강의실 오면서 현재 루틴 계산해 봄
7시 30분 기상
7시 50분 강의실 입실
8시 00분 공부 시작
점심, 저녁 식사 각각 1시간씩 소모
23시 00분 강의실 퇴실
강의실 재실 시간: 13시간
휴식 시간: 1시간
하루 학습 시간 12시간
6일 학습 시간 12 x 6 = 72시간
7일 학습 시간 12 x 7 = 84시간
결론: 주당 100시간에 한참 모자르다.
(루틴을 개선할 필요가 있음)
자료구조
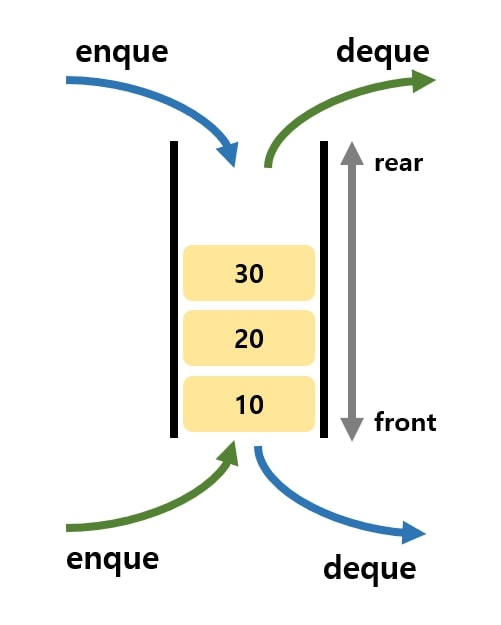
큐(queue)
(스태과 마찬가지로) 데이터를 임시 저장하는 자료구조
선입입선출(FIFO, First In First Out)
용어 정리
인큐(enqueue): 데이터를 추가하는 작업 ('밀어넣기'라고도 함)
디큐(dequeue): 데이터를 꺼내는 작업
프론트(front): 데이터를 꺼내는 쪽
리어(rear): 데이터를 넣는 쪽
큐는 공항에서 체크인 할 때 줄 서는 거 생각!
입구(리어)로 들어가서 출구(프론트)로 나간다!
처리 복잡도
인큐: O(1) > 끝에 그냥 집어넣으면 됨
디큐: O(n) > 하나를 꺼내고, 나머지를 각각 한칸씩 앞으로 땡겨야 함
(참고)우선순위 큐
인큐할 때 데이터에 우선 순위 부여
디큐할 때 우선순위 높은 데이터를 꺼냄
(파이썬에서 heapq 모듈에서 제공)
우선순위큐 인큐: heapq.heappush(heap, data)
우선순위큐 디큐: heapq.heappop(heap)
우선 순위 큐도 hands on으로 구현해 보자!
(우선 순위 큐를 구현하려면 heap을 알아야 함)
그럼 heap을 알아보자!(하단)
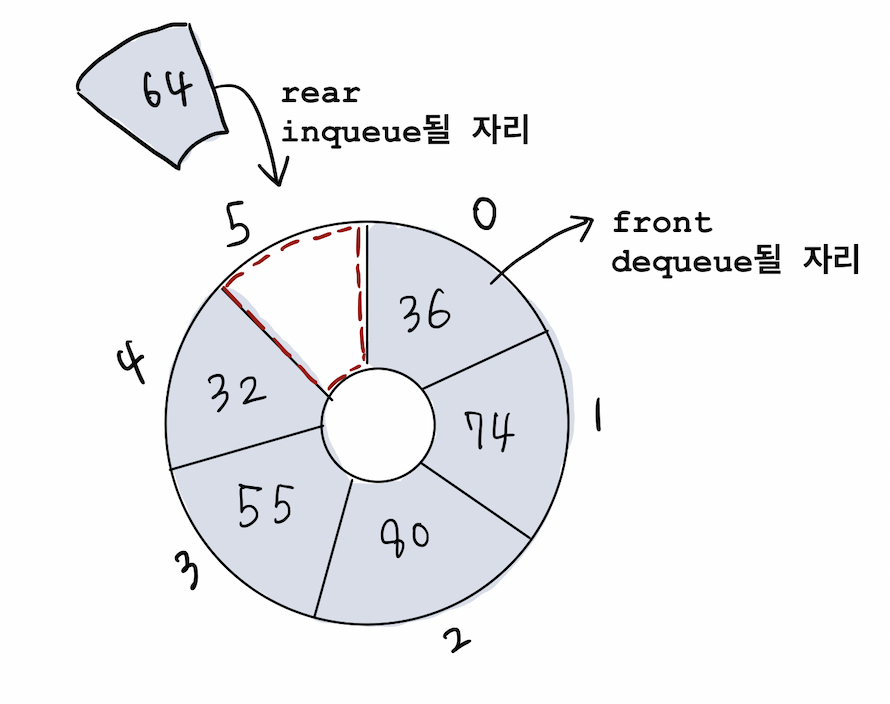
링 버퍼로 큐 구현하기
디큐 이후에 배열 안의 원소를 옮기지 않는 큐
**링 버퍼는 디큐 후에 모든 원소를 옮길 필요 없이 front와 rear값을 업데이트만 하면 된다.
따라서 디큐를 할 때도 처리 복잡도는 O(1)이다.
링 버퍼자료구조란?
배열의 처음과 끝이 연결되어 있다고 보는 자료 구조
맨 앞과 맨 끝의 원소를 식별하기 위해front,rear변수를 사용함.
버퍼란?
데이터를 한 곳에서 다른 한 곳으로 전송하는 동안 일시적으로 데이터를 보관하는 메모리 영역**
'버퍼링'이라는 말이 여기서 나왔음.
버퍼링: 버퍼를 활용하는 방식이나 버퍼를 채우는 동작
(북한말로 버퍼를 '완충기억기'라고 함)
파이썬으로 큐 구현(Hands On)
from typing import Any
class FixedQueue:
class Empty(Exception):
"""비어 있는 FixedQueue에서 디큐 또는 피크할 때 내보내는 예외 처리"""
pass
class Full(Exception):
"""가득 차 있는 FixedQueu에서 인큐할 때 내보내는 예외 처리"""
pass
def __init__(self, capacity: int) -> None:
"""큐 초기화"""
self.no = 0 # 현재 데이터 개수
self.front = 0 # 맨 앞 원소 커서
self.rear = 0 # 맨 끝 원소 커서
self.capacity = capacity # 큐의 크기
self.que = [None] * capacity # 큐의 본체
def __len__(self) -> int:
"""큐에 있는 모든 데이터 개수를 반환"""
return self.no
def is_empty(self) -> bool:
return self.no <= 0
def is_full(self) -> bool:
return self.no >= self.capacity
def enque(self, x: Any) -> None:
"""데이터 x를 인큐"""
if self.is_full():
raise FixedQueue.Full # 큐가 가득 차 있는 경우 예외 처리 발생
self.que[self.rear] = x
self.rear += 1
self.no += 1
if self.rear == self.capacity:
self.rear = 0
def deque(self) -> Any:
"""데이터를 디큐"""
if self.is_empty():
raise FixedQueue.Empty # 큐가 비어 있는 경우 예외 처리 발생
x = self.que[self.front]
self.front += 1
self.no -= 1
if self.front == self.capacity:
self.front = 0
return x
def peek(self) -> Any:
"""큐에서 데이터를 피크(맨 앞 데이터를 들어다봄)"""
if self.is_empty():
raise FixedQueue.Empty # 큐가 비어 있는 경우 예외 처리를 발생
return self.que[self.front]
def find(self, value: Any) -> Any:
"""큐에서 value를 찾아 인덱스를 반환(없으면 -1을 반환)"""
for i in range(self.no):
idx = (i + self.front) % self.capacity # 검색 성공
if self.que[idx] == value:
return idx
return -1 # 검색 실패
def count(self, value: Any) -> int:
"""큐에 있는 value의 개수를 반환"""
c = 0
for i in range(self.no): # 큐 데이터를 선형 검색
idx = (i + self.front) % self.capacity
if self.que[idx] == value: # 검색 성공
c += 1
return c
def __contains__(self, value: Any) -> bool:
"""큐에 value가 있는지 판단"""
return self.count(value)
def clear(self) -> None:
"""큐의 모든 데이터를 비움"""
self.no = self.front = self.rear = 0
def dump(self) -> None:
"""모든 데이터를 맨 앞부터 맨 끝 순서로 출력"""
if self.is_empty(): # 큐가 비어있음
print("큐가 비었습니다.")
else:
for i in range(self.no):
print(self.que[(i + self.front) % self.capacity], end=' ')
print()
que.enque(10)
que.enque(7)
que.enque(2)
que.enque(2)
que.enque(2)
print(que.is_empty())
print(que.is_full())
print(que.peek())
print(que.find(10))
print(que.deque())
print(que.count(2))
print(que.dump())
print(que.clear())
print(que.dump())파이썬 배열로 큐 자료구조 구현해 봄!
(참고)양방향 대기열 덱
덱(deque, Double Ended Queue)
맨 앞과 맨 끝 양쪽에서 데이터를 넣고 꺼낼 수 있는 자료 구조
(프론트와 리어에서 인큐와 디큐가 각각 가능)
파이썬에서 collections.deque 컨테이너로 제공
큐와 스택을 합친 형태
큐를 사용한 프로그램 제작(hand on)
from enum import Enum
from fixed_queue import FixedQueue
Menu = Enum('Mune', ['인큐', '디큐', '피크', '검색', '덤프', '종료'])
def select_menu() -> Menu:
"""메뉴 선택"""
s = [f'({m.value}){m.name}' for m in Menu]
while True:
print(*s, sep=' ', end='')
n = int(input(': '))
if 1 <= n <= len(Menu):
return Menu(n)
q = FixedQueue(64)
while True:
print(f'현태 데이터 개수: {len(q)} / {q.capacity}')
menu = select_menu() # 메뉴 선택
if menu == Menu.인큐: # 인큐
x = int(input('인큐할 데이터를 입력하세요.: '))
try:
q.enque(x)
except FixedQueue.Full:
print('큐가 가득 찼습니다.')
elif menu == Menu.디큐:
try:
x = q.deque()
print(f'디큐한 데이터는 {x}입니다.')
except FixedQueue.Empty:
print('큐가 비어 있습니다.')
elif menu == Menu.피크:
try:
x = q.peek()
print(f'피크한 데이터는 {x}입니다.')
except FixedQueue.Empty:
print('큐가 비었습니다.')
elif menu == Menu.검색:
x = int(input('검색할 값을 입력하세요: '))
if x in q:
print(f'{q.count(x)}개 포함되고, 맨 앞의 위치는 {q.find(x)}입니다.')
else:
print('검색값을 찾을 수 없습니다.')
elif menu == Menu.덤프:
q.dump()
else:
break링 버퍼 구현하기
오래된 데이터를 버리는 용도로 사용
(버퍼가 가득 찬 상황에서 새로운 데이터가 인큐되면 마지막 원소에 덮어씌움)
n = int(input('정수를 몇 개 저장할까요?: '))
a = [None] * n
cnt = 0
while True:
a[cnt % n] = int(input((f'{cnt + 1}번째 정수를 입력하세요.: ')))
cnt += 1
retry = input(f'계속 할까요?(Y ... Yes / N ... No): ')
if retry in {'N', 'n'}:
break
i = cnt - n
if i < 0: i = 0
while i < cnt:
print(f'{i + 1}번째 = a{a[i % n]}')
i += 1
파이썬 Enum
열거형을 정의
enumeration(특정 값들의 집합을 정의할 때 사용)
Enum(열거형의 이름, 열거형 멤버의 이름을 리스트 형태로 제공
Enum('Mune', ['인큐', '디큐', '피크', '검색', '덤프', '종료'])
# 클래스로 사용
from enum import Enum
class Color(Enum):
RED = 1
GREEN = 2
BLUE = 3
print(Color.RED) # 출력: Color.RED
print(Color.RED.value) # 출력: 1파이썬 enumerat()
iter객체를 (0, iter[0]), (1, iter[1]) ... 형식으로 반환
리스트나 튜플 같은 순회 가능한 객체를 인데스와 값을 함께 사용할 때 활용
fruits = ["apple", "banana", "mango"]
for index, value in enumerate(fruits):
print(index, value)1시간 고민해서 11866 요세푸스(하) 풀었음!
내가 푼 방식(큐(덱)를 활용하지 않음)
N, K = map(int, input().split())
nums = [num for num in range(1, N+1)]
eliminated = []
idx = -1
while len(order) < N:
count = 0
while True:
idx = (idx + 1) % N
if nums[idx] != 0:
count += 1
if count == K:
eliminated.append(nums[idx])
nums[idx] = 0
break
print(str(eliminated).replace("[", "<").replace("]", ">"))큐(덱)를 활용한 방식
from collections import deque
queue = deque()
answer = []
N, K = map(int, input().split())
for i in range(1, N+1):
queue.append(i)
while queue:
for i in range(K-1):
queue.append(queue.popleft())
answer.append(queue.popleft())
print(str(answer).replace("[", "<").replace("]", ">"))파이썬 deque 연습을 많이 해 봐야겠다.
deque적 사고(?)에 익숙해지기!
파이썬 deque 정리
# 정리 대기우선 순위 큐
우선 순위 큐는 일반적으로 힙(heap)으로 구현
힙 공부한 다음에 다시 정리
Heap
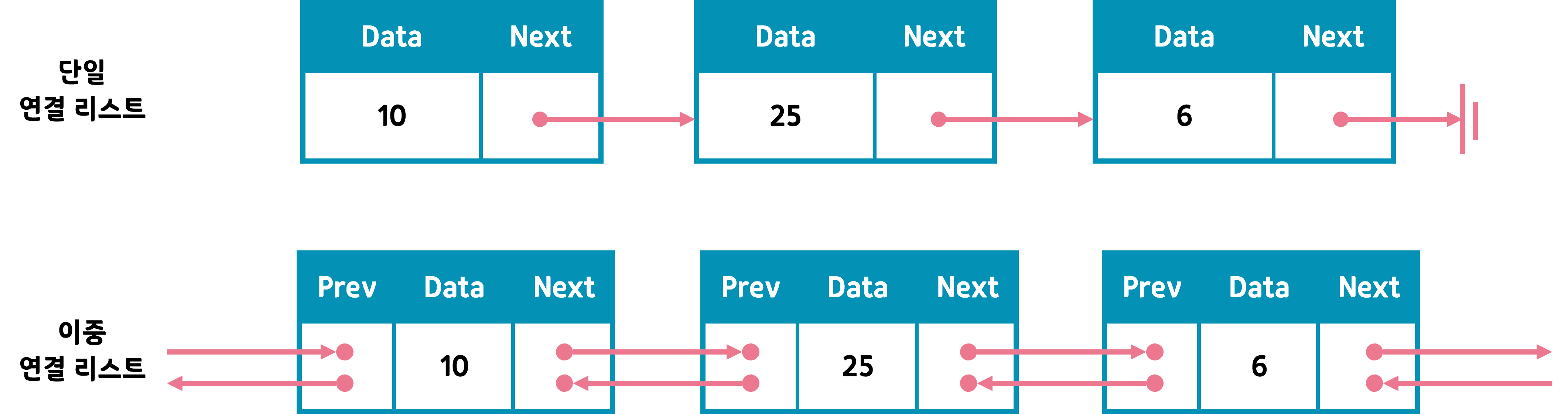
연결 리스트(linked list)
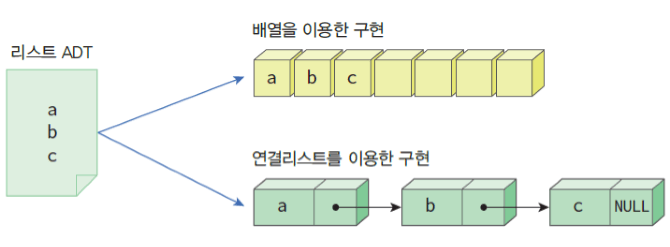
리스트 자료 구조 중 하나
리스트: 순서가 있는 데이터를 늘어놓은 자료구조
큐, 스택도 일종의 리스트 자료구조
(파이썬의 '리스트'와는 다른 개념임)
연결 리스트의 구성
연결 리스트는 노드로 구성 되어 있음
노드: 연결 리스트를 구성하는 원소
데이터: 해당 노드의 값(데이터 자체가 아니라 참조 값임!)
포인터: 다음 노드를 가리키는 값(다음 노드 자체가 아니라 참조 값임!)
머리 노드(head node): 맨 앞에 있는 노드
꼬리 노드(tail node): 맨 끝에 있는 노드
앞쪽 노드(predecessor node): 각 노드 바로 앞에 있는 노드
뒤쪽 노드(successor node): 각 노드 바로 뒤에 있는 노드
단순 배열로 포인터가 없는 리스트를 구현할 수 있지만 비효율적(이건 사실상 배열임)
자기 참조형
자신과 같은 형의 인스턴스를 참조하는 필드가 있는 구조
(참조하는 다음 노드가 자기랑 같은 자료형인 경우)
연결 리스트 왜 쓰나?
원소 삽입, 삭제할 때 빠름(포인터만 바꿔주면 되니까)
(배열은 삽입, 삭제 시 모든 원소를 이동시켜야 되는 문제 있음)
메모리, 속도 면에서는 배열보다 효율 낮음(선형 검색)
(기본적으로 포인터를 저장해야 됨, 순차 접근 해야 됨)
파이썬으로 연결 리스트 hands on
# 포인터로 연결 리스트 구현
from __future__ import annotations
from typing import Any, Type
class Node:
"""연결 리스트용 노드 클래스"""
def __init__(self, data: Any = None, next: Node = None):
"""초기화"""
self.data = data
self.next = next
class LinkedList:
"""연결 리스트 클래스"""
def __init__(self) -> None:
"""초기화"""
self.no = 0
self.head = None
self.current = None
def __len__(self) -> int:
"""연결 리스트의 노드 개수를 반환"""
return self.no
def search(self, data: Any) -> int:
"""data와 값이 같은 노드를 검색"""
cnt = 0
ptr = self.head
while ptr is not None:
if ptr.data == data:
self.current = ptr
return cnt
cnt += 1
ptr = ptr.next
return -1
def __contains__(self, data: Any) -> bool:
"""연결 리스트에 data가 포함되어 있는지 확인"""
return self.search(data) >= 0
def add_first(self, data: Any) -> None:
"""맨 앞에 노드를 삽입"""
ptr = self.head # 삽입하기 전의 머리 노드
self.head = self.current = Node(data, ptr) # head와 current에 같은 값을 할당
self.no += 1
def add_last(self, data: Any):
"""맨 끝에 노드를 삽입"""
if self.head is None:
self.add_first(data)
else:
ptr = self.head
while ptr.next is not None:
ptr = ptr.next
# current는 최근 활성화된 노드라고 생각하기
ptr.next = self.current = Node(data, None)
self.no += 1
def remove_first(self) -> None:
"""머리 노드를 삭제"""
if self.head is not None: # 리스트가 비어 있지 않다면
self.head = self.current = self.head.next
self.no -= 1
# 꼬리 노드를 삭제하려면 삭제 후에 꼬리가 될 노드(pre)를 찾아야 됨
def remove_last(self):
"""꼬리 노드를 삭제"""
if self.head is not None:
if self.head.next is None: # 노드가 1개 뿐이라면
self.remove_first # 머리 노드를 삭제
else:
ptr = self.head # 스캔 중인 노드
pre = self.head # 스캔 중인 노드의 앞쪽 노드
while ptr.next is not None:
pre = ptr
ptr = ptr.next
pre.next = None # pre는 삭제 뒤 꼬리 노드
self.current = pre
self.no -= 1
def remove(self, p: Node) -> None:
"""노드 p를 삭제"""
if self.head is not None:
if p is self.head:
self.remove_first() # p가 머리 노드이면
else:
ptr = self.head
while ptr.next is not p:
ptr = ptr.next
if ptr is None:
return # ptr은 리스트에 존재하지 않음
ptr.next = p.next
self.current = ptr
self.no -= 1
def remove_current_node(self) -> None:
"""주목 노드를 삭제"""
while self.head is not None: # 전체가 비어 있을 때까지
self.remove_first() # 머리 노드를 삭제
self.current = None
self.no = 0
def next(self) -> bool:
"""주목 노드를 한 칸 뒤로 이동"""
if self.current is None or self.current.next is None:
return False
self.current = self.current.next
return True
def print_current_node(self) -> None:
"""주목 노드를 출력"""
if self.current is None:
print("주목 노드가 존재하지 않습니다.")
else:
print(self.current.data)
def print(self) -> None:
"""모든 노드를 출력"""
ptr = self.head
while ptr is not None:
print(ptr.data)
ptr = ptr.next
def __iter__(self) -> LinkedListIterator:
"""이터레이터를 반환"""
return LinkedListIterator(self.head)
class LinkedListIterator:
"""클래스 LinkedList의 이터레이터용 클래스"""
def __init__(self, head: Node):
self.current = head
def __iter__(self) -> LinkedListIterator:
return self
def __next__(self) -> Any:
if self.current is None:
raise StopIteration
else:
data = self.current.data
self.current = self.current.next
return data
연결 리스트를 활용한 프로그램
# 포인터를 이용한 연결 리스트 클래스 LinkedList 사용하기
from enum import Enum
from linked_list import LinkedList
Menu = Enum('Menu', [
'머리에노드삽입',
'꼬리에노드삽입',
'머리노드삭제',
'꼬리노드삭제',
'주목노드출력',
'주목노드이동',
'주목노드삭제',
'모든노드삭제',
'검색',
'멤버십판단',
'모든노드출력',
'스캔',
'종료'
])
def select_Menu() -> Menu:
"""메뉴 선택"""
s = [f'({m.value}){m.name}' for m in Menu]
while True:
print(*s, sep=' ', end='')
n = int(input(': '))
if 1 <= n <= len(Menu):
return Menu(n)
lst = LinkedList()
while True:
menu = select_Menu()
if menu == Menu.머리에노드삽입:
lst.add_first(int(input('머리 노드에 넣을 값을 입력하세요.: ')))
elif menu == Menu.꼬리에노드삽입:
lst.add_last(int(input('꼬리 노드에 넣을 값을 입력하세요: ')))
elif menu == Menu.머리노드삭제:
lst.remove_first()
elif menu == Menu.꼬리노드삭제:
lst.remove_last()
elif menu == Menu.주목노드출력:
lst.print_current_node()
elif menu == Menu.주목노드이동:
lst.next()
elif menu == Menu.주목노드삭제:
lst.remove_current_node()
elif menu == Menu.모든노드삭제:
lst.clear()
elif menu == Menu.검색:
pos = lst.search(int(input('검색할 값을 입력하세요: ')))
if pos >= 0:
print(f'그 값의 데이터는 {pos + 1}번째에 있습니다.')
else:
print('해당하는 데이터가 없습니다.')
elif menu == Menu.멤버십판단:
print('그 값의 데이터는 포함되어' +
('있습니다.' if int(input('판단할 값을 입력하세요: ')) in lst else '있지 않습니다.'))
elif menu == Menu.모든노드출력:
lst.print()
elif menu == Menu.스캔:
for e in lst:
print(e)
else:
break
연결 리스트는 약간 git이랑 비슷하다?(특히 head 포인터)
파이썬으로 원형 이중 연결 리스트 hands on
꼬리 노드가 머리 노드를 가리키는 모양
꼬리 노드 뒤쪽 포인터가 None이 아니라 머리 노드의 포인터값
이중 연결 리스트가 왜 필요한가?
연결 리스트는 뒤쪽 노드 찾기 슆지만 앞쪽 노드 찾기 어렵다.(앞 포인터가 없다)
(머리쪽이 앞이다.)
이걸 개선한 게 이중 연결 리스트
이중 연결 리스트는 '양방향 리스트(bidirectional linked list)'라고도 함
이중 리스트의 필드
1. data: 데이터에 대한 참조
2. prev: 앞쪽 노드에 대한 참조
3. next: 뒤쪽 노드에 대한 참조
원형 이중 연결 리스트 구현
더미 노드를 만들고 더미 노드를 중심으로 연결한다.
(더미 노드는 실제 노드로 취급하지 않음.)
# 원형 이중 연결 리스트
from __future__ import annotations
from typing import Any, Type
class Node:
"""원형 이중 연결 리스트용 노드 클래스"""
def __init__(self, data: Any = None, prev: Node = None, next: Node = None) -> None:
"""초기화"""
self.data = data # 데이터
self.prev = prev or self # 앞쪽 포인터
self.next = next or self # 뒤쪽 포인터
class DoubleLinkedList:
"""원형 이중 연결 리스트 클래스"""
def __init__(self) -> None:
"""초기화"""
self.head = self.current = Node() # 더미 노드 생성
self.no = 0
def __len__(self) -> int:
"""연결 리스트의 노드 수를 반환"""
return self.no
def is_empty(self) -> bool:
"""리스트가 비었는지 확인"""
return self.head.next is self.head
def search(self, data: Any) -> Any:
"""data와 값이 같은 노드를 검색"""
cnt = 0
ptr = self.head.next # 현재 스캔 중인 노드
while ptr is not self.head:
if data == ptr.data:
self.current = ptr
return cnt # 검색 성공
cnt += 1
ptr = ptr.next # 뒤쪽 노드에 주목
return -1 # 검색 실패
def print_current_node(self) -> None:
"""주목 노드를 출력"""
if self.is_empty():
print('주목 노드는 없습니다.')
else:
print(self.current.data)
def print(self) -> None:
"""모든 노드를 출력"""
ptr = self.head.next # 더미 노드의 뒤쪽 노드
while ptr is not self.head:
print(ptr.data)
ptr = ptr.next
def print_reverse(self) -> None:
"""모든 노드를 역순으로 출력"""
ptr = self.head.prev # 더미 노드의 앞쪽 노드
while ptr is not self.head:
print(ptr.data)
ptr = ptr.prev
def next(self) -> bool:
"""주목 노드를 한 칸 뒤로 이동"""
if self.is_empty() or self.current.next is self.head:
return False # 이동할 수 없음
self.current = self.current.next
return True
def prev(self) -> bool:
"""주목 노드를 한 칸 앞으로 이동"""
if self.is_empty() or self.current.prev is self.head:
return False # 이동할 수 없음
self.current = self.current.prev
return True
def add(self, data: Any) -> None:
"""주목 노드 바로 뒤에 노드를 삽입"""
node = Node(data, self.current, self.current.next)
self.current.next.prev = node
self.current.next = node
self.current = node
self.no += 1
def add_first(self, data: Any) -> None:
"""맨 앞에 노드를 삽입"""
self.current = self.head # 더미 노드 head의 바로 뒤에 삽입
self.add(data)
def add_last(self, data: Any) -> None:
"""맨 뒤에 노드를 삽입"""
self.current = self.head.prev # 꼬리 노드 head.prev의 바로 뒤에 삽입
self.add(data)
def remove_current_node(self) -> None:
"""주목 노드 삭제"""
if not self.is_empty():
self.current.prev.next = self.current.next
self.current.next.prev = self.current.prev
self.current = self.current.prev
self.no -= 1
if self.current is self.head:
self.current = self.head.next
def remove(self, p: Node) -> None:
"""노드 p를 삭제"""
ptr = self.head.next
while ptr is not self.head:
if ptr is p:
self.current = p
self.remove_current_node()
break
ptr = ptr.next
def remove_first(self) -> None:
"""머리 노드 삭제"""
self.current = self.head.next # 머리 노드 head.next를 삭제
self.remove_current_node()
def remove_last(self) -> None:
"""꼬리 노드 삭제"""
self.current = self.head.prev # 꼬리 노드 head.prev를 삭제
self.remove_current_node()
def clear(self) -> None:
"""모든 노드를 삭제"""
while not self.is_empty(): # 리스트 전체가 빌 때까지
self.remove_first() # 머리 노드를 삭제
self.no = 0
def __iter__(self) -> DoubleLinkedList:
"""이터레이터를 반환"""
return DoubleLinkedListIterator(self.head)
def __reversed__(self) -> DoubleLinkedListReverseIterator:
"""내침차순 이터레이터를 반환"""
return DoubleLinkedListReverseIterator(self.head)
class DoubleLinkedListIterator:
"""DoubleLinkedList의 이터레이터용 클래스"""
def __init__(self, head: Node):
self.head = head
self.current = head.next
def __iter__(self) -> DoubleLinkedListIterator:
return self
def __next__(self) -> Any:
if self.current is self.head:
raise StopIteration
else:
data = self.current.data
self.current = self.current.next
return data
class DoubleLinkedListReverseIterator:
"""DoubleLinkedList의 내림차순 이터레이터 클래스"""
def __init__(self, head: Node):
self.head = head
self.current = head.prev
def __iter__(self) -> DoubleLinkedListReverseIterator:
return self
def __next__(self) -> Any:
if self.current is self.head:
raise StopIteration
else:
data = self.current.data
self.current = self.current.prev
return data실행 프로그램은 기존 연결 리스트와 비슷해서 구현 안 함.
노드와 연결 리스크는 분리해서 생각하기
연결 리스트를 생성하고, 그 안에 노드를 생성해서 연결시킴
노드 자체가 연결 리스트가 아님
자료 구조를 hands on하면 좋은 점
각 자료구조의 구조를 이해하기 쉬움!
(자료 저장 방식이나 필요한 메서드 등)
포인터를 이용한 연결 리스트 구현 완료
커서를 이용한 연결 리스트도 구현해 봐야함(이건 나중에)
해시테이블
키를 값에 매핑할 수 있는 구조
연관 배열 추상 자료형(ADT)을 구현하는 자료 구조
배열과 해시 함수를 사용하여 map을 구현한 자료 구조
용어 정리
해싱(hashing): 데이터를 저장할 위치(인덱스)를 간단한 연산으로 구하는 것
해시값(hash): 해싱을 통해 계산된 값 (digest 값이라고도 함)
해시 테이블: 해시값을 인덱스로 해서 원소를 새로 저장한 배열
해시 함수: 키를 해시값으로 변환하는 과정
버킷(bucket): 해시 테이블에서 만들어진 원소
충돌(collision): 저장할 버킷이 충돌되는 현상(다른 입력값에 동일한 해시가 계산)
체인법(chaning, open hashing): 해시값이 같은 원소를 연결 리스트로 관리
오픈 주소법(open address): 빈 버킷을 찾을 때까지 해시를 반복
추상 자료형이란?
구현 방법은 명시하지 않고 데이터의 구조와 연산에 대한 명세
ADT는 마치 추상 클래스와 비슷하다!
자료구조를 만들기 위한 이데아 같은 느낌?
해시 함수
임의의 크기의 데이터를 고정된 크기의 값으로 매핑
해시 테이블의 핵심은 해시 함수
해시 함수를 사용하는 것을 해싱이라고 한다.
해시 테이블 안에서 해시 함수는 임의의 데이터를 정수로 변환
(해시 테이블 이외에서 사용되는 해시 테이블은 꼭 정수를 반환하는 건 아님)
좋은 해시 함수의 특징
- 해시 함수 값 충돌의 최소화
- 쉽고 빠른 연산
- 해시 테이블 전체에 해시 값이 균일하게 분포
- 사용할 키의 모든 정보를 이용하여 해싱
- 해시 테이블 사용 효율이 높을 것
해시 충돌(Hash Collision)
서로 다른 입력 데이터가 동일한 해시 코드로 매핑되는 상황
key는 다른데 hash가 같다
이것 뿐만 아니라 해시를 모듈러 연산했을 때 나오는 값이 같은 경우도 해시 충돌
해시 충돌을 해결하는 방법
무식한 방법은 해시 테이블을 충분히 크게 하는 것!(하지만 메모리 낭비)
충돌을 피하려면 해시 함수가 해시 테이블 크기보다 작거나 같은 정수를 고르게 생성해야 함. 그래서 테이블 크기는 소수를 권장
1. 개별 체이닝(separate chaining)
연결 리스트를 활용
충돌 발생 시 같은 해시 코드에 여러 값을 저장, 검색 시 해당 버킷 연결 리스트를 순회
2. 개방 주소법(Open Address, 더 효율적)
충돌이 발생하면 빈 버킷을 찾아 데이터를 저장
(여러 방법이 있음, linear probing(선형 탐사법) 기준으로 정리)
해시가 충돌하면 충돌되지 않을 때까지 재해시 함.
검색할 원래 버킷을 검색하고 다음 버킷이 비어있을 때까지 순차적으로 검색
(개방 주소법으로 값을 저장했다면 다음 버킷이 비어있을 수 없음)
개방 주소법에서는 값을 삭제하면 밀려났던 값을 데리고 오던가,
지워버린 값에 더미 데이터를 채워줘야 한다.
그렇지 않으면 제대로 검색 과정을 거치지 못하니까.
해시 테이블에 저장 시 데이터와 해시도 같이 저장함.
그러면 데이터 접근 시 저장된 데이터에 대해서는 해시 함수를 실행하지 않고, 저장된 해시를 활용할 수 있음.
해시의 시간 복잡도
일반적으로는 O(1)
그러나 해시 충돌로 체이닝이 길어지면 O(n)
해시는 어디에 쓰나?
데이터베이스 인덱싱, 캐싱, 집합 및 맵, 보안(암호화 및 데이터 무결성 검사)
해시 테이블(체이닝) hands on
# 체인법으로 해시 함수 구현하기
from __future__ import annotations
from typing import Any, Type
import hashlib
class Node:
"""해시를 구성하는 노드"""
def __init__(self, key: Any, value: Any, next: Node) -> None:
"""초기화"""
self.key = key
self.value = value
self.next = next
class ChaninedHash:
"""체인법으로 해시 클래스 구현"""
def __init__(self, capacity: int) -> None:
"""초기화"""
self.capacity = capacity # 해시 테이블의 크기를 지정
self.table = [None] * self.capacity # 해시 테이블(리스트)을 선언
def hash_value(self, key: Any) -> int:
"""해시값을 구함"""
if isinstance(key, int):
return key % self.capacity
return (int(hashlib.sha(str(key).encode()).hexidigest(), 16) % self.capacity)
def search(self, key: Any) -> Any:
"""키가 key인 원소를 검색하여 값을 반환"""
hash = self.hash_value(key) # 검색하는 키의 해시값
p = self.table[hash] # 노드를 주목
while p is not None:
if p.key == key:
return p.value # 검색 성공
p = p.next
return None # 검색 실패
def add(self, key: Any, value: Any) -> bool:
"""키가 key이고 값이 value인 원소를 추가"""
hash = self.hash_value(key) # 추가하는 key의 해시값
p = self.table[hash]
while p is not None:
if p.key == key:
return False
p = p.next # 뒤쪽 노드를 주목
temp = Node(key, value, self.table[hash])
self.table[hash] = temp # 노드를 추가
return True # 추가 성공
def remove(self, key: Any) -> bool:
"""키가 key인 원소를 삭제"""
hash = self.hash_value(key) # 삭제할 key의 해시값
p = self.table[hash] # 노드를 주목
pp = None # 바로 앞의 노드를 주목
while p is not None:
if p.key == key: # key를 발견하면 아래를 실행
if pp is None:
self.table[hash] = p.next
else:
pp.next = p.next
return True
pp = p # 뒤쪽 노드를 주목
p = p.next # 삭제 실패(key가 존재하지 않음)
return False
def dump(self) -> None:
"""해시 테이블을 덤프"""
for i in range(self.capacity):
p = self.table[i]
print(i, end='')
while p is not None:
print(f' -> {p.key} ({p.value})', end='')
p = p.next
print()해시 테이블(체이닝) 테스트
# 체인법으로 해시 함수 구현하기
from __future__ import annotations
from typing import Any, Type
import hashlib
class Node:
"""해시를 구성하는 노드"""
def __init__(self, key: Any, value: Any, next: Node) -> None:
"""초기화"""
self.key = key
self.value = value
self.next = next
class ChaninedHash:
"""체인법으로 해시 클래스 구현"""
def __init__(self, capacity: int) -> None:
"""초기화"""
self.capacity = capacity # 해시 테이블의 크기를 지정
self.table = [None] * self.capacity # 해시 테이블(리스트)을 선언
def hash_value(self, key: Any) -> int:
"""해시값을 구함"""
if isinstance(key, int):
return key % self.capacity
return (int(hashlib.sha(str(key).encode()).hexidigest(), 16) % self.capacity)
def search(self, key: Any) -> Any:
"""키가 key인 원소를 검색하여 값을 반환"""
hash = self.hash_value(key) # 검색하는 키의 해시값
p = self.table[hash] # 노드를 주목
while p is not None:
if p.key == key:
return p.value # 검색 성공
p = p.next
return None # 검색 실패
def add(self, key: Any, value: Any) -> bool:
"""키가 key이고 값이 value인 원소를 추가"""
hash = self.hash_value(key) # 추가하는 key의 해시값
p = self.table[hash]
while p is not None:
if p.key == key:
return False
p = p.next # 뒤쪽 노드를 주목
temp = Node(key, value, self.table[hash])
self.table[hash] = temp # 노드를 추가
return True # 추가 성공
def remove(self, key: Any) -> bool:
"""키가 key인 원소를 삭제"""
hash = self.hash_value(key) # 삭제할 key의 해시값
p = self.table[hash] # 노드를 주목
pp = None # 바로 앞의 노드를 주목
while p is not None:
if p.key == key: # key를 발견하면 아래를 실행
if pp is None:
self.table[hash] = p.next
else:
pp.next = p.next
return True
pp = p # 뒤쪽 노드를 주목
p = p.next # 삭제 실패(key가 존재하지 않음)
return False
def dump(self) -> None:
"""해시 테이블을 덤프"""
for i in range(self.capacity):
p = self.table[i]
print(i, end='')
while p is not None:
print(f' -> {p.key} ({p.value})', end='')
p = p.next
print()해시 테이블(체이닝) 시각화
0
1 -> 14 (민서) -> 1 (수연)
2
3
4
5 -> 5 (동혁)
6
7
8
9
10 -> 10 (예지)
11
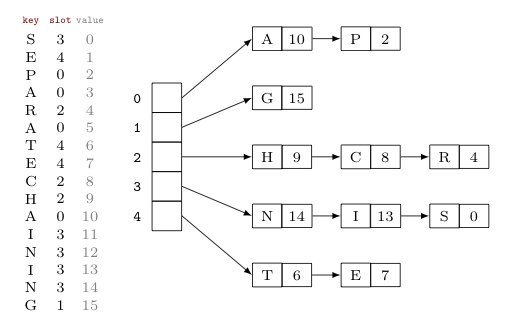
12 -> 12 (원준)해시 테이블은 배열인 것이었다!
그리고 배열에는 단순히 값이 들어가는 게 아니라 노드 또는 버킷이 들어간다.
(배열 하나 하나를 버킷이라고 칭하고, 체이닝의 경우 버킷 안에 노드로 이루어진 연결 리스트가 들어가고, 개방 주소법은 버킷 자체가 들어간다.)
해시 테이블(개방 주소법) hands on
# 오픈 주소법으로 해시 함수 구현하기
from __future__ import annotations
from typing import Any, Type
from enum import Enum
import hashlib
# 버킷의 속성
class Status(Enum):
OCCUPIED = 0 # 데이터를 저장
EMPTY = 1 # 비어있음
DELETED = 2 # 삭제 완료
class Bucket:
"""해시를 구성하는 버킷"""
def __init__(self, key: Any = None, value: Any = None, stat: Status = Status.EMPTY) -> None:
"""초기화"""
self.key = key # 키
self.value = value # 값
self.stat = stat
def set(self, key: Any, value: Any, stat: Status) -> None:
"""모든 필드에 값을 설정"""
self.key = key # 키
self.value = value # 값
self.stat = stat # 속성
def set_status(self, stat: Status) -> None:
"""속성을 설정"""
self.stat = stat
class OpenHash:
"""오픈 주소법으로 구현하는 해시 클래스"""
def __init__(self, capacity: int) -> None:
"""초기화"""
self.capacity = capacity # 해시 테이블의 크기를 지정
self.table = [Bucket()] * self.capacity # 해시 테이블
def hash_value(self, key: Any) -> int:
"""해시값을 구함"""
if isinstance(key, int): # key객체가 int형과 호환되는지
return key % self.capacity
return (int(hashlib.md5(str(key).encode()).hexidigest(), 16) % self.capacity)
def rehash_value(self, key: Any) -> int:
"""재해시값을 구함"""
return (self.hash_value(key) + 1) % self.capacity
def search_bucket(self, key: Any) -> Any:
"""키가 key인 버킷을 검색"""
hash = self.hash_value(key) # 검색하는 키의 해시값
p = self.table[hash] # 버킷을 주목
for i in range(self.capacity):
if p.stat == Status.EMPTY:
break
elif p.stat == Status.OCCUPIED and p.key == key:
return p
hash = self.rehash_value(hash) # 재해시
p = self.table[hash]
return None
def search(self, key: Any) -> Any:
"""키가 key인 원소를 검색하여 값을 반환"""
p = self.search_bucket(key)
if p is not None:
return p.value # 검색 성공
else:
return None # 검색 실패
def add(self, key: Any, value: Any) -> bool:
"""키가 key이고 값이 value인 원소를 추가"""
if self.search(key) is not None:
return False # 이미 등록된 키
hash = self.hash_value(key) # 추가하는 키의 해시값
p = self.table[hash] # 버킷을 주목
for i in range(self.capacity):
if p.stat == Status.EMPTY or p.stat == Status.DELETED:
self.table[hash] = Bucket(key, value, Status.OCCUPIED)
return True
hash = self.rehash_value(hash) # 재해시
p = self.table[hash]
return False # 해시 테이블이 가득참
def remove(self, key: Any) -> int:
"""키가 key인 원소를 삭제"""
p = self.search_bucket(key) # 버킷을 주목
if p is None:
return False # 이 키는 등록되어 있지 않음
p.set_status(Status.DELETED)
return True
def dump(self) -> None:
"""해시 테이블을 덤프"""
for i in range(self.capacity):
print(f'{i:2} ', end=' ')
if self.table[i].stat == Status.OCCUPIED:
print(f'{self.table[i].key} ({self.table[i].value})')
elif self.table[i].stat == Status.EMPTY:
print('-- 미등록 --')
elif self.table[i].stat == Status.DELETED:
print('-- 삭제 완료 --')해시 테이블(개방 주소법) 테스트
# 오픈 주소법을 구현하는 해시 클래스 Openhash 사용
from enum import Enum
from open_hash import OpenHash
Menu = Enum('Menu', ['추가', '삭제', '검색', '덤프', '종료']) # 메뉴를 선억
def select_menu() -> Menu:
"""메뉴 선택"""
s = [f'({m.value}){m.name}' for m in Menu]
while True:
print(*s, sep=' ', end='')
n = int(input(': '))
if 1 <= n <= len(Menu):
return Menu(n)
hash = OpenHash(13) # 크기가 13인 해시 테이블 생성
while True:
menu = select_menu()
if menu == Menu.추가:
key = int(input('추가할 키를 입력하세요: '))
val = input('추가할 값을 입력하세요: ')
if not hash.add(key, val):
print('추가를 실패했습니다.')
elif menu == Menu.삭제:
key = int(input('삭제할 키를 입력하세요: '))
if not hash.remove(key):
print('삭제를 실패했습니다!')
elif menu == Menu.검색:
key = int(input('검색할 키를 입력하세요: '))
t = hash.search(key)
if t is not None:
print(f'검색한 키를 갖는 값은 {t}입니다.')
else:
print('검색할 데이터가 없습니다.')
elif menu == Menu.덤프:
hash.dump()
else:
break해시 테이블(개방 주소법) 시각화
0 -- 미등록 --
1 1 (수연)
2 14 (민서)
3 -- 미등록 --
4 -- 미등록 --
5 5 (동혁)
6 -- 미등록 --
7 -- 미등록 --
8 -- 미등록 --
9 -- 미등록 --
10 10 (예지)
11 -- 미등록 --
12 12 (원준)1주차 퀴즈 후기
처음으로 손 코딩 해봄
(재귀 함수는 단일 원소만 출력하고 배열은 출력 안함(오답이겠지?)
# fin(n)만 제출함
def fib(n):
if n <= 2:
return 1
return fib(n-1) + fib(n-2)
# 이거 추가했으면 됐을 듯
def print_fib(n):
for i in range(1, n+1):
print(fib(i))
print_fib(10)
정렬은 과정 하나 하나를 분해하면서 공부해야 겠음
(시험 풀면서 퀵 소트 과정 다시 정리되었음)
해시는 진도를 못 나가서 못 풀었음(덕분에 해시는 더 빡세게 공부하게 됨)
재귀 어려웠는데 퀴즈로 나오니까 두뇌 풀가동해서 풀었음.
그러더니 갑자기 재귀의 아하 모먼트가 온 것 같음!!
피보나치 재귀 이해 제대로 못했는데 퀴즈 풀면서 두뇌 풀가동해서 깨달음!!
스터디 모임
새롭게 알게된 용어
메모이제이션(memoization)
