7:50 입실
뭔가 피곤해서 5분 더 자고 7:35 기상
운영체제 영상보다가 1시쯤 잤는데 앞으로는 12시 땡하면 자야겠음.
백준 1992 쿼드드리
커리큘럼 문제는 아니지만 분할 정복 문제 감 잡아보려고 풂.
GPT의 깔끔한 풀이..
import sys
sys.setrecursionlimit(10**6)
N = int(sys.stdin.readline().strip())
video = [list(map(str, sys.stdin.readline().strip())) for _ in range(N)]
def divide_conquer(x, y, N, video):
# Check if all the pixels in the current section are the same
if all(video[i][j] == video[x][y] for i in range(x, x + N) for j in range(y, y + N)):
return video[x][y]
half = N // 2
# Divide the current section into 4 quarters and solve them recursively
half_a = divide_conquer(x, y, half, video)
half_b = divide_conquer(x, y + half, half, video)
half_c = divide_conquer(x + half, y, half, video)
half_d = divide_conquer(x + half, y + half, half, video)
# Return the combined result
return f"({half_a}{half_b}{half_c}{half_d})"
print(divide_conquer(0, 0, N, video))전체적인 아이디어는 맞았고 어느 정도 구현했으나 재귀적 사고가 부족해서 실패
2차원 배열 슬라이싱 하는 것 몰라서 GPT 도움 받음.
이건 반복 연습하기!half = N // 2 a = [row[:half] for row in video[:half]] b = [row[half:] for row in video[:half]] c = [row[:half] for row in video[half:]] d = [row[half:] for row in video[half:]
파이썬 all()
순회 가능한 객체의 값이 모두 True로 평가되면 True, 아니면 False를 반환
print(all([True, True, True])) # True
print(all([True, False, True])) # False
print(all([1, 2, 3])) # True (모든 숫자가 0이 아님)
print(all([0, 1, 2])) # False (0은 False로 평가됨)
# 이럴 때 유용한
nums = [2, 4, 6, 8, 10]
print(all(num % 2 == 0 for num in nums)) # True (모든 숫자가 짝수임)파이썬 리스트 컴프리헨션 이중 반복문
# 기본적인 이중 반복문
result = []
for i in range(3):
for j in range(3):
result.append((i, j))
# 리스트 컴프리헨션 이중 반복문
result = [(i, j) for i in range(3) for j in range(3)]
result = [(i, j) for i in range(3) for j in range(3) if i != j]C 포인터
*의 3가지 역할
1. 곱하기
2 * a;2. 포인터
포인터로 쓸 때는 자료형을 명시해야 함.
int *p:
double *p;
3. 역참조
포인터로 값을 가져오기
*p;*은 변수명의 일부가 아니다. 포인터를 나타내는 연산자!
64비트 기준 포인터 크기는 int, double 상관없이 무조건 8바이트
그럼 왜 포인터 할당할 때 자료형 명시해야 하나?
포인터를 해당 변수 값의 상위 주소(첫 번째 주솟값)만 가지고 있다.
자료형을 명시해야지 어디까지 읽어올지 알 수 있음.
변수의 포인터 값 가져오기(참조)
double *ptr = &d;CSAPP 3
3.4 정보 접근하기
x86-64의 64비트 레지스터는 여러 부분(또는 하위 영역)을 가지고 있어
8비트, 16비트, 32비트 데이터에 접근할 수 있다.
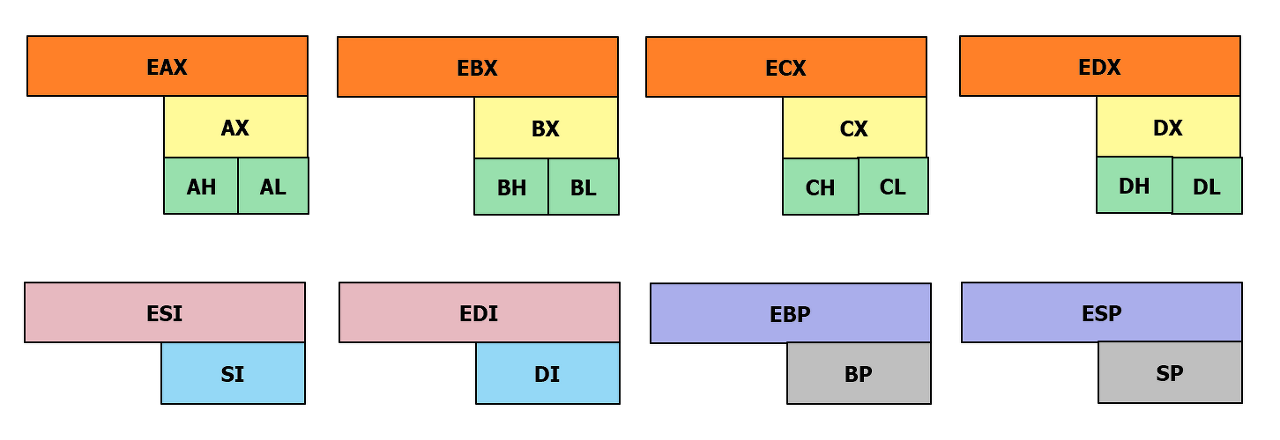
x86 아키텍처 레지스터
RAX
RBX
RCX
RDX
RSI
RDI
RBP (Base Pointer)
RSP (Stack Pointer)
x86-64 아키텍처에서 추가된 8개의 레지스터
R8
R9
R10
R11
R12
R13
R14
R15
하위 레지스터가 왜 필요하지?
1. 하위 호환(16비트, 32비트 코드나 라이브러리 사용 시)
2. 모든데이터가 64비트가 필요한 건 아니다. 32비트 정수 연산이나 32비트 명령어는 32비트 레지스터에 값을 저장하는 게 적절
3. 하위 레지스터 대상으로 하는 명령어가 때로는 더 짧아 코드 크기를 줄일 수 있다.(메모리 감소, 성능 향상)
3.4.1 오퍼랜드 식별자
오퍼랜드(피연산자): 연산 수행에 필요한 데이터 혹은 데이터 주소
(연산을 수행할 소스 source 값과 그 결과를 저장할 목적지 destination의 위치)
오퍼랜드 타입
1. immediate(즉시): 상수, $로 나타냄.
2. register(레지스터): 64비트 레지스터(또는 그 하위 레지스터)
3. 메모리 참조: 유효 주소(effective adres, 실제 데이터 위치)에 의해 메모리 위치 접근
연습 문제 3.1
| address | value | register | value |
|---|---|---|---|
| 0x100 | 0xFF | %rax | 0x100 |
| 0x104 | 0xAB | %rcx | 0x1 |
| 0x108 | 0x13 | %rdx | 0x3 |
| 0x10C | 0x11 |
풀이
M(주소)는 해당 주소 메모리에 할당된 값
R(이름)는 해당 이름 레지스터에 할당된 값
| Operand | Value | 타입 | 풀이 |
|---|---|---|---|
| %rax | 0x100 | 레지스터 | R(%rax) |
| 0x104 | 0xAB | 메모리 | M(0x104) |
| $0x108 | 0x108 | 즉시 | 상수 0x108 |
| (%rax) | 0xFF | 메모리 | M(%rax) |
| 4(%rax) | 0xAB | 메모리 | M(4 + %rax = 0x104) |
| 9(%rax,%rdx) | 0x11 | 메모리 | M(9 + %rax + %rdx = 0x10C) |
| 260(%rcx,%rdx) | 0x13 | 메모리 | M(260 + 0x1 + 0x3 = 0x108) |
| 0xFC(,%rcx,4) | 0xFF | 메모리 | M(0xFC + (0x1 * 4) = 0x100) |
| (%rax,%rdx,4) | 0x11 | 메모리 | M(0x100 + (0x3 * 4) = 0x10C) |
3.4.2 데이터 이동 인스트럭션
데이터 이동 클래스(MOV)
- movb
- movw
- movl
- movq
모두 비슷하다. 어떤 크기의 데이터를 계산하는지가 차이
b, w, l, q는 지정된 레지스터 크기와 일치해야 한다. -각각 1, 2, 4, 8 바이트
단, movl이 레지스터가 목적지인 경우 상위 4바이트가 0으로 자동 설정됨.
(관습에 의함. 32비트 값을 생성하는 인스트럭션은 상위도 0으로 하는 관습이 있음.)
(32비트와 64비트 간의 호환성 문제가 생길 수 있음)
(x86-64에서 32비트 연산을 할 때 실수로 상위 비트에 예기치 않은 데이터 남는 것 방지)
RAX는 8바이트 레지스터이다. 이중 하위 32비트는 EAX로 접근할 수 있다.
다음 명령어에서 EAX에 값을 할당하면 자동으로 상위 32비트가 0으로 설정된다.
movl $0x12345678, %eax
// RAX value: 0x0000000012345678
데이터 이동 프로세스
x86-64에서는 2개의 오퍼랜드에 모두 메모리 위치가 올 수 없다.
(즉, 하나의 인스트럭션으로 데이터 이동 불가)
1. 소스 값을 레지스터에 적재
2. 이 레지스터 값을 목적지에 쓰기
값을 이동하는 인스트럭션
(인스트럭션, 소스 오퍼랜드, 목적지 오퍼랜드)
movl $0x4050,%eax // %eax 레지스터에 4바이트(long)의 0x4050값을 이동(복사)
(그리고 %rax의 나머지 상위 4바이트를 0으로 초기화)
movw %bp,%sp // 2바이트(word)의 %bp 레지스터 값을 %sp로 이동(복사)
movb (%rdi,%rcx),%al // %rdi와 %rcx의 합으로 얻어진 주소 1바이트 값을 %al 레지스터로 이동(복사)
movb $-17,(%rsp) // 1바이트 상수 -17을 %rsp 레지스터에 저장된 메모리 주소로 이동(복사)
movq %rax,-12(%rbp) // %rax에 저장된 8바이트(quadword)값을 %rbp레지스터에 저장된 메모리 주소에서 12를 뺀 주소에 이동(복사)오퍼랜드가 없는 cltq 인스트럭션
cltq는 레지스터 %eax를 소스로, %rax를 목적지로 사용해서 부호 확장 결과를 만든다.
movslq %eax, %rax와 동일한다.
s: Sign-extend
l: Long
q: Quadword
32비트 값을 64비트 값으로 부호 확장(sign-extend)한다.
-> 64비트의 나머지 비트를 32비트의 최상위 비트(부호)로 채운다.
0xFFFFFFFF(-1을 2의 보수로 나타낸 값)을 0xFFFFFFFFFFFFFFFF로 확장
3.4.3 데이터 이동 예제
C에서 포인터가 어셈블리어에서는 단순히 주소다.
즉, 포인터를 역참조하는 과정을 어셈블리어에서는 해당 포인터를 레지스터에 복사하고,
그 레지스터에 저장된 주소로 메모리에서 값을 읽어 오는 것!
3.4.4 스택
스택의 탑 원소가 오든 스택 원소 중 가장 낮은 주소
스택은 아래 방향으로 성장(관습적으로 스택은 위아래를 뒤집어서 그림.)
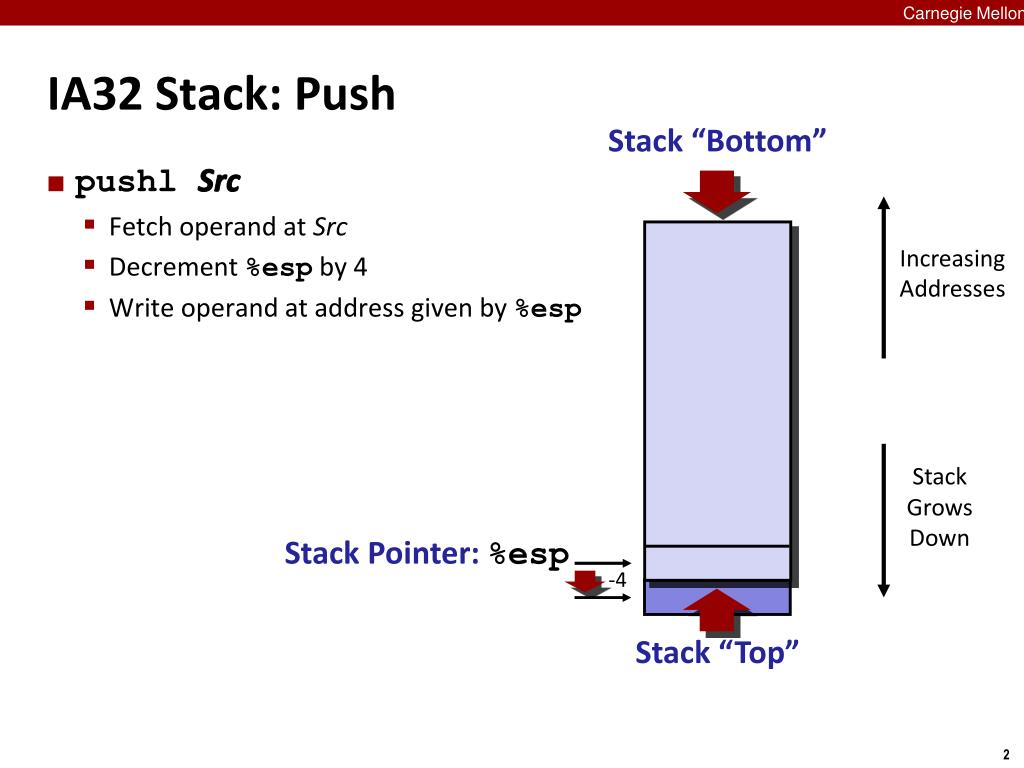
스택에 데이터를 추가하는 과정을 살펴보자
(쿼드워드 값 추가 가정)
1. 스택 포인터 8감소
2. 해당 값을 스택 주소의 새로운 탑에 기록
subq &8,%rsp
movq %rbp,(%rsp)%rsp는 스택 맨 위 원소의 주소
현재 스택의 탑에 8(쿼드워드의 경우)을 증가시켜서 다음 메모리를 가리키게 하고,
거기에 새로운 값을 할당하면 스택에 값이 추가된다!
스택에 데이터를 pop하는 과정을 살펴보자
(쿼드워드 값 pop 과정)
1. 스택 포인터 8증가
movq (%rsp),%rax // %rsp는 top의 메모리 주소이다. ()를 통해 메모리 값을 읽어와서 %rax에 복사
addq $8,%rsp // %rsp에 저장된 스택 포인터의 값을 8 증가시킨다.실제 직전 탑 위치의 데이터를 지우는게 아니라 단순히 스택 포인터만 이동한다.
그래서 다른 값이 덮어씌어지기 전까지 직전 탑에 있는 데이터는 메모리에 여전히 남아 있는다.
3.5 산술연산과 논리연산
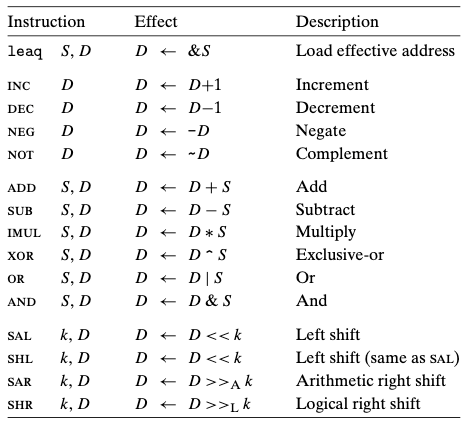
3.5.1 유효주소 적재(Load Effective Address)
유효주소 적재 인스트럭션
leaq (movq의 변형)
leaq 7(%rdx, %rdx, 4) // 레지스터 %rdx에 5x + 7을 저장
// 아래의 경우는 배열의 다음 배열을 참조하는 인스트럭션
leaq 8(%rbx), %rax(%rbx)처럼 괄호가 있다고 무조건 해당 값의 주소는 참조하는 건 아님!
어떤 인스트럭션에서 사용됐는지에 따라 다름.
leaq 8(%rbx), %rax에서는 메모리를 참조 하지 않지만,
movq 8(%rbx), %rax에서는 메모리를 참조 함.
이 과정에서 주소를 대상으로 연산만 할 뿐, 그 주소를 참조하지는 않는다!
이렇게 연산된 결과를 '유효 주소'라고 함.
컴파일러는 메모리 값을 읽어올 필요 없는 경우 leaq를 적절히 사용한다.
3.5.2 단항 및 이항 연산
단항 연산
incq %rax // %rax의 값을 1 증가시킴
decq %rax // %rax의 값을 1감소 시킴다항 연산
addq %rcx, %rdx // %rcx의 값과 %rdx의 값을 더하고, %rdx에 저장
subq %rsi, %rdi // %rdi에서 %rsi값을 뺀 후, %rdi에 저장
imulq %r8, %r9 // %r9의 값과 %r8의 값을 곱한 후, %r9에 저장
이 경우에도 move와 마찬가지로 두 오퍼랜드가 모두 메모리 주소가 될 수는 없다.
중간에 레지스터를 이용해야 한다.
3.5.3 (비트) 쉬프트 연산
비트를 왼쪽 또는 오른쪽으로 이동시키는 연산
Left Shift
주어진 비트열을 왼쪽으로 특정 수만큼 이동
벗어나는 왼쪽은 버려지며, 오른쪽은 0으로 채워짐
101(2)을 왼쪽 시프트 하면 1010(2)
좌측 시프트는 SAL, SHL이 있다. 모두 동일한 효과.
Right Shift
주어진 비트열을 오른쪽으로 특성 수만큼 이동
벗어나는 오른쪽은 버려지며, 왼쪽은 0으로 채워지거나(SHR) 그 전 최상위 비트 값(0 or 1)으로 채워질 수도 있음.(SAR)
(부호를 유지하려면 최상위 비트가 유지되어야 함.)
우측 시프트 SHR(Shift Right)은 0으로 채운다.(논리 시프트)
우측 시프트 SAR(Shift Arithmetic Right)은 부호 비트를 복사해서 채운다.
sarq $9, %rdx // %rdx에 저장된 값의 비트를 오른쪽으로 9번 이동 시킨다.3.5.5 특수 산술연산
64비트 간의 곱셈은 결과에 128비트가 필요한다.
mulq(비부호형)
(sign bit가 없어 양수 또는 0으로만 해석)
movq $10, %rax ;%rax에 10을 저장
movq $20, %rbx ;%rbx에 20을 저장
mulq %rbx ; %rax와 %rbx읠 값을 곱함.(=200(0xC8)imulq(2의 보수 곱셈)
(i는 integer를 의미)
; 두 피연산자를 사용하는 경우
movq $-10, %rax ;%rax에 -10을 저장
movq $20, %rbx ;%rbx에 20을 저장
imulq %rbx, %rax ; %rax에 -10 * 20 = -200 결과 저장
; 세 연산자를 사용하는 경우
movq $-10, %rax ; %rax에 -10을 저장
movq $20, %rbx ; %rbx에 20을 저장
imulq $3, %rax, %rcx ; %rcx에 -10 * 3 = -30 결과 저장나눗셈도 곱셈과 비슷한다.
divq(비부호형); 목표: 10을 2로 나눈다. movq $10, %rax ; RAX에 10 저장 xorq %rdx, %rdx ; RDX를 0으로 초기화 movq $2, %rbx ; RBX에 2 저장 divq %rbx ; RDX:RAX (즉, 10)을 RBX로 나눈다. RAX에는 몫 (5)이 저장되고, RDX에는 나머지 (0)가 저장됨.
idivq(2의 보수 나눗셈)
; 목표: 10을 2로 나눈다.
movq $10, %rax ; RAX에 10 저장
xorq %rdx, %rdx ; RDX를 0으로 초기화 (부호 확장을 위함)
movq $2, %rbx ; RBX에 2 저장
idivq %rbx ; RDX:RAX (즉, 10)을 RBX로 나눈다. RAX에는 몫 (5)이 저장되고, RDX에는 나머지 (0)가 저장됨.각각 초기화 하는 이유는 나눗셈은 두 개의 64비트 레지스터를 마치 하나의 128레지스터처럼 사용하기 때문에 계산의 안정성을 위해서 당장 계산에 사용되지 않는 레지스터는 0으로 초기화
movq처럼 명령어 다음에 꼭 접미사를 써야 할까?
안 써도 오퍼랜드 크기를 자동으로 유추할 수 있는 경우에는 생략 가능!
(%rax는 64비트 레지스터니까 생략해도 알아서 8비트(쿼브워드)로 유추함)
하지만 상수와 메모리 오퍼랜드 사용할 때는 크기를 명시적으로 지정하는 게 좋음.
3.6 제어문
3.6.1 조건 코드
조건 코드를 구현하기 위해 단일 비트 조건 코드로 구성된 특별한 레지스터가 있음.
(기존 16개의 범용 레지스터와 다름)
대표적인 플래그 레지스터
CF(Carry Flag)(부호 없는 오버플로우)
가장 최근 연산에서 MSB(최상위 비트)에 받아 올림이 발생한 것 표시. 비부호형 연산에서 오버플로우 검출 시 사용
연산 중 오버플로우나 언더플로우가 발생하면 1로 설정
(최상위 비트에서 덧셈 받아올림, 뺄셈 받아내림)
부호 없는 정수의 최대값(2^64 - 1)에서 +1이 되면 오버 플로우가 발생하여 0으로 간주된다.
PF(Parity Flag)
결과 값의 최하위 바이트 내의 1의 개수가 짝수면 1로 설정
ZF(Zero Flag)
가장 최근 연산의 결과가 0이면 1로 설정
SF(Sign Flag)
가장 최근 연산이 음수면 1로 설정
OF(Overflow Flag)(부호 있는 오버플로우)
가장 최근 연산이 양수/음수의 2의 보수 오버플로우(2^63 - 1)면 1로 설정
3.6.2 조건 코드(플래그 레지스터) 사용하기
조건 코드를 직접 읽지 않고 조건 코드를 이용하는 방법
1. 조건 코드 조합에 따라 0 또는 1을 한개의 바이트에 기록
leaq 인스트럭션은 주소 계산만 하니까 조건 코드를 바꾸지 않지만,
나머지 인스트럭션은 연산 결과에 따라 조건 코드를 바꿀 수 있다.
(조건 코든느 연산 결과를 기반으로 변경된다.)
Set 인스트럭션
sete: ZF (Zero Flag)가 1일 경우 대상에 1을 설정합니다.
setne: ZF (Zero Flag)가 0일 경우 대상에 1을 설정합니다.
sets: SF (Sign Flag)가 1일 경우 대상에 1을 설정합니다.
setns: SF (Sign Flag)가 0일 경우 대상에 1을 설정합니다.
cmp eax, ebs ; eax와 ebx를 비교
sete a1 ; 두 결과가 같으면 a1 레지스터에 1 저장, 아니면 0 저장조건 코드가 뭐야?
조건 코드는 X86 아키텍처의 플래그 래지스터의 내부의 특정 플래그들을 지칭!
2. 조건에 따라 프로그램의 다른 부분으로 이동
3. 조건에 따라 데이터를 전송하는 방법
3.6.3 점프(JUMP) 인스트럭션
일반적인 인스트럭션이 나열된 순서에 따라 순차 실행되는 반면,
점프 인스트럭션은 완전시 새로운 위치에서 프로그램이 실행된다.
점프 목적지를 label로 표시한다.
jmp *%rax ;%rax에 저장된 메모리 주소로 직접 이동
jmp *(%rax) ;%rax에 저장된 메모리 주소에 저장된 메모리 주소로 이동3.6.4 점프 인스트럭션 인코딩
movq %rdi, %rax ; %rdi의 값을 %rax로 복사합니다.
jmp .L2 ; .L2 레이블로 점프합니다.
.L3:
sarq %rax ; %rax 값을 오른쪽으로 1비트 산술 시프트합니다.
.L2:
testq %rax, %rax ; %rax의 값을 테스트합니다.
jg .L3 ; %rax의 값이 양수인 경우 .L3 레이블로 점프합니다.
rep; ret ; 함수를 종료합니다.3.6.5 조건부 분기 조건제어
jmp: 무조건적 점프 (조건 코드를 확인하지 않고 항상 분기)
je (Jump if Equal): ZF가 설정되어 있는 경우 분기
jne (Jump if Not Equal): ZF가 설정되어 있지 않은 경우 분기
jg (Jump if Greater): SF와 OF가 같고 ZF가 설정되어 있지 않은 경우 분기
jl (Jump if Less): SF와 OF가 다르고 ZF가 설정되어 있지 않은 경우 분기
조건부 제어 이동 기반 코드
section .data
; 데이터 섹션: 메시지 문자열 저장
hello db 'Hello, World!',0
section .text
global _start
_start:
; 조건부 점프 명령어 (JZ: 제로 플래그가 설정되었을 때 점프)
; 이 코드는 제로 플래그(ZF)가 설정되면 'hello' 문자열을 출력하고, 그렇지 않으면 종료합니다.
; 비교 명령어 (CMP: 두 값을 비교하여 제로 플래그 설정)
cmp eax, eax ; eax와 eax를 비교 (항상 같으므로 ZF가 설정됨)
jz .print_hello ; ZF가 설정되면 'print_hello' 레이블로 점프
jmp .exit ; 그렇지 않으면 'exit' 레이블로 점프
.print_hello:
; 메시지 출력
mov eax, 4
mov ebx, 1
mov ecx, hello
mov edx, 13
int 0x80
.exit:
; 종료 시스템 콜
mov eax, 1
int 0x80jmp와 jge는 무슨 차이일까?
jmp는 무조건적 점프. 조건을 검사하지 않고 항상 지정된 목적지로 점프.
jge는 부호가 크거나 같음(Jump if Greator or Equal)을 검사
3.6.6. 조건부 데이터 이동으로 조건부 분기 구현
조건부 데이터 이동 기반 코드
section .data
; 데이터 섹션: 두 정수 저장
num1 dd 10
num2 dd 20
section .text
global _start
_start:
; 조건부 데이터 이동 명령어 (CMOV: 조건에 따라 레지스터 값을 이동)
; 이 코드는 num1이 num2보다 크면 num1 값을 num2에 복사하고, 그렇지 않으면 그대로 둡니다.
; 비교 명령어 (CMP: 두 값을 비교하여 ZF 설정)
mov eax, [num1] ; num1의 값을 eax 레지스터로 로드
mov ebx, [num2] ; num2의 값을 ebx 레지스터로 로드
cmp eax, ebx ; eax와 ebx를 비교하여 ZF 설정
cmovg eax, ebx ; ZF가 설정되면 eax에 ebx 값을 복사 (num1 > num2)
; ZF가 설정되지 않으면 eax는 그대로 (num1 <= num2)
; 결과를 출력
; (eax 레지스터에는 더 큰 값이 들어가 있음)
; 여기서는 출력 코드는 생략합니다.
조건부 제어 이동 기반 코드와 조건부 데이터 이동 코드는 무슨 차이?
조건부 제어 이동 기반 코드는 조건부 분기 명령어(je, jg 같은 거)를 사용하여 프로그램 흐름 제어
어떤 조건이 '참'일 때 실행하는 경우에 사용
조건부 데이터 이동 코드는 cmov같은 걸로 조건을 검사하고 충족되면 데이터를 이동, 복사
어떤 값이 음수인 경우에 값을 복사하는 경우
일반적으로 제어 이동 기반보다 데이터 이동 기반이 성능이 더 좋다.
제어 기반으로 실행 순서가 바뀌면 프로세서가 예측하기 어려워 함. 파이프라인이 끊기는 경우 생김.
반면 데이터 기반은 분기가 나뉘는 경우가 더 적고, 데이터를 바탕으로 실행 순서 예측이 용이하기 때문
3.6.7 반복문
C를 간단하게 훑어보고 다양한 반복문 구문이 어셈블리어로 어떻게 대응되는지 하나씩 훑어보기!
C에서는 여러 반복문 구문을 제공하지만 기계어에는 여기에 대응되는 인스트럭션이 없다?!
조건부 테스트와 점프를 사용해 반복문의 효과를 구현하는 것!!
조건부 테스트?
플래그 레지스터의 상태를 확인하고 이 값을 기반으로 조건을 판단
test, cmp, jcc(Jump if Condition is met) 등이 있음.
3.6.8 Switch문
어셈블리어로 변환될 때 소스코드를 그대로 1:1로 변환하는 건 아니다.
컴파일러가 코드를 평가하여 필요 없는 부분은 조정하거나, 최적화를 시킬 수 있다.
이 과정에서 일부 스위치 케이스가 디폴트로 통합되거나, 순서가 조정될 수도 있다.
3.7 프로시저
프로시저는 일반적으로 어떤 작업을 수행하는 코드의 논리적인 묶음
프로시저는 특정 기능을 구현하는 큰 범위의 추상화
함수나 메서드는 프로시저의 구체적인 형태이다.
3.7.1 런타임 스택
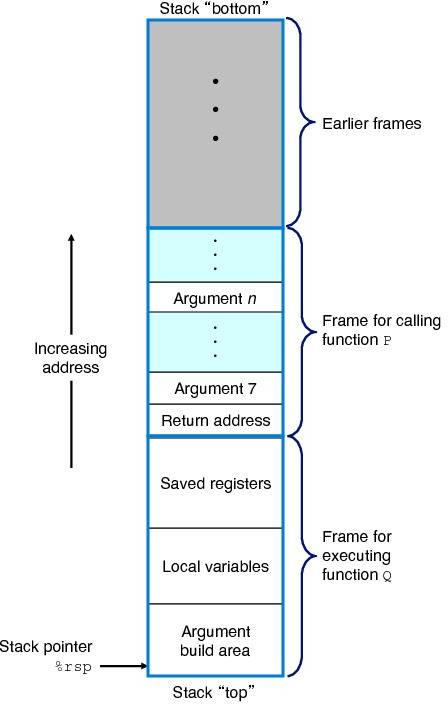
대부분의 언어에서 프로시저 호출 동작은 스택 자료구조 기반으로 진행(후입선출)
(복습) 스택은 낮은 주소로 차오른다.
즉, 프로시저를 호출할 때는 다음으로 낮은 주소에 프로시저를 할당하고 스택 포인터를 감소시키고,
프로시저를 반납할 때는 스택 포인터만 올리면 된다.
스택 프레임이란?
프로시저가 레지스터를 초과하는 저장 공간이 필요할 때 공간을 스택에 할당하는데
이 영역을 이 프로시저의 스택 프레임이라고 부름
프로시저마다 스택 프레임은 독립적으로 존재하며, 주로 스택 메모리 영역에 할당됨.
스택 포인터(SP)를 통해 접근
프로시저 실행 중에 필요한 로컬 변수, 매개 변수, 복귀 주소, 기타 제어 정보 등의 정보를 저장하는데 사용함.
프로시저가 호출될 때 스택 프레임이 생성되고, 프로시저가 종료되면 스택 프레임이 제거됨.
스택 프레임마다 크기가 다를 수 있고, 동적으로 조절됨.
매개변수가 적은 함수인 경우 레지스터로 충분하기 때문에 스택 프레임을 요청하지 않는 경우도 많음.
프로시저마다 스택 프레임은 독립적으로 존재하며, 주로 스택 메모리 영역에 할당됨.
이게 뭔 말임?
시스템 전체 물리 메모리 중 일부가 스택 메모리 영역으로 할당되어 있으며, 이 영역은 프로그램 실행 중에 사용되는 데이터를 저장하는 목적으로 사용.
스택 프레임은 이 스택 메모리 영역에 할당됨.
근데 스택 프레임이 독립적으로 생성됐는데 스택이 증가하면서 서로 침범할 수도 있나?
놉, 겹칠 일 없음. 스택 프레임은 각각 고유한 영역을 할당받는데, 특정 스택 프레임의 스택이 계속 쌓인다고 해도 스택이 넘치면 스택 오버플로우 등으로 에러가 발생하기 때문.
링크드 리스트(linked likst)
파이썬으로 단방향 링크드 리스트 구현
class Node:
def __init__(self, data):
self.data = data
self.next_node = None
class LinkedList:
def __init__(self):
self.head = None
def is_empty(self):
return self.head is None
def append(self, data):
new_node = Node(data)
if self.is_empty():
self.head = new_node
else:
current = self.head
while current.next_node is not None:
current = current.next_node
current.next_node = new_node
def prepend(self, data):
new_node = Node(data)
new_node.next_node = self.head
self.head = new_node
def delete(self, data):
if self.head is None:
return
if self.head.data == data:
self.head = self.head.next_node
return
current = self.head
while current.next_node is not None:
if current.next_node.data == data:
current.next_node = current.next_node.next_node
return
current = current.next_node
def display(self):
current = self.head
while current:
print(current.data, end=" -> ")
current = current.next_node
print("None")
my_list = LinkedList()
my_list.append(1)
my_list.append(2)
my_list.append(3)
my_list.display() #1 -> 2 -> 3 -> None
my_list.delete(2)
my_list.display() #1 -> 3 -> None파이썬으로 양방향 리스트 구현
class DoublyNode:
def __init__(self, data):
self.data = data
self.next_node = None
self.prev_node = None
class DoublyLinkedList:
def __init__(self):
self.head = None
self.tail = None
def is_empty(self):
return self.head is None
def append(self, data):
new_node = DoublyNode(data)
if self.is_empty():
self.head = new_node
self.tail = new_node
else:
new_node.prev_node = self.tail
self.tail.next_node = new_node
self.tail = new_node
def prepend(self, data):
new_node = DoublyNode(data)
if self.is_empty:
self.head = new_node
self.tail = new_node
else:
new_node.next_node = self.head
self.head.prev_node = new_node
self.head = new_node
def delete(self, data):
current = self.head
while current:
if current.data == data:
if current.prev_node:
current.prev_node.next_node = current.next_node
else:
self.head = current.next_node
if current.next_node:
current.next_node.prev_node = current.prev_node
else:
self.tail = current.prev_node
return
current = current.next_node
def display_forward(self):
current = self.head
while current:
print(current.data, end=" <-> ")
current = current.next_node
print("None")
def display_backward(self):
current = self.tail
while current:
print(current.data, end=" <-> ")
current = current.prev_node
print("None")
# 양방향 링크드 리스트 생성
my_list = DoublyLinkedList()
# 데이터 추가
my_list.append(1)
my_list.append(2)
my_list.append(3)
# 데이터 출력 (정방향)
my_list.display_forward() # 출력: 1 <-> 2 <-> 3 <-> None
# 데이터 출력 (역방향)
my_list.display_backward() # 출력: 3 <-> 2 <-> 1 <-> None
# 데이터 삭제
my_list.delete(2)
# 삭제 후 데이터 출력 (정방향)
my_list.display_forward() # 출력: 1 <-> 3 <-> None
# 삭제 후 데이터 출력 (역방향)
my_list.display_backward() # 출력: 3 <-> 1 <-> None병원 가야 해서 18:00 퇴실.
다음 주 11시에 온다. 금요일 오후, 토, 일, 월요일 오전까지 빈다.
비어 있는 시간 동안 C 포인터 확실하게 이해하고 링크드 리스트 C로 구현해 볼 예정!
CSAPP은 우선 3장 1회독으로 전체적인 흐름 잡고 연습문제 풀어보기!
다행히 아예 이해가 안 되지는 않음.
숫자를 더하고 빼고 하는 그런 어셈블리어의 동작으로 컴퓨터가 동작한다는 게 경이로움 그 자체다..
초창기에 어셈블리어로 코딩하던 사람들은.. 가능한가?
