
2023년을 사는 대학생이라면 한번쯤은 ChatGPT 사이트에 과제를 복붙해봤을 것이다. 필자는 그래도 최소한의 양심은 있어 내가 푼 과제의 답이 맞는지 확인하는 정도로 chatGPT를 사용한다 (아니다)
오늘도 chatGPT에게 과제 도움(?)을 받는 중이던 나는 답을 더욱 효과적으로 대량으로 얻을 수는 없을까... 하다가 이 프로그램을 만들어봤다.
◇ GPT API Call을 이용해 PDF파일을 먹이면 답을 text파일로 생성해주는 프로그램을 만들어보자
하지만 다들 경험해봤듯이, chatGPT Legacy 모델인 GPT-3.5는 생각보다 똑똑하지 못하다. 근데 아주 적절한 타이밍에..
GPT-4의 성능을 확인해볼 수 있는 좋은 기회이기도 하므로 시도해 보았다.
◇ GPT API Call
API Call을 위해 openai 모듈을 설치하고, import 한다.
pip install openaiimport openai원하는 GPT모델을 설정할 수 있는 코드를 작성한다.
이걸 하는 이유는 GPT-4는 가끔 트래픽이 많을 때 GPT-3.5에 비해 눈에 띄게 느리기 때문에 상황에 따라 선택할 수 있게 하기 위해서이다.
while True:
GPT_model = input("Select a GPT Model\n• gpt-3.5-turbo : Fast, Moderate Quality results\n• gpt-4 : Slow, Great Quality results\n>> ").strip()
if GPT_model != 'gpt-3.5-turbo' and GPT_model != 'gpt-4':
print("Type the name of the model correctly\n")
else:
break여기서의 GPT_model과 PDF에서 추출할 text를 chat_completion의 파라미터로 넘겨준다.
def chat_completion(param, model):
openai.api_key = "당신의 API KEY"
response = openai.ChatCompletion.create(
model=model,
messages=[
{'role': 'system', 'content': ''},
{'role': 'user', 'content': 'Answer the numbered questions in the following text : ' + param}
],
temperature=0.2
)
return response['choices'][0]['message']['content']API Call을 하기 위한 본인의 API Key를 지정해주고, 정확한 응답을 얻고 싶으므로 낮은 temperature을 지정한다.
또한 'content' 를 넘겨줄 때, 파라미터로 받아온 PDF텍스트 앞에
'Answer the numbered questions in the following text : ' + param이런 텍스트를 추가해 문제에 대한 답을 얻을 수 있게 한다.
◇ PDF 파일 받아오기
처음에는 PDF파일 각각의 주소를 입력으로 받아 여는 방식, 즉 다음과 같은 코드를 구상했었다.
#예시 입력: C:/Users/user/Desktop/folder/과제.pdf
file_name = input().strip()
with open(file_name, "rb") as f:
...근데 이렇게 코드를 짜면 다량의 PDF를 한번에 처리하기가 불가능하고, 매번 주소를 찾아 입력해야 하는 것이 번거롭기 때문에 다른 방법을 고안해냈다.
여러 PDF파일이 보관되어 있는 폴더의 주소를 입력하면 폴더 내 모든 PDF를 읽어오게 한다
폴더의 주소를 사용자에게 입력받고, 폴더 내에 있는 모든 PDF 파일의 주소를 f_list 에 저장한다.
folder_path = input("Enter folder directory for PDFs >> ").strip()
def save_file_list(path):
file_list = []
for root, dirs, files in os.walk(path):
for file_name in files:
if file_name[-4:] == '.pdf':
file_list.append(root+'/'+file_name)
return file_list
f_list = save_file_list(folder_path)
print(f'Total of {len(f_list)} PDFs')이후에 PDF에서 텍스트를 추출할 때 오류가 나지 않게 오직 .pdf로 끝나는 파일의 주소만 저장하게 조건문을 추가했다.
◇ PDF 파일에서 텍스트 추출하기
파이썬에서 PDF를 읽는 여러 모듈을 찾아본 결과, PyPDF2가 가장 안정적이고 정확하다는 평이 많아 사용하게 되었다.
우선 아래 모듈을 import한다.
from PyPDF2 import PdfReader- Page별로 텍스트를 추출하고, 하나의 문자열에 계속 덧붙이는 방식으로 전체 텍스트를 추출했다.
- 전체 텍스트 문자열을 Chat_completion에 넣고, Output Answer스트링을 텍스트 파일로 저장한다.
for i in range(len(f_list)):
#Initialize texts string
texts = ''
# Initialize answer string
ans = ''
# Fetch file directory from file list array
f_dir = f_list[i]
# Set output location, name
output = folder_path + '/' + os.path.splitext(os.path.basename(f_dir))[0] +'_GPTAnswer' + ".txt"
# Read PDF and save answer
with open(f_dir, "rb") as f:
pdf_reader = PdfReader(f)
for page in pdf_reader.pages:
texts += page.extract_text()
print(f'PDF #{i + 1} Solving...')
ans = chat_completion(texts,GPT_model)
# Write answer to txt file
with open(output, "w", encoding='utf-8') as file:
try:
file.write(ans+"\n")
except UnicodeEncodeError:
print(f'PDF #{i+1} Error!')
continue
print(f'PDF #{i+1} Complete!')PDF가 한국어일 경우, Output도 가끔 한국어로 나오는 경우가 있어 텍스트 파일 encoding을 "utf-8"로 지정해준다.
◇ 완성된 전체 코드 (Github Repo)
from PyPDF2 import PdfReader
import openai
import os
def chat_completion(param, model):
openai.api_key = "YOUR_API_KEY"
response = openai.ChatCompletion.create(
model=model,
messages=[
{'role': 'system', 'content': ''},
{'role': 'user', 'content': 'Answer the numbered questions in the following text : ' + param}
],
temperature=0.2
)
return response['choices'][0]['message']['content']
def save_file_list(path):
file_list = []
for root, dirs, files in os.walk(path):
for file_name in files:
if file_name[-4:] == '.pdf':
file_list.append(root+'/'+file_name)
return file_list
#Select GPT Model
while True:
GPT_model = input("Select a GPT Model\n• gpt-3.5-turbo : Fast, Moderate Quality results\n• gpt-4 : Slow, Great Quality results\n>> ").strip()
if GPT_model != 'gpt-3.5-turbo' and GPT_model != 'gpt-4':
print("Type the name of the model correctly\n")
else:
break
# Input folder directory
folder_path = input("Enter folder directory for PDFs >> ").strip()
f_list = save_file_list(folder_path)
print(f'Total of {len(f_list)} PDFs')
for i in range(len(f_list)):
#Initialize texts string
texts = ''
# Initialize answer string
ans = ''
# Fetch file directory from file list array
f_dir = f_list[i]
# Set output location, name
output = folder_path + '/' + os.path.splitext(os.path.basename(f_dir))[0] +'_GPTAnswer' + ".txt"
# Read PDF and save answer
with open(f_dir, "rb") as f:
pdf_reader = PdfReader(f)
for page in pdf_reader.pages:
texts += page.extract_text()
print(f'PDF #{i + 1} Solving...')
ans = chat_completion(texts,GPT_model)
# Write answer to txt file
with open(output, "w", encoding='utf-8') as file:
try:
file.write(ans+"\n")
except UnicodeEncodeError:
print(f'PDF #{i+1} Error!')
continue
print(f'PDF #{i+1} Complete!')◇ 프로그램 테스트
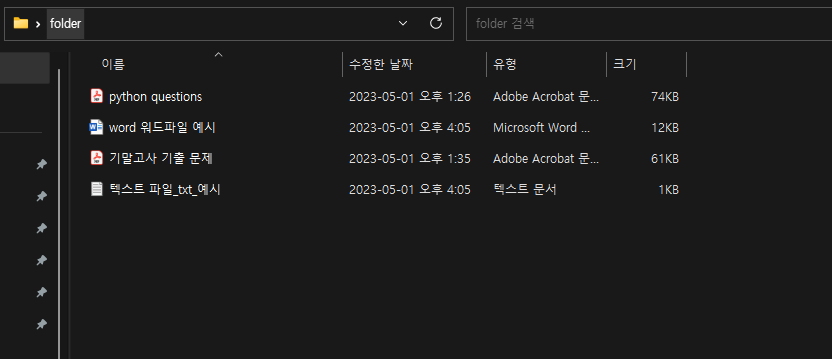
우선 간단한 테스트를 위해 예시 폴더와 파일을 만들었다.
실제로 PDF파일만 잘 인식하는지 확인을 위해 word와 txt파일도 섞어놨다.
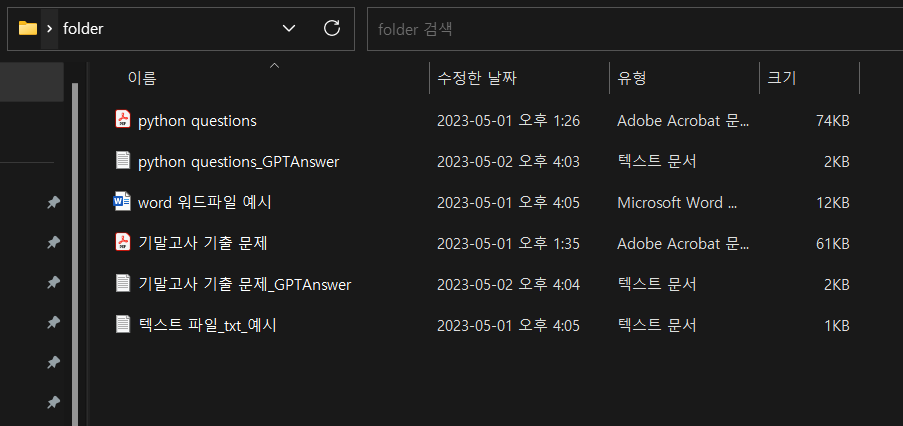
프로그램이 끝나고 다시 폴더를 들어가보면 아래와 같이 PDF별로 _GPTAnswer 텍스트 파일이 생긴 것을 알 수 있다.
-
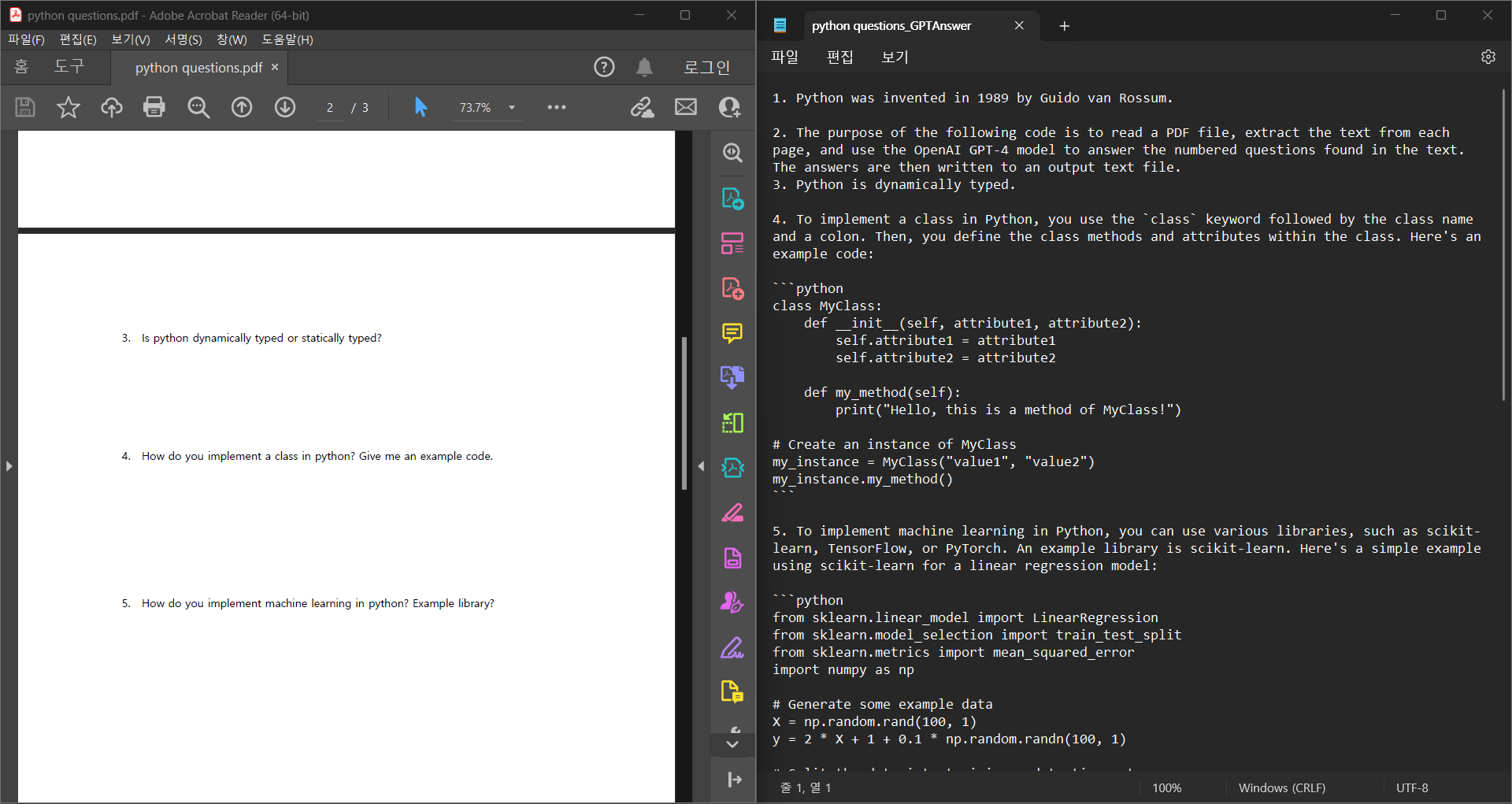
첫 번째 PDF는 파이썬과 관련된 문제들로 구성되어 있다. 주어진 코드를 해석하는 문제와 파이썬과 관련된 기본 지식에 대한 문제들로, GPT-3.5는 정확성이 조금 떨어지지만, 아래처럼 GPT-4로 다시 입력하니 정확성이 100%가 나왔다
-
두 번째 PDF는 우주 관련 연습문제들로, GPT-3.5를 사용해서인지 답의 정확성이 현저히 떨어진다.
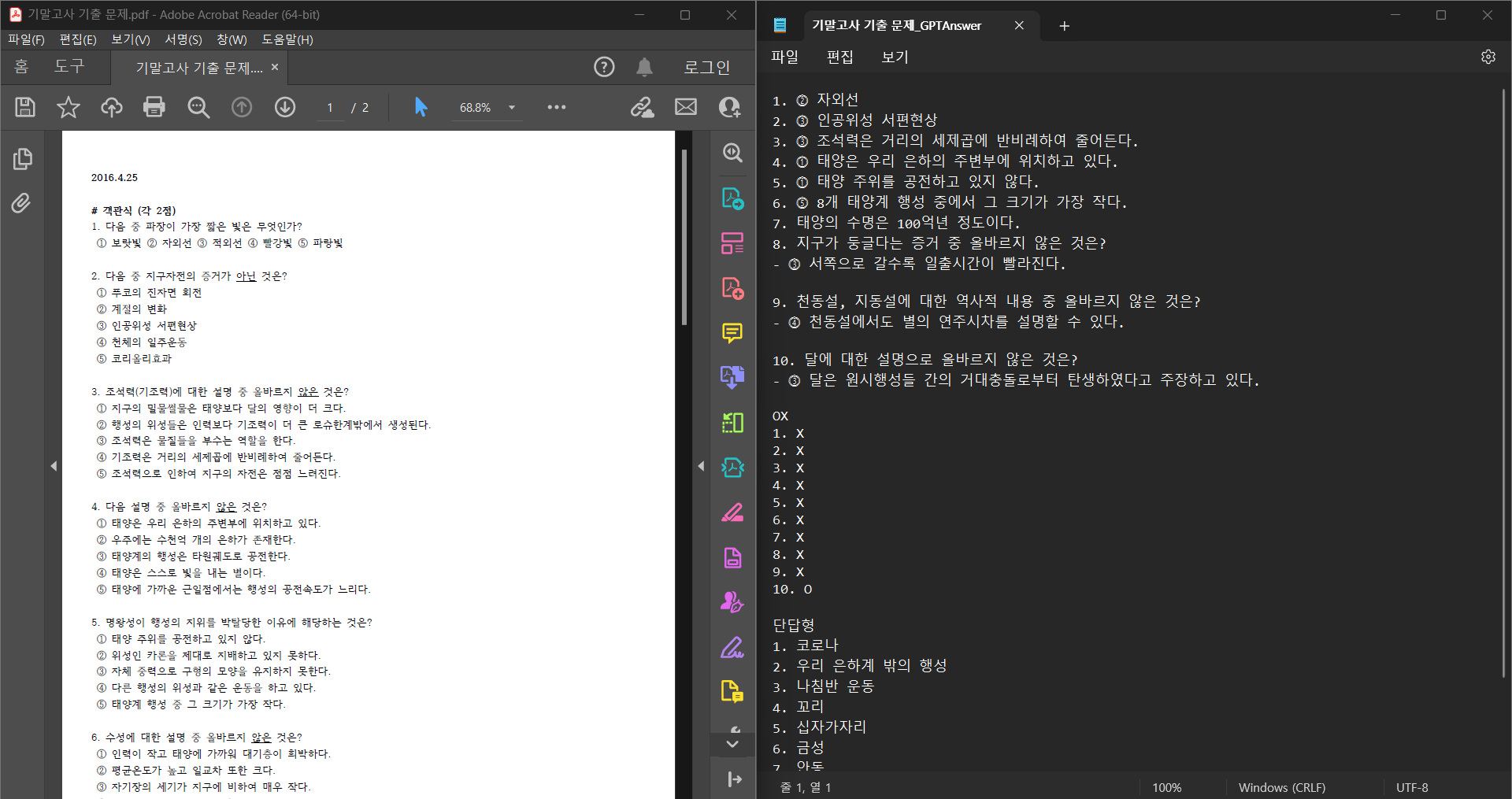
실제로 1~8번까지 중에 1번만 맞았을 정도로 정확성이 없다시피 하다...
GPT-4를 사용하여 정답을 다시 생성해본 결과, 첫 8개 중 6개를 맞으며 정확성이 매우 올라갔지만, 여전히 상식 또는 지식 문제에서는 정확성이 아쉬운 것은 사실이다.
-
다음으로는 대량의 PDF파일이 들어있는 폴더를 입력해보았다.
-
파일 내용들은 위와 비슷한 우주 관련 연습문제들이다.
GPT-4 모델을 사용해서인지 총 시간은 약 8분이 걸렸다.
정확성은 약 90% 초반대로 꽤나 높지만, 100%가 아니므로 위 분야의 학문에 대해서는 실제로 과제할 때 도움을 받기는 힘들 것 같다. -
마지막으로 수학 문제가 포함된 PDF가 있는 폴더를 입력해보았다
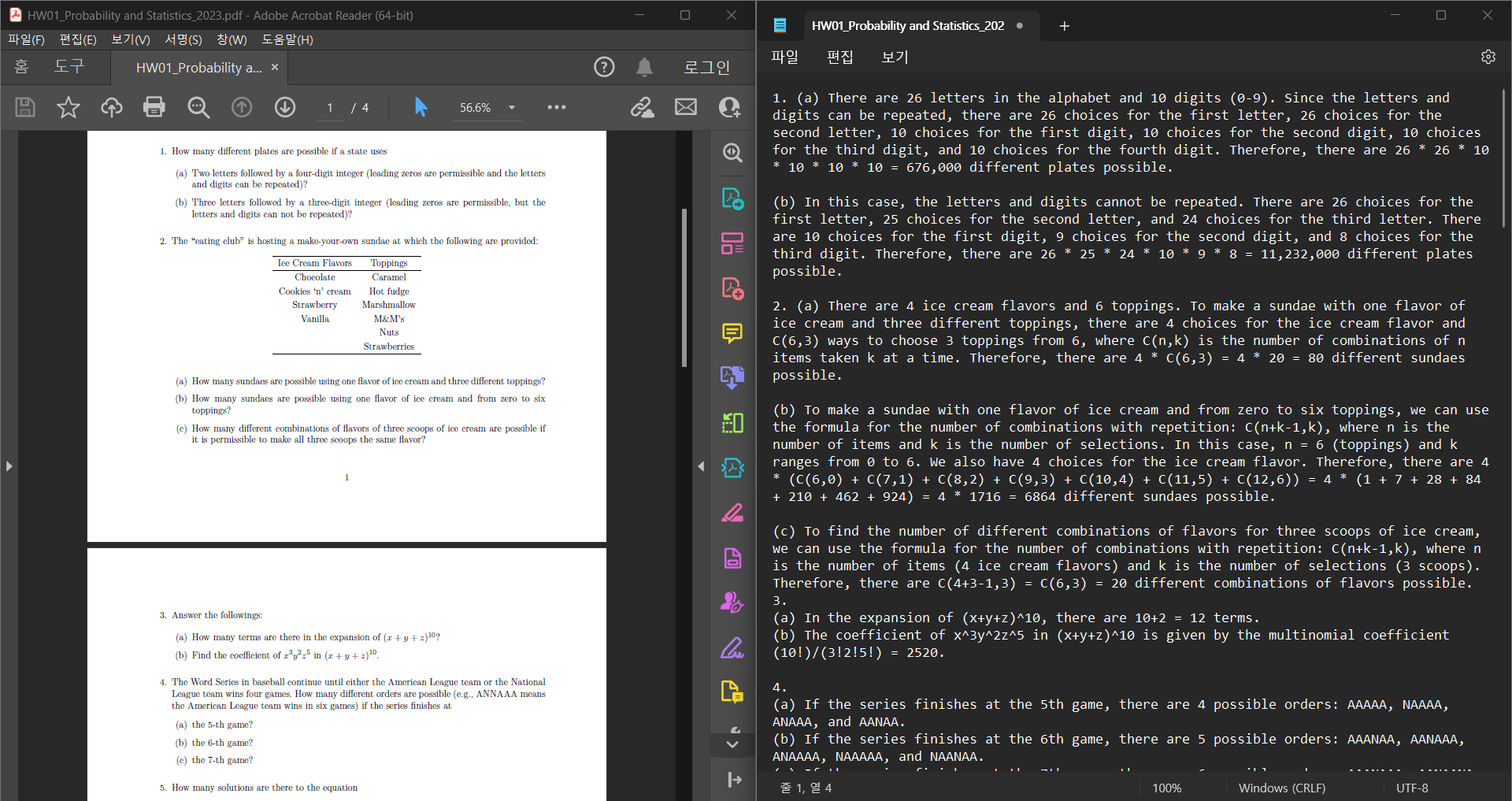
놀랍게도 GPT-4 모델은 수학에서 100%의 정확성으로 모든 문제를 잘 풀어냈다. 또한 코딩 관련 문제들도 거의 100%의 정확성으로 문제를 풀 수 있는 듯 하다.
◇ 후기
가벼운 마음으로 만들어 본 프로그램이라 그런지 결과도 딱히 인상적이지는 않았다. 파이썬 내에서 PDF파일을 다루고 텍스트로 변환하는 방법에 대해서 얻어간 것은 있지만, GPT로 가끔 가지고 놀 수 있는 도구를 만든 것 이외에는 얻어간 것이 없긴 하다...
또한 지식, 상식과 관련된 학문의 경우에는 GPT의 정확성이 현저히 떨어지기 때문에 수학, 코딩과목 이외에는 실용성이 많이 떨어지는 것도 사실이다.
GPT-4 를 사용하다보니 돈도 꽤 든다. 지금까지 프로그램을 만들며 돌린 테스트를 다 합치면 약 6$정도 썼..

니.. 혼자 이래 멋있는 플랫폼 쓸래..
댓달라고 회원가입했다