[논문 리뷰] Neural Machine Translation by Jointly Learning to Align and Translate - Bahdanau Attention
자연어처리 논문 리뷰
Preface
오늘은 트랜스포머 논문의 핵심 기법인 어텐션 기법이 기계 번역에 어떻게 사용이 되었는 지에 대한 논문을 읽어보겠습니다.
급하신 분들은 챕터 3부터 해보시면 될 거 같습니다! + latex를 처음 쓰는 과정이라 조금 어숙합니다.. ㅠ
(2단원은 RNN을 이용한 Seq2Seq의 설명입니다.)
Motivation
위 논문은 어텐션 메커니즘을 신경망 기계학습(NMT)에 적용한 논문으로, 모델 성능에서 굉장히 높은 퍼포먼스를 보여주었습니다. 기존의 Seq2Seq가 가지는 병목(bottleneck)현상은 encoder의 결과를 고정된 벡터로 변환하는 과정에서 문장이 길어지면 길어질수록, 데이터가 완전히 전달되지 않게 됩니다. 그렇기에 번역하려고 하는 단어와 유사한 단어들을 찾는 방식인, 어텐션을 제안합니다.

내용 정리
1. Introduction
<예시>
한글 : 나는 밥을 먹었습니다
영어 : I had a meal.
위의 예시를 통해, Seq2Seq에서 한글 데이터 ‘나는 밥을 먹었습니다’를 Embedding layer로 넣어, 벡터로 변환한 뒤, Encoder에서 학습하여 fixed-length-vector를 만들고, 이를 Decoder에 넣어서 ‘I had a meal’ 이라는 문장을 학습합니다.
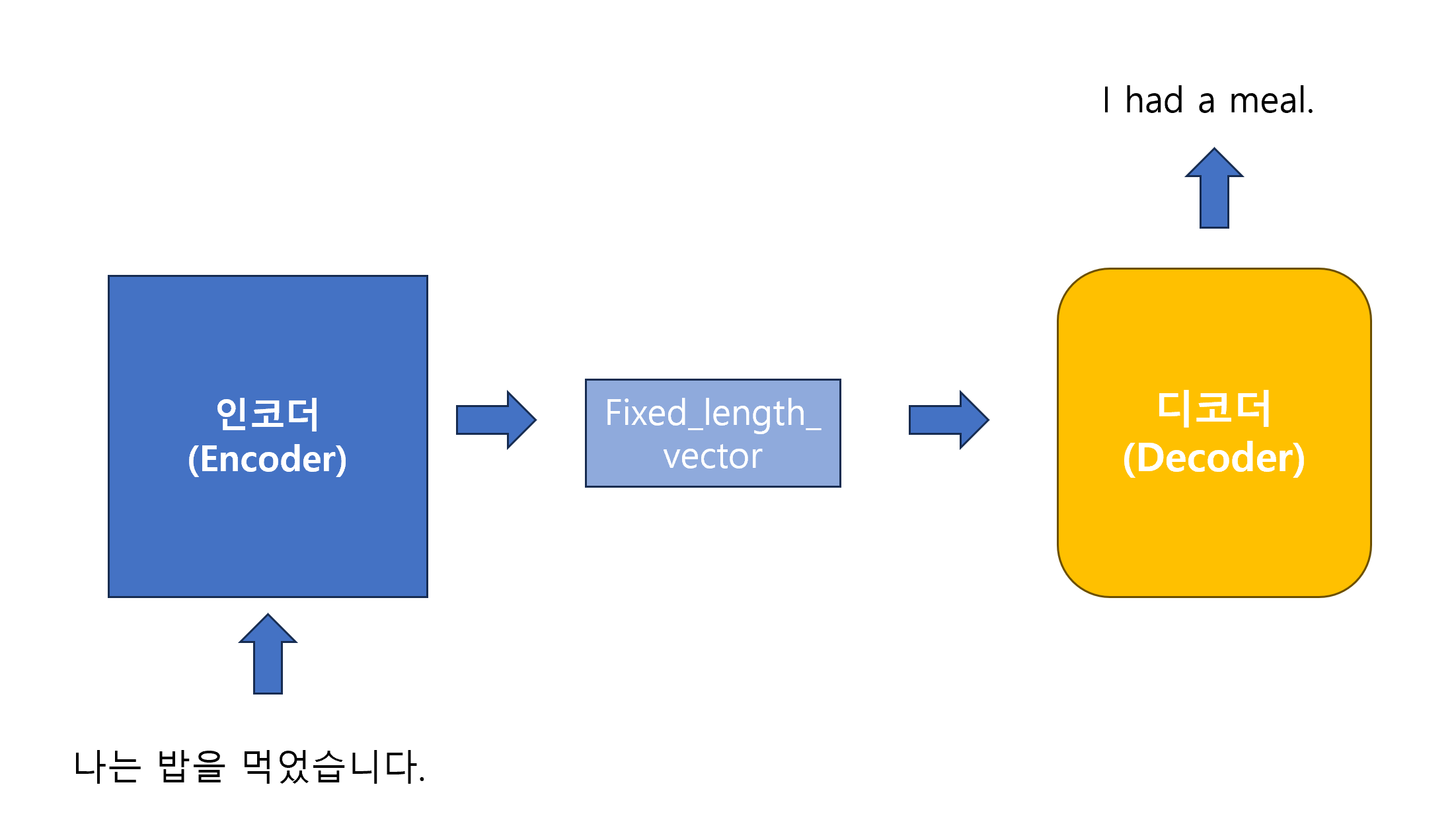
대부분의 모델은 인코더와 디코더가 연결되어 학습합니다. 여기서 문제는 모든 인코더의 데이터를 fixed_length_vector로 변환을 하기 때문에 문장을 학습하기 원활하지 않습니다. 특히 문장의 길이가 더 길다면, 문장의 의미가 제 의미를 가지고 변화하지 않습니다.
그리하여 위 논문에서는 인코더와 디코더를 연결하여 학습하는 법을 배웁니다. 문장에서 가장 관련있는 단어에 집중하여, context vector를 만듭니다. 그리하여 이 context vector와 이전의 단어들을 바탕으로 predict를 하게 됩니다.
그리하여 모델이 디코딩 하는 동안, 인코딩에서 학습된 문장 벡터들의 부분을 선택하게 됩니다. 이 현상은 길이와 관련 없이 데이터 전체가 뭉개지는(squash) 현상을 줄여 줍니다.
2. Background : Neural Machine Translation
2014년 당시 기계 번역은 언어 모델의 개념을 활용하여 X라는 데이터가 주어졌을 때, 가장 높은 확률인 y 값을 선택하여 번역 과정을 거치게 됩니다.
예를 들어,
- Cho et al. (2014a)의 연구는 신경망을 사용하여 기계 번역 시스템의 구문 테이블(phrase table)에 있는 구문 쌍을 평가하는 방법을 제시합니다. 구문 테이블은 전통적인 통계 기반 번역 시스템에서 원문과 번역문 사이의 가능한 구문 매칭을 저장하는데 사용됩니다.
- Sutskever et al. (2014)의 연구에서는 후보 번역들을 재정렬(re-rank)하는 데 신경망을 사용합니다. 이는 번역 후보들 중에서 최적의 번역을 선택하는 과정을 개선하는 것입니다.
2.1 RNN Encoder - Decoder
위 논문에서는 RNN을 이용한 Encoder와 Decoder에 대해서 설명하고 있습니다.
주어진 데이터를 X(한 문장)라고 표현을 하고, RNN Encoder를 통해서 일 때, 학습한 hidden state를 , 는 context로 각각의 hidden state를 모아서 마지막의 hidden state를 의미하고 있습니다.
(여기서 X는 문장, 들은 해당 문장의 단어를 표현하는 스칼라 값 하나하나임.)
Decoder는 보통 다음 의 단어를 예측하기 위해 사용되는 것으로, context vector 와 이전의 모든 단어 까지의 모든 값들을 사용해서 예측합니다.
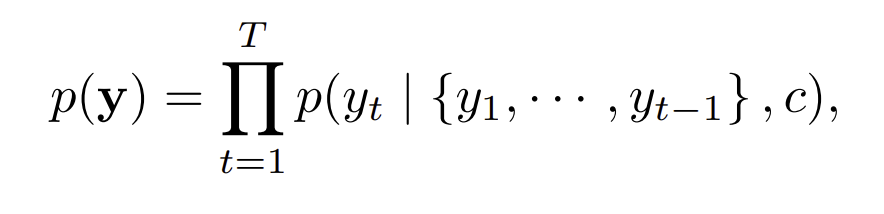
3. Learning To Align and Translate
3.1 Encoder
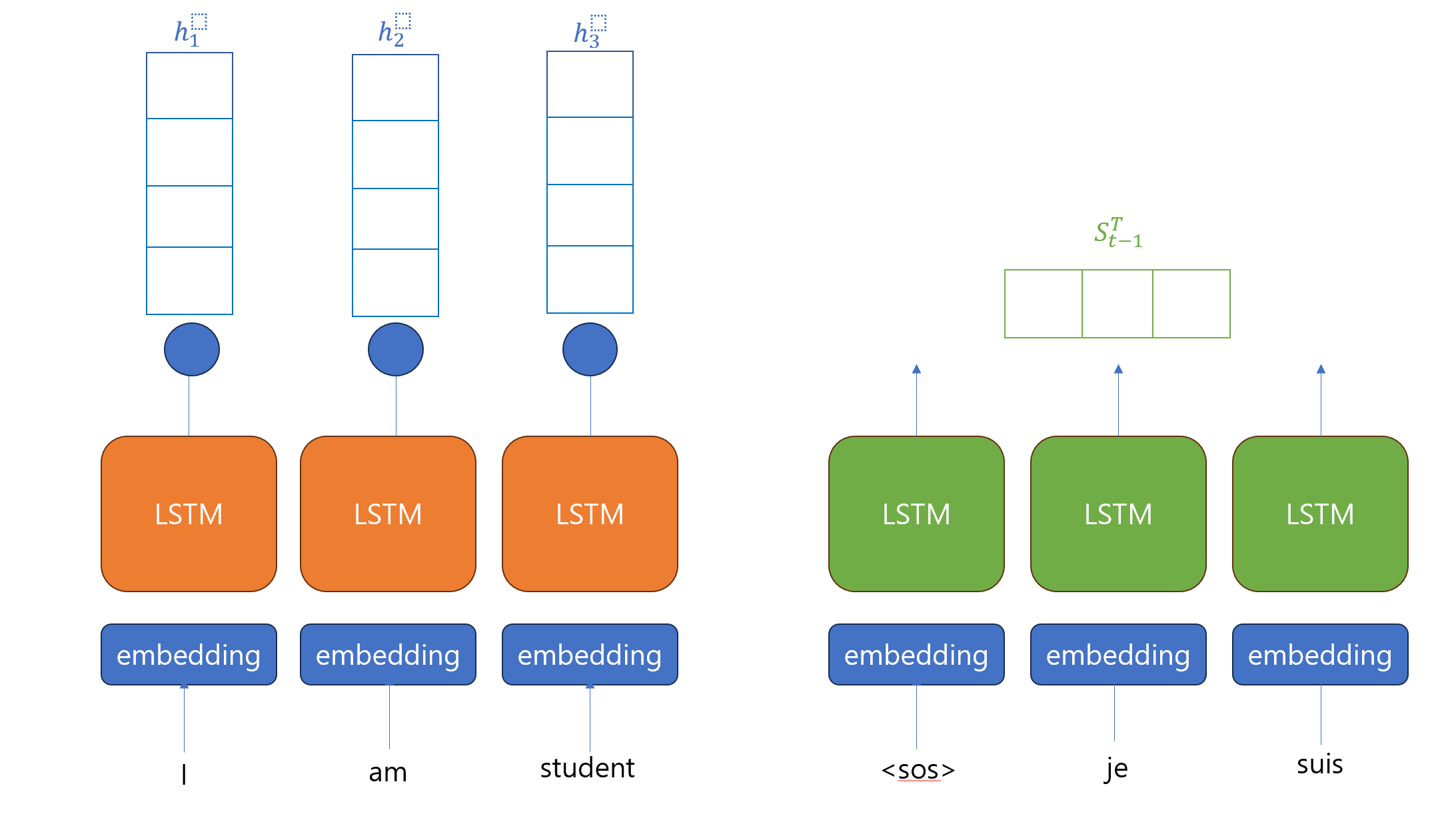
위 논문에서는 기본 RNN이 아닌 양방향의 Bidirectional RNN을 사용합니다. 데이터셋은 forward RNN와 backward RNN을 합쳐서 구성되었습니다.
Encoder에서는 The forward RNN 을 이용하여 로 hidden state를 만들고, The backward RNN 을 이용하여 를 만들고, 각 시점의 hidden state를 단순히 concat를 하여 를 구성합니다.
그리하여 번째의 값과 의 값이 주어진 채로, 어텐션 스코어를 계산하게 됩니다. 식은 다음과 같습니다. 일때, , 여기서 는 학습 가능한 행렬입니다.
이를 모든 값에 적용하여 에 softmax를 취하면 어텐션 분포를 얻게 됩니다. 이 값을 각각의 encoder의 hidden state에 곱하여 context vector 를 구하게 됩니다.
3.2 Decoder : General Description
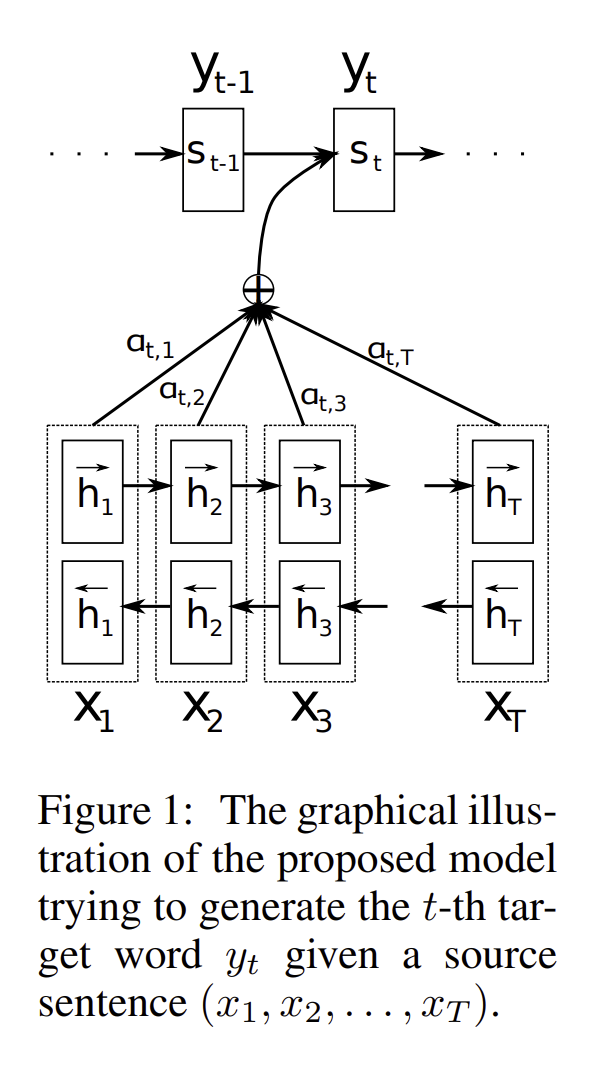
위 논문에서는 과 가 주어졌을 때의 확률을 라는 nonlinear function으로 정의하고, 와 그리고 이 주어졌을 때의 함수 값으로 정의한다. 특히 강조하는 내용은 context vector C를 이용하여 확률을 예측한다는 점이다.
위 그림을 설명해보면, 일때, 양방향 RNN을 통해 나왔던 hidden state들과 attention 스코어를 각각 계산하여 이를 더하여 context vector 로 만든 뒤에 에 넣게 된다.
여기서 는 번째 hidden state 값이고 값은 업데이트된 게이트의 결과, 는 아래와 같은 공식으로 정의된다. 는 아래에서 더 자세히 설명하겠다.
여기서 은 단어 의 embedding이며, 는 reset gate 결과 이다.
논문에서 context vector 는 annotations 을 참고한다고 나와있다.
각각의 annotations 들은 문장의 번째 단어 주위에 어느 부분에 집중을 해야 되는지를 알려준다. → Attention!
context 는 위와 같이 작성이 가능한데, 여기서 는 번째 hiddenstate 값, $a{ij}$ 는 단어 일때, 번째 단어와의 가중치로 로 작성이 되는데 softmax 함수를 사용하여 각각의 가중치 값을 표현한 것이다.
- 여기서 는 번째 context vector를 고려한 hidden state와 번째 RNN hidden state의 연산이다.
- 는 j번째 hidden state 값이기 때문에, j번째 단어의 정보를 가장 많이 포함하고 있을 것이고,
위 모델은 latent variable이 아니고, backpropagated 하는 과정에서 계속적으로 optimized 하는 과정을 거치게 된다. 그리하여 확률 값은 annotation 에서 중요한 값을 표현해주어, context 를 참고한 hidden state 를 통해 다음의 결정하고 와 를 만드는데 기여를 합니다.
4. Result
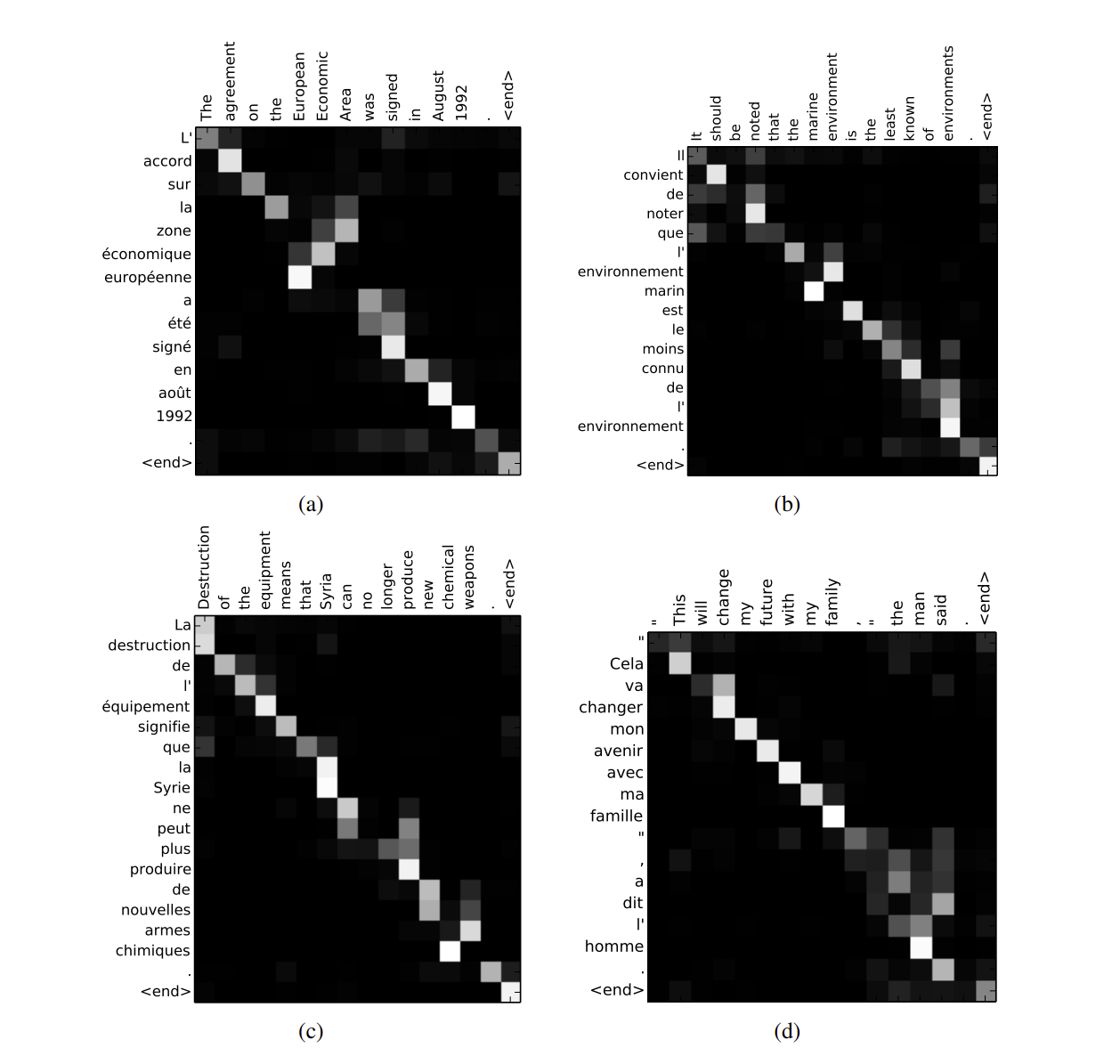
- 문장의 길이가 늘어날 수록, 대부분의 모델이 성능이 나빠지지만 RNNsearch-50은 Attention을 통해 BLEU score가 유지됨을 알 수 있습니다.
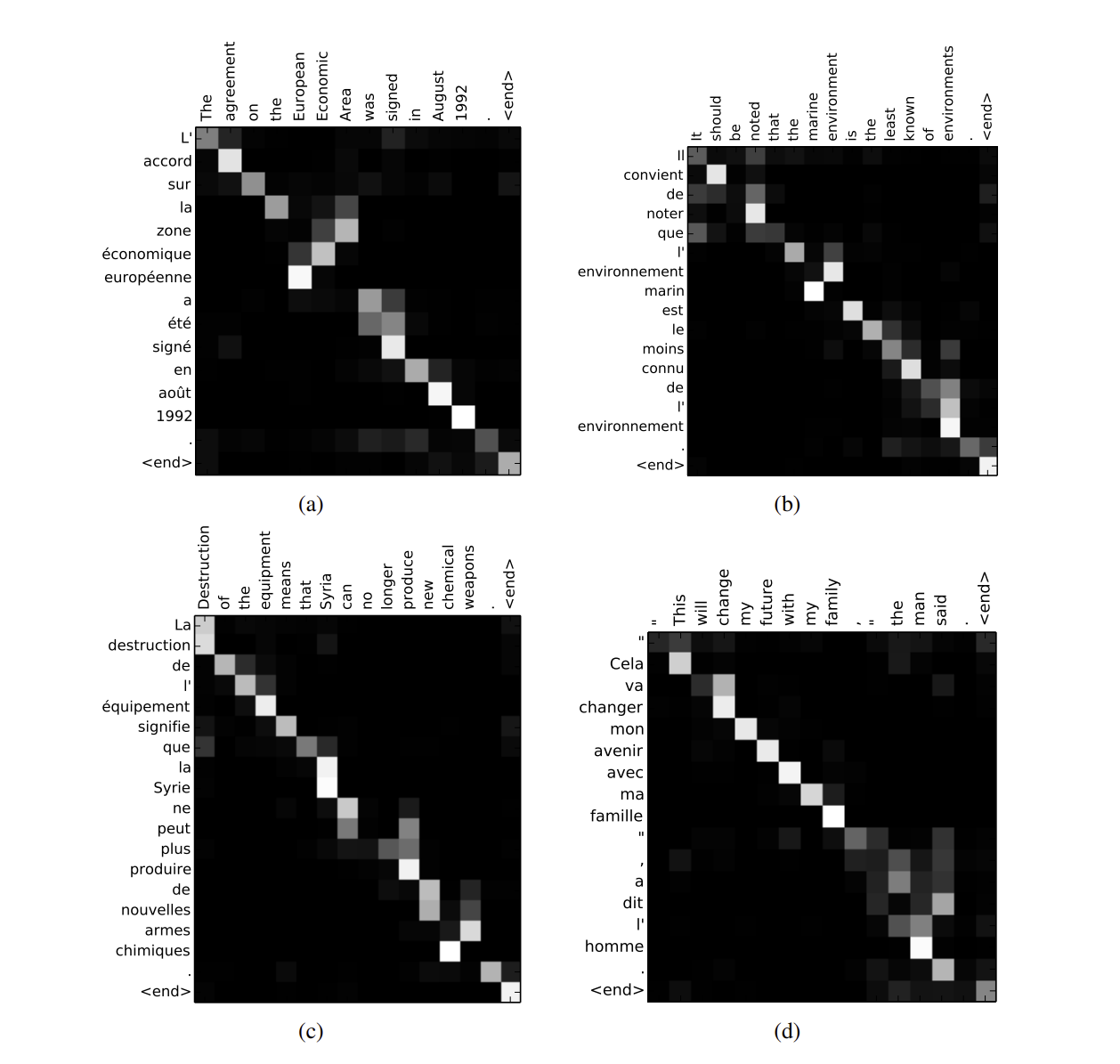
- Attention score를 시각화 그래프로, 각각의 단어가 무슨 단어와 연관이 있는 지를 알아내어, 이를 참고하여 모델이 학습을 진행하게 됩니다.
- 그리하여 이 모델을 통해 Seq2Seq의 고질적인 병목현상을 해결하고 긴 문장이 들어와도 이를 견딜 수 있게 (robus) 해지는 현상을 볼 수 있습니다
한줄로 정리하면?
어텐션 메커니즘을 통해서 모델이 각 단어별로 어느 단어와 연관성이 높은지, 문장의 중요한 부분을 잘 이해할 수 있게 되어 신경망 기계학습(NMT)의 성능이 굉장히 올랐다.
