수원역에서 바로 강의실 입실 10:40
CSAPP 밀린 진도 부지런히 따라가기
3.7.2 제어의 이동
인스트럭션 call Q
주소 A(리턴 주소)를 스택에 푸시
(리턴 주소: call 인스트럭션 바로 다음 인스트럭션 주소)
PC를 Q의 시작으로 설정
인스트럭션 ret
주소 A를 스택에서 팝
PC를 A로 세팅
3.7.3 데이터 전송
프로시저로부터 데이터 전달은 레지스터를 통해 일어남
교재에는 레지스터에 함수 인자를 6개까지 전달하는 것이 예시로 나와 있다.ㄷ
그럼 6개 초과 함수 인자는 전달하지 못하는 걸까?
아님! 인자 1~6은 레지스터로 전달되며, 인자 7~8은 스택에 전달!
3.7.4 스택에서의 지역저장공간
지역 데이터가 메모리에 저장되어야 하는 경우
- 지역 데이터에 비해 레지스터가 부족
- 지역변수에 연산자 '&'이 사용되고, 변수의 주소가 필요
- 배열 또는 구조체 타입은 참조로 접근되어야 한다.
3.7.5 레지스터를 이용하는 지역저장소
프로시저P가 프로시저Q를 호출할 때,
Q는 Q가 P로 리턴될 때 Q 호출 당시의 레지스터 값을 보존해야 함.
Q는 원래 레지스터 값을 변경하지 않거나,
이 값을 스택에 푸시해두고 우선 레지스터 값을 변경하고,
리턴하기 전에 스택에서 값을 팝하는 방식으로 레지스터는 보존한다.
3.7.6. 재귀 프로시저
(연습문제 풀어보기)
3.8 배열의 할당과 접근
스칼라 데이터가 뭐야?
정수, 실수, 문자, 불리언 같은 그 자체로 하나의 값인 데이터
(반대 개념으로는 구조체, 배열, 리스트 등이 있음)
3.8.1 기본 원리
배열 E에서 E[i]를 읽어오는 상황
E의 주소는 %rdx에 저장
i는 %rcx에 저장
xE + 4i 주소 계산 후 메모리 위치를 읽어서 그 결과를 %eax에 저장
movl (%rdx,%rcx,4),%eax
C에서 문자열 할당
// 12의 문자를 저장, 메모리의 연속된 위치에 저장
char A[12];
// 크기가 8인 char 포인터 타입 배열
// 8개의 문자열 포인터를 저장(각각 다른 문자열을 가리킬 수 있음)
char *B[8];3.8.2 포인터 연산
#include <stdio.h>
int main() {
int x = 10; // 정수 변수 x를 선언하고 10으로 초기화
int *p; // 정수 포인터 p를 선언
p = &x; // x의 주소를 p에 할당
*p = 20; // p가 가리키는 주소 (x의 주소)의 값을 20으로 변경
return 0;
}3.8.3 다중 배열
C에서 2차원 배열은 1차원 배열로 메모리에 저장된다.
다중 배열의 메모리 주소 계산법
메모리 주소 = 베이스 주소 + (i * 1행의 수 + j) * 데이터 사이즈
(int 기준)
arr[2][3] = base add + (2 * 4 + 3) * 4
3.8.4 고정크기의 배열
3.8.5 가변크기 배열
3.9 이기종(Heterogeneous 자료구조)
이기종 = 이질적인, 서로 다른
C에서 서로 다른 유형 객체를 연결해서 자료형 만드는 방법
1. struct(구조체): 다수의 객체를 하나의 단위로 연결
2. union(공용체): 하나의 객체를 여러 개의 다른 자료형으로 참조
3.9.1 구조체(structure)
서로 다른 유형의 객체들을 하나의 객체로 묶어주는 자료형을 생성
마치 배열처럼 메모리의 연속된 영역에 저장됨.
구조체의 포인터가 첫 번째 바이트의 주소다.
struct rec {
int i;
int j;
int a[2];
int *p;
};
3.9.2. 공용체(union)
공용체를 선언하는 문법은 구조체와 동일하나 의미가 다르다.
구조체에서는 각각의 데이터 타입이 메모리에 연속해서 할당되지만,
공용체에서는 모든 멤버가 메모리를 공유하며, 가장 큰 데이터 타입의 크기가 해당 공용체의 전체 크기가 된다.
공용체에 선언된 여러 데이터 타입 중 한 번에 하나의 타입의 값만 저장
struct S3 {
char c;
int i[2];
double v;
};
union U3 {
char c;
int i[2];
double v;
};
// 공용체 선언
union U3 foo;3.9.3 데이터의 정렬
(많은 프로세서 아키텍처에서) 특정 데이터 타입은 해당 크기의 배수에 해당하는 주소에서 시작되어야 한다.
예) 4바이트 정수는 4의 배수 주소에서 시작되어야 함.
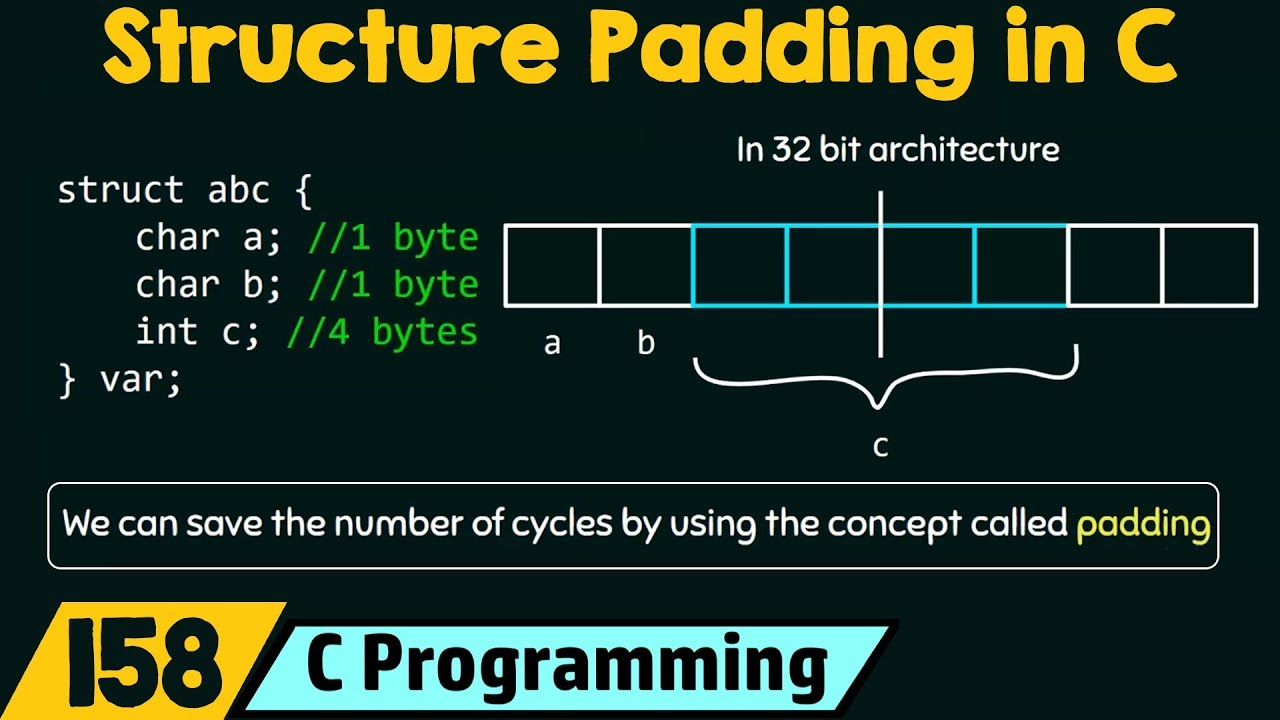
구조체 관련 코드에서 컴파일러는 각 구조체의 원소들이 각각의 정렬 요구 사항을 만족하도록 필드 할당 시 빈 공간을 삽입한다.(padding)
struct Sample {
char a; // 1 byte
int b; // 4 bytes (가정)
};int가 4바이트 경계에 정렬되어야 한다면 char a에는 3바이트 패딩이 삽입될 수 있다.
따라서 struct Sample의 실제 메모리는 8바이트가 될 수 있다.
코드 상에서 요청한 메모리보다 컴파일 후 할당된 메모리가 더 클 수 있음!
정렬 조건(제한)이 뭐야?
예) int 타입의 시작 주소는 4의 배수여야 한다.
double 타입의 시작 주소는 8의 배수여야 한다.
만약 8의 배수인 주소에서 값을 인출하는 프로세서에서
double값이 8의 배수라고 보장할 수 있으면 메모리 접근은 한 번으로 끝남.
하지만 그렇지 않으면, 해당 메모리 블록을 한 번에 다 읽어오지 못하기 때문에
두 번 접근해야 하는 일이 발생함.
char는 어차피 1바이트라서 거의 문제가 발생하지 않지만, int부터는 정렬이 되지 않으면 한 번에 못 읽어올 수도 있음.
일반적으로 데이터를 읽어오는 단위는 프로세서의 워드 크기 또는 데이터 버스 너비에 의존함.
32비트 프로세서의 경우 대체로 4바이트 단위로,
64비트 프로세서의 경우 대체로 8바이트 단위로 읽어 옴.
3.10 제어와 데이터 결합
3.10.1 포인터 이해하기
포인터는 연관된 자료형을 갖는다.
모든 포인터는 특정 값을 가진다.(NULL(0)은 아무 곳도 가리키지 않는 것 의미)
&연산자로 만든다.
*연산자로 역참조한다. -> 포인터와 연관된 자료형을 갖는 값을 가져옴
배열과 포인터는 밀접한 관련이 있다.
포인터는 함수를 가리킬 수도 있다.
3.10.2 GDB
3.10.3 범위를 벗어난 메모리 참조, 버퍼 오버 플로우
C에서 gets() 함수는 입력되는 데이터의 길이를 검사하지 않기 때문에 버퍼 오버플로우가 발생할 수 있다.
#include <stdio.h>
int main() {
char buffer[10];
printf("Enter yout name: ");
gets(buffer);
printf("Hello, %s!\n", buffer);
return 0;
}위 경우 10바이트를 넘어가는 문자를 입력하면 나머지가 스택에 쌓이며 다른 데이터를 손상시킬 수 있다.
fgets()로 이 문제를 해결할 수 있다.
'버퍼'는 스택이나 힙 처럼 메모리의 특정 영역을 지칭하는 말이 아니다. 어떤 데이터를 연속적으로 담는 임시 공간을 '버퍼'라고 한다. 버퍼는 스택이나 힙, 또는 다른 메모리 영역에 적재될 수 있다.
3.10.4 버퍼 오버플로우 공격 대응 기법
공격자의 목표는 쉘코드를 실행시키는 것!
공격자는 버퍼 오버 플로우를 통해 스택에 NOP sled와 쉘코드를 삽입
버퍼 오퍼 플로우로 인해 함수의 반환 주소가 덮어씌여지고 NOP sled코드가 실행되며
궁극적으로 쉘 코드에 도달함.
1. 스택 랜덤화
alloca함수로 랜덤하게 미사용 공간을 지정하여 스택 포인터를 랜덤화한다.
n이 너무 크면 낭비가 생기며, 너무 적으면 변화가 적어 보안에 취약해진다.
스택 랜덤화는 Address Space Layout Randomization(ASLR)의 한 부분
스택 랜덤화 예시
스택 랜덤화 없이 프로그램 실행:
첫 번째 실행: 스택 시작 주소 = 0x7fffe000
두 번째 실행: 스택 시작 주소 = 0x7fffe000
세 번째 실행: 스택 시작 주소 = 0x7fffe000
스택의 시작 주소가 항상 동일하므로, 공격자는 이 주소를 기반으로 공격 코드를 작성할 수 있습니다.
스택 랜덤화로 프로그램 실행:
첫 번째 실행: 스택 시작 주소 = 0x7fffd234
두 번째 실행: 스택 시작 주소 = 0x7fffa987
세 번째 실행: 스택 시작 주소 = 0x7fffbcde
스택의 시작 주소가 매번 다르므로, 공격자는 어디에 쉘 코드나 공격 코드를 위치시켜야 할지 예측하기 어려워집니다.
NOP Sled
NOP(No Operation)은 CPU에게 아무 일도 하지 않고 다음 명령어로 넘어가라는 명령어.
x86에서는NOP이0x90바이트로 표현됨.
NOP Sled는 이러한 NOP 명령어의 시퀀스를 의미하고, 공격자는 실행 흐름을 NOP Sled 중 특정한 부분으로 로 옮기기만 하면 NOP Sled가 계속해서 실행되며 끝나는 시점에서 쉘 코드(공격자 코드)로 실행 흐름을 이동시킬 수 있음.
2. 스택 손상 검출
카나리(canary)값을 비교하여 손상 여부 검증
함수 호출 시 초기화되며, 함수 종료 전 변조 여부를 체크
3. 실행코드 영역 제한하기
공격자가 실행코드를 추가할 가능성을 제거
-> 컴파일러가 만든 코드를 저장하는 메모리 부분만 실행 가능하게
-> 나머지 부분은 읽기와 쓰기만 허용(실행은 금지)
3.10.5 가변크기 스택 프레임 지원하기
%rbp를 프레임포인터로 사용
프레임 포인터는 현재 실행 중인 함수의 스택 프레임의 시작점을 가리키는 레지스터
3.11 부동소수점 코드
%ymm0 ~ %ymm15의 16개의 YMM 레지스터에 저장됨.
부동소수점 데이터만 보관함.
float는 하위 32비트, double은 64비트를 사용.
3.11.1 부동소수점 이동 및 변환 연산
C 포인터 실습
#include <stdio.h>
int main() {
int x = 10;
int *p;
p = &x;
printf("x의 값: %d\n", x);
printf("x의 주소: %p\n", &x);
printf("p의 값(x의 주소): %p\n", p);
printf("p가 가리키는 값: %d\n", *p);
return 0;
}Longest Common Subsequence
최장 공통 부분 수열: 두 문자열의 가장 긴 공통 부분 문자열을 찾는 문제
(부분 수열: 어떤 주어진 수열에서 일부 원소를 선택하여 만들어진 새로운 수열.
순서는 유지해야 하지만 연속적일 필요는 없다.)
대표적인 DP 문제! 2차원 리스트를 만든다.(DP테이블)
LCS 점화식
값이 같을 때: DP[i][j] = DP[i-1][j-1] + 1
값이 다를 때: PD[i][j] = Math.max(DP[i-1][j], DP[i][j - 1])
https://www.youtube.com/watch?v=ukb5aVT64uY
백준 9251 LCS
import sys
A = sys.stdin.readline().strip()
B = sys.stdin.readline().strip()
dp = [[0 for _ in range(1001)] for _ in range(1001)]
la, lb = len(A), len(B)
for i in range(1, la + 1):
for j in range(1, lb + 1):
if A[i - 1] == B[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
print(dp[la][lb])| - | C | A | P | C | A | K |
|---|---|---|---|---|---|---|
| A | 0 | 1 | 1 | 1 | 1 | 1 |
| C | 1 | 1 | 1 | 2 | 2 | 2 |
| A | 1 | 2 | 2 | 2 | 3 | 3 |
| Y | 1 | 2 | 2 | 2 | 3 | 3 |
| K | 1 | 2 | 2 | 2 | 3 | 4 |
| P | 1 | 2 | 3 | 3 | 3 | 4 |
DP 테이블의 각 0행과, 0열은 '0'으로 채워져 있음.
DP 더미 테이블 만들기!
dp = [[0 for _ in range(1001)] for _ in range(1001)]
Knapsack Problem(배낭 채우기 문제)
대표적인 DP 문제!
백준 12865 평범한 배낭
대략적인 흐름은 알겠는데 코딩은 못 하겠음. 연습 필요.
import sys
def knapsack(N, K, items):
dp = [[0] * (K + 1) for _ in range(N + 1)]
for i in range(1, N + 1):
for j in range(1, K + 1):
weight, value = items[i - 1]
if weight <= j:
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight] + value)
else:
dp[i][j] = dp[i - 1][j]
return dp[N][K], dp
N, K = map(int, sys.stdin.readline().strip().split())
items = [tuple(map(int, input().split())) for _ in range(N)]
max_value, dp_table = knapsack(N, K, items)
print(max_value)이 코드에서는 최대 가치만 카운팅한다.
구체적으로 어떤 아이템이 들어가는지는 별도의 로직이 필요하다.
즉 직전까지의 가치와 현재 예정된 가치를 비교해서 더 높은 가치 쪽으로 갱신해 나가는 방식
백준 11403 경로 찾기
(퀴즈 대비 플로이드 와샬 문제 풀이)
오.. 응용해서 혼자 풀었음..
인접 행렬 미루고 있었는데 어렵지 않게 해결함!
import sys
from copy import deepcopy
N = int(sys.stdin.readline().strip())
adj_arr = []
for _ in range(N):
adj_arr.append(list(map(int, sys.stdin.readline().strip().split())))
def find(N, arr):
distances = deepcopy(arr)
for k in range(N):
for i in range(N):
for j in range(N):
if distances[i][k] + distances[k][j] == 2:
distances[i][j] = 1
return distances
result = find(N, adj_arr)
for row in result:
print(" ".join(map(str, row)))백준 15723 n단 논법
풀긴 했는데 알파벳 기반으로 인접 행렬 사용하는 거 좀 익숙치 않음..
플로이드 와샬에서 INF로 처음 더미 값 채우는 거랑 3중 반복문 쓰는 거 기억하기!
import sys
from collections import defaultdict
from copy import deepcopy
alphabet = "abcdefghijklmnopqrstuvwxyz"
n = len(alphabet)
INF = float("inf")
graph = [[INF] * n for _ in range(n)]
N = int(sys.stdin.readline().strip())
for _ in range(N):
u, v = map(alphabet.index, sys.stdin.readline().strip().split(" is "))
graph[u][v] = 1
for k in range(n):
for i in range(n):
for j in range(n):
graph[i][j] = min(graph[i][k] + graph[k][j], graph[i][j])
M = int(sys.stdin.readline().strip())
results = []
for _ in range(M):
u, v = map(alphabet.index, sys.stdin.readline().strip().split(" is "))
if graph[u][v] == INF:
results.append("F")
else:
results.append("T")
for result in results:
print(result)CSAPP 연습문제
3.2 인스트럭션 접미어
레지스터 크기를 외워야하나?
개발자나 리버스 엔지니어링 전문가들은 기본적으로 외운다는 GPT 답변..
대략적인 느낌(무조건 그런건 아님)
3글자에 r로 시작하면 8바이트,
3글자에 e로 시작하면 4바이트,
2글자에 x로 끝나면 2바이트,
2~3글자에 l로 끝나면 1바이트
접미어의 역할
b, s, l, q는 각각 1, 2, 4, 8 바이트씩 주어진 주소로부터(혹은 값)
몇 바이트를 이동시킬지 결정! 연산의 데이터 크기를 지정이라고 표현.
주어진 데이터에서 얼마나 많은 부분을 처리할지 결정하는 지표!
movl %eax, (%rsp)
%eax는 4바이트 레지스터
%rsp는 8바이트 레지스터
여기서 인스트럭션은 movl(4바이트)이다.
왜냐하면 %eax에 저장된 4바이트 값을 %rsp가 가리키는 메모리 주소에 할당하는 것이기 때문에,
%rsp는 단순히 메모리 주소 참조 역할만 할 뿐, 8바이트라는 건 여기서 고려 대상이 아니다.
실질적으로 %eax에 할당된 4바이트 데이터가 이동의 대상이 된다.
즉, movl명령어를 통해 %rsp가 가리키는 주소의 첫 4바이트에 %eax의 값을 저장한다.
movw (%rax), %dx
%rax는 8바이트 레지스터
%dx는 2바이트 레지스터
인스트럭션은 movw(2바이트)이다.
왜나하면 %dx는 2바이트 레지스터이기 때문에 movw 인스트럭션이 적절한다.
%rax에서는 64비트가 중요한 게 아니라 해당 메모리 참조값에서 최종적으로 2바이트만 읽어오는 게 중요하다.
%rax에 저장된 메모리 주솟값(아마 8바이트)를 참조하여
해당 메모리 위치에서 movw에 따라 2바이트 값만 읽어와서 %dx레지스터에 저장하는 인스트럭션이다.
movb $0xFF, %bl
$0xFF는 상수
%bl은 1바이트 레지스터
인스트럭션은 movb이다.
왜냐하면 %bl이 1바이트 레지스터이기 때문이고,
이 레지스터에는 상수 $0xFF가 들어가기 때문이다.
movb (%rsp,%rdx,4), %dl
(%rsp,%rdx,4)를 계산하면 %rsp + (%rdx * 4)이다.
계산된 메모리 주소를 참조해서, 해당 메모리에 할당된 값 중 1바이트를 읽어와서
%dl레지스터에 할당하는 명령어이다.
movq (%rdx), %rax
%rdx는 8바이트 레지스터
%rax도 8바이트 레지스터
여기서 %rdx가 8바이트인 것은 중요하지 않다.
왜냐하면 단지 메모리 주솟값을 저장하고 있기 때문이다.
이 인스트럭션은 %rdx에 저장된 메모리 주솟값에 접근해서
8바이트의 데이터를 %rax 레지스터에 할당하는 인스트럭션이다.
movw %dx, (%rax)
%dx는 2바이트 레지스터
%rax는 8바이트 레지스터
여기서 %rax가 8바이트란 사실은 중요하지 않다.
%dx에 저장된 2바이트 값을 %rax가 참조하는 메모리 주소에 할당하는 것이기 때문
즉, %rax가 8바이트이지만 이건 데이터의 크기가 아니라 단지 메모리 주소의 크기일 뿐이다.
오.. 기초적인지만 어셈블리어가 눈에 읽힌다.
연습문제도 그럭저럭 풀었음! (겨우 2문제이지만..)
