 IMDb, TREC-6, AG를 train data 셋으로 사용, 50 epoch로 학습, train set에서 10퍼센트를 빼놓아 validation data으로 사용하였다.
Low - shot learning
pretrained의 장점은 label이 적은 데이터를 transfer learning을 통해 높은 성능을 보여주는 것이다.
IMDb와 AG 데이터셋에서 ULMFiT는 단 100개의 레이블 예제만 사용하여도 스크래치에서 10배 또는 20배 더 많은 데이터로 훈련하는 것과 유사한 성능을 보여준다.
TREC-6 데이터셋에서는 ULMFiT가 스크래치에서 훈련하는 것보다 크게 개선되었습니다. 이 데이터셋의 예제가 더 짧고 적기 때문에, supervised와 semi-supervised ULMFiT 모두 비슷한 결과를 달성한다.
즉, 이 부분은 ULMFiT가 fine tuning 하는 과정에서 소량의 레이블 데이터를 사용하는 low-shot learning 상황에서도 높은 성능을 보여주며, 이는 사전 훈련된 언어 모델의 강점을 활용하는 데서 비롯된다는 점을 강조하고 있습니다.
Impact of Pretraining
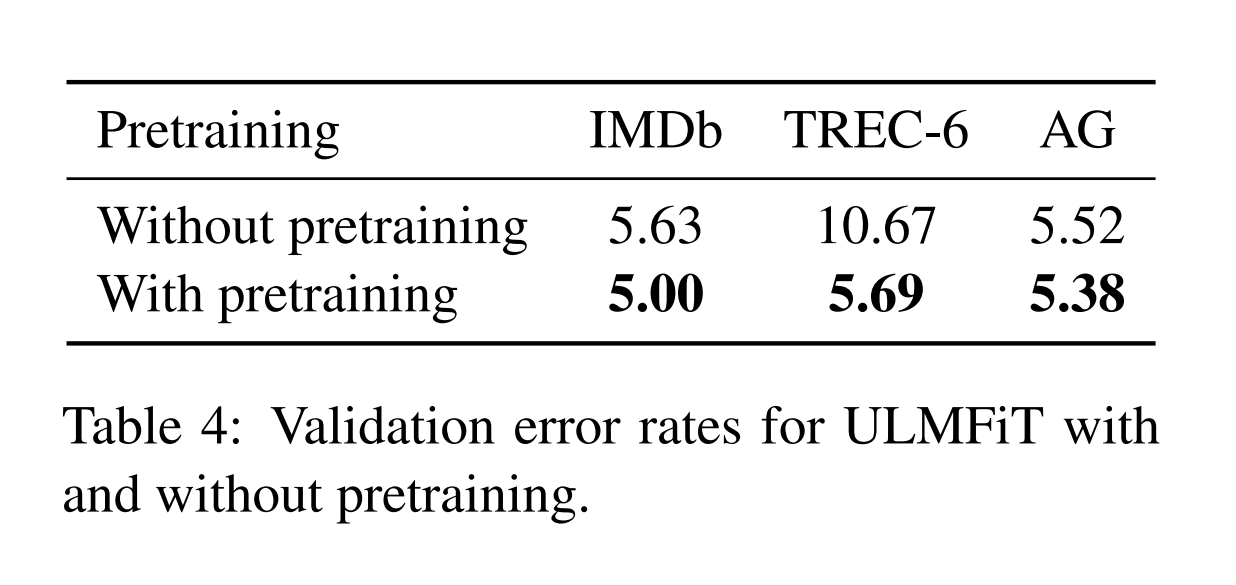
위 표는 fine tuning의 유무로 나뉠 수 있으며, fine tuning을 하는게 모델 성능이 더 좋아짐을 보여준다.
Impact of LM quality
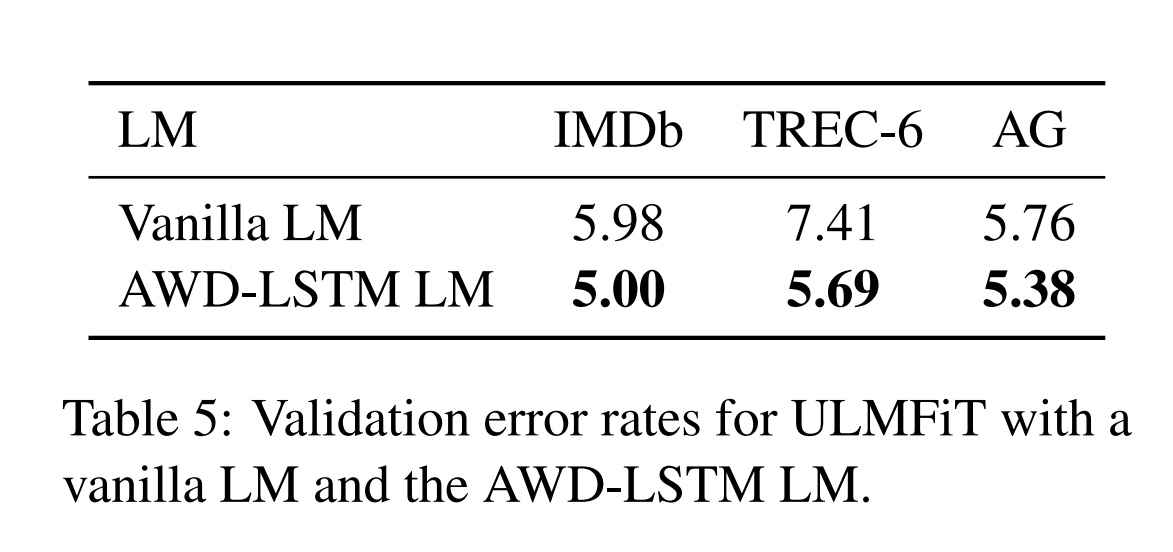
Vanlia LM은 fine tuning시, dropout을 설정하냐 마냐에 따른 성능 차이를 보여준다. Vanlia LM은 dropout이 없고, AWD-LSTM LM은 dropout을 설정하여 높은 성능을 보여준다.
Impact of LM fine-tuning
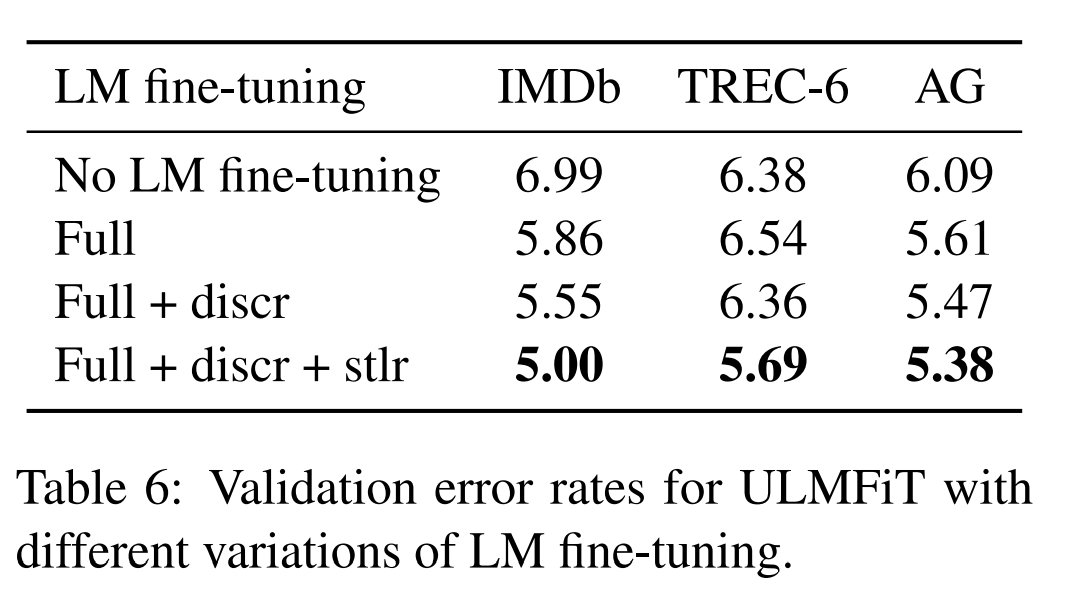
위 논문에서 제안하는 2가지 방식 Discr와 Stlr을 적용했을 때, 모델 성능이 더 좋음을 보여주었다.
Impact of classifier fine - tuning
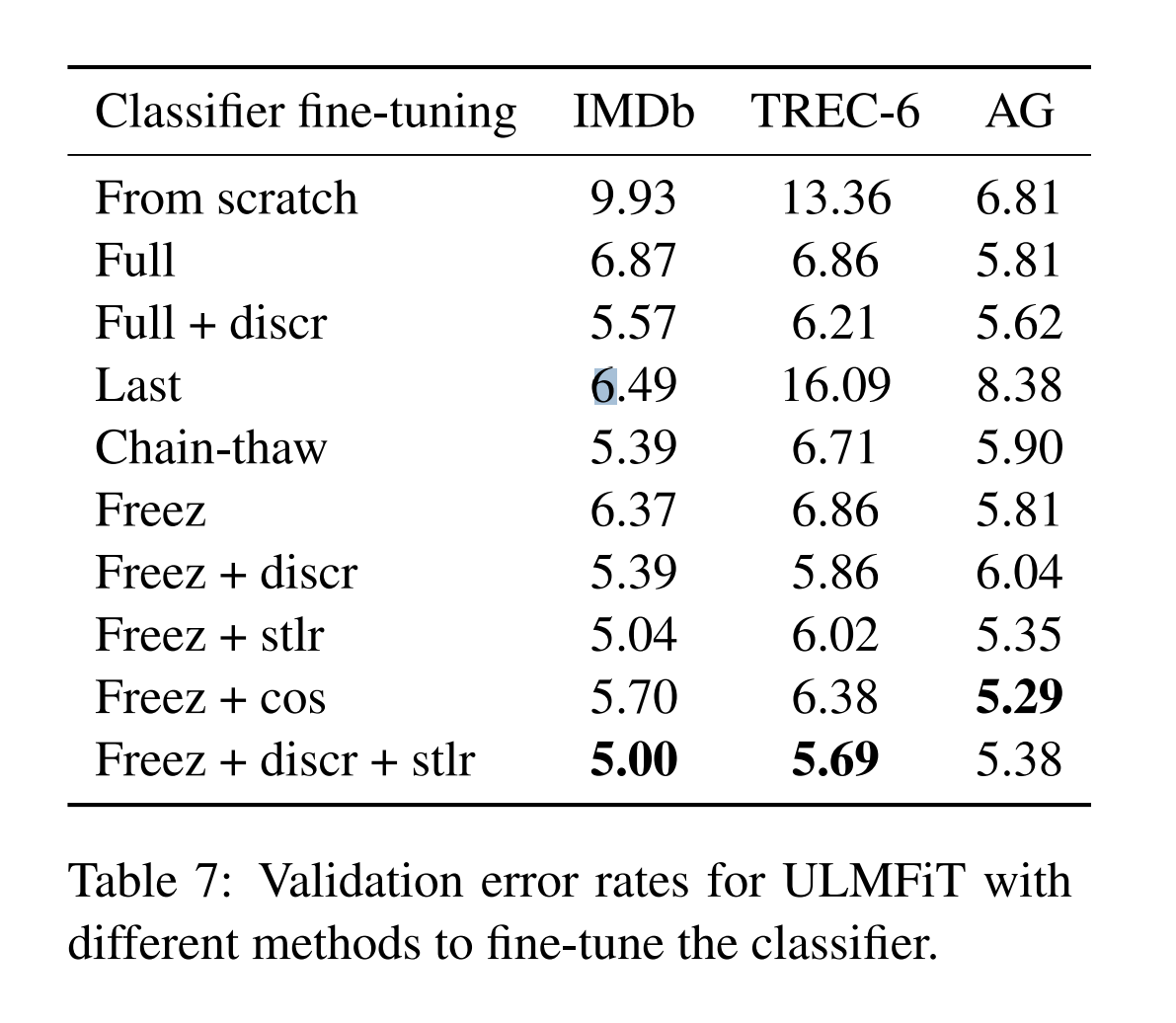
더불어 3번째 과정인 LM Fine tuning 과정에서 적용할 수 있는 방식인 Freeze를 적용했을 때, 모델 성능이 좋음을 보여줄 수 있다.
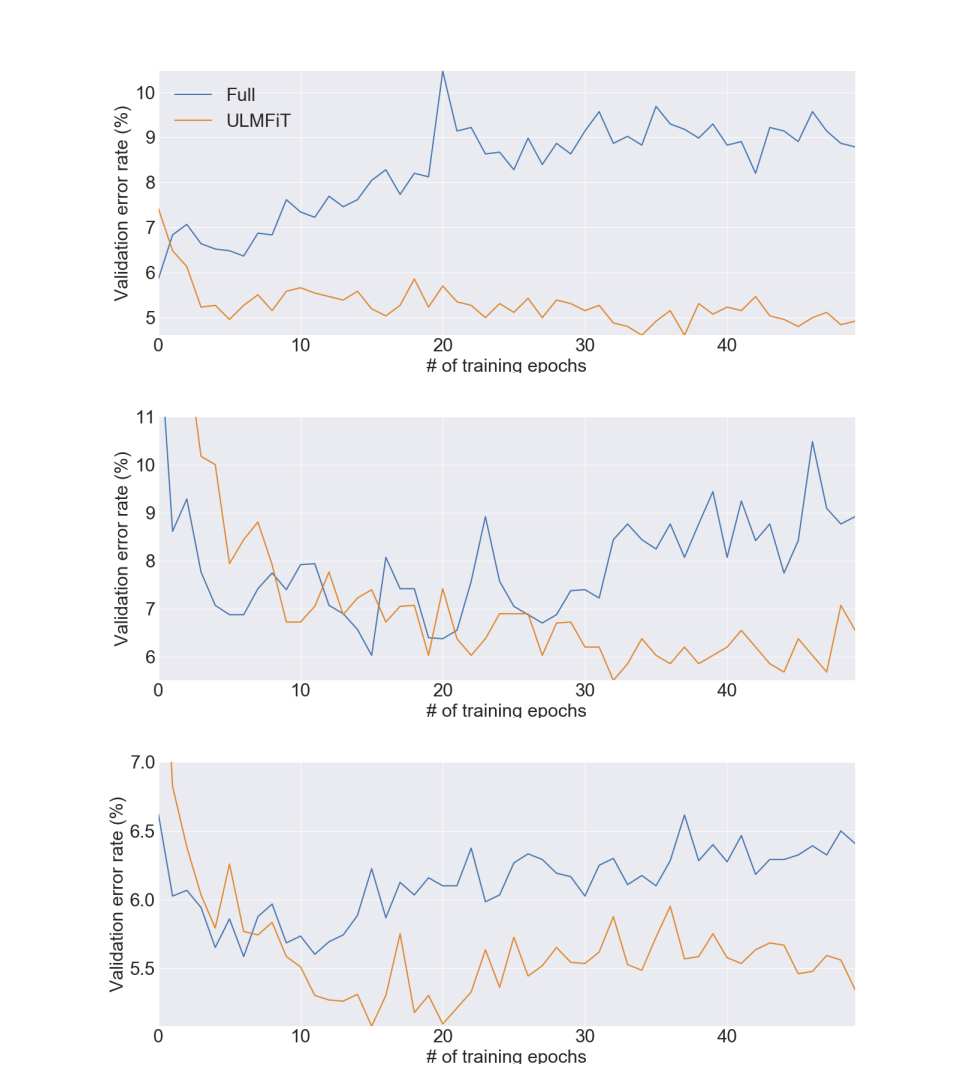
이는 모델 학습 과정을 보여준 것으로 Full은 one epoch 만에 over fitting이 발생하는 것을 볼 수 있는 반면, ULMFiT 모델은 overfitting이 아닌 적절한 학습 상황을 보여주고 있다.
7. Conclusion
위 논문에서는 어느 nlp task에도 ULMFiT를 적용할 수 있음을 보여주었고, transfer learning의 고질적인 문제 catastrophic forgetting을 해결하고, 학습 과정에서 robust 함을 보여주게 되었다.
한 줄로 요약을 하면?
catastrophic forgetting 문제를 해결하기 위해, learning rate를 layer마다 따로 설정하고 Slanted triangular learning rates로 learning rate를 조절했으며 gradual unfreezing으로 마지막 layer부터 시작하여 layer를 녹여 fine-tuning을 했다.
