[논문 리뷰]Effective Approaches to Attention-based Neural Machine Translation - Luong Attention
자연어처리 논문 리뷰
Preface
저번 시간에는 attention 기법을 통해 NMT에서 단어의 중요도를 알고, 이를 바탕으로 모델 학습을 하여 긴 문장에도 학습이 잘 된 경우를 보았습니다. 이번 시간에는 이런 Attention 기법을 어떻게 효율적으로 이용할 수 있는지에 대해서 배워봅시다.
Abstract
위 논문에서는 어텐션 기법이 가지는 문제점에 대해서 이야기하고, 이를 어떻게 하면 효율적으로 이용할 수 있는지에 대한 논문입니다. 문장 전체에 대해서 단어의 중요도를 판단하는 Global 방식과 한 번에 어떤 집단만을 보고 판단하는 local 방식에 대해서 이야기하고 있습니다. 두 방법 모두 논문이 나온 기준으로 State-of-the-art를 달성하였습니다.

1. Introduction
문장의 끝까지 읽어 단어의 중요도를 판단하는 어텐션 기법은 발전되었습니다. 위 논문에서는 이 어텐션 기법을 더 가볍고, 효율적인 방식으로 다루는 방법 2가지를 만들었습니다.
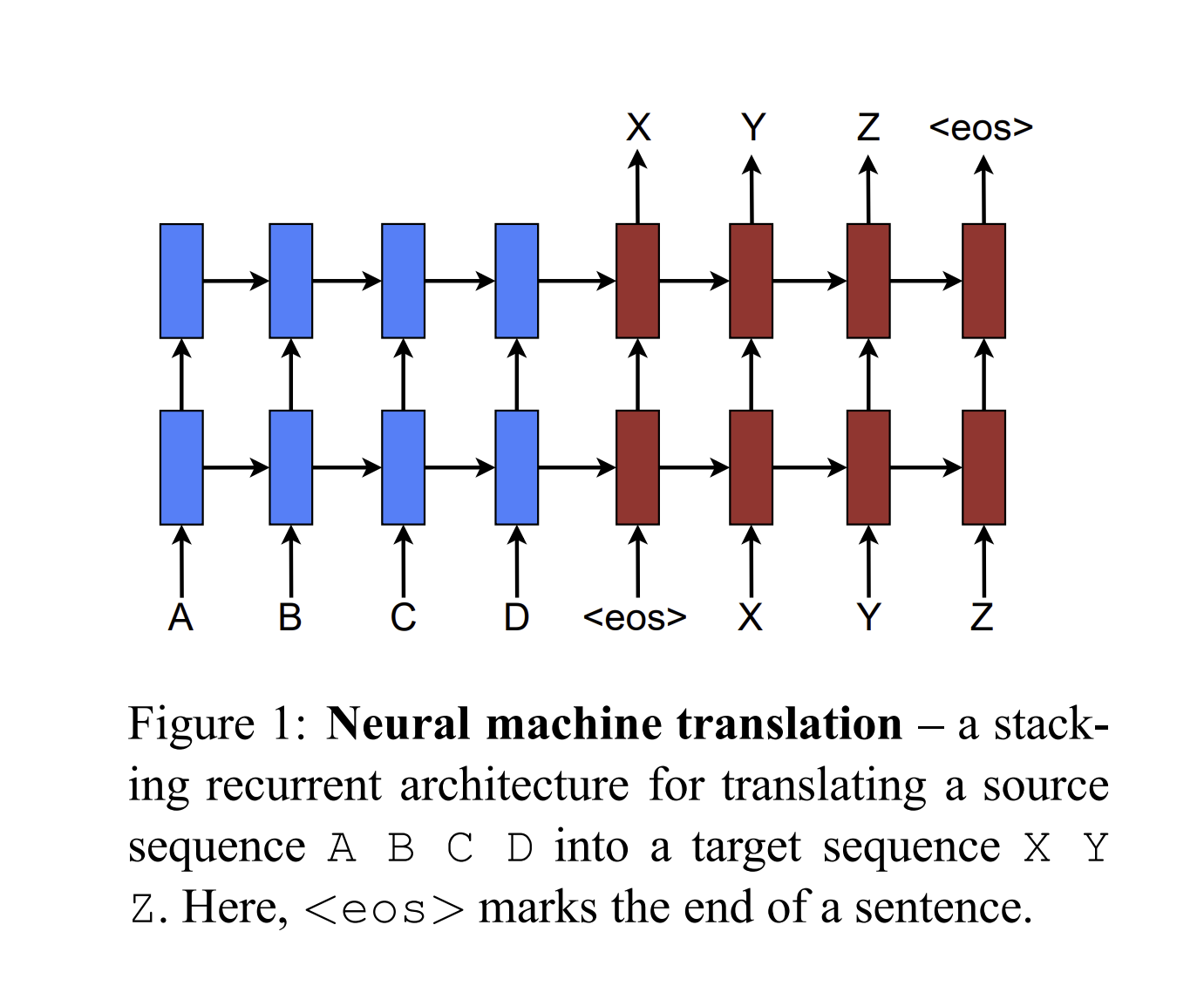
첫 번째는 Global 방식으로 모든 단어를 고려하는 모델, 두 번째는 local 방식으로 한 번에 한 집단의 단어무리들을 고려하는 모델 입니다. 두 번째 방식은 첫 번째 방식보다 가볍고, 모델을 돌리기 쉽습니다. 그리고 사용하는 함수가 미분이 가능하여, 역전파 계산해도 굉장히 효율적입니다.
3. Attention -based Model
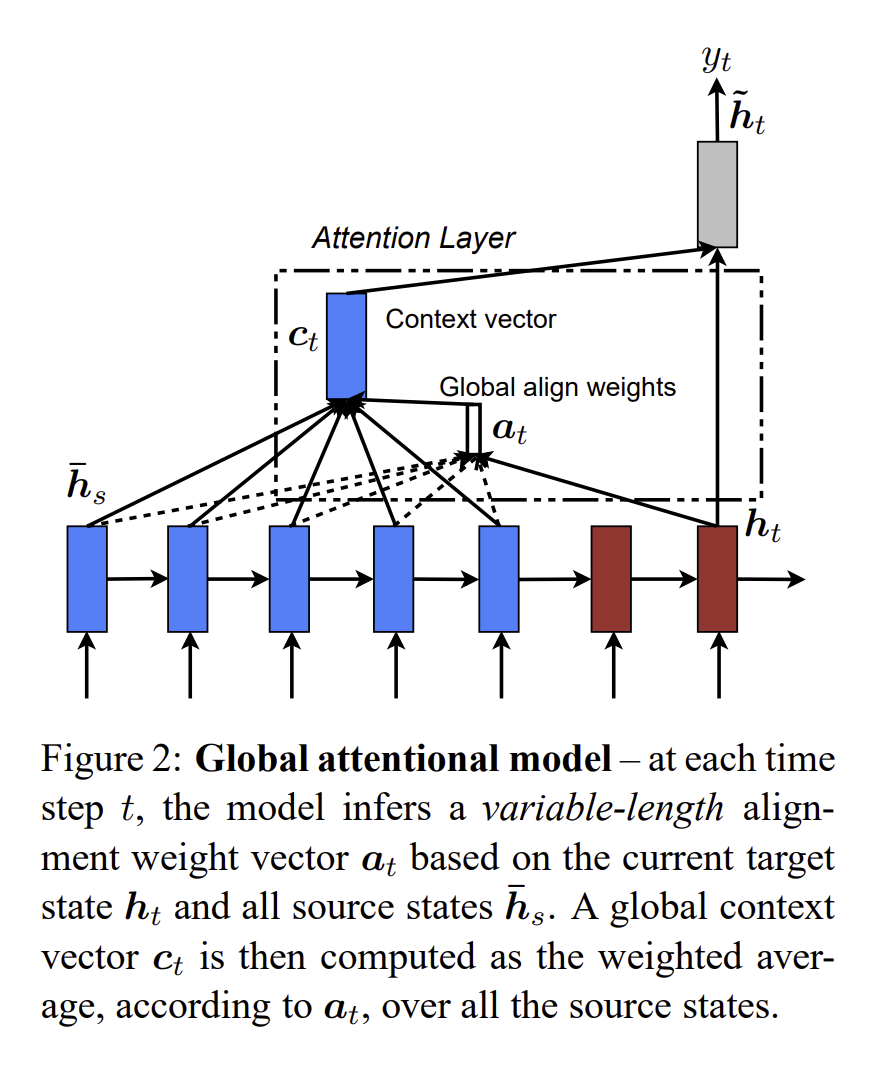
앞에서 언급한 두 모델 전부 디코딩을 하는 때, Attention layer에 hidden state를 넣어 중요한 단어를 알려주는 맥락인 context vector 를 뽑아내는 것 입니다.
식은 로 일때의 hidden state 와 context vector 를 계산하고, 이를 가중치 행렬 에 곱하여 tanh를 태워 attention vector 를 계산하게 됩니다. 그 이후 softmax 함수를 태워 어텐션 행렬을 만들게 됩니다.
아래에서는 context vector를 어떻게 만들었는지를 알아보겠습니다.
3.1 Global Attention
이 어텐션 기법의 핵심적인 방법은 RNN에서 나온 hidden state 모든 것을 고려하는 것 입니다. 특히 variable - length alignment vector인 은 현재의 hidden state인 와 를 고려하여 일때의 값을 확인할 수 있습니다.
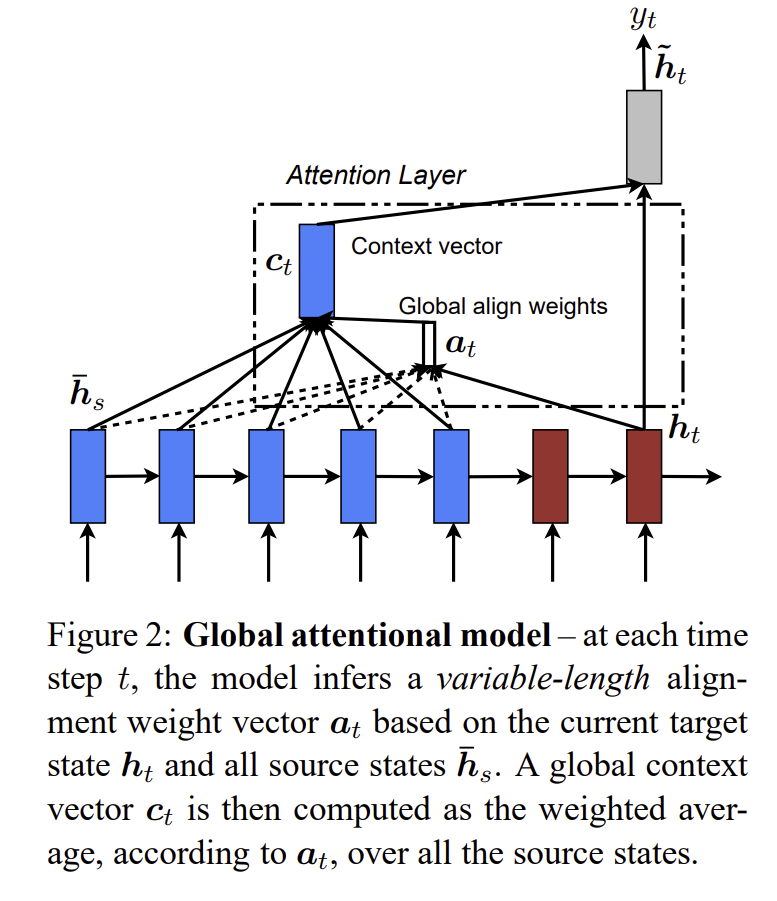
이는 t값을 계산할 때, RNN Layer를 타고 온 hidden state 를 통해서 attention 값을 구하고, 앞 논문에서 언급한 것처럼, hidden state와 이를 가중합을 하여 를 구하게 됩니다.
앞에서 설명한 논문 Bahdanau Attention 과 다른 점은
- Encoder와 Decoder에서 Layer 타고온 한 방향의 hidden state만 사용하지만, Bahdanau attention은 두 방향에 대한 모든 값들을 사용한다는 점.
- 계산과정이 더 단순하다는 점 입니다.
3.2 Local Attention
Global Attention은 모든 단어에 대한 attention 값을 계산하기에 굉장히 비효율적이다. 그래서 위 논문에서는 Local Attention을 제안하여, target 단어의 부분 집합을 계산하여 attention을 계산하겠다는 점입니다.
논문에서는 영감을 얻은 Xu et al(2015)의 soft attention 과 hard attention의 trade-off를 설명하고 있습니다. soft attention은 Global attention과 같이 모든 단어에 집중하여 계산하는 것이고, hard attention은 한 번에 한 개씩의 단어에만 집중하여 계산하는 것입니다. 여기 hard attention은 계산도 느리고, 미분도 불가능합니다.
그리하여 위 논문은 선택적으로 중요한 단어에 집중하여 미분이 가능하게 만드는 것입니다.
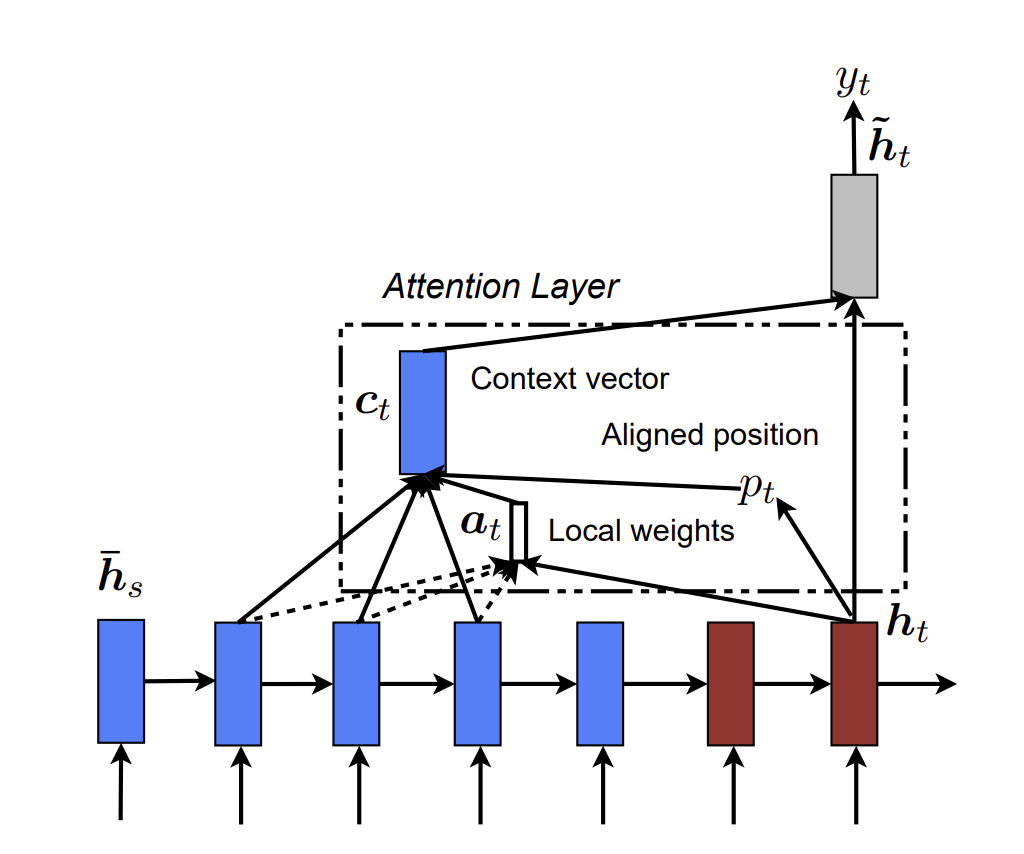
를 가장 잘 표현할 위치인 aligned position 를 구하여 임의의 D에 의하여 구간으로 어텐션을 구하게 됩니다.
저자는 를 구하는 과정에서 2가지 방법을 제안하였는데
첫번째로, Monotonic alignment(local-m) 의 방식으로, = t 라고 설정하여, Global attention과 비슷하게 설정한다.
두번째로, Predictive alignment(local-p)의 방식으로,
여기서 와 는 모델이 알아서 학습할 변수, S는 문장의 길이로 설정하여 를 의 범위로 할당하고, 이를 가우시안 분포에 넣어 최적의 위치로 선정될 수 있게 어텐션 값을 구합니다.
3.3 Input - feeding Approach
MT(Machine translation)에서는 데이터를 학습할 때, 각 문장의 번역 정보를 잘 유지가 되어야 합니다. 그리하여 위 논문에서는 과거의 정보를 잘 학습하기 위해서 를 다음 스탭의 단어와 합쳐서 학습을 시킵니다. 이렇게 하면, 과거의 번역을 하면서 배웠던 순서나 성질에 대해서 더 잘 학습할 수 있게 됩니다.
이전의 방식과 차이가 뭐나면, 각각의 단어에 집중할지 결정하는 주의가 독립적으로 이루어지는 반면, 위 input-feeding approach에서는
- 한 단계의 주의 메커니즘 출력을 다음 단계의 입력을 고려하게 하여, 모델이 현재 상태와 원본 입력뿐만 아니라 이전에 이루어진 주의 선택도 고려하게 만들 수 있게 합니다.
- 수평적으로 수직적으로 깊은 네트워크를 형성하는 것입니다.
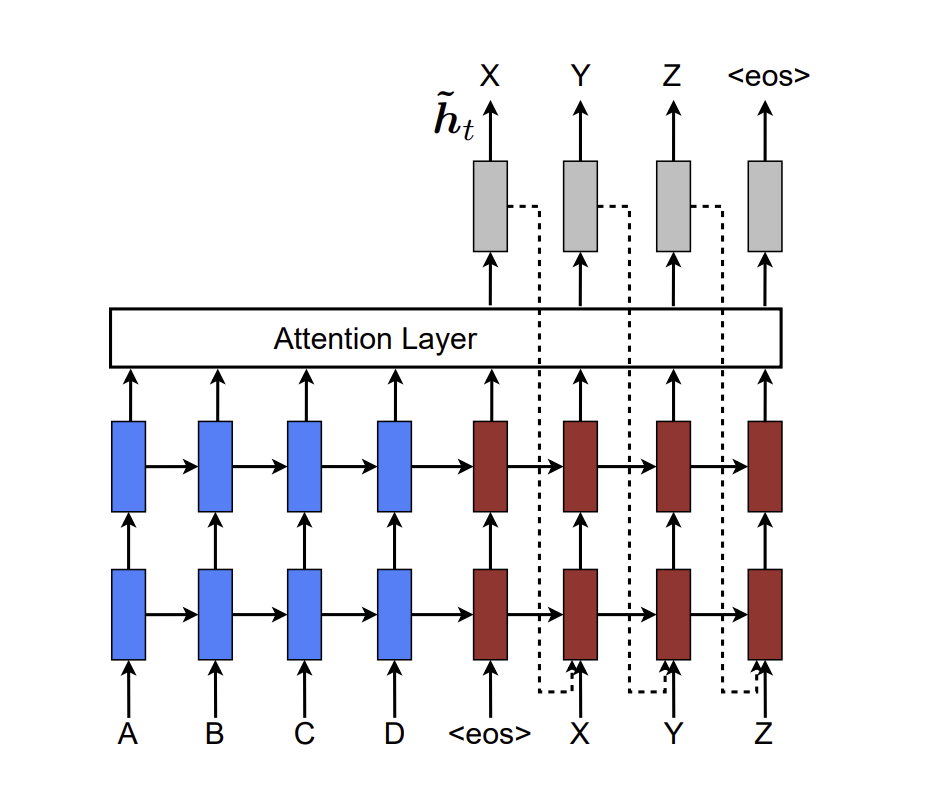
4. Experiment
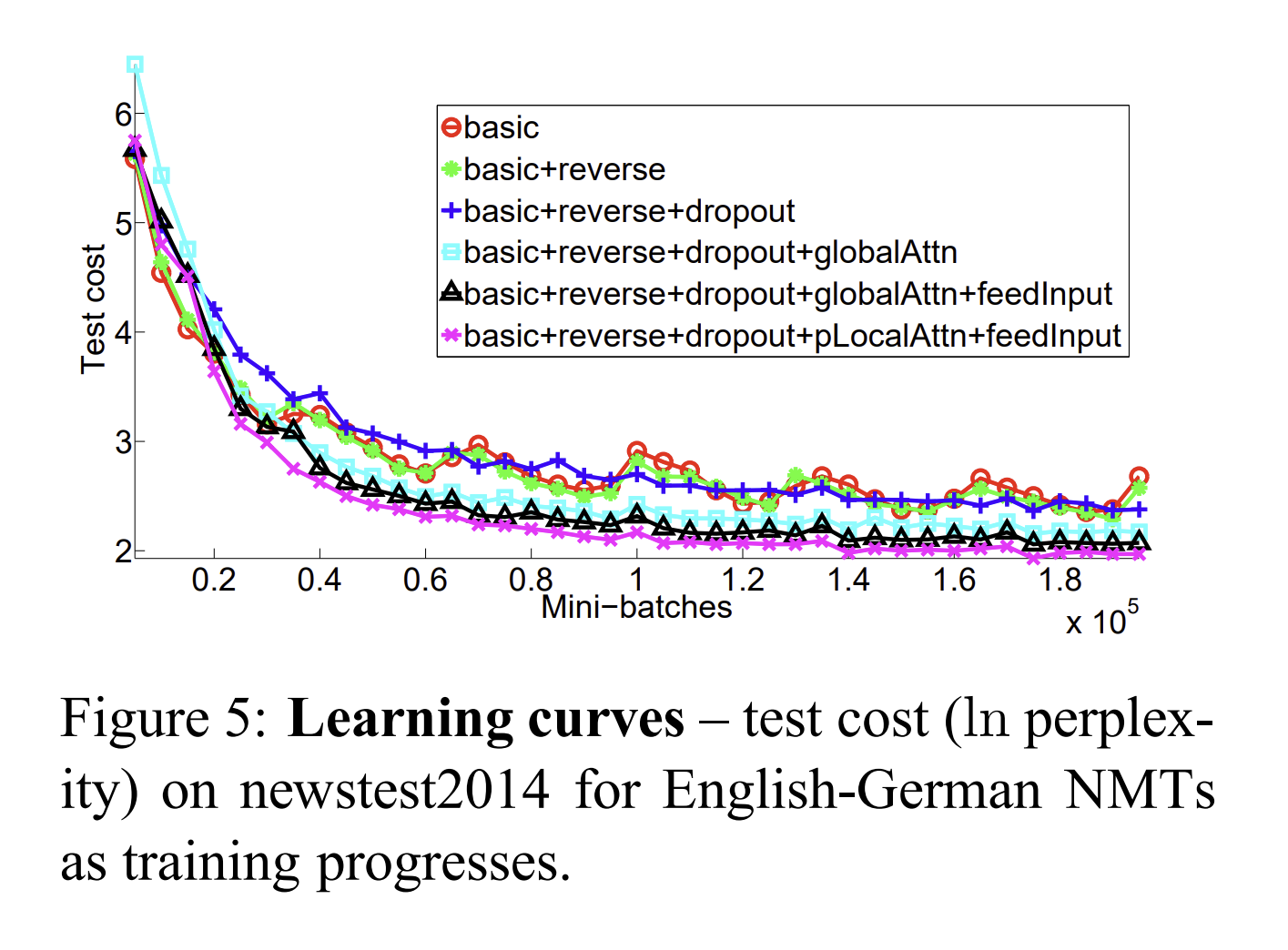
- Mini batch 값을 키울때마다, Test 값이 작아진다.
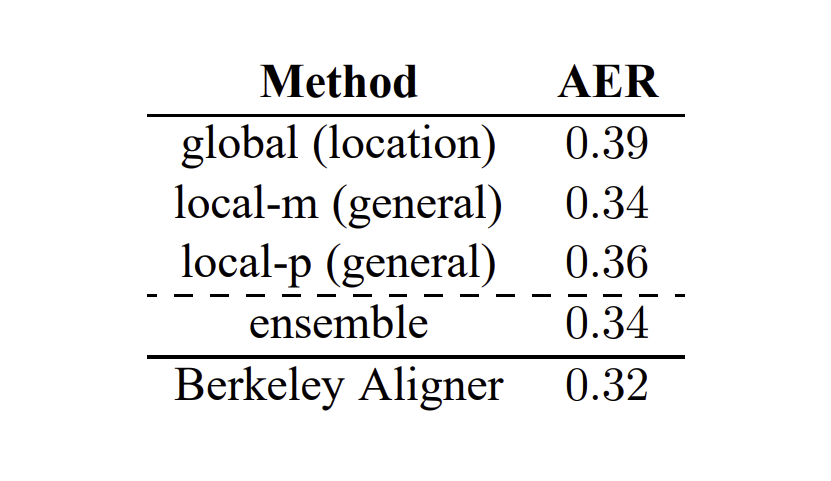
위 값은 논문에서 제안한 3가지 방법의 AER 값을 비교한 표로, AER는 기계번역의 평가 지표중 하나로, 역된 문장과 원본 문장 간의 단어 정렬(alignments)의 정확도를 측정하는 데 사용됩니다. AER 값이 낮으면 낮을 수록 높은 정렬도(문장의 순서)를 보입니다. 위 결과 local-m 방식의 결과가 가장 좋다는 것을 해석할 수 있습니다.
한줄로 정리하면?
어텐션 메커니즘에서 모든 문장의 단어들을 고려하는 것도 좋지만, 한 단어의 부분집합을 지정해서 어텐션 메커니즘을 적용해도 효율은 좋다!
