
Classical Image Deblurring
Image deblurring은 blurred image에 있는 blur를 제거해서 다음과 같이 sharp image로 만드는 image restoration 기법 중 하나이다.
 이 문제에서 목표는 blurred image가 주어졌을 때 latent sharp image로 복원하고 싶은 것이다. Latent sharp image에서는 카메라의 흔들림이나 개체의 흔들림이 없어야 한다.
이 문제에서 목표는 blurred image가 주어졌을 때 latent sharp image로 복원하고 싶은 것이다. Latent sharp image에서는 카메라의 흔들림이나 개체의 흔들림이 없어야 한다.
Commonly Used Blur Model
Image deblurring을 해결하고자 여러 접근법이 있지만, deep learning 이전에 가장 효과적인 classical approach는 inverse problem으로 접근하는 방법이 있다. Inverse problem으로 접근하기 위해서는 image degradation model이 필요하다. 지금 이 문제에서 image degradation은 image blur이다. 그래서 이를 image blur model이라 부를 것이다. 그래서 다음은 가장 일반적으로 사용하는 image blur model이다.
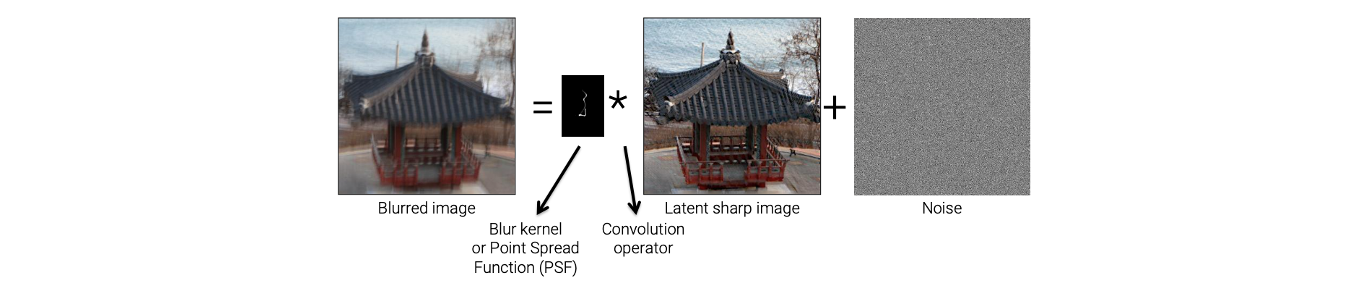 이 model은 어떻게 blurred image가 만들어지는지를 설명하고 있다. 이 model을 보면 blurred image가 위와 같이 주어졌을 때, 이 blurred image는 blur kernel, 혹은 point spread function(PSF)와 latent sharp image의 convolution 연산으로 만들어진다. 기본적으로 latent sharp image는 blur가 없는 상태를 가정하고, 이 sharp image는 blur kernel에 의해서 blurred image로 바뀌게 된다.
이 model은 어떻게 blurred image가 만들어지는지를 설명하고 있다. 이 model을 보면 blurred image가 위와 같이 주어졌을 때, 이 blurred image는 blur kernel, 혹은 point spread function(PSF)와 latent sharp image의 convolution 연산으로 만들어진다. 기본적으로 latent sharp image는 blur가 없는 상태를 가정하고, 이 sharp image는 blur kernel에 의해서 blurred image로 바뀌게 된다.
Blur kernel을 자세히보면 어떠한 trajectory가 있음을 볼 수 있다. 이러한 blur kernel은 얼마나 카메라가 흔들렸는지를 설명한다. 위와 같은 경우에는 카메라가 수직으로 위에서 아래로, 혹은 아래서 위로 흔들렸음을 알 수 있다. 그래서 이 kernel은 카메라가 얼마나 흔들렸는지를 알려주거나 혹은 개체가 얼마나 이동했는지를 말하고 있다. Latent sharp image는 이러한 blur kernel에 의해서 blur가 만들어지고 추가적인 noise가 합쳐지게 된다.
앞서 blur kernel을 point spread function이라고도 한다고 했다. 만약 어떠한 point에서 빛이 발생하고 있는데 이를 카메라로 찍었다면, 해당 point는 blur 모양으로 image에서 보일 것이다. 만약 point에 blur가 없다면 point는 단지 point로 찍힐 것이다. 반면 blur가 존재한다면 이 point는 주변 pixel에도 찍히게 될 것이다. 이러한 현상으로부터 blur kernel을 point spread function이라고도 부르는 것이다.
이러한 model이 가장 기본적인 image deblurring model이고, 이를 이용해서 image deblurring 문제를 풀 수가 있다. Classical approach에서 image deblurring은 다시 몇개의 카테고리로 나눠서 볼 수 있다.
Blind Deconvolution
그 중 첫번째는 blind deconvolution이다. Image deblurring을 "deconvolution"이라고도 부르는데, 그 이유는 blurring process가 convolution 연산에 의해서 진행되기 때문이다. Deconvolution은 convolution의 inverse이고, image deblurring은 blurring process의 반대되는 과정이기에 deconvolution이라고 부를 수 있는 것이다. 위에서 blurring process를 convolution 연산으로 modeling 했다. 그래서 image deblurring에서는 이러한 process를 뒤짚고 싶은 것이다.
그리고 "blind"라는 단어는 우리가 이 과정에서 blur kernel을 모르기 때문에 붙은 것이다. 즉, 우리는 blur kernel, latent sharp image, noise 중 그 어느 것도 알지 못하는 상태가 된다. 특히 blur kernel을 모르기 때문에 blind deconvolution이라는 이름이 붙은 것이다.
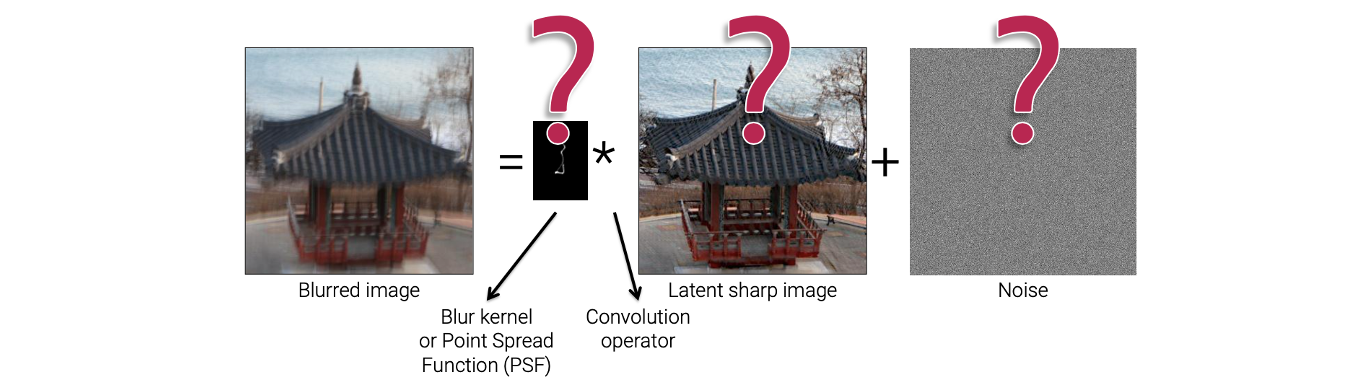 사실 blur는 카메라의 흔들림에 의해서 발생하게 되고, 대부분 알지 못한다. Blurred image를 보더라도 우리는 실제로 카메라가 얼마나 흔들렸는지 알 수가 없다. 카메라의 흔들림에 의해서 blurred image가 만들어지고 이를 다시 latent sharp image로 복원하기 위해서는 위와 같은 blind deconvolution problem을 풀어야 한다. Blind deconvolution은 non-blind deconvolution보다 더 실용적이고 현실적인 방법이다.
사실 blur는 카메라의 흔들림에 의해서 발생하게 되고, 대부분 알지 못한다. Blurred image를 보더라도 우리는 실제로 카메라가 얼마나 흔들렸는지 알 수가 없다. 카메라의 흔들림에 의해서 blurred image가 만들어지고 이를 다시 latent sharp image로 복원하기 위해서는 위와 같은 blind deconvolution problem을 풀어야 한다. Blind deconvolution은 non-blind deconvolution보다 더 실용적이고 현실적인 방법이다.
Non-Blind Deconvolution
Non-blind deconvolution의 경우는 blur kernel에 대해서 알고 있다. 그래서 blur kernel의 존재를 알고 latent sharp image로 복원하려는 것이다. 그래서 blind인지 non-blind인지는 blur kernel을 아는지 모르는지에 따라서 결정하면 된다.
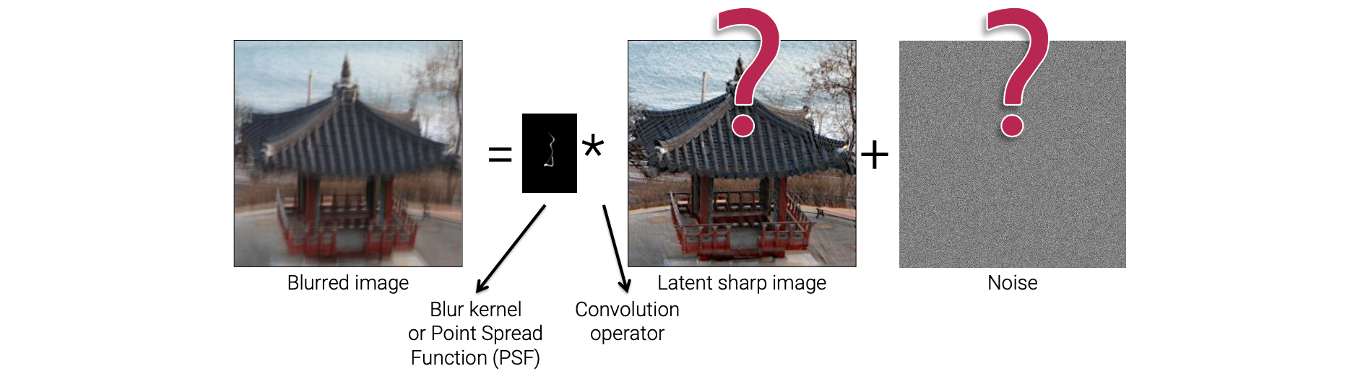 대부분의 경우 blind kernel을 알고 있다. 카메라의 흔들림 외에도 sharp image를 카메라로 촬영했을 때 blurred image를 얻었다면 lens에 의해서 생겼을 수도 있다. Lens는 image의 해상도에 무조건적으로 영향을 끼치고 low-pass filter와 같이 사용이 되서 blur를 만들 수 있다. 대부분의 경우 lens에 의해서 발생하는 blur를 없애고 싶어한다. 이러한 경우에 우리는 chart image와 같은 것을 사용해서 lens에 의해서 발생하는 blur를 예측할 수 있다.
대부분의 경우 blind kernel을 알고 있다. 카메라의 흔들림 외에도 sharp image를 카메라로 촬영했을 때 blurred image를 얻었다면 lens에 의해서 생겼을 수도 있다. Lens는 image의 해상도에 무조건적으로 영향을 끼치고 low-pass filter와 같이 사용이 되서 blur를 만들 수 있다. 대부분의 경우 lens에 의해서 발생하는 blur를 없애고 싶어한다. 이러한 경우에 우리는 chart image와 같은 것을 사용해서 lens에 의해서 발생하는 blur를 예측할 수 있다.
특정 chart image가 있다고 해보자. 그리고 우리는 이미 이 chart image가 sharp하다는 것을 알고 있다. 이 chart image를 카메라를 이용해서 촬영했다고 해보자. 그러면 그 결과 lens blur에 의해서 chart image에 약간의 blur가 생길 것이다. 그래서 sharp chart image와 captured blur chart image를 비교하면 lens blur를 예측할 수 있게 된다. 그러면 lens에 의해서 발생되는 blur를 알게 되고, 또한 blur kernel을 예측할 수 있다. 그래서 이러한 blur kernel을 이용해서 chart image를 복원해서 lens blur를 없앨 수 있다. 그래서 이러한 시나리오의 경우에서 non-blind deconvolution을 이용하는 것이다.
또한 non-blind deconvolution은 blind deconvolution에서 중요한 요소로서 사용된다. 사실 non-blind deconvloution은 실용적이고 현실적인 것과는 거리가 멀지만, 특정 상황에서는 사용할 수 있고 이는 blind deconvolution에서 중요한 요소로서 작용한다.
Popular Approaches for Blind Deconvolution
다음은 주로 사용되는 blind deconvolution의 방법들이다. Blind deconvolution은 unknown의 개수가 다른 image restoration 기법들인 image denoising이나 super-resolution보다도 많기 때문에 더 어려운 문제이다. 그래서 많은 방법들이 blind deconvolution을 해결하고자 등장했다.
- Maximum posterior(MAP)
- Variational Bayesian
- Edge prediction
이 3가지 중에서 가장 간단한 MAP 접근법에 대해서 알아보려고 한다. 다른 방법들에 비해서 MAP를 사용하는 것이 가장 간단하면서도 이해하기 쉬울 것이다.
MAP Based Deblurring
MAP는 다음의 posterior distribution을 최대로 만드는 해를 찾아야 한다.
는 given blurred image이고, 은 latent sharp image, 는 blurred kernel이다. 그래서 blurred image가 주어졌을 때 가장 확률이 높은 latent sharp image와 blurred kernel을 찾기를 원한다. 이 문제를 풀기 위해서 가장 먼저 image degradation model을 정의해야 한다. 그래서 이 model을 기반으로 posterior distribution을 수식화 할 수 있다. 가장 간단한 방법은 Bayes' rule을 사용하는 것이다.
는 likelihood, 은 latent sharp image의 prior, 그리고 는 blur kernel의 prior이다. 그래서 likelihood와 prior를 수식화해야 한다. 그래서 다음과 같이 data term과 regularization term을 이용해서 energy function을 이끌어낼 수 있다. 그래서 energy function을 최소로 만드는 를 찾는 것으로 바뀌게 된다. 여기서 라는 2개의 unknown을 가지게 된다.
 Input blurred image 가 주어졌을 때 가장 먼저 latent image estimation을 진행하게 된다. 이 단계에서 특정 가 주어졌다고 가정하고 위의 energy function을 에 대해서 최소로 만들게 된다. 즉, 의 초기값이 주어지고 이를 고정시킨 다음에 에 관해서 energy function을 최소화하면 된다. 그리고 다음 단계에서 latent image 을 업데이트시키고, 다시 이 을 고정시켜서 에 관한 energy function을 최소로 만들면 된다. 이렇게 를 업데이트 시키는 과정을 반복하면서 latent image와 blur kernel을 개선시키면 된다. 이러한 과정을 여러번 반복한 후에는 최종적으로 blur가 없는 sharp image를 얻게 될 것이다. Latent image estimation 단계에서 를 고정시키게 되는데 이러한 과정은 non-blind deconvolution에 해당하게 된다.
Input blurred image 가 주어졌을 때 가장 먼저 latent image estimation을 진행하게 된다. 이 단계에서 특정 가 주어졌다고 가정하고 위의 energy function을 에 대해서 최소로 만들게 된다. 즉, 의 초기값이 주어지고 이를 고정시킨 다음에 에 관해서 energy function을 최소화하면 된다. 그리고 다음 단계에서 latent image 을 업데이트시키고, 다시 이 을 고정시켜서 에 관한 energy function을 최소로 만들면 된다. 이렇게 를 업데이트 시키는 과정을 반복하면서 latent image와 blur kernel을 개선시키면 된다. 이러한 과정을 여러번 반복한 후에는 최종적으로 blur가 없는 sharp image를 얻게 될 것이다. Latent image estimation 단계에서 를 고정시키게 되는데 이러한 과정은 non-blind deconvolution에 해당하게 된다.
Multi-Scale Estimation
Image deblurring에서 multi-scale 기반의 방법이 많이 사용되어 왔다. Multi-scale approach는 다음과 같다.
 예를 들어 blurred image가 있다고 해보자. 만약 blur의 크기가 매우 크다면 blur kernel을 예측하는 것이 매우 어려울 것이고, blur를 제거하는데도 어려움이 있을 것이다. 그래서 이 Image를 downsampling하기로 했다. Image 자체를 downsampling 했기 때문에 blur 또한 같이 작아졌을 것이다. 그러면 blur kernel을 예측하는 것이 더 쉬워져서 blur를 쉽게 제거할 수 있게 된다. 그래서 먼저 이렇게 줄어든 scale에서 sharp image와 blur kernel을 예측할 수 있다. 그리고 이 정보를 이용해서 더 큰 scale에서 blur kernel과 latent shapr image를 예측할 수 있다. 이렇게 작은 scale에서 blur를 제거할 수 있으면, 다음 scale이나 최종 scale에서 blur를 제거할 수 있게 된다. 이러한 것이 multi-scale estimation의 아이디어다. 결론적으로 scale을 바꿔가면서 이전 scale에서 예측한 blur kernel를 이용해서 새롭게 blur kerenel을 예측하는 것이다. 그리고 각 scale마다도 blur kernel estimation와 latent image estimation 과정이 반복적으로 진행된다.
예를 들어 blurred image가 있다고 해보자. 만약 blur의 크기가 매우 크다면 blur kernel을 예측하는 것이 매우 어려울 것이고, blur를 제거하는데도 어려움이 있을 것이다. 그래서 이 Image를 downsampling하기로 했다. Image 자체를 downsampling 했기 때문에 blur 또한 같이 작아졌을 것이다. 그러면 blur kernel을 예측하는 것이 더 쉬워져서 blur를 쉽게 제거할 수 있게 된다. 그래서 먼저 이렇게 줄어든 scale에서 sharp image와 blur kernel을 예측할 수 있다. 그리고 이 정보를 이용해서 더 큰 scale에서 blur kernel과 latent shapr image를 예측할 수 있다. 이렇게 작은 scale에서 blur를 제거할 수 있으면, 다음 scale이나 최종 scale에서 blur를 제거할 수 있게 된다. 이러한 것이 multi-scale estimation의 아이디어다. 결론적으로 scale을 바꿔가면서 이전 scale에서 예측한 blur kernel를 이용해서 새롭게 blur kerenel을 예측하는 것이다. 그리고 각 scale마다도 blur kernel estimation와 latent image estimation 과정이 반복적으로 진행된다.
Deblurring with DNNs
Classical approach는 blur model와 명시되는 blur kernel에 의존하게 되는데 이로 인하여 몇가지 한계점이 생긴다. 만약 카메라가 회전한다면 한 장면에서도 서로 다른 blur가 발생할 수 있다. 회전하는 지점을 기준으로 거리가 멀어질수록 blur가 더 심해지기 떄문이다. 이러한 blur를 spatially varying blur라고 한다. 그리고 이러한 blur는 하나의 convolution kernel로 설명될 수 없다. 현실에서 대부분의 blur는 이러한 spatially variying blur이다. 그래서 classical approach는 현실에서의 대부분의 blur를 없애는데 한계가 존재한다.
Deep learning을 사용하는 최근 deblurring approach는 CNN과 간단한 deblurring network를 사용한다.
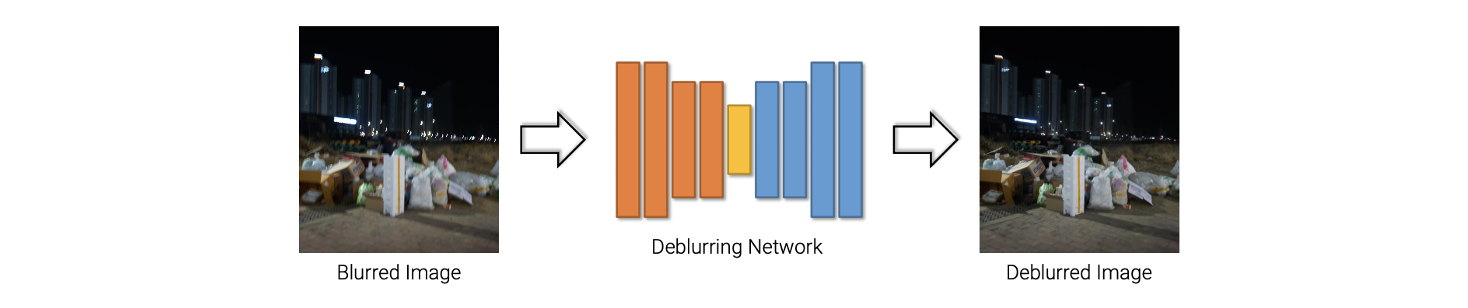 이러한 구조의 간단한 network는 blurred image 하나를 input으로 받아서 deblurred image를 ouput으로 만들어낸다. 이러한 framework에는 blurred kernel이 존재하지 않는다. 단순히 deblurring network를 학습시켜서 deblurred image를 예측하도록 한다. 그래서 이러한 방식은 blur kernel과 blur model에 의존하지 않아서 임의의 blur들을 쉽게 다룰 수가 있다. Spatially varying blur 뿐만 아니라 다른 blur들도 쉽게 다룰 수가 있어졌다. Deep learning을 사용하면 deblurring 문제 또한 쉽게 해결이 가능하다.
이러한 구조의 간단한 network는 blurred image 하나를 input으로 받아서 deblurred image를 ouput으로 만들어낸다. 이러한 framework에는 blurred kernel이 존재하지 않는다. 단순히 deblurring network를 학습시켜서 deblurred image를 예측하도록 한다. 그래서 이러한 방식은 blur kernel과 blur model에 의존하지 않아서 임의의 blur들을 쉽게 다룰 수가 있다. Spatially varying blur 뿐만 아니라 다른 blur들도 쉽게 다룰 수가 있어졌다. Deep learning을 사용하면 deblurring 문제 또한 쉽게 해결이 가능하다.
Multi-Scale CNN
Image deblurring에서 가장 대표적인 연구 중 하나가 2017년도에 나온 "Deep Multi-Scale Convolutional Neural Network for Dynamic Scene Deblurring"이다. 여기서 dynamic scene이라는 것은 spatially varying blur를 다룰 수가 있다는 것이다.
예를 들어 움직이는 물체가 존재하는 image가 있다고 해보자. Image 속 사람이 움직이고 또한 카메라 또한 흔들린다고 가정해보자. 그러면 배경에도 blur가 생길 것이고, 그렇게 되면 결국에는 서로 다른 motion을 가지게 되어 움직이는 foreground 사람과 background가 서로 다른 blur가 생기게 된다. 이러한 것도 spatially varying blur에 해당하기에 deep learning 기반의 approach로 해결할 수가 있다.
이 논문은 deep learning을 사용해서 deblurred image에 바로 적용한 첫번째 논문이다. 이전에는 deep learning과 classical approach를 조합해서 image deblurring framework를 제시했다. 그래서 이전까지는 blur kernel 기반의 blur model에 의존했다. 그래서 이 논문이 최초의 완전히 blur model로부터 독립된 방법을 제시했다.
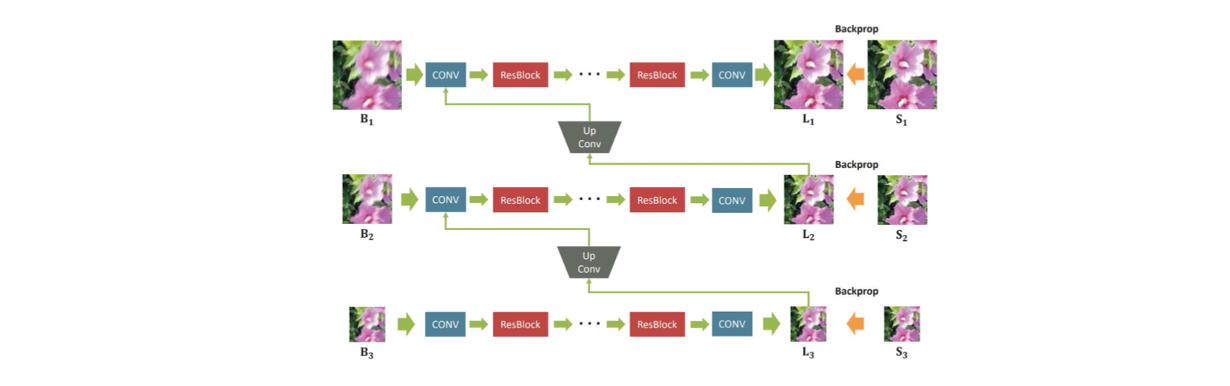 이들이 제시하는 것은 위와 같이 convolution neural network를 사용하는 것이다. 한 부분씩 보면 간단한 구조로 되어 있다. 하나의 convolution layer로 feature를 추출하고 여러개의 residual block을 사용했다. 그리고 다시 convolution layer를 추가해서 feature를 image로 전환시켰다. 이러한 network는 하나의 blurred image 를 받아서 latent sharp image 를 만들어냈다. 그리고 ground truth sharp image 를 이용해서 학습시켰다. Image deblurring에서 loss function은 image denoising과 super-resolution과 비슷하게 mean squared error 등을 사용한다.
이들이 제시하는 것은 위와 같이 convolution neural network를 사용하는 것이다. 한 부분씩 보면 간단한 구조로 되어 있다. 하나의 convolution layer로 feature를 추출하고 여러개의 residual block을 사용했다. 그리고 다시 convolution layer를 추가해서 feature를 image로 전환시켰다. 이러한 network는 하나의 blurred image 를 받아서 latent sharp image 를 만들어냈다. 그리고 ground truth sharp image 를 이용해서 학습시켰다. Image deblurring에서 loss function은 image denoising과 super-resolution과 비슷하게 mean squared error 등을 사용한다.
여기서 주목할 부분은 multi-scale 방식을 사용해서 또 다른 sub network들을 가지고 있다는 것이다. 원래의 input image를 절반의 비율로 downsampling을 계속해서 sub network에 사용하고 sharp image를 예측한 뒤에 upsampling 시켜서 한단계 큰 image와 concatenation을 해서 다시 sub network를 통과시킨다. 그렇게 다시 sharp image를 예측하고 upsampling과 concatenation을 해서 network를 통과시키게 된다. 이러한 식의 아이디어를 이용해서 latent sharp image를 만들겠다는 것이 이 논문에서 제안한 방식이다. 이러한 방식은 classical approach에서 multi-scale 방식을 흉내내서 사용한 것이다. 그리고 여기서의 동기는 scale이 작은 blur의 경우 deblurring 하는 것이 더 쉽다는 것이다.
Dataset Generation
이렇게 학습을 시키기 위해서는 sharp image와 blurry image의 쌍이 data로 필요하다.
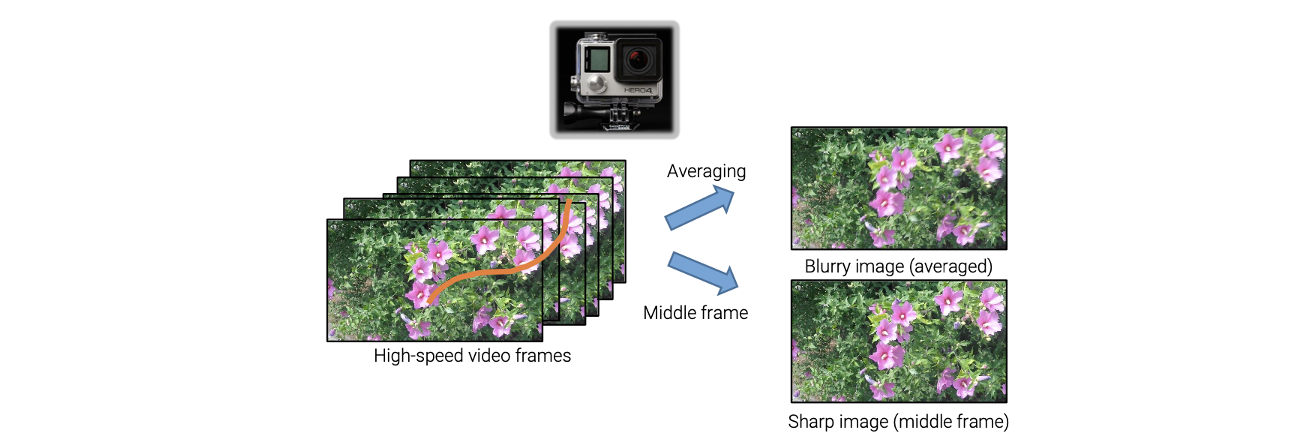 현실에서는 위와 같은 dataset을 얻는 것이 어렵다. 우선 blurry image는 카메라의 흔들림에 의해서 blur가 생겨야 한다. 만약 손으로 카메라를 들고 blurry image를 얻었다고 하더라도 똑같은 장면을 blur가 없는 상태로 촬영을 해야한다. 하나의 카메라를 이용해서 2장의 다른 image를 얻는 것은 어렵다.
현실에서는 위와 같은 dataset을 얻는 것이 어렵다. 우선 blurry image는 카메라의 흔들림에 의해서 blur가 생겨야 한다. 만약 손으로 카메라를 들고 blurry image를 얻었다고 하더라도 똑같은 장면을 blur가 없는 상태로 촬영을 해야한다. 하나의 카메라를 이용해서 2장의 다른 image를 얻는 것은 어렵다.
그래서 이를 해결하고자 high-speed 카메라를 사용하고자 했다. 이러한 아이디어는 최근에도 널리 사용되고 있다. High-speed 카메라를 사용해서 같은 장면을 비디오로 촬영하고자 하면 물체는 어느정도 이동하게 될 것이다. 여러 frame을 합치게 되면 blurry image를 얻을 수 있을 것이고, 중간의 하나의 frame을 선택하게 되면 sharp image가 될 것이다. 왜냐하면 exposure time이 굉장히 작아서 카메라가 움직이더라도 각 frame은 선명한 결과를 얻게 될 것이다. 이렇게 해서 같은 장면에 대해서 blurry image와 sharp image를 쌍으로 얻을 수 있다. 이러한 dataset을 GoPro dataset이라고 하며, 이 dataset을 사용해서 neural network를 학습시키게 된다.
Scale-Recurrent Network
다음으로 2018년도에 발표된 "Scale-recurrent Network for Deep Image Blurring"이라는 논문이다.
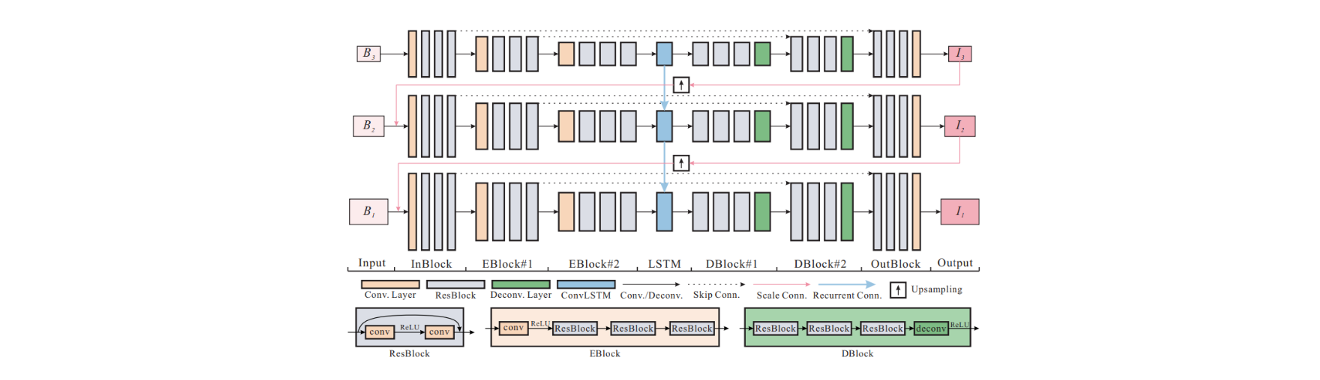 아이디어는 굉장히 유사하다. 이 논문은 multi-scale architecture를 사용해서 하나의 blurred image를 사용해서 downsmapling을 시키고 작은 크기부터 blur를 없애가면서 sharp image를 예측하고 이를 upsampling 시켜서 다음 크기에서 blur를 없애가는 것이다. 또한 LSTM을 사용한 것도 이 논문에서 제안한 방법 중 하나이다. 이렇게 layer를 구성하면 성능이 좋아진다고 말하고 있다.
아이디어는 굉장히 유사하다. 이 논문은 multi-scale architecture를 사용해서 하나의 blurred image를 사용해서 downsmapling을 시키고 작은 크기부터 blur를 없애가면서 sharp image를 예측하고 이를 upsampling 시켜서 다음 크기에서 blur를 없애가는 것이다. 또한 LSTM을 사용한 것도 이 논문에서 제안한 방법 중 하나이다. 이렇게 layer를 구성하면 성능이 좋아진다고 말하고 있다.
GAN-based Deblrruing
Image deblurring에는 GAN을 기반으로 연구한 2018년도에 나온 "DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks"라는 논문이 있다.
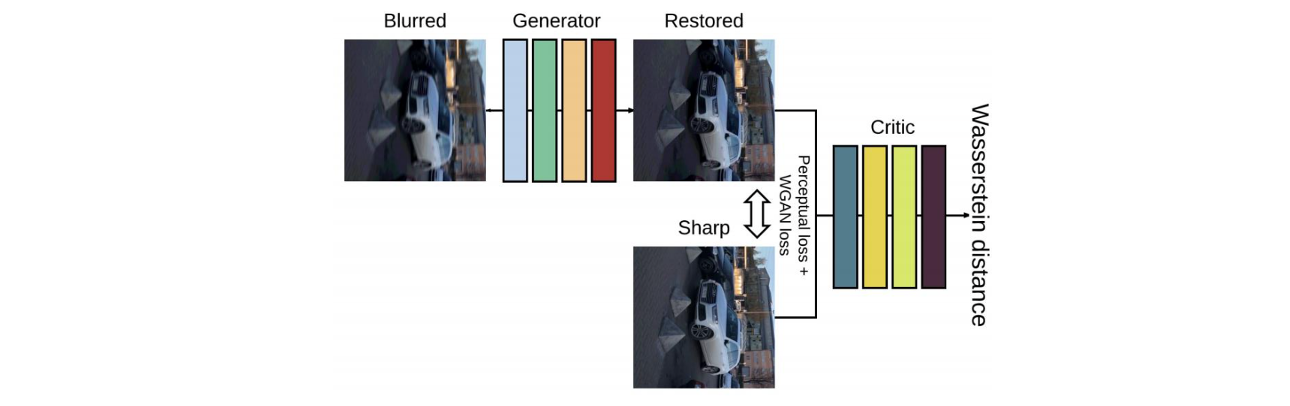 여기서 generator가 deblurring network에 해당한다. 이 network는 하나의 blurred image를 사용해서 sharped image를 복원하게 된다. 여기서 generator를 학습시키기 위해서 critic이라 불리는 discriminator를 사용하게 된다. Discriminator도 generator를 학습시키는 동안에 함께 학습이 진행된다. 여기서 학습을 시키는 이유는 input image가 sharp image인지 deblurred reuslt인지 구별하기 위해서이다. 실제 sharp image와 복원된 deblurred image를 discriminator를 이용해서 구별하는 이유는 결과적으로 만든 image가 실제 image인지 가짜인지를 판단하기 위해서다. 그래서 generator가 학습을 통해서 deblurred image를 예측해서 만들게 되면 이를 이용해서 discriminator를 학습시키는 것이다.
여기서 generator가 deblurring network에 해당한다. 이 network는 하나의 blurred image를 사용해서 sharped image를 복원하게 된다. 여기서 generator를 학습시키기 위해서 critic이라 불리는 discriminator를 사용하게 된다. Discriminator도 generator를 학습시키는 동안에 함께 학습이 진행된다. 여기서 학습을 시키는 이유는 input image가 sharp image인지 deblurred reuslt인지 구별하기 위해서이다. 실제 sharp image와 복원된 deblurred image를 discriminator를 이용해서 구별하는 이유는 결과적으로 만든 image가 실제 image인지 가짜인지를 판단하기 위해서다. 그래서 generator가 학습을 통해서 deblurred image를 예측해서 만들게 되면 이를 이용해서 discriminator를 학습시키는 것이다.
Deblurring Datasets
Deblurring network를 학습시키려면 training dataset이 필요하기 마련이다. 위에서 high-speed 카메라 기반의 dataset에 대해서는 알아보았다. 이외에도 여러 방법이 있지만 여기서 볼 방법으로는 model-based generation이다. 다음과 같은 blur model이 있다고 해보자.
 이러한 model은 classical approach에서 주로 사용되었다. 이러한 model을 기반으로 blurred image를 합성할 수가 있다. Sharp image가 있을 때 우리는 random Gaussian noise를 sampling 할 수가 있다. 그리고 무작위로 blur kernel도 만들 수가 있어서 이렇게 만들어진 blur kernel과 noise를 이용해서 blurred image를 합성할 수가 있다. 그러나 이 방법으로 만든 blur는 uniform blur라는 한계점이 존재하게 된다. Uniform blur라는 것은 동일한 방법으로 모든 pixel에 blur가 생기는 것이다. 그래서 전체적으로 고른 결과를 만들어내는데, 실제와는 다소 다른 형태의 blur를 만들게 된 것이다.
이러한 model은 classical approach에서 주로 사용되었다. 이러한 model을 기반으로 blurred image를 합성할 수가 있다. Sharp image가 있을 때 우리는 random Gaussian noise를 sampling 할 수가 있다. 그리고 무작위로 blur kernel도 만들 수가 있어서 이렇게 만들어진 blur kernel과 noise를 이용해서 blurred image를 합성할 수가 있다. 그러나 이 방법으로 만든 blur는 uniform blur라는 한계점이 존재하게 된다. Uniform blur라는 것은 동일한 방법으로 모든 pixel에 blur가 생기는 것이다. 그래서 전체적으로 고른 결과를 만들어내는데, 실제와는 다소 다른 형태의 blur를 만들게 된 것이다.
우리가 위에서 살펴 본 spatially varying blur는 non-uniform blur라고 말할 수 있으며, uniform blur를 반대로 spatially invariant blur라고 말할 수 있다. 그래서 결국에 이렇게 합성한 결과는 model에 의해서 한계가 존재하고 요즘에는 high-speed based genration을 주로 사용하게 된다. 그렇다고 하더라도 이렇게 만든 결과도 결국에는 현실과는 다소 동떨어진 방법이다.
Real-World Blur Dataset
그래서 2020년도에 "Real-World Blur Dataset for Learning and Benchmarking Deblurring Algorithms"라는 논문에서 새로운 dataset을 제시했다.
 GoPro dataset은 여러 frame을 합쳐서 평균을 낸 결과이기 때문에 temporal gap이 존재하게 된다. 연속해서 frame을 촬영하기 위해서는 shutter를 열고 닫는 행위가 반복되어야 하는데 shutter를 닫고 다시 여는 과정 사이에 temporal gap이 발생하게 된다. 그래서 (d)는 (c)의 일부분을 확대한 결과인데 자세히 보면 하얀 점같은 것들이 연결되어있지 않고 끊어져 있게 된다. 그리고 GoPro dataset은 매우 짧은 exposure time 동안에 촬영하기 때문에 빛이 없는 밤에 비디오를 촬영하는 것에는 어려움이 존재한다. 그래서 GoPro dataset은 낮 동안에 촬영된 결과가 대부분이다. (e)는 빛이 적은 현실적인 blurred image로 밤에도 얻었으며 temporal gap도 없다. 그리고 blur의 형태도 다른 것을 볼 수 있다. 그러면 어떻게 real-world blur dataset을 만들 수 있었을까?
GoPro dataset은 여러 frame을 합쳐서 평균을 낸 결과이기 때문에 temporal gap이 존재하게 된다. 연속해서 frame을 촬영하기 위해서는 shutter를 열고 닫는 행위가 반복되어야 하는데 shutter를 닫고 다시 여는 과정 사이에 temporal gap이 발생하게 된다. 그래서 (d)는 (c)의 일부분을 확대한 결과인데 자세히 보면 하얀 점같은 것들이 연결되어있지 않고 끊어져 있게 된다. 그리고 GoPro dataset은 매우 짧은 exposure time 동안에 촬영하기 때문에 빛이 없는 밤에 비디오를 촬영하는 것에는 어려움이 존재한다. 그래서 GoPro dataset은 낮 동안에 촬영된 결과가 대부분이다. (e)는 빛이 적은 현실적인 blurred image로 밤에도 얻었으며 temporal gap도 없다. 그리고 blur의 형태도 다른 것을 볼 수 있다. 그러면 어떻게 real-world blur dataset을 만들 수 있었을까?
 여기서 특별하게 image를 촬영하는 시스템인 dual camera system을 만들었다. 이 시스템은 동시에 기하학적으로 정렬된 blurred image와 sharp image를 촬영할 수 있다. 이 시스템은 2개의 카메라와 그 사이에 beam splitter를 설치했다. Beam splitter는 반투명 거울이다. 그래서 이 시스템을 이용해서 장면을 촬영하고자 할 때 들어오는 빛에서 절반의 빛은 반사되고 절반의 빛은 통과하게 된다. 이러한 방식을 통해서 2개의 카메라는 동일한 장면을 촬영할 수 있다. 그리고 multi-camera trigger를 설치해서 버튼을 누르게 되면 동시에 같은 장면을 촬영하게 된다. 이렇게 shutter가 동기화 되는 것이다. 이제 하나의 카메라는 exposure time을 길게하고 다른 하나는 exposure time을 짧게하면 짧게 설정한 카메라는 shutter가 빨리 닫혀서 sharp image를 얻게 되고 길게 설정한 카메라는 흔들리는 blurry image를 얻게 된다. 그리고 이렇게 얻어진 2개의 결과가 잘못 정렬될 수 있기 때문에 post-processing을 통해서 맞춰주는 과정을 가지면 된다.
여기서 특별하게 image를 촬영하는 시스템인 dual camera system을 만들었다. 이 시스템은 동시에 기하학적으로 정렬된 blurred image와 sharp image를 촬영할 수 있다. 이 시스템은 2개의 카메라와 그 사이에 beam splitter를 설치했다. Beam splitter는 반투명 거울이다. 그래서 이 시스템을 이용해서 장면을 촬영하고자 할 때 들어오는 빛에서 절반의 빛은 반사되고 절반의 빛은 통과하게 된다. 이러한 방식을 통해서 2개의 카메라는 동일한 장면을 촬영할 수 있다. 그리고 multi-camera trigger를 설치해서 버튼을 누르게 되면 동시에 같은 장면을 촬영하게 된다. 이렇게 shutter가 동기화 되는 것이다. 이제 하나의 카메라는 exposure time을 길게하고 다른 하나는 exposure time을 짧게하면 짧게 설정한 카메라는 shutter가 빨리 닫혀서 sharp image를 얻게 되고 길게 설정한 카메라는 흔들리는 blurry image를 얻게 된다. 그리고 이렇게 얻어진 2개의 결과가 잘못 정렬될 수 있기 때문에 post-processing을 통해서 맞춰주는 과정을 가지면 된다.
이렇게 만들어진 dataset을 RealBlur dataset이라고 부른다.
 이 dataset은 real-world blurred image와 ground truth sharp image를 쌍으로 제공하게 된다. 이 dataset을 사용하면 기존의 deblurring method의 성능을 개선시킬 수 있다. (b)는 high-speed 카메라에 의해서 만들어진 GoPro dataset을 학습시킨 결과인데 다소 정확하지는 않다. 반면, (c)는 동일한 network를 이용해서 RealWorld dataset을 학습시킨 결과로 ground truth와 굉장히 유사한 결과를 만들 수 있었다. 이를 통해서 image restoration에서 training dataset의 중요성에 대해서 다시 알아볼 수 있었다.
이 dataset은 real-world blurred image와 ground truth sharp image를 쌍으로 제공하게 된다. 이 dataset을 사용하면 기존의 deblurring method의 성능을 개선시킬 수 있다. (b)는 high-speed 카메라에 의해서 만들어진 GoPro dataset을 학습시킨 결과인데 다소 정확하지는 않다. 반면, (c)는 동일한 network를 이용해서 RealWorld dataset을 학습시킨 결과로 ground truth와 굉장히 유사한 결과를 만들 수 있었다. 이를 통해서 image restoration에서 training dataset의 중요성에 대해서 다시 알아볼 수 있었다.

글 정말 잘 봤습니다, 재윤님!
MAP method에서 p(l,k|b)를 최대화하는 l,k를 찾기 위해 data term과 regularization term을 이용한 energy function 변환 과정이 이해가 잘 안가서 그러는데, 이와 관련된 정보를 알려주시거나 참고 논문을 알 수 있을까요?