
Classical Super-Resolution
Super-resolution도 image restoration에서 대표적인 기법 중 하나이다. Super-resolution은 2종류의 problem이 존재한다. 하나는 single image SR이고, 다른 하나는 multi frame SR, 혹은 video SR이다.
 Single image SR은 위와 같이 저해상도의 image 하나가 필요하다. 이러한 저해상도 image 하나를 고새항도 image로 복원하고 싶은 것이 single image SR의 목표이다. Single image SR은 이미 high frequency information이 없는 상태이다. 그래서 원래 고해상도 image로 복원하는 것은 상당히 어려운 작업이다. 그래서 single image SR같은 경우 image synthesis와 같다고 볼 수 있다. Pixel들을 이용해서 디테일을 합성해야 하는 작업인 셈이다.
Single image SR은 위와 같이 저해상도의 image 하나가 필요하다. 이러한 저해상도 image 하나를 고새항도 image로 복원하고 싶은 것이 single image SR의 목표이다. Single image SR은 이미 high frequency information이 없는 상태이다. 그래서 원래 고해상도 image로 복원하는 것은 상당히 어려운 작업이다. 그래서 single image SR같은 경우 image synthesis와 같다고 볼 수 있다. Pixel들을 이용해서 디테일을 합성해야 하는 작업인 셈이다.
 반면, multiple frame SR에서는 여러개의 저해상도 image를 필요로한다. 이렇게 여러개의 image로부터 고해상도 image 하나를 복원하는 것이 multi frame SR의 목표이다. Multi frame SR같은 경우 여러개의 저해상도 image로부터 부분적으로 디테일들을 얻을 수 있다. 그래서 모든 partial information을 모을 수 있고 이를 이용해서 고해상도 image를 다시 만들 수 있다. 즉, image가 많으면 많을수록 완성도 높은 결과를 얻을 수 있게 된다.
반면, multiple frame SR에서는 여러개의 저해상도 image를 필요로한다. 이렇게 여러개의 image로부터 고해상도 image 하나를 복원하는 것이 multi frame SR의 목표이다. Multi frame SR같은 경우 여러개의 저해상도 image로부터 부분적으로 디테일들을 얻을 수 있다. 그래서 모든 partial information을 모을 수 있고 이를 이용해서 고해상도 image를 다시 만들 수 있다. 즉, image가 많으면 많을수록 완성도 높은 결과를 얻을 수 있게 된다.
Interpolation Based Approach
대표적인 single image SR 기법 중 하나로 interpolation 기반의 방식이 있다. 사실 interpolation 기반의 방식은 너무나도 간단해서 SR이라고 잘 부르지는 않는다. 이 방법은 너무나도 간단하고 computational effective하지만, 결과가 너무나도 좋지 못하다. 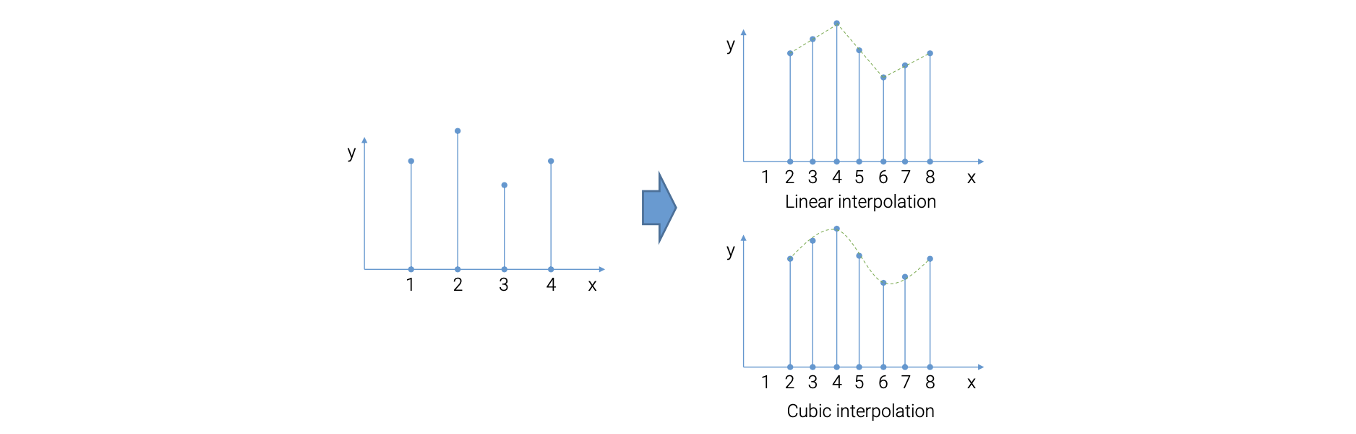 Interpolation 기법들 중에서도 bicubic interpolation이 가장 널리 사용된다. 예를 들어 위와 같이 pixel들이 존재한다고 가정해보자. 이렇게 적은 pixel 개수로부터 image의 크기를 키우거나 해상도를 높이고자 한다. 위의 pixel들의 intensity 값들을 가상의 직선으로 이은 다음에 중간 지점의 값을 사이의 pixel에 추가해주는 것이 linear interpolation이다. 반면, 곡선으로 이은 다음에 중간 지점의 값을 사이의 pixel에 추가해주는 것이 cubic linear interpolation이 된다. Image의 경우 보통 2차원의 array를 사용하기 때문에 이러한 아이디어를 2차원으로 확장해서 사용해야 한다. 그러면 linear이 bilinear, cubic이 bicubic이 된다.
Interpolation 기법들 중에서도 bicubic interpolation이 가장 널리 사용된다. 예를 들어 위와 같이 pixel들이 존재한다고 가정해보자. 이렇게 적은 pixel 개수로부터 image의 크기를 키우거나 해상도를 높이고자 한다. 위의 pixel들의 intensity 값들을 가상의 직선으로 이은 다음에 중간 지점의 값을 사이의 pixel에 추가해주는 것이 linear interpolation이다. 반면, 곡선으로 이은 다음에 중간 지점의 값을 사이의 pixel에 추가해주는 것이 cubic linear interpolation이 된다. Image의 경우 보통 2차원의 array를 사용하기 때문에 이러한 아이디어를 2차원으로 확장해서 사용해야 한다. 그러면 linear이 bilinear, cubic이 bicubic이 된다.
그리고 linear interpolation같은 새로운 sample을 얻기 위해서 경우 오직 2개의 pixel만 있으면 된다. 반면에 cubic interpolation은 새로운 sample을 얻으려면 4개의 pixel이 필요하다. 그래서 bicubic interpolation같은 경우 bilinear interpolation보다 computation time이 더 필요하긴 하다. 그래서 더 나은 결과를 만들 수 있다.
SR as an Inverse Problem
SR을 inverse problem으로 풀 수도 있다. 그러기 위해서 먼저 image degradation model을 정의해야 한다. SR의 경우 다음과 같이 image degradation model을 정의하곤 한다.
는 noise-free high resolution image, 는 noisy low resolution image, 는 downsampling operator, 그리고 은 Gaussian noise이다. SR의 image degradation model을 보면 image denoising에서의 image degradation model과 굉장히 비슷하다. 중요한 것은 가 SR에서는 추가되었다는 것이다. 이렇게 degradation model을 정의하고나면 다음과 같이 SR을 inverse problem으로 수식화 할 수 있다.
Energy function에서 는 data term이고, 는 regularization 혹은 prior term이다. 우리는 여기서 와 비슷한 downsampling 된 를 찾고싶은 것이다. 그리고 좋은 결과를 얻기 위해서는 좋은 regularization term이 필요하다. Image denoising에서 사용했던 prior를 다시 사용할 수 있다. 이러한 inverse problem 접근법은 좋은 image prior가 있다면 다른 restoration 기법에도 다시 사용할 수 있다는 장점이 있다.
Super-Resolution with DNNs
SRCNN
Super-resolution도 deep learning을 이용해서 많은 연구가 진행되었다. 대표적인 method 중 하나가 SRCNN이다. SRCNN은 "Image Super-Resolution Using Deep Convolutional Network"라는 논문에서 2014년에 소개되었다. SRCNN은 image restoration 분야에 있어서 처음 등장했던 deep learning approach이다. 그래서 매우 간단한 구조의 neural network를 사용했다.
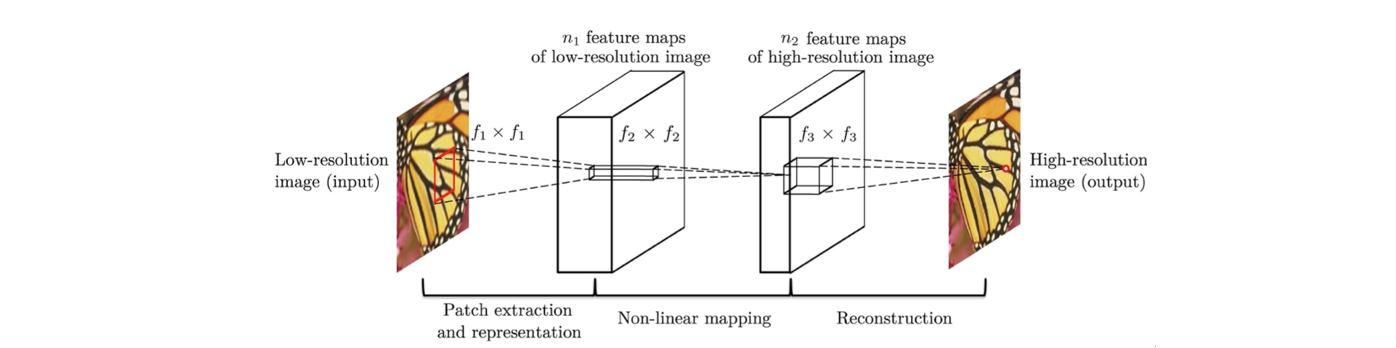 오직 3개의 layer로 구성되어 있으며 patch extraction과 representation 용으로 convolution layer 하나와 ReLU와 같은 non-linear mapping layer 하나, 그리고 마지막으로 복원용으로 사용된 convolution layer까지 총 3개의 layer로 neural network를 구성했다. 이러한 구조의 neural network는 저해상도 image를 input으로 사용해서 고해상도 image를 만들고자 했다. Input으로 사용된 저해상도 image는 원래의 image에 bicubic upsampling을 적용해서 학습을 시켰다. 이 과정은 매우 간단한 과정이지만 놀랍게도 이렇게 간단한 neural network를 이용해서 실험한 결과가 이전의 deep learning을 사용하지 않은 복잡한 과정들보다 더 나은 결과를 보여줬다.
오직 3개의 layer로 구성되어 있으며 patch extraction과 representation 용으로 convolution layer 하나와 ReLU와 같은 non-linear mapping layer 하나, 그리고 마지막으로 복원용으로 사용된 convolution layer까지 총 3개의 layer로 neural network를 구성했다. 이러한 구조의 neural network는 저해상도 image를 input으로 사용해서 고해상도 image를 만들고자 했다. Input으로 사용된 저해상도 image는 원래의 image에 bicubic upsampling을 적용해서 학습을 시켰다. 이 과정은 매우 간단한 과정이지만 놀랍게도 이렇게 간단한 neural network를 이용해서 실험한 결과가 이전의 deep learning을 사용하지 않은 복잡한 과정들보다 더 나은 결과를 보여줬다.
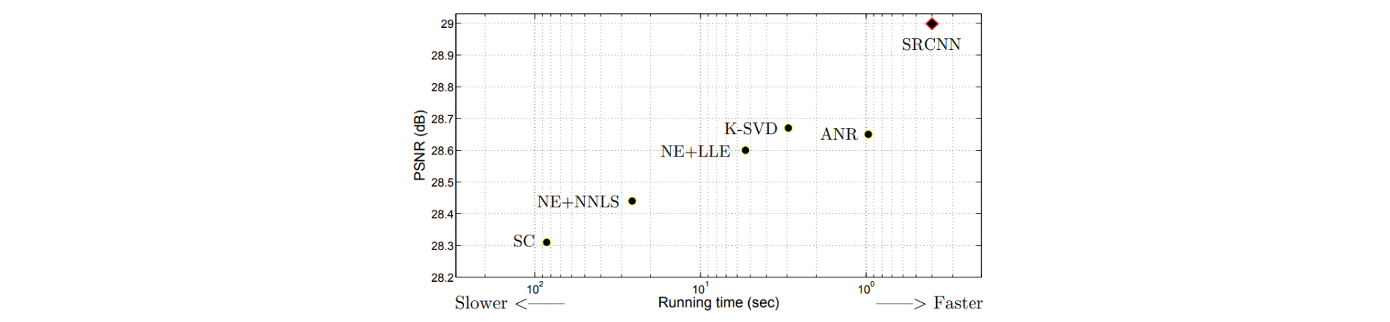 y축은 image의 퀄리티를 보여주고 있으며, 높은 PSNR일수록 더 나은 결과를 말하고 있다. x축은 학습하는데 걸린 시간을 보여주고 있다. 위의 결과를 보면 SRCNN이 이전보다 나은 성능과 효율적인 학습 시간을 보여주고 있다. SRCNN 이전에 굉장히 정교하고 복잡한 알고리즘들이 많이 제시가 되었지만, deep learning 기반의 super-resolution이 새로운 결과를 가져온 것이다. 그래서 이후에 image restoration task에 있어서 deep learning 기반의 연구가 활발히 진행되는 계기가 되었다.
y축은 image의 퀄리티를 보여주고 있으며, 높은 PSNR일수록 더 나은 결과를 말하고 있다. x축은 학습하는데 걸린 시간을 보여주고 있다. 위의 결과를 보면 SRCNN이 이전보다 나은 성능과 효율적인 학습 시간을 보여주고 있다. SRCNN 이전에 굉장히 정교하고 복잡한 알고리즘들이 많이 제시가 되었지만, deep learning 기반의 super-resolution이 새로운 결과를 가져온 것이다. 그래서 이후에 image restoration task에 있어서 deep learning 기반의 연구가 활발히 진행되는 계기가 되었다.
VDSR
또 다른 super-resolution method로는 VDSR이 있다. 이 method는 "Accurate Image Super-Resolution Using Very Deep Convolution Networks"라는 논문에서 2016년에 소개되었다.
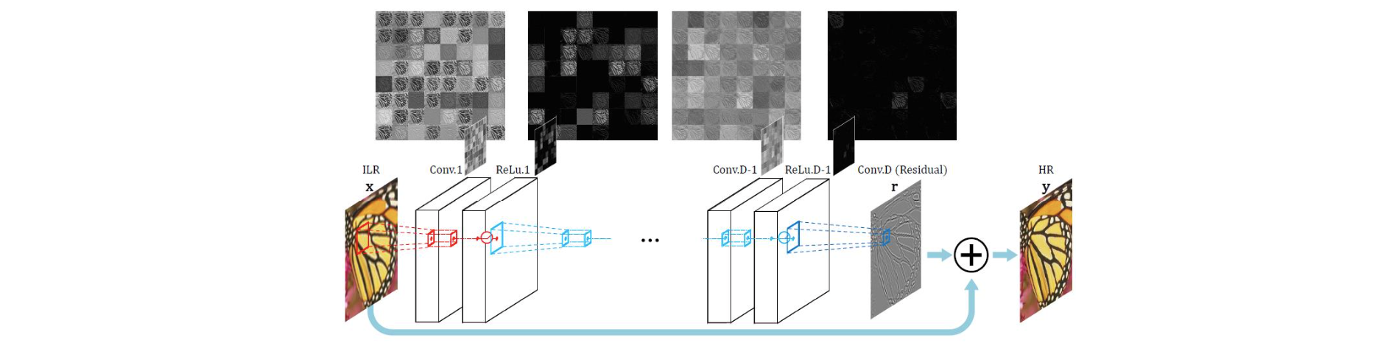 Deep learning을 배울 때 한가지 확실한 사실은 network의 깊이가 깊어질수록 성능이 올라간다는 것이다. Neural network의 깊이를 증가시킬수록 더 많은 layer를 쌓을 수 있어서 성능이 향상될 수 있다. VDSR은 이러한 성질을 이용해서 super-resolution을 하고자 한 것이다. 그래서 위와 같이 여러개의 convolution layer와 ReLU layer를 쌓은 model을 구성했다. Network 구조는 매우 간단하고 단순히 깊게 쌓았다는 점만 이전과 차이가 있다. 추가적으로 residual learning 기법을 사용해서 학습을 시켰다. Input으로는 bicubic interpolation으로 upsampling 된 저해상도 image를 사용하게 된다. 이 image를 network로 학습시키면 residual image가 만들어지게 되며, residual image와 input image를 합쳐서 고해상도 image를 최종적으로 복원하는 것이다.
Deep learning을 배울 때 한가지 확실한 사실은 network의 깊이가 깊어질수록 성능이 올라간다는 것이다. Neural network의 깊이를 증가시킬수록 더 많은 layer를 쌓을 수 있어서 성능이 향상될 수 있다. VDSR은 이러한 성질을 이용해서 super-resolution을 하고자 한 것이다. 그래서 위와 같이 여러개의 convolution layer와 ReLU layer를 쌓은 model을 구성했다. Network 구조는 매우 간단하고 단순히 깊게 쌓았다는 점만 이전과 차이가 있다. 추가적으로 residual learning 기법을 사용해서 학습을 시켰다. Input으로는 bicubic interpolation으로 upsampling 된 저해상도 image를 사용하게 된다. 이 image를 network로 학습시키면 residual image가 만들어지게 되며, residual image와 input image를 합쳐서 고해상도 image를 최종적으로 복원하는 것이다.
SRGAN
SRGAN은 2017년도에 "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network"라는 논문에서 소개된 super-resolution method이고, Generative adversairal network(GAN)을 super-resolution에 사용한 것이 이 논문의 특징이다.
 그렇다면 왜 GAN을 super-resolution에 사용했던 것일까? Super-resolution에는 한가지 문제점이 존재했다. 원래의 image를 bicubic interpolation을 사용해서 upsampling해서 사용했었는데, scaling factor가 커지게 되면 디테일이 사라지는 상황이 발생할 수 있다. 그래서 이러한 input image에 대해서 더욱 정교한 method가 필요해진 것이다. 단순히 deep learning을 사용했을 때 어느정도 성능은 보장되지만 놓치는 부분들이 생기게 된다. 그래서 ground truth와 비교했을 때 놓치는 디테일을 없애고자 SRGAN에서는 GAN을 super-resolution에 접목시킨 것이다. Image의 scale을 바꾸는 과정에서 생기는 디테일의 손실은 super-resolution으로 복구하기가 어렵다. 그래서 SRGAN은 새로운 image를 합성해서 디테일을 보존하고자 한다. 그래서 결과를 보면 high frequency 디테일은 전부 합성된 결과이고 이는 ground truth와 매우 비슷해서 자연스럽게 보인다. 그러나 자세히보면 디테일의 형태가 살짝 다른 것을 볼 수 있는데, 전체적으로 보면 선명하면서도 자연스러운 결과를 만들었다.
그렇다면 왜 GAN을 super-resolution에 사용했던 것일까? Super-resolution에는 한가지 문제점이 존재했다. 원래의 image를 bicubic interpolation을 사용해서 upsampling해서 사용했었는데, scaling factor가 커지게 되면 디테일이 사라지는 상황이 발생할 수 있다. 그래서 이러한 input image에 대해서 더욱 정교한 method가 필요해진 것이다. 단순히 deep learning을 사용했을 때 어느정도 성능은 보장되지만 놓치는 부분들이 생기게 된다. 그래서 ground truth와 비교했을 때 놓치는 디테일을 없애고자 SRGAN에서는 GAN을 super-resolution에 접목시킨 것이다. Image의 scale을 바꾸는 과정에서 생기는 디테일의 손실은 super-resolution으로 복구하기가 어렵다. 그래서 SRGAN은 새로운 image를 합성해서 디테일을 보존하고자 한다. 그래서 결과를 보면 high frequency 디테일은 전부 합성된 결과이고 이는 ground truth와 매우 비슷해서 자연스럽게 보인다. 그러나 자세히보면 디테일의 형태가 살짝 다른 것을 볼 수 있는데, 전체적으로 보면 선명하면서도 자연스러운 결과를 만들었다.
Super-Resolution Datasets
Super-resolution을 위해서 학습을 진행하려면 학습하고자하는 dataset이 필요하다. Supre-resolution을 하기 위한 dataset을 준비하기 위해서 저해상도 image가 필요하다. 저해상도 image를 만드는 방식은 2가지가 존재한다. 하나는 digital device를 이용해서 downsampling하는 것이고, 다른 하나는 용도에 맞는 카메라를 사용하는 것이다.
 예를 들어 컴퓨터에 고해상도 image가 있다고 해보자. 이 image를 어딘가에 업로드한다고 했을 때, 실제로 이렇게 고해상도 image는 필요가 없다. 그래서 downsampling을 통해서 해상도를 낮추게 된다.
예를 들어 컴퓨터에 고해상도 image가 있다고 해보자. 이 image를 어딘가에 업로드한다고 했을 때, 실제로 이렇게 고해상도 image는 필요가 없다. 그래서 downsampling을 통해서 해상도를 낮추게 된다.
 카메라를 이용해서 어떠한 장면을 촬영하고자 할 때, 빛이 카메라의 lens로 들어오고 선택적으로 anti aliasing이 진행될 것이다. 그리고 해당 빛은 sensor에 도달하게 될 것이다. 그러면 sensor는 electric signal을 digital signal로 바꿔서 image를 얻게 된다. 이 과정에서 lens나 anti aliasing filter가 lospass filter의 역할을 하고 sensor가 sampling을 하게 된다. 이러한 과정에서 sensor의 크기를 줄이면 높은 해상도의 결과를 얻게 될 것이다. 그러나 물리적인 한계로 인해서 저해상도 image를 최종적으로 얻게 될 것이다. 그래서 좋은 lens와 sensor를 사용하게 되면 더 나은 결과를 얻게 되고, 이렇게 카메라 자체적으로 촬영을 했을 때 해상도가 기본적으로 제한이 된다. 현실 세계에서의 super-resolution을 이야기한다면 기본적으로 이러한 가정을 가지고 가야한다. Image를 얻는 과정에서 자체적으로 저해상도 image를 가지게 된다.
카메라를 이용해서 어떠한 장면을 촬영하고자 할 때, 빛이 카메라의 lens로 들어오고 선택적으로 anti aliasing이 진행될 것이다. 그리고 해당 빛은 sensor에 도달하게 될 것이다. 그러면 sensor는 electric signal을 digital signal로 바꿔서 image를 얻게 된다. 이 과정에서 lens나 anti aliasing filter가 lospass filter의 역할을 하고 sensor가 sampling을 하게 된다. 이러한 과정에서 sensor의 크기를 줄이면 높은 해상도의 결과를 얻게 될 것이다. 그러나 물리적인 한계로 인해서 저해상도 image를 최종적으로 얻게 될 것이다. 그래서 좋은 lens와 sensor를 사용하게 되면 더 나은 결과를 얻게 되고, 이렇게 카메라 자체적으로 촬영을 했을 때 해상도가 기본적으로 제한이 된다. 현실 세계에서의 super-resolution을 이야기한다면 기본적으로 이러한 가정을 가지고 가야한다. Image를 얻는 과정에서 자체적으로 저해상도 image를 가지게 된다.
현실에서는 저해상도 image를 쉽게 구하기 어려워서 여기서도 합성해서 만든 dataset을 주로 사용하곤 한다.  먼저 고해상도 image를 모은 뒤에 bicubic downsampling과 같은 주로 사용되는 downsampling 기법들을 사용해서 해상도를 낮추게 된다. 그러면 이렇게 만들어진 저해상도 image들을 neural network로 학습시켜서 고해상도 image로 복원하게 된다. 그래서 이렇게 복원된 super-resolution 결과와 원래 Inputd으로 사용된 고해상도 image를 비교해서 학습을 시키는 것이다.
먼저 고해상도 image를 모은 뒤에 bicubic downsampling과 같은 주로 사용되는 downsampling 기법들을 사용해서 해상도를 낮추게 된다. 그러면 이렇게 만들어진 저해상도 image들을 neural network로 학습시켜서 고해상도 image로 복원하게 된다. 그래서 이렇게 복원된 super-resolution 결과와 원래 Inputd으로 사용된 고해상도 image를 비교해서 학습을 시키는 것이다.
이러한 방법은 널리 사용되었지만, 오래전부터 사용되어져 온 downsampling 기법이 현실적이지 못해서 실제로 image를 얻는 과정과 차이가 존재한다. 그래서 합성된 image들을 학습한 neural network의 경우 현실 세계의 image에 대해서 제대로 동작하지 않는 문제가 생긴다.
RealSR
이러한 문제를 해결하기 위해서 RealSR이라는 dataset이 등장하게 되었다. 이 dataset은 2019년도에 "Real-World Single Image Super-Resolution: A New Benchmark and A New Model"이라는 논문에서 소개되었다.
 이 논문에서는 고해상도 image와 저해상도 image를 focal length 값이 다른 카메라들을 이용해서 dataset을 만들었다. 먼저 삼각대를 설치하고 카메라를 연결시켜서 image를 얻는다. 그리고 focal length를 바꿔서 다른 image를 얻는다. 이렇게 image 쌍을 얻으면 하나는 고해상도 image가 되고 다른 하나는 저해상도 image가 될 것이다. 그러면 image를 잘라내서 저해상도 image에서 특정 부분이 고해상도 image에 대응될 것이다. 그러면 이 저해상도 image가 실제로 카메라를 통해서 image를 얻는 과정과 같아질 것이다. 그래서 이 image를 학습에 사용하게 되면 현실 세계의 image에 더 좋은 성능을 보일 것이다.
이 논문에서는 고해상도 image와 저해상도 image를 focal length 값이 다른 카메라들을 이용해서 dataset을 만들었다. 먼저 삼각대를 설치하고 카메라를 연결시켜서 image를 얻는다. 그리고 focal length를 바꿔서 다른 image를 얻는다. 이렇게 image 쌍을 얻으면 하나는 고해상도 image가 되고 다른 하나는 저해상도 image가 될 것이다. 그러면 image를 잘라내서 저해상도 image에서 특정 부분이 고해상도 image에 대응될 것이다. 그러면 이 저해상도 image가 실제로 카메라를 통해서 image를 얻는 과정과 같아질 것이다. 그래서 이 image를 학습에 사용하게 되면 현실 세계의 image에 더 좋은 성능을 보일 것이다.

