내일이 알고리즘 시험이지만..
우선 자료구조 이론부터 정리하고 감.
정답 맞추기에 급급하기보다 이론적으로 먼저 정리하고 배운 이론을 적용해서 알고리즘 문제 풀어보기
(문제 취지가 재귀인데 반복문으로 풀고 정답 맞췄다고 넘어가면 안 됨)
자료구조
ADT(Abstract Data Type, 추상 자료형)
자료들과 그 자료에 대한 연산(메서드?)을 명기
구현 방법을 명시하지는 않는다.(구현은 알아서 해라.)
(추상적 자료구조라는 것도 있다. 이건 시간 복잡도를 명기함. 추상 자료형을 시간 복잡도 명기 안함)
인터페이스와 구현을 분리하여 추상화 계층을 둔 것!
추상 자료형은 자료에 대하여 질의하는 것과 변경하기 위한 연산으로 나뉨
스택 ADT 예시
1. 자료를 변경하기 위한 연산 push, pop이 있다.
2. 질의는 던지는 연산 size, full, empty
3. pop(제거), peek(제거될 자료 보기)
이렇게 명시하면 추상 자료형
4. 각 연산은 O(1)이다. -> 여기까지 명기하면 추상 자료 구조
추상 자료형 예시
복소수
리스트
스택
큐
맵
우선순위 큐
집합
ADT 여기 참고하기
추상 자료형의 개념은 추상 클래스와 비슷한 것 같다.
(내 생각) 그리고 ECMAScript와 JavaScript의 관계와도 비슷한 것 같다.
우선 순위 큐
우선순위를 가진 원소가 먼저 처리된다
우선순위 큐 = 힙표현은 틀렸다. 우선순위 큐는 리스트나 맵과 같이 추상적인 개념이다.
리스트는 연결 리스트, 배열로 구현될 수 있는 것처럼 우선순위 큐는 힙이나 다른 방법으로 구현될 수 있다.
(무식하게 배열로 구현될 수도 있음. 어떤 자료를 처리할 때마다 모든 배열을 순회하면서 우선 순위를 체크)
우선 순위 큐 ADT
최소 지원 연산
insert_with_priority: 하나의 원소를 우선순위를 지정하여 큐에 추가한다.
pull_highest_priority_element: 가장 높은 우선순위를 가진 원소를 큐에서 제거하고 이를 반환한다.
Heap(힙)
최댓값 및 최솟값을 빠르게 찾기 위해 고안된 자료구조
(완전 이진 트리를 기본으로 한다.)
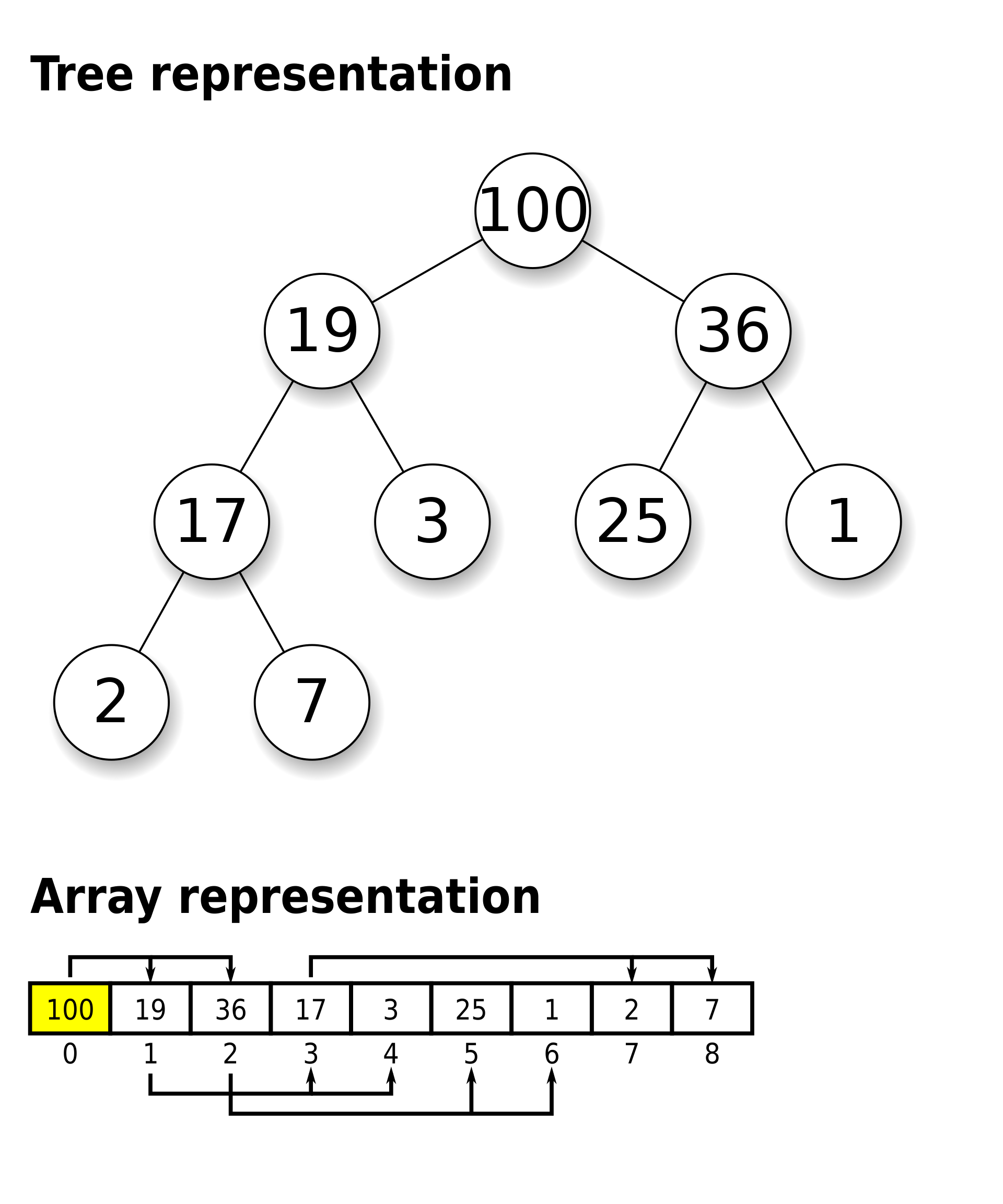
힙의 조건
항상 루트 노드를 제거한다.
힙의 종류
- 최소 힙(min heap): 루트 노드가 가장 작은 값
- 최대 힙(max heap): 루트 노드가 가장 큰 값
힙 구성 방법(최소 힙 예시)
일반적으로 힙을 구성하는 함수를 heapify()라고 함.
원소 추가 방법(최소 힙 예시)
(상향식 heapify)자식 노드와 부모 노드를 비교해서 부모보다 자식이 더 작으면 위치를 교체
(최소 힙 성질을 만족하는지 만족하지 않는지 체크)
원소 삭제 방법(최소 힙 예시)
1. 가장 마지막 노드가 루트 노드로 간다.
2. (하향식 heapify)부모 노드와 자식 노드를 비교해서 부모가 자식보다 더 크면 교체
힙(구체적인 자료 구조)은 우선순위 큐(추상 자료형)의 구현체다.
힙은 프로세스 스케줄링(레디큐)에 사용될 수 있다
(무조건 사용되는 건 아님)
p1, p2, p3, p4가 실행 중인 상황을 가정해 보자.
p1이 cpu를 점유(실행)하고 있으면 나머지 프로세스는 레디 큐에서 대기한다.
레디 큐가 FIFO큐가 아니라 우선순위 큐라면 레디큐에서 우선순위가 높은 프로세스가 실행될 수 있다.
참고 나중에 배울 힙 메모리의 '힙'과는 관련 없다!
파이썬 heapq hands-on
import heapq
import random
def heapsort(iterable):
h = []
result = []
# 주어진 데이터를 h에 삽입하면서 최소힙으로 정렬
for value in iterable:
heapq.heappush(h, value)
# 힙에서 작은 값을 순차적으로 추출해서 result에 담음
# h는 최소힙이며, 배열로 일자로 출력했을 땐 정렬 안 된 것처럼 보임
for i in range(len(h)):
result.append(heapq.heappop(h))
return result
# 여기서부터는 실행 프로그램
# 더미 데이터 생성
arr = [random.randint(0, 100) for _ in range(10)]
print(f"정렬 전 배열: {arr}")
sorted_arr = heapsort(arr)
print(f"힙정렬 후 배열: {sorted_arr}")
if sorted_arr == sorted(arr):
print("✅ 정렬 테스트 통과!")기억해야 할 메서드
heapq.heappush(arr, value): arr에 value를 삽입하면서 arr에 heapify를 수행한다.
heapq.heappop(arr): arr에서 루트 노드를 꺼내오고 arr에 heapify를 수행한다.
(보너스)heapq.merge(arr1, arr2): 정렬을 마친 두 개의 배열을 병합
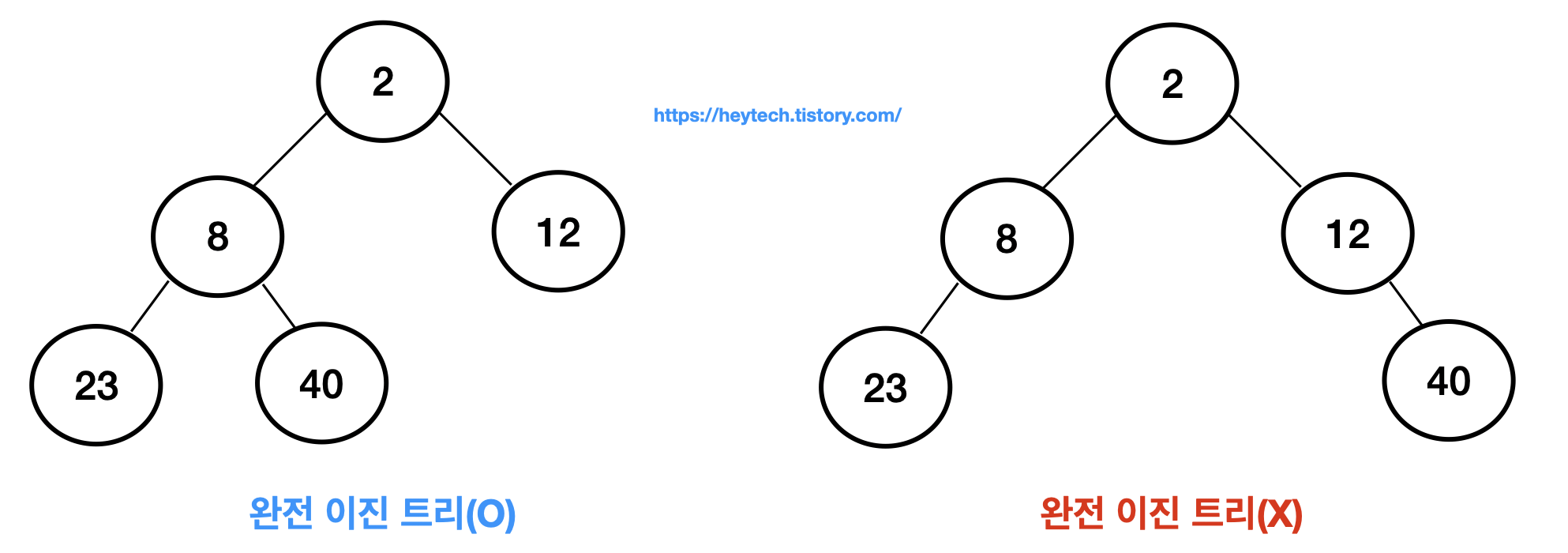
완전 이진 트리란?
(트리는 다음 주에 공부하기!)
조건1. 마지막 레벨을 제외하고 모든 레벨이 완전히 채워져 있음.
조건2. 마지막 레벨의 모든 노드는 왼쪽부터 채워짐.
(최대 가질 수 있는 노드 갯수는 2^h - 1)
백준 최대 힙(11279)를 heapq로 풀어 보았다
import heapq
import sys
N = int(input())
nums = []
for _ in range(N):
nums.append(int(sys.stdin.readline().strip()))
h = []
for num in nums:
if num == 0:
if len(h) > 0:
print(-heapq.heappop(h))
else:
print(0)
else:
heapq.heappush(h, -num)오류 복기
readline()을readlin이라고 적음
파이썬의 heapq는 최소힙을 구현한다! 백준 문제는 최대 힙이었음!!
heapq는 최대힙을 지원하지 않는다. 그래서 push할 때 음수로 넣어주고, 꺼낼 때 음수 붙여서 빼면 최대힙 효과가 난다.
파이썬의 heapq는 최소 힙(min heap)이라는 걸 꼭 기억!!!
파이썬으로 heap sort 구현체 hands on(최대 힙)
# 힙 정렬 알고리즘 구현하기
from typing import MutableSequence
def heap_sort(a: MutableSequence) -> None:
"""힙 정렬"""
# 시프트 다운, 부모 노드에서 자식 노드의 값을 비교하겠다
def down_heap(a: MutableSequence, left: int, right: int) -> None:
"""a[left] ~ a[right]를 힙으로 만들기"""
temp = a[left] # 루트의 값을 임시로 저장
# left는 루트 노드 인덱스
# right는 현재 노드의 인덱스
parent = left
while parent < (right + 1) // 2: # 자식 노드가 있는 노드의 개수, right+1은 전체 원소의 개수, 자식 노드가 있는 부모 노드만 검색하겠다!(부모로 사용할 인덱스를 돌린다.)
cl = parent * 2 + 1 # 왼쪽 자식
cr = cl + 1 # 오른쪽 자식
child = cr if cr <= right and a[cr] > a[cl] else cl # 큰 값을 선택, 주목!
if temp >= a[child]:
break
a[parent] = a[child]
parent = child
a[parent] = temp
n = len(a)
# 말단부터 차례 대로 heapify를 수행해서 힙을 만든다.
for i in range((n - 1) // 2, -1, -1): # 마지막 자식의 부모노드부터 시작
print(f"{i}[info]{a} a[{i}]부터 a[{n - 1}]까지 heapify를 수행합니다.")
down_heap(a, i, n - 1)
# 새로운 배열을 반환하지 않고 기존 a에 정렬을 수행한다.
# 루트 노드(최대값)을 마지막 원소와 교환(맨 뒤로 보내서 정렬 수행)
# 힙 정렬이 끝난 배열에서 가장 큰 값을 가장 뒤로 보내는 작업(오름차순 정렬 수행)
for i in range(n - 1, 0, -1):
a[0], a[i] = a[i], a[0]
print(f"{i}[info]{a} a[0]과 a{[i]}를 스왑합니다.")
down_heap(a, 0, i - 1) # 스왑 후 힙 구조가 무너질 수 있다. 이미 정렬된 부분을 제외하고(뒷 부분) 루트부터 교환한 부분까지 다시 힙 체크(시프트 다운)을 한다.
if __name__ == "__main__":
print("힙 정렬을 수행합니다.")
num = int(input("원소 수를 입력하세요: "))
x = [None] * num
for i in range(num):
x[i] = int(input(f"x[{i}]: "))
heap_sort(x)
print("오름차순으로 정렬했습니다.")
for i in range(num):
print(f"x[{i}] = {x[i]}")
//를 모듈러 연산(%)으로 착각해서 코드 이해에 1시간 넘게 걸림.
while parent < (right + 1) // 2:코드 이해 못해서 2시간 넘게 고민함. 유튜브 영상 보고 바로 이해 함.
힙 정렬 C언어
힙에서 자식이 있는 노드의 개수는전체 노드 수 // 2임.
그래서 이 코드는 힙 정렬 대상이 되는 트리에서시프트 다운을 할 필요가 있는 노드 개수만큼만 시프트 다운을 한다는 의미!
힙 소트 코드 거의 하루 종일 고민했는데 이해했음!!!!
코드 이해를 위한 정리
1. 힙은 원소 개수 / 2만큼의 노드가 자식 노드를 갖는다.
배열 기반 힙의 부모-자식 인덱스 관계
1. (부모 i) 왼쪽 자식 노드 : (2 i) + 1
2. (부모 i) 오른쪽 자식 노드 : (2 i) + 2
3. (자식 i) 부모 노드 : (i - 1) // 2
파이썬 deque(double ended queue) hands-on
from collections import deque
# 데크 객체 생성
my_deque = deque()
# 오른쪽 끝에 원소 추가
my_deque.append(1)
my_deque.append(2)
my_deque.append(3)
my_deque.append(4)
my_deque.append(5)
my_deque.append(6)
# 왼쪽 끝에 원소 추가
my_deque.appendleft(0)
print("--전체 데크입니다.--")
print(my_deque)
# 오른쪽 끝의 원소 제거
value = my_deque.pop()
print("---오른쪽 끝 원소 pop입니다.---")
print(value)
# 왼쪽 끝의 원소 제거
left_value = my_deque.popleft()
print("---왼쪽 끝 원소 pop입니다.---")
print(left_value)
# 길이 확인
length = len(my_deque)
print("---데크 길이입니다.---")
print(length)
# 원소 접근
# 인덱스로 접근할 수 있지만 양 끝을 접근하는 게 가장 빠름
# 첫 번째 (왼쪽 끝) 원소 접근
first_item = my_deque[0]
print("---왼쪽 끝 원소입니다.---")
print(first_item)
# 마지막 (오른쪽 끝) 원소 접근
last_item = my_deque[-1]
print("---오른쪽 끝 원소입니다.---")
print(last_item)
# 회전 시키기
my_deque.rotate(2) # 시계 방향은 양수, 반대는 음수
result = list(my_deque)
print(result)deque는 list와 매우 비슷함. 이것만 추가로 기억하자!
appendleft(),popleft()
파이썬 list가 있는데 왜 deque를 쓰지?
deque는 list보다 속도가 빠름. 예를 들어 리스트의pop(0)이 O(n)이라면
dequed의pop(),popleft()는 O(1)이다.
파이썬 list의 pop(0)이 왜 O(n)일까?
pop을 한 이후에 나머지 원소를 한 칸씩 왼쪽으로 땡겨줘야 하기 때문임!
요세푸스 문제(백준 11866)를 데크로 풀어보았다
from collections import deque
# N, K를 입력 받는다
N, K = map(int, input().split())
# 데크 객체를 생성한다
my_deque = deque()
# 데크 객체에 숫자를 집어 넣는다
for i in range(1, N + 1):
my_deque.append(i)
# 데크가 빌 때까지 로테이션 하며 제거 작업(가장 왼쪽 pop)을 반복한다
result = []
while len(my_deque) > 0:
my_deque.rotate(-(K-1))
killed_member = my_deque.popleft()
result.append(killed_member)
# 예시 출력 형태로 변환한다
formatted_result = str(result).replace("[", "<").replace("]", ">")
print(formatted_result)데크로 쉽게 풀었음! 앞으로 이런 유형 문제는 쉽게 풀 수 있을 것 같음!
비슷한 유형 여러개 풀어보면서 메서드 익숙해지기!
런타임 오류 2개 발생
1.deque()를Deque()로 적음
2.replace를replave로 적음.(심지어 지금 쓰면서도replave라고 타이핑 함)
다른 풀이법
나는 로테이션 함수를 사용했는데 로테이션 함수를 쓰지 않고 로테이션 효과를 낼 수 있음
(가장 왼쪽을 오른쪽으로 보내는 것, 로테이션과 같음)
while queue:
for i in range(K-1):
queue.append(queue.popleft())
answer.append(queue.popleft())큐 구현 문제(백준 18258)를 데크로 풀어 보았다
(리스트로 풀었을 땐 시간 초과)
from collections import deque
import sys
N = int(input())
codes = []
for _ in range(N):
codes.append(sys.stdin.readline().rstrip())
my_deque = deque()
for code in codes:
if "push" in code:
data = int(code.split()[1])
my_deque.append(data)
elif code == "pop":
if len(my_deque) == 0:
print(-1)
else:
print(my_deque.popleft())
elif code == "size":
print(len(my_deque))
elif code == "empty":
if len(my_deque) == 0:
print(1)
else:
print(0)
elif code == "front":
if len(my_deque) == 0:
print(-1)
else:
print(my_deque[0])
elif code == "back":
if len(my_deque) == 0:
print(-1)
else:
print(my_deque[-1])오류 발생 원인 복기
1. 반복문에서 이미 print하고 있는데 하단에 deque를 또 print함.
2.my_deque를deque라고만 씀(근데 이 반복문은 어차피 없어야 되는 거였음. 괜히 오류만 발생)
3. 리스트 순회할 때for code in codes():라고 씀. 마지막 괄호가 왜 들어간 거야?
4. 값 입력 받을 때\n제거 안함.codes.append(sys.stdin.readline().rstrip())
리스트로 안 풀리던 문제가 deque로 풀리니까 신기!!
정렬(이어서)
- 버블 정렬 ✅
- 단순 선택 정렬 ✅
- 단순 삽입 정렬 ✅
- 셸 정렬 🔥
- 퀵 정렬 🔥
- 병합 정렬 ✅
- 힙 정렬 ✅
- 도수 정렬 🤔
정렬은 대충의 원리는 알겠는데 알고리즘을 구현하거나 문제를 푸는데 어려움이 있다. 전체적인 아이디어 습득한 후에는 하나의 정렬 문제를 다양한 알고리즘으로 풀어보자!
병합 정렬
배열을 앞부분(a), 뒷부분(b)으로 나누어 각각 정렬한 후 병합(c)을 반복
a, b 배열을 비교해서 작은 쪽의 원소를 꺼내 c 배열에 저장
(공간이 추가로 필요하다.)
정렬을 마친 2개의 배열 병합 hands-on
from typing import Sequence, MutableSequence
def merge_sorted_list(a: Sequence, b: Sequence, c: MutableSequence):
"""정렬을 마친 배열 a와 b를 병합하여 c에 저장"""
pa, pb, pc = 0, 0, 0 # 각 배열의 커서(이건 인덱스 값)
na, nb, nc = len(a), len(b), len(c) # 각 배열의 원소 수(이건 길이 값, 최대 인덱스보다 1이 큼)
while pa < na and pb < nb: # 두 배열이 모두 원소가 있으면
if a[pa] <= b[pb]: # a 배열의 값이 더 작으면
c[pc] = a[pa] # c 배열에 a 배열의 값을 복사
pa += 1 # a 배열 포인터 우측으로 이동
else: # b 배열의 값이 더 작으면
c[pc] = b[pb] # c 배열에 b 배열의 값을 복사
pb += 1 # b 배열의 포인터를 우측으로 이동
pc += 1 # 1차 병합이 완료되었으므로 c 배열의 포인터를 우측으로 이동
while pa < na: # a 배열에만 원소가 남아 있으면(b 배열이 비워져 있는 상황)
c[pc] = a[pa] # a 배열의 값을 c 배열로 복사
pa += 1 # a 포인터 우측으로 이동
pc += 1 # c 포인터 우측으로 이동
while pb < nb: # b 배열에만 원소가 남아 있으면(a 배열이 비워져 있는 상황)
c[pc] = b[pb] # b 배열의 값을 c 배열로 복사
pb += 1 # b 포인터 우측으로 이동
pc += 1 # c 포인터 우측으로 이동
if __name__ == '__main__':
a = [2, 4, 6, 8, 11, 13]
b = [1, 2, 3, 4, 9, 16, 21]
c = [None] * (len(a) + len(b))
print('정렬을 마친 두 배열의 병합을 수행합니다.')
merge_sorted_list(a, b, c)
print('배열 a와 b를 병합하여 배열 c에 저장했습니다.')
print(f'배열 a: {a}')
print(f'배열 b: {b}')
print(f'배열 c: {c}')재귀로 구현된 병합 정렬 hands on
# 병합 정렬 알고리즘 구현하기
from typing import MutableSequence
def merge_sort(a: MutableSequence) -> None:
"""병합 정렬"""
def _merge_sort(a: MutableSequence, left: int, right: int) -> None:
"""a[left] ~ a[right]를 재귀적으로 병합 정렬"""
# 여기가 recursive 조건, 자동적으로 left >= right일 때(원소가 1개 일 때)가 base 조건이 됨
if left < right: # 배열의 원소가 1개 이상이면, 즉 쪼갤 수 있으면 재귀 호출이 필요함.
center = (left + right) // 2 # 가운데 인덱스, 만약 짝수면 왼쪽에 포함
_merge_sort(a, left, center) # 배열의 앞부분을 재귀적으로 병합 정렬
_merge_sort(a, center + 1, right) # 배열의 뒷부분을 재귀적으로 병합 정렬
p = j = 0 # p, j는 버퍼 포인터
i = k = left # i는 원본 배열 a 포인터
while i <= center: # 배열의 앞부분을 버퍼로 복사
buff[p] = a[i] # 배열의 첫번째 원소를 버퍼의 제일 처음으로 복사
p += 1 # 버퍼 배열의 포인터를 우측으로 이동시킨다.
i += 1 # a 배열의 포인터를 우측으로 이동시킨다.
# 버퍼가 일종의 앞 배열이 되는 것(공간 절약을 위해?)
# 그래서 기존 a 배열의 앞 부분이 채워 나간다.
while i <= right and j < p: # a 포인터가 a 배열 끝까지 가지 않았고, 버퍼 포인터가 center 다음까지 도달하지 않았을 때
if buff[j] <= a[i]: # 뒷배열(원본)보다 앞배열(버퍼)가 작으면
a[k] = buff[j] # 원본 a에 버퍼의 값을 넣는다.
j += 1 # 버퍼 포인터를 우측으로 이동한다.
else: # 앞배열(버퍼)가 뒷배열(원본)보다 작으면
a[k] = a[i] # 원본 a에 뒷배열(원본)의 값을 넣는다.
i += 1 # 뒷배열 포인터를 우측으로 이동한다.
k += 1 # 다음 값이 들어갈 a의 포인터를 우측으로 이동한다.
while j < p: # a 뒷배열이 비어있으면(앞배열은 비어있을 수 없음)
a[k] = buff[j] # 버퍼의 값을 넣는다.
k += 1 # 다음 값이 들어갈 a의 포인터를 우측으로 이동한다.
j += 1 # 버퍼 포인터를 우측으로 이동한다.
n = len(a)
buff = [None] * n # 작업용 배열 생성
_merge_sort(a, 0, n - 1) # 배열 전체를 병합 정렬
del buff # 작업용 배열을 소멸
if __name__ == "__main__":
print("병합 정렬을 수행합니다")
num = int(input("원소 수를 입력하세요: "))
x = [None] * num
for i in range(num):
x[i] = int(input(f"x[{i}]: "))
merge_sort(x)
print("오름차순으로 정렬했습니다.")
for i in range(num):
print(f"x[{i}] = {x[i]}")
공간 활용을 위해 새로운 배열에 병합하지 않고 기존 원본 a의 절반을 버퍼로 복사해서 버퍼(앞부분)와 기존 배열 a(뒷부분)을 병합해서 기존 공간 a에 값을 덮어씌우는 방식이 어려웠지만 이해됨!!
알고리즘
드디어 기본적인 자료구조, 정렬 다 훑어 봄.. 힘들었지만 재밌다!!
(정렬은 아직 개념 정도만.. 문제 풀면서 익혀볼 예정!)
이제 무한 문제 풀이 도입!
이분 탐색은 포인터 + 재귀로 풀기
포인터가 교차되면 탐색 종료
백준 2805 나무자르기
반복문으로 풀었더니 시간 초과됨
import sys
N, M = map(int, sys.stdin.readline().strip().split())
trees = [int(tree) for tree in sys.stdin.readline().strip().split()]
def cut(trees, h):
len_sum = 0
tree_count = 0
for tree in trees:
if tree > h:
len_sum += (tree - h)
return len_sum
right_pointer = max(trees)
left_pointer = 0
h = 0
while right_pointer >= left_pointer:
mid = (left_pointer + right_pointer) // 2
cut_tree_len = cut(trees, mid)
if cut_tree_len > M:
h = mid
left_pointer = mid + 1
elif cut_tree_len < M:
right_pointer = mid - 1
else:
print(mid)
print(h)
재귀로 풀었더니 풀림
import sys
N, M = map(int, sys.stdin.readline().strip().split())
trees = [int(tree) for tree in sys.stdin.readline().strip().split()]
def cut(trees, h):
len_sum = 0
for tree in trees:
if tree > h:
len_sum += (tree - h)
return len_sum
def find(left_pointer, right_pointer):
if left_pointer > right_pointer:
return right_pointer
mid = (left_pointer + right_pointer) // 2
cut_tree_len = cut(trees, mid)
if cut_tree_len > M:
return find(mid + 1, right_pointer)
elif cut_tree_len < M:
return find(left_pointer, mid - 1)
else:
return mid
answer = find(0, max(trees))
print(answer)오류 복기
recursive 조건에서 return을 하지 않고 재귀 함수만 호출해서 계속 틀림
백준 10816 숫자 카드
import sys
from collections import defaultdict
N = int(input())
cards = [int(num) for num in sys.stdin.readline().strip().split()]
M = int(input())
targets = [int(num) for num in sys.stdin.readline().strip().split()]
table = defaultdict(int)
for card in cards:
table[card] += 1
answer = []
for target in targets:
answer.append(table[target])
print(" ".join(map(str, answer)))이분 탐색 아닌데 왜 이분 탐색 카테고리로 분류된 거야..
그래도join쓰는 거랑defaultdict(int)익힘.
join은 스트링 타입에만 쓸 수 있음
파이썬
defaultdict 객체
dict는 원래 없는 키를 조회하면 에러가 발생한다.
defaultdict는 없는 키를 조회하면 해당 키에 대한 아이템(default = 0)을 생성한다.
from collections import defaultdict
my_dict = defaultdict(int)