[논문 리뷰] Training language models to follow instructions with human feedback(InstructGPT)
자연어처리 논문 리뷰
Preface

<GPT의 역사 정리>
GPT1
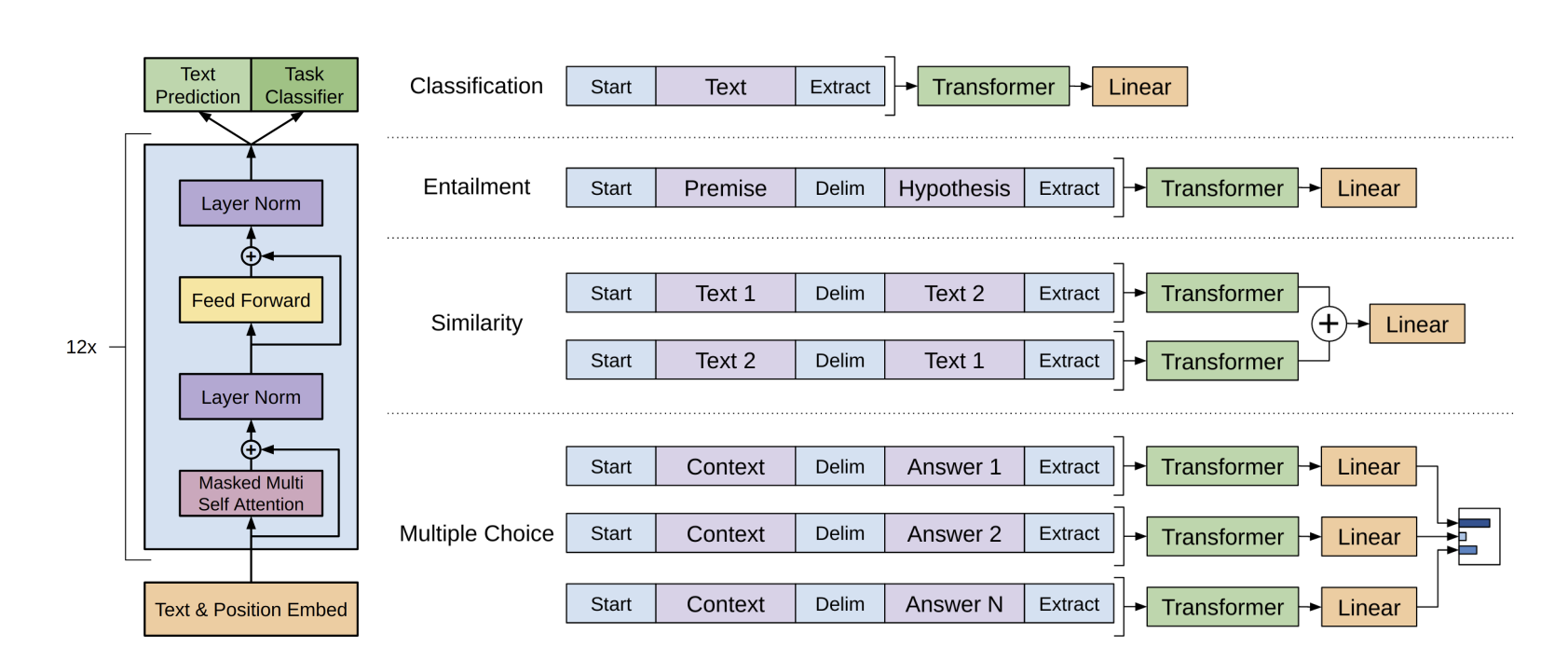
GPT1은 Transformer의 Decoder 구조를 12개의 layer를 쌓아 올린 구조입니다. Pretraining을 위해서 Language Modeling을 했습니다. 이는 주어진 토큰 시퀀스를 바탕으로 다음에 올 토큰을 예측하게 하는 auto regressive한 구조로 만들어졌습니다.
GPT2
GPT1 이후에 던져진 Research Question으로는 Fine tuning 없이 zero-shot으로 downstream task를 풀 수 있는 방법이 있을까요? 에 대한 질문이 제기되었습니다. (GPT에서는 pretraining 이후, fine tuning을 통해 downstream task에 맞게 함). 그리하여 직접 구축한 데이터셋(WebText)를 이용하여, batch_size, input_length, vocab_size, model_size 등을 증대시켜서 GPT2를 만들게 됩니다.
GPT2에서는 In-context learning을 사용하게 됩니다. In-context learning은 ****맥락을 읽는 것으로, 이미 dataset 과정에서 downstream task과 관련된 문장들이 존재했습니다. 그리하여 사전학습 과정에서 downstream task 학습이 가능해집니다. 그래서 Prompt만 추가를 하여 downstream task를 설정하기만 하면 fine tuning 과정이 필요 없어지는 것입니다.
GPT3
1750억개의 파라미터를 활용하여 In-context learning을 하는데, GPT2와 달라진 점은 모델이 task에 대한 정보를 참고해서 inference 할 수 있도록 input에 예제(demonstration)을 추가하는 것입니다.
(여기서 demonstration은 학습 데이터에서 랜덤으로 최대 32개의 문장을 뽑아 연결(concat)하게 됩니다.)
1. Introduction
LM 모델들은 ‘prompted’ 하여 NLP 테스크에 적용할 수 있습니다. 그러나 이러한 unintended behaviors들인 종종 발생하기도 하는데, toxic text나 biased된 text를 만들거나, 없던 사실을 만들거나, 유저의 지시를 잘 따르지 못하는 문제점이 있습니다. 이러한 사실은 많은 언어 모델의 결론이 misaligned된 것으로, 이러한 문제점을 개선하기 위한 방법을 저자는 제안하였습니다. user의 instruction을 잘 제공할 수 있다면, helpful, honest, harmless, 하게 모델을 만들어낼 수 있습니다.
저자는 강화학습을 이용하여 RLHF 방식을 이용해 LM모델을 fine tuning 하였습니다. 사람의 선호도를 reward로 적용하여 model에 fine tuning을 진행하였습니다. screenting test를 하여 40명의 알바생을 고용하여 label링을 진행하였습니다. 인간에 의해서 적힌 desired output behavior의 human written demonstrations dataset을 모으고, 이것을 이용하여 supervised learning을 진행하였습니다. 그리고 human labeled된 comparision 데이터셋을 보아서 결과와 비교하는 작업을 진행하였습니다. 이걸 바탕으로 Reward model을 학습을 진행하고 PPO algorithm을 이용하여 총 reward가 크게 나오게 하는 과정을 진행하였습니다. 이렇게 나온 모델을 InstructGPT라고 정의하였습니다.
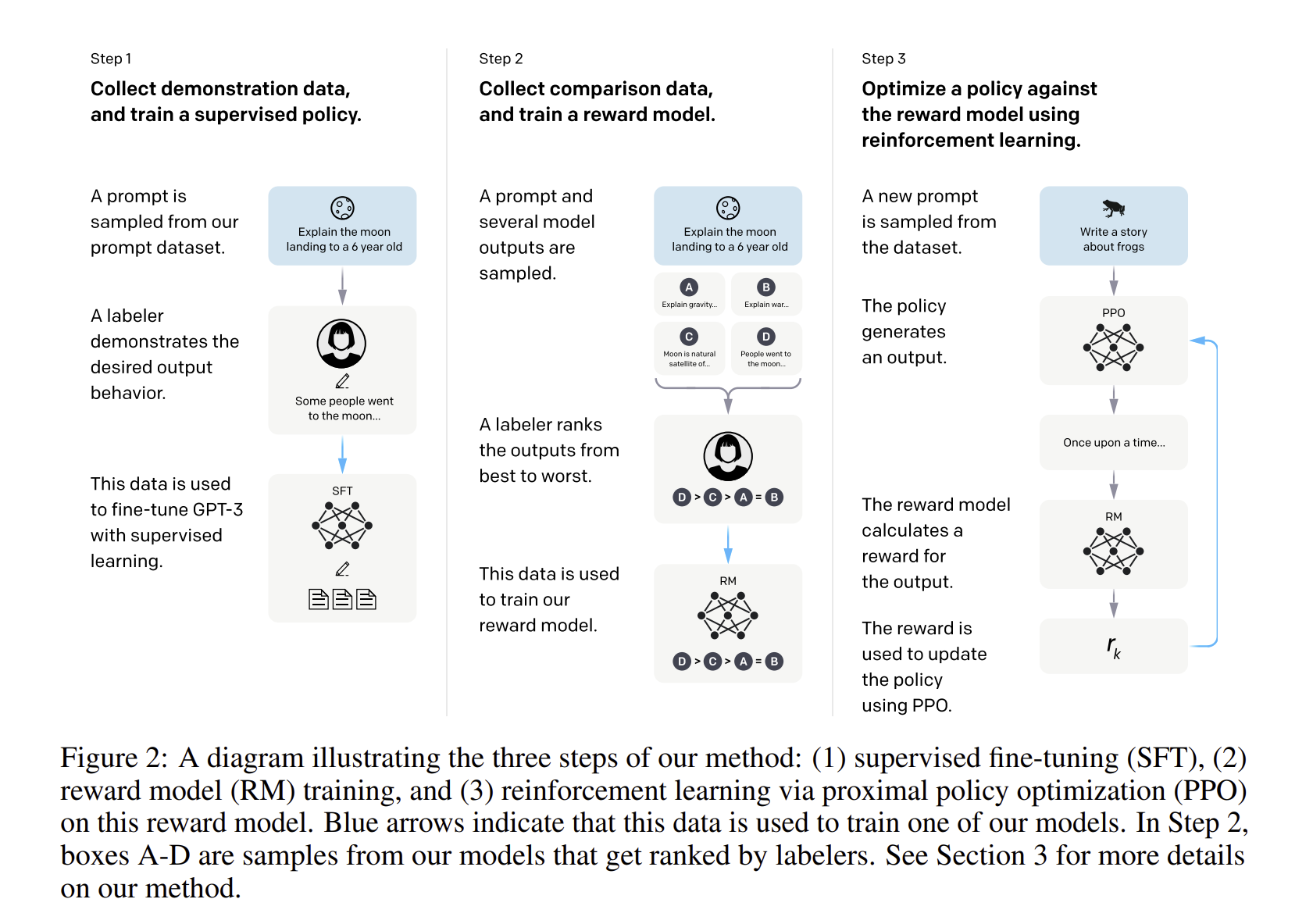
학습 과정을 정리해보겠습니다.
1단계로, prompt 모델에 sample prompt(질문)를 받아, 이에 대한 desired output을 인간이 직접 도출하고, 이에 대한 결과를 모델에 fine tuning을 시킵니다
2단계로, prompt 모델에 sample prompt(질문)을 받고, 모델이 직접 낸 결과를 사람들이 선호도를 매기고, 이로 Reward model을 학습하게 됩니다.
3단계로, 위에서 학습한 Reward function 최대화시키기 위해서, 강화학습 기법 중 하나인 PPO를 통해서 Policy(파라미터)를 학습하게 된다.(어떤 질문에 대해서 policy가 결과를 내게 되는데, reward function을 통해 reward 를 생성하게 됩니다. 이후 PPO를 업데이트 해서 GPT3에 파인튜닝이 진행된다. → Policy가 점점 업뎃되는 것.)
2단계와 3단계는 계속 반복되어 더 좋은 모델이 되기 위해 반복되게 됩니다.
<결과 정리>
- labeler들은 상당히 GPT3 의 결과보다 Instruct GPT의 결과가 더 좋다고 하였음
- InstructGPT 모델이 GPT3 보다 truthfulness를 가짐.
- small toxicty를 가짐. 그런데 bias까진 아님.
- 성능이 더 좋아졌어도 실수는 아직도 하긴 함.
2. Related Work
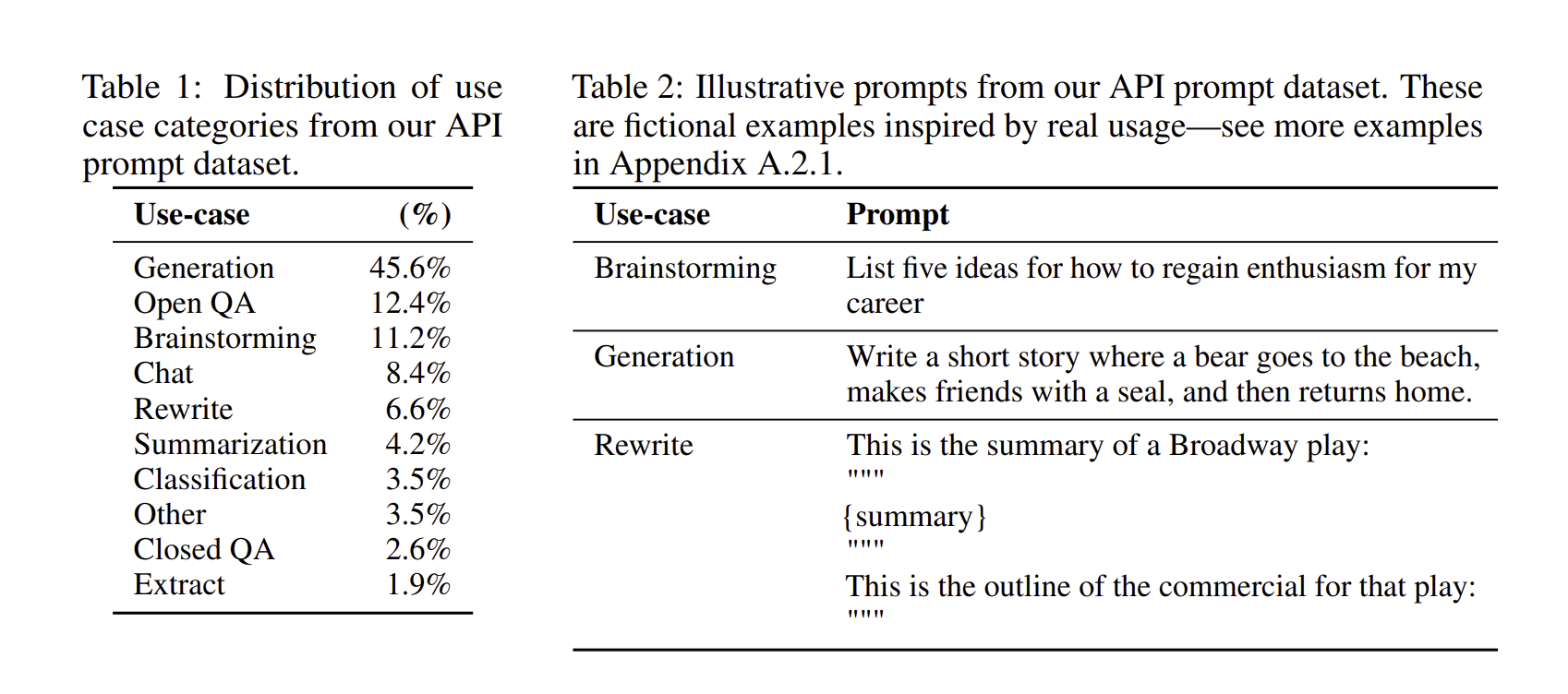
API prompt를 이용해서 생성한 데이터셋과 구해온 데이터셋의 분포는 Table1과 같습니다. 그리고 API prompt dataset에서 만들어내었던 example은 오른쪽 위와 같습니다.
3. Methods and experimental details
3.1 High-level methodology
학습 과정은 다음과 같습니다.
Step 1: demonstration data를 모으고, supervised policy를 train 하기.
Step 2: comparision data를 모으고, reward model를 학습하기
Step 3: PPO를 이용한 reward model에 대응한 policy 최적화시키기.
3.2 Dataset
Labeler들에게 데이터셋을 모으기 시작하게 할 때,3가지의 기준으로 데이터를 모으게 하였습니다.
먼저. Plain으로 언제든 arbitrary task를 떠올릴 수 있게 물어보게 하였고, Few-shot으로 지시와 multiple query와 response pairs를 물어볼 수 있는 것, User-based로 각 Use case에 별로 prompt를 물어볼 수 있는 것 등의 기준으로 질문을 하였습니다.
3.3 Tasks
training task는 2가지 source인데, 첫 번재는 labeler에 의해서 가져와진 데이터셋, 두 번째는 early instructGPT model에 의해서 만들어진 datset 입니다.
3.4 Human data collection
40명의 labeler를 모을 때는 사람들이 최대한 민감하지 않으며 harmful 한 데이터를 잘 구분하는 사람들을 모으고자 하였습니다. 그리하여 screening test를 통해서 사람들을 구별하였고, 이러한 test에 적절한 사람들을 선택하였습니다
3.5 Model
모델 학습 순서는 3가지로 구성됩니다.
Supervised fine - tuning(SFT) : supervised learning으로 demonstration을 이용하여 GPT-3를 fine tuning 하였습니다. 16에폭으로 학습을, cosine learning rate decay,와 residual dropout을 활용하였습니다. 학습은 RM 스코어를 기준으로 학습하여, overfitting이 되어도 RM 스코어가 잘 나오는 쪽으로 진행되었습니다.
Reward Modeling(RM) : 6B RM을 이용하고, 2가지의 모델 아웃풋 사이에서 비교한 데이터셋으로 학습이 진행이 됩니다. cross entropy loss를 이용함. human laberer에 의해서 어느 응답이 좋은지를 구분합니다.
K값을 4개에서 9개 사이로 설정을 하면, 개의 응답이 나오게 됩니다. 이를 전부 비교하면 single pass를 여러번 하게 되어 시간이 오래 걸릴 수 있습니다. 그리고 각 라벨링별로 응답들이 어느정도 유사도가 있기 때문에, overfitting을 유발하기도 합니다. 그래서 한개의 single batch로 모든 comparision을 넣은 다음에 모든 경우의 수를 한번에 계산하면 굉장히 computationally 하게 effencient 하다는 점을 알 수 있습니다. 그래서 overfitting도 막을 수 있게 됩니다.
x는 내가 넣은 input, , 은 각각 넣었을 때, 나온 답변이고, 이들의 차이를 통해서 loss funciton을 계산하게 됩니다.
Reinforcement learning(RL) : 이후에 학습한 RM 모델을 reward function으로 활용하 PPO 알고리즘을 이용하여 다시 학습을 진행하였습니다. KL penalty term을 추가하여 Policy의 급격한 변화를 방지하기 위해 파라미터 변동 폭을 제한하였고, 특정 task에서 성능 저하를 관측하다보니, PPO-ptx라는 pretraining gradient를 PPO gradient와 mix하는 방법을 제안합니다.
Baselines : GPT-3 모델과 SFT 모델에 각 PPO를 적용한 perofrmance를 비교하였습니다.
3.6 Evaluation
저자의 목표는 user intention에 맞게 모델을 학습하는 것입니다. 그래서 모델은 instruction에 따라야 하는데, 프롬프트의 의도가 불명확하는 경우가 있는데, 이는 전적으로 labeler들의 판단에 맞기기로 하였습니다. 그러나 labeler들은 프롬프트를 생성한 사람들이 아니기 때문에, 유저가 생각한 것과 labeler들이 생각한 것간의 차이가 있을 수도 있습니다.
두번째로 판단해야 하는 것은 truthfulness로, 일단 모델의 output의 belief를 계산하는 것은 힘들었습니다. 그래서 truth 한지 안한지를 계산하기로 하는 것입니다. 정보를 만들어내는 모델의 경향성을 판단하거나, TruthfulQa dataset을 이용하여 평가하였습니다.
세번째로 판단하는 것은 언어 모델의 harmful을 평가하는 것으로, 많은 언어모델에서 harms은 실제 세계에서 그들의 결과가 어떻게 사용되는지에 대해 달려있습니다. 예를 들어서, toxic한 output은 deployed chatbot의 context에서는 harmful 하지, detection model에서는 더 정확한 결과를 만들어 내기 위해서 helpful 할 수도 있습니다.
4. Results
4.1 Results on the API distrivution
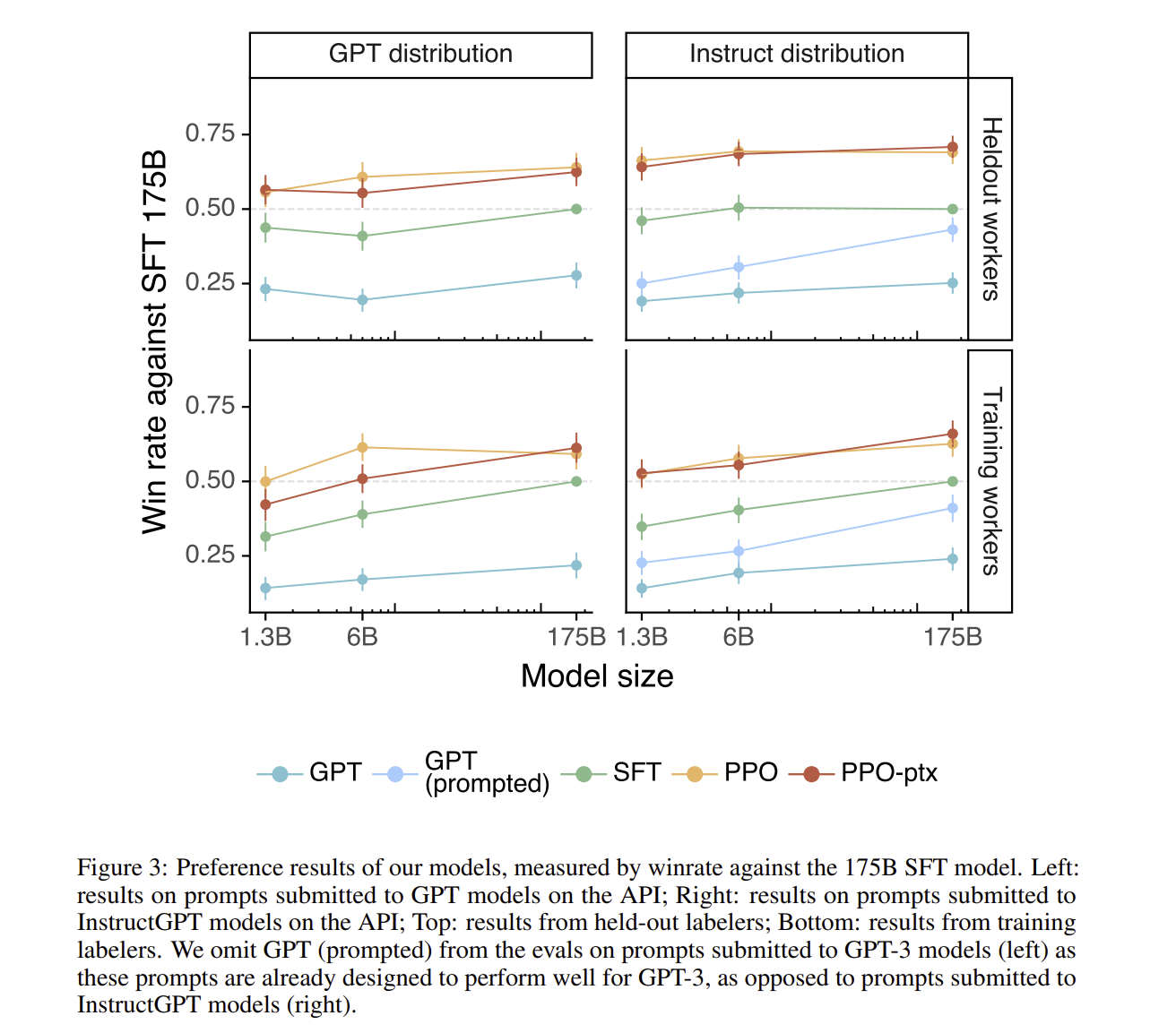
labeler들은 상당히 일반 GPT 보다 Instruct GPT가 더 좋은 성능을 보인다고 이야기하였습니다. 모델의 성능을 보게 되면, instruct를 참조한 GPT의 경우에 기존의 GPT 보다 더 높은 성능을 보이게 되었다.
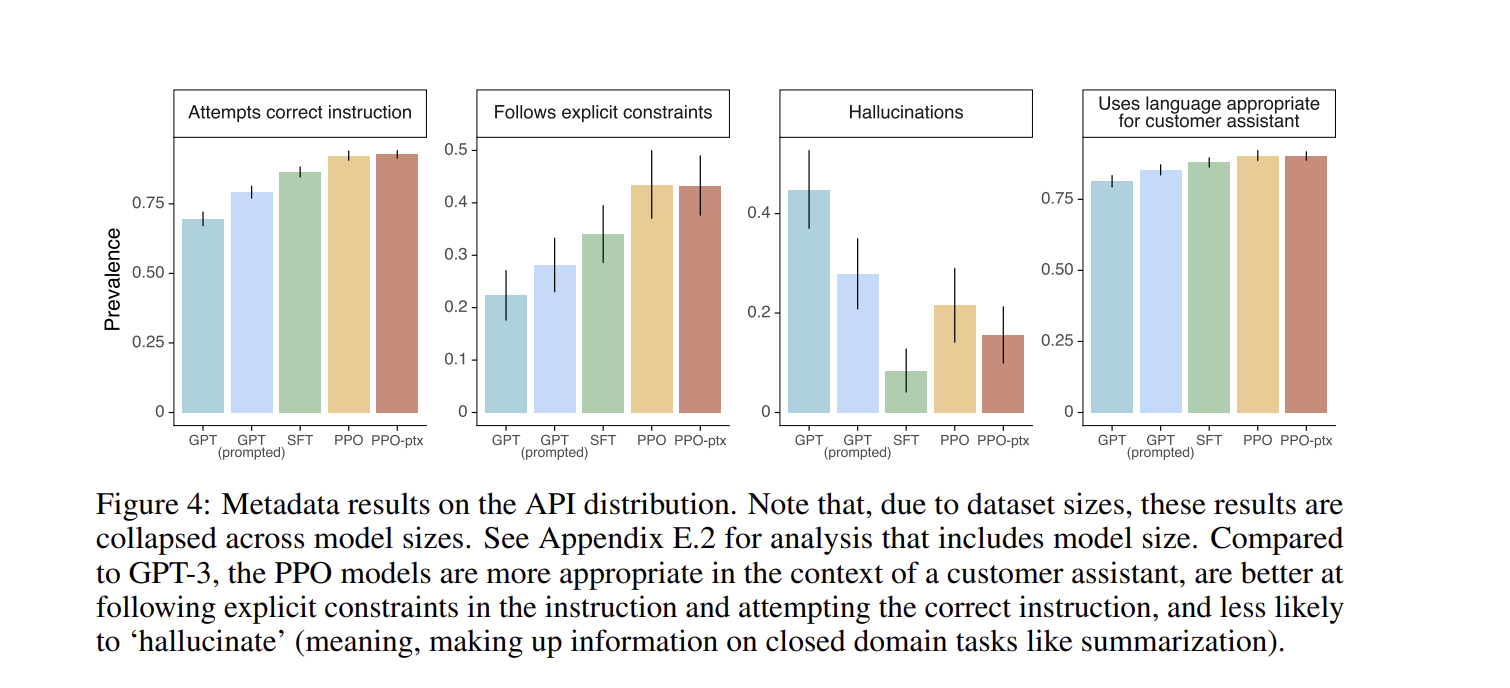
그리고 PPO-ptx를 적용시킨 instruct GPT의 결과를 보게 되면, prevalance가 굉장히 높다는 것, hallucination이 기존의 GPT 보다 엄청 낮다는 것을 확인해볼 수 있습니다. Held-out labeler(training data를 만들 때는 참여하지 않았던 labeler)들이 이를 평가하였습니다.
4.2 Results on public NLP datasets
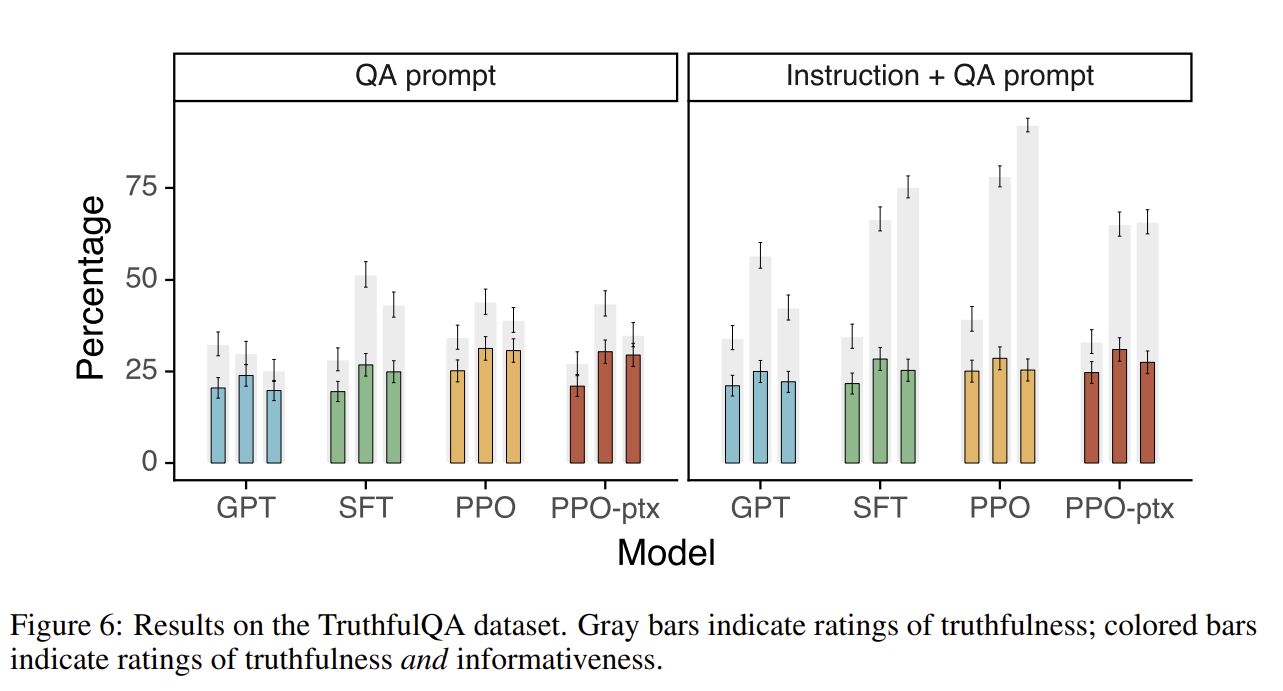
QA dataset을 기반으로 한 결과도 보게 되면, instruction의 최댓값이 일반적으로 높다는 것을 알 수 있습니다.
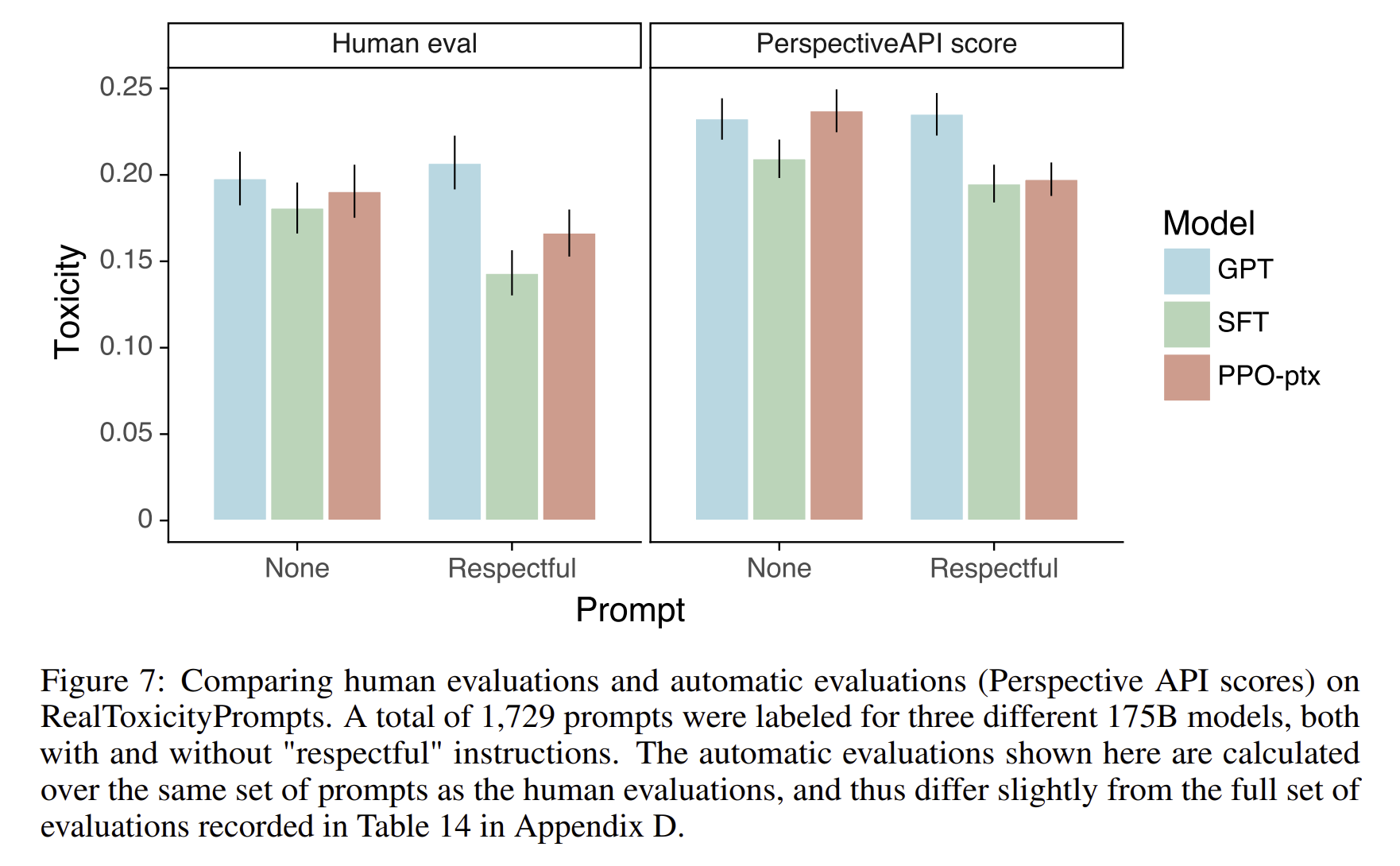
Toxic 값을 낮출 수는 있었지만, bias 값은 해결하지 못했습니다. respectful하게 답변하라는 prompt 가 제공되었을 때, GPT-3보다 25%가 적은 toxic 답변을 제공하게 됨. 그러나 bias를 평가하는 Winogender과 CrowSpari 데이터셋에서는 GPT-3에 비해서 크게 개선되지는 않았음.

fine tuning 과정에서 나왔던 RLHF 과정을 잘 적용시켜서 public NLP datasets에 minimize를 시킬 수 있었고 확실히, InstructGPT의 결과가 더 자세하고 좋았다는 게 확인이 됩니다.
한 줄로 요약하면?
기존의 GPT 방식에서 RLHF 라는 인간의 선호도를 추가하여 학습을 하게 된 InstructGPT는 성능이 향상 + toxic 제거 + 할루시네이션 감소.
