[논문 리뷰] Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation (2020 ACL)
자연어처리 논문 리뷰
Preface

1. Introduction
Multilingual NMT가 큰 이점을 가지고 있음에도 불구하고, 너무 많은 언어들이 모델에 포함되어 있을 때, 종종 성능을 낮추게 하는 경우가 있습니다. 왜냐하면 MNMT의 언어들은 각자 언어적 특징을 가지는 게 다르기 때문에, 모델의 capacity가 굉장히 큽니다.(mBERT에서는 그래서 모델의 용량이 적기 때문에 너무 많은 언어들을 포함하면, bottleneck 문제로 모델에 오히려 성능을 저하시키는 경우가 있습니다.
그리하여 저자는 언어를 잘 알고 있는 layer normalizaition과 representation들을 linear transformation 하는 방식을 제안했습니다. Encoder과 Decoder 사이에 linear transformation을 넣어서 모델이 이러한 해석 과정을 더 잘 알게 만들어 주었습니다. 또한 새로운 NMT 아키텍쳐를 제안하였습니다.
MNMT에서 생길 수 있는 또 다른 문제점은 zero shot performance가 굉장히 낮다는 점인데, 특히 pivot based한 model들과 비교하면 굉장히 낮습니다. (여기서 pivot based 란? 중간 매개체인 언어인데, 예를 들어 한국어, 영어, 중국어가 있고 한국어와 중국어를 번역하려고 하는데, 한국어 → 영어 → 중국어 여기서 영어가 pivot based 언어입니다.) (왜 낮나면, zero shot learning 에서는 애초에 보지도 못한 쌍을 가지고 학습을 진행하기 때문에, 언어쌍 관계를 모르지만, pivot based한 모델들은 언어쌍의 관계를 간접적으로라도 학습할 수 있기 때문이다)

이렇게 pivot 언어를 영어로 설정하여(영어가 세계에서 제일 많이 쓰는 언어중 하나), 번역을 하면 비용을 줄일 수 있다는 점.
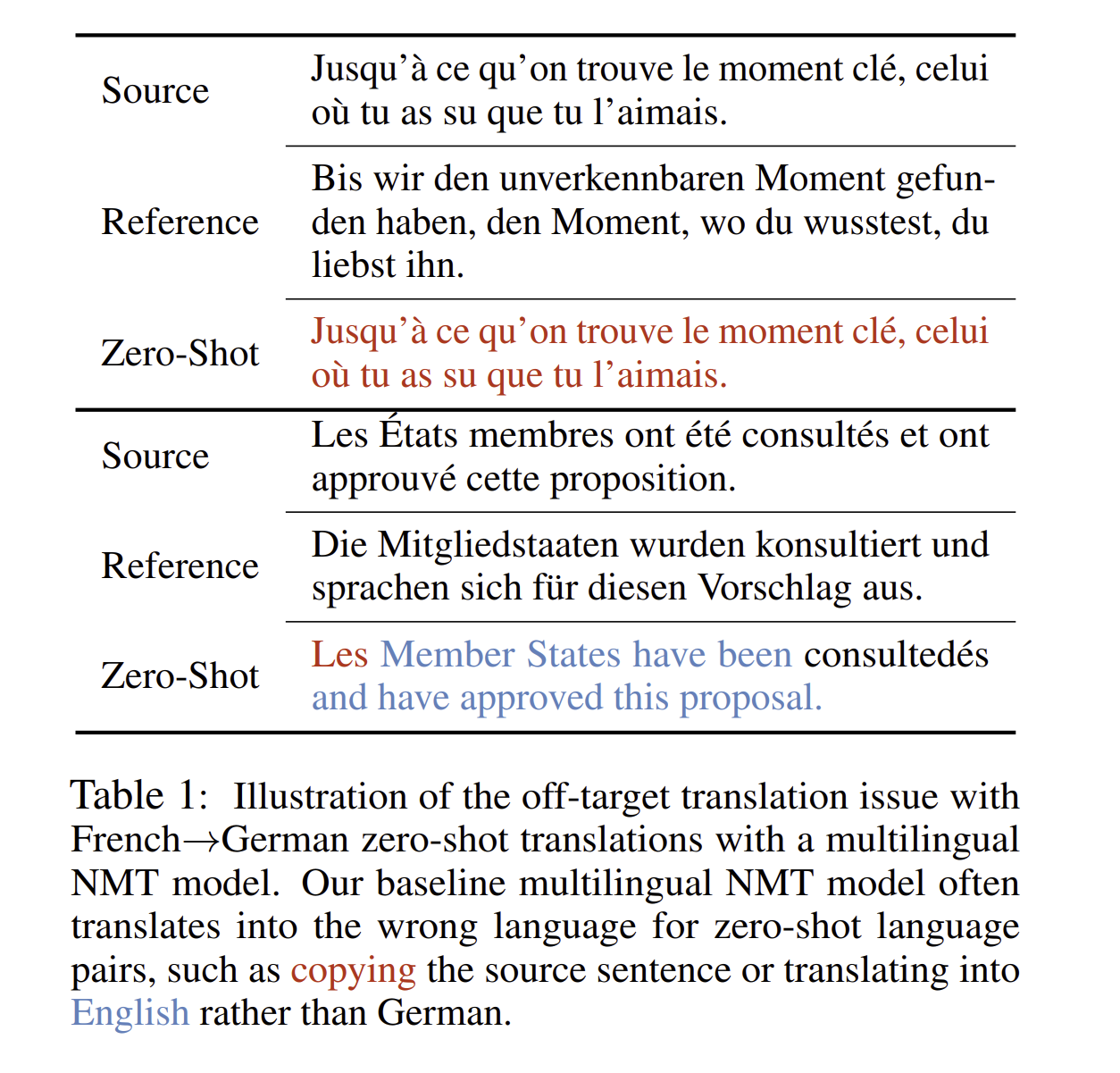
만약에 다국어 언어쌍을 병렬적으로 배열하지 못한다면, multilingual model은 쉽게 목표 언어를 무시하고, 잘못된 언어로 번역을 해버리는 off target 번역의 문제에 쉽게 빠질 수 있습니다.
그리하여, 저자는 ROBt(random online backtranslation)을 제안합니다. ROBt는 pretrained된 MNMT 모델을 보지 못한 언어쌍에 대해서 fine tuning 합니다. 그리고 목표측 훈련 데이터를 역번역하여, 생성된 가짜 병렬 배치를 이용하게 됩니다. 역번역은 무작위로 선택된 중간 언어로 수행되어 약 10,000개의 제로샷 방향을 잘 커버할 수 있도록 합니다.
모델 학습을 하면서 저자가 발견한 것은
- MNMT의 용량을 늘리면서 엄청나게 학습 효과가 늘었으며, 단일 언어 모델의 performance gap을 좁힐 수 있었다는 점, 특히 low resource translation에서 더 큰 이점을 얻었음.
- Language specific modeling과 deep NMT 아키택쳐가 zero shot learning translation의 성능을 올릴 수 있었다는 점, 그러나 off target translation issue는 완화하지 못함.
- ROBt 데이터로 MNMT를 fine tuning 하니, off target translation의 문제를 나름 해결할 수 있었으며, BLUE 스코어가 10이나 올랐다는 것을 알 수 있었다.
2. Related Work
MNMT의 첫 시작은 encoder를 공유하는 것으로, one -to-many 번역이나, many - to -many 번역을 사용하였습니다. 이러한 방법은 각 언어 마다 encoder와 decoder를 필요로 하여 그들의 scalability를 제한하였습니다. 반대로 character level inpput을 사용하고, shared encoder를 사용하여 many - to -one translation을 만들기도 하였습니다.
Ha et al 와 Johnson et al은 target language를 알려주는 symbol을 이용하여 번역을 더 잘하기도 하였지만 이는 언어적 다양성을 무시하는 경우를 초래했습니다. 이후의 연구들은 이러한 representation 병목 현상을 해결하기 위해서 parameter sharing을 진행하거나, language-specific parameter gernerator를 만들거나, multilingual word encoding을 language clustering으로 decoupling을 진행하기도 하였습니다. 저자도 이와 비슷한 방향으로 진행이 되지만 normalization layer를 더 넓히는 것에 초점을 맞춥니다.
MNMT는 종종 위 사진 Table1과 같은 잘못된 번역을 하는 경우가 있습니다. 그리하여 zero shot performance를 항샹시키는 위해 일반적으로 해결책이 2가지 카테고리로 분류됩니다.
- 새로운 cross lingual regularizer, consistency regularizerd를 developing 하기
- artificial parallel data를 역번역이랑 같이 하기 or pivot based 번역하기.
저자가 제안한 ROBt algorithm은 2번째 항목에 해당이 되고, ROBt는 각 zero shot 언어 쌍에 대해서 전체 학습 세트를 decoding 하지 않기 때문에 multilingual setting에 거대하게 다가갈 수 있습니다.
3. Multilingual NMT
구조는 Transformer 구조에, layer는 6개를 쌓았으며, encoder는 똑같고, decoder는 비슷하지만 extra cross attention sublayer를 사용하지 않는다는 점이고, each sublayer에는 residual connection만 들어간다.
4. Apporach
MNMT는 여전히 1. 많은 언어를 넣으면 넣을수록 모델의 퀄리티가 내려가는 모델의 수용량 2. off target translation의 문제점을 겪고 있습니다.
그리하여 저자는 기존의 Transformer 구조는 이를 해결하기 못할 것이라고 생각하여 더 깊은 Deep Transformer 구조를 제안하기도 하고 language별 구성 요소를 고안하였습니다. 반대로, 저자는 parallel data의 부족을 off target issue의 이유로 취급하여 제로샷 언어 쌍마다 인공 병렬 훈련 데이터를 온라인으로 생성하여 번역의 performance를 더 늘리는 데이터 수준 전략을 사용합니다.(지금까지는 이해가 잘 안감)
Deep Transformer
모델이 수용할 수 있는 양을 늘리는 방법은 단순하게 모델의 깊이를 늘리면 되는 것이다. 저자는 depth - scaled initialization method를 선택하여 더 깊은 Transformer를 학습시킵니다.
Language - aware Layer Normalization
언어가 다름에도 불구하고, layer normalization은 모든 언어들이 하나의 가우시안 space로 가는 것으로 제한시켜 버립니다.(왜냐하면, 언어적 차이성을 애초에 고려를 하지 않고 하나로만 다 넣어버리니). 그래서 normarlization을 condition을 하여 이러한 제한을 완화시키는 것을 제안하고 있습니다.
이 formula는 모든 normalization layer입니다.
Language - aware Linear Transformation
다른 언어 쌍들은 다른 번역 관계나 word alignment를 가지고 있습니다. 더불어, LaLn에 추가하여, 저자는 target language aware linear tranformation을 제안합니다. 인코더와 디코어 사이에 넣어서 flexible translation 관계를 만들어줍니다.
Random Online Backtranslation
zero shot translation에서 역번역에 대한 이전의 연구들은 전부 전체 training set을 각 zero shot language에 decode를 하는 것이고(과정을 자세히 말해보면, 프랑스어에서 영어, 영어에서 독일어로된 학습된 모델이 있다고 가정을 하면,프랑스에서 독일어로 번역하기 위해 영어를 써서 decode를 하는 것이지요). 이 방식으로는 zero shot 언어 쌍에 대한 전체 훈련 세트에 대해서 모두 번역을 해야 하기 때문에 9702개의 번역 방향성을 가지게 됩니다.

그리하여 online backtranslation을 하여 scalability를 다루게 됩니다. 위 사진은 ROBt에 대한 자세한 사진으로, 각 training때 마다, 저자는 중간 언어를 선택하고, back translate를 진행해서 x데이터를 얻게 됩니다. 그리고 새로운 예시에 대해서 다시 학습을 하는 것입니다.
5. OPUS - 100
최근에 MNMT는 10~100개 이상의 언어를 다루게 되었습니다. 저자는 영어를 중심으로 하는 데이터셋을 만들었는데, 이는 모든 데이터 쌍에 train 이든 test 이든 English를 포함한다는 의미입니다. English를 포함하지 않는 영어 데이터 쌍은 zero shot으로 진행을 하거나 English를 통해 pivot 하게 하였습니다.
저자는 OPUS collection에서 데이터를 선택해서 OPUS-100을 만들었습니다. OPUS-100은 100개의 언어로 구성되어 각 언어에 대해서 1M까지 데이터쌍이 있었으며, OPUS에서 이용가능한 병렬 데이터의 양에 기반하여 언어를 선택하였습니다.
데이터셋에 overlap 되는 train, test는 없었고, 학습 과정에서도 filter 를 계속 사용하여 업셍 만들었습니다.
6. Experiments
6.1 Setup
저자는 one - to many와 many to many 방식으로 번역 작업을 하였고, BPE를 통해 multilingual word를 다루었습니다. 평가 지표로는 BLEU 스코어를 사용하였고, langde-tect library를 통해서 zero shot case에의 언어 번역 정확도를 측정하였습니다. 각 언어쌍 별로 정확도를 제공하는거 보다는, 평균적인 BLEU 스코어를 94개의 언어에 대해서 평가하였습니다. 또한 win ratio, WR을 사용하여 baseline에 넘는 횟수를 counting 하였습니다.
기존의 MNMT에 벗어나서, 기본적인 baselines들은 bilingual NMT와 pivot-based translation을 포함시켰고, 각각 다른 4개의 target language의 typological을 추가시켰습니다.
6.2 Results on One-to-Many Translation
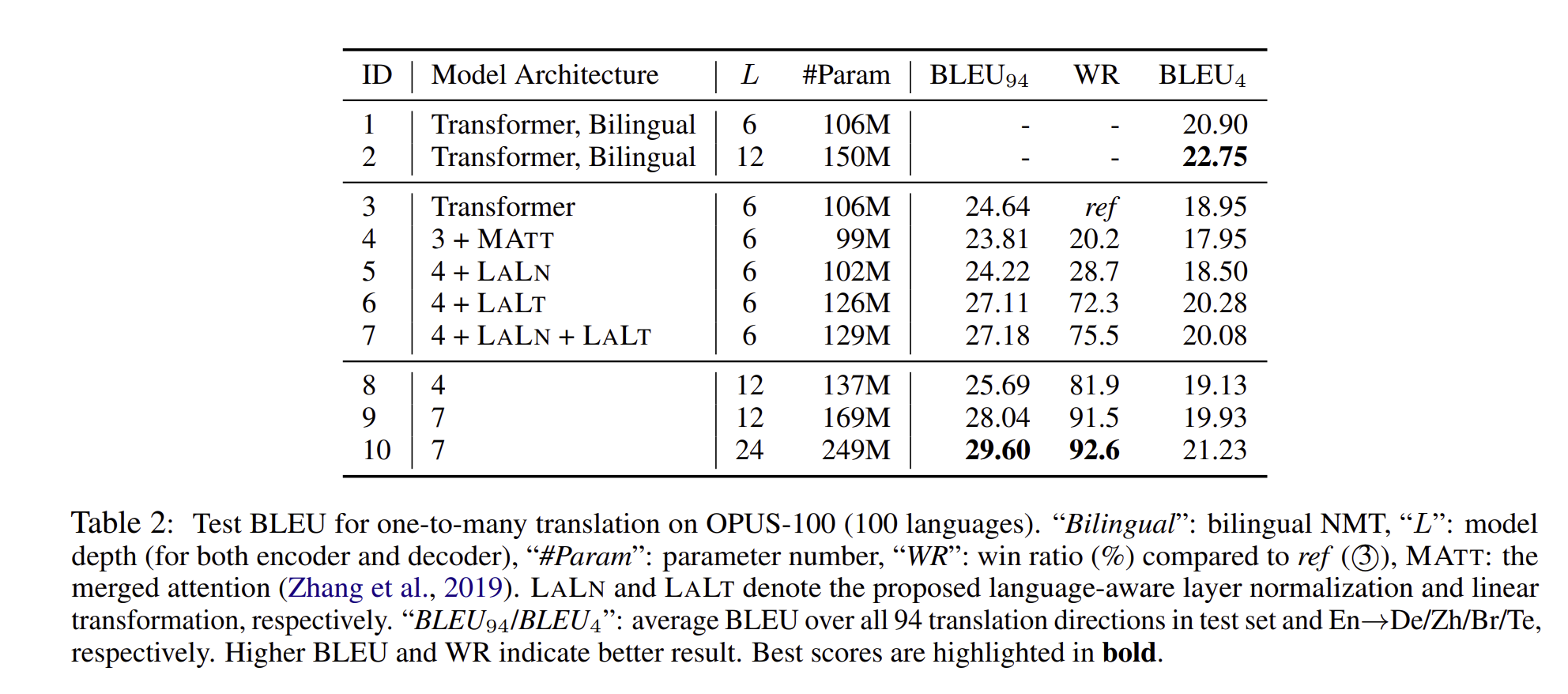
위 결과는 모델 결과를 요약한 표이다. ablation study(4-7)은 langauge awareness를 확장시키게 하니, 모델이 수용할 수 있는 문제를 완화시켜주었으며, normalization constraint를 relaxing 하니, BLEU 스코어와 WR 값들이 올라감을 확인할 수 있었습니다. 또한 모델을 더 깊게 만들니 (4→8) BLEU 점수가 늘어났다는 점을 볼 수 있습니다.
비록 deep Transformer가 LaLn + LaLt 모델 보다 더 낮은 성능을 냄에도 불구하고, WR 분야에서는 더 높은 점수를 보입니다. 그리하여 이런 점을 모두 통합하였을 때(10), 제일 높은 점수가 나오는 것을 확인할 수 있었습니다.
6.3 Results on Many-to-Many Translation
one-to-many dataset을 합쳐서 NMT 모델을 학습을 시켰습니다.
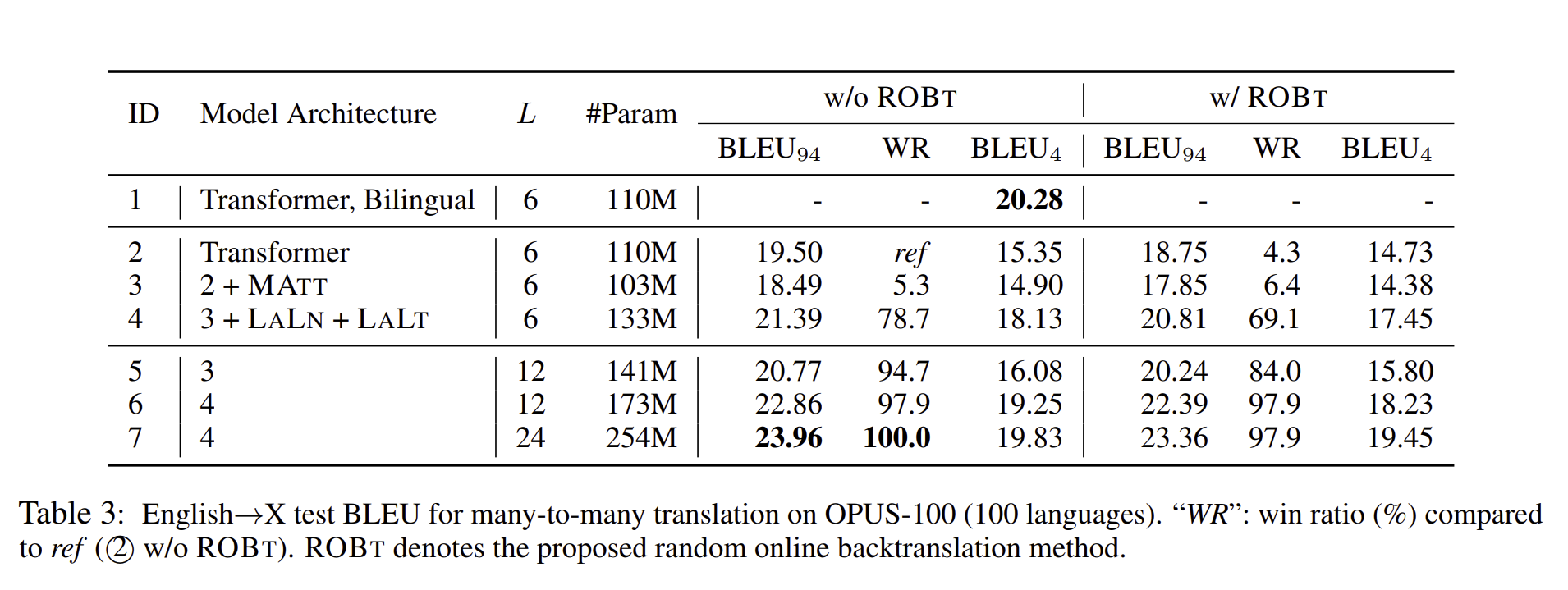
one-to-many translation과 비교를 해보면, many-to-many translation은 더 많은 번역 방향을 수용해야 하며, 이로 인해 다대다 모델은 심각한 용량 문제가 발생할 수 있습니다. 특히 영어에서 다른 언어(English →X)로의 번역 작업에서는 BLEU 점수가 매우 떨어집니다.
반면, LALN과 LALT 작업을 추가를 하니 BLUE 점수가 떨어지는 것을 크게 줄일 수 있었습니다.
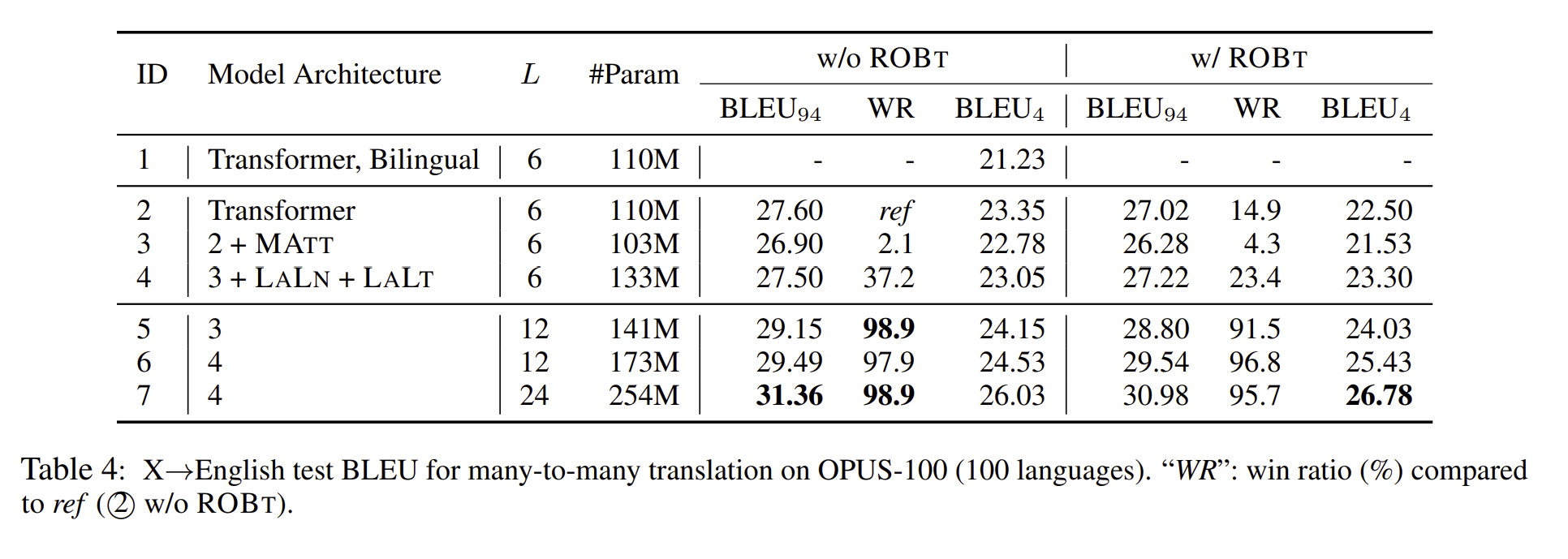
그리고 다언어학습 만으로도 다른 언어에서 영어로의 번역 성능이 굉장히 올라감을 확인할 수 있습니다.
위 두 사진의 성능 차이를 확인해보면, 영어에서 다른 언어로의 번역은 다른 언어에서 영어로의 번역보다 더 낮은 점수를 보입니다. 이는 훈련 데이터의 분포가 영어를 목표 언어로 사용하는 경우가 절반에 달하기 때문으로, 디코더가 영어로 번역하는 능력을 강화하고, 다른 언어에서 영어로의 transfer learning을 촉진시킵니다.
결과적으로, Transformer를 더 깊게 했다는 점, 그리고 LALN과 LALT를 추가로 하여 BLEU 점수가 더 많이 올랐다는 점을 보여줍니다.
6.4 Effect of Training Corpus Size
위 모델의 데이터셋은 전혀 공평하게 분포되어 있지 않습니다. 이는 충분히 knowledge transfer에 영향을 줄 수 있습니다. 그래서 저자는 OPUS-100의 다른 언어 쌍들을 그룹핑하여 이런 effect를 조사하였습니다. 3가지로 나누었는데, HIGH(≥0.9M), Low(< 0.1M), and Medium(others) 이렇게 3가지 구조로 나누었습니다.
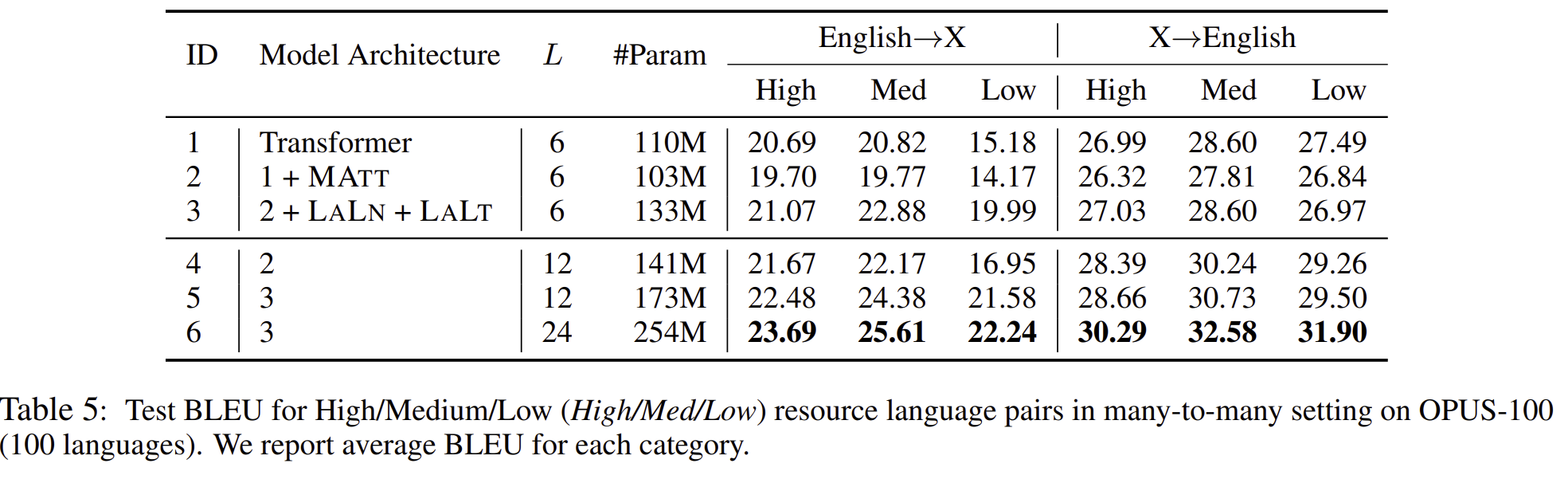
Language aware modeling은 low resource language pair에 특히 좋은 번역 효과를 보여주었습니다. 하지만 X→English 번역에서는 안좋은 경우를 보이기도 하였습니다.
deep Transformers는 비슷한 데이터셋에서 비슷한 결론을 내놓았습니다.
6.5 Results on Zero - shot Translation
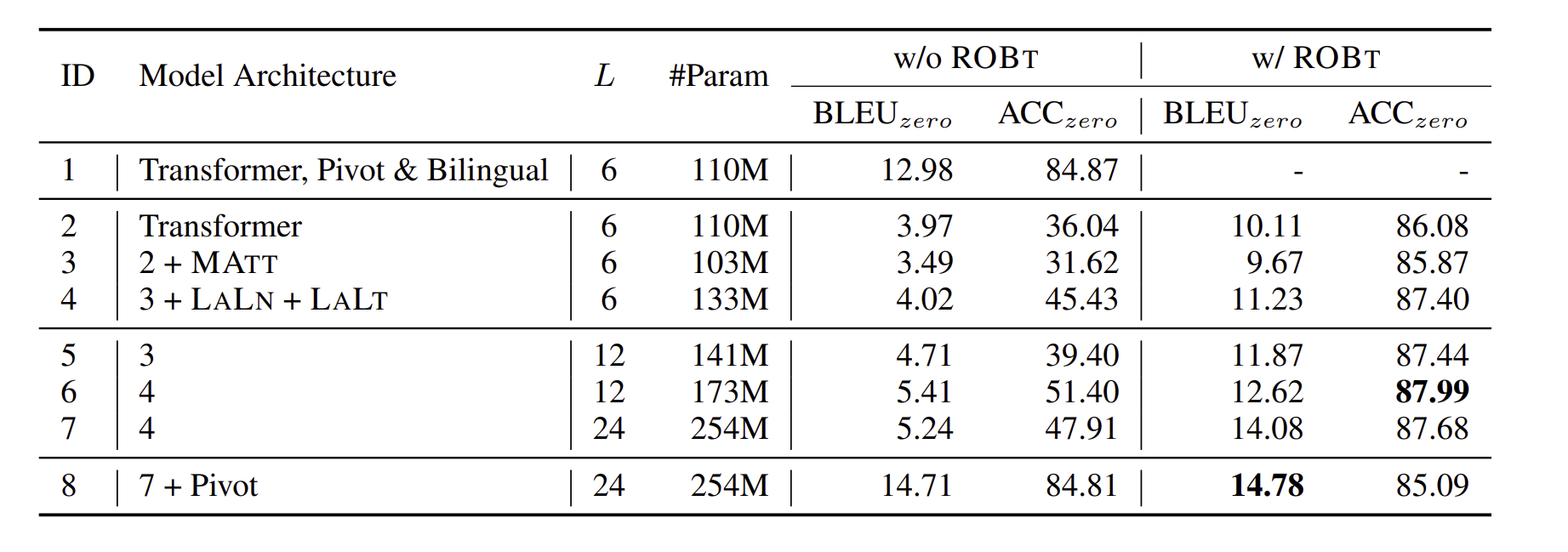
위 표를 보시면, pivot based bilingual baseline 점수보다 기존의 번역 점수(12.98)가 더 낮았음을 볼 수 있으며, 대부분의 점수가 3~5점인 것이 웃기다. ㅋㅋ 일단 바닐라 Transformer에서 점점 저자가 제안한 구조를 추가하면 점수가 늘어남을 확인해볼 수 있고, 모델의 수용량이 적어도 이는 모델의 성능에 주요한 문제가 아니라는 것을 볼 수 있습니다.
zero shot learning으로 학습된 NMT를 보게 되면, off target translation 문제가 발생하는 것을 볼 수 있었고, 특히 위 테이블에서는 ROBt 알고리즘이 적용 안된 acc와 pivot을 비교하면 48점 가까이 차이난다는 것을 볼 수 있습니다. 이는 즉, off -target translation이 zero shot learning의 성능을 저하시키는 하나의 문제라고도 볼 수 있습니다. 그리고 ROBt 알고리즘을 적용시킨 모델들은 대부분이 85~87퍼 사이의 정확도를 보인다는 점, BLEU score도 굉장히 높다는 것을 확인할 수 있습니다 .
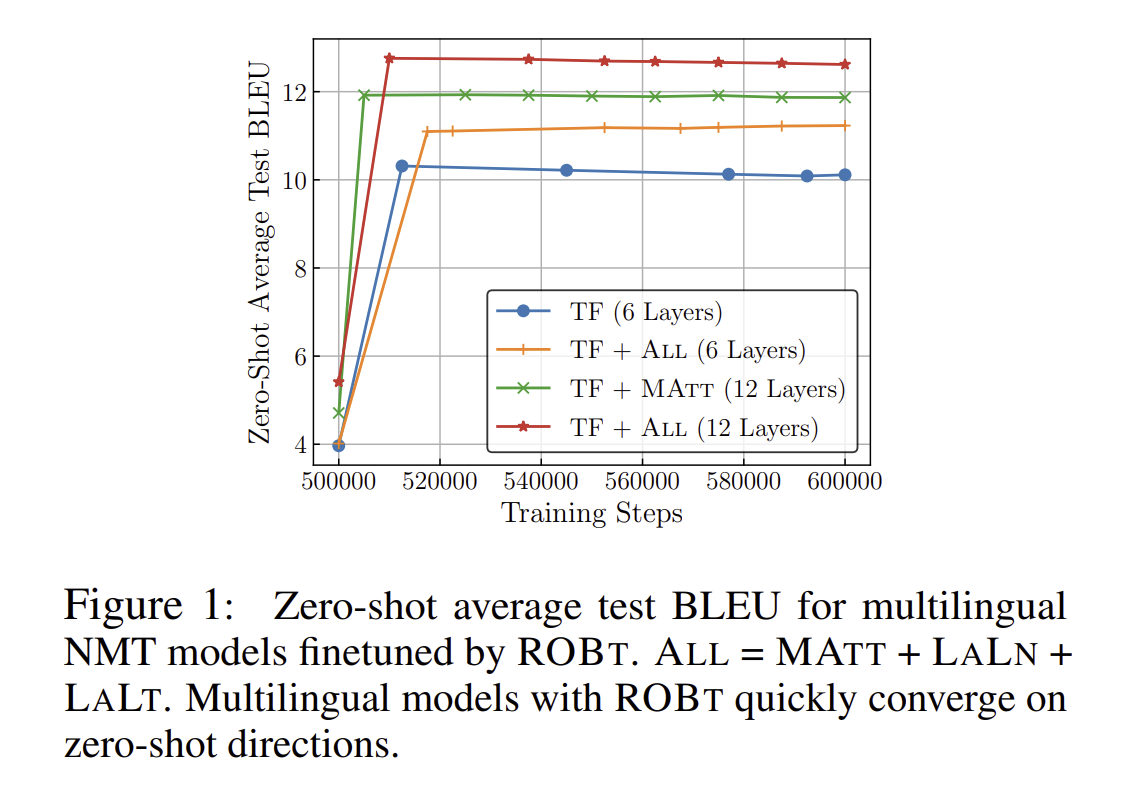
Traning step에서도 ROBt 방법은 매우 효율적인 방법이라는 점, 그리고 converge 하는데도 굉장히 빠른 속도를 보여줍니다. 이는 즉슨, 모든 training set의 언어쌍을 굳이 decode할 필요가 없다는 것을 의미합니다.

ROBT 모델은 목표 언어 집합(T)에 의존하여 제로샷 번역 방향에 모델량 용량을 분배합니다. 결과에서는 T를 6개 언어로 제한하여 ROBT의 성능 영향을 분석했습니다.결과적으로 T의 개수를 제한한 것이 ROBT를 기본 모델보다 0.75 BLEUzero 점수로 우수하게 만들었다는 것을 보여줍니다. 이는 제로샷의 방향의 수(번역을 할 때 사용하는 중간의 언어 개수)가 ROBT에 있어 가장 큰 제한 요소가 아닌 것을 말해줍니다.
한 줄로 요약하면?
ROBt인, 역번역의 과정을 통해서 NMNT가 엄청나게 큰 데이터셋을 잘 흡수할 수 있게 되었고, off target과 같은 문제점이 해결이 되었습니다.
