
GANs
최근들어 수많은 image synthesis는 neural network를 사용한다. GAN은 generative adversarial network의 약자이며 2014년도에 "Generative Adversarial Nets"라는 논문에서 처음으로 소개되었다. GAN의 목표는 새로운 image를 합성해내는 것이다. 여기서 새로운 image라는 것은 현실적이어야 하지만 가짜여야 한다. 즉, 이 세상에 존재하는 사람이면 안된다. 매우 자연스러운 사람을 만들어내게 되면 GAN의 위력을 확인할 수 있다. 최근에는 GAN 연구는 매우 좋은 성능을 보여주곤 한다.
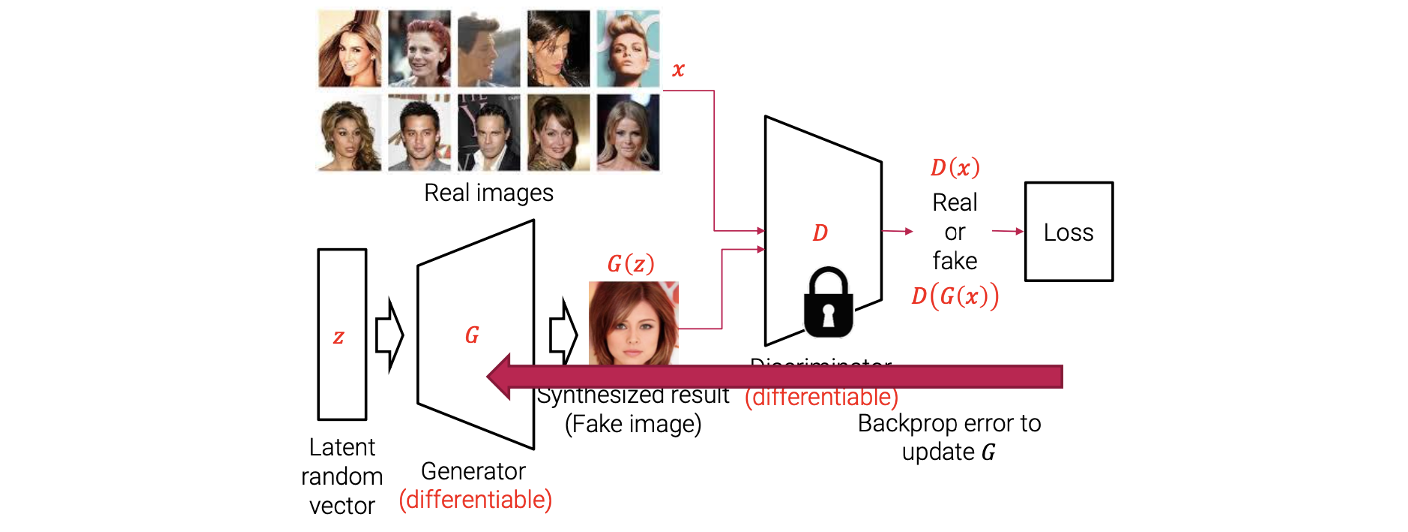
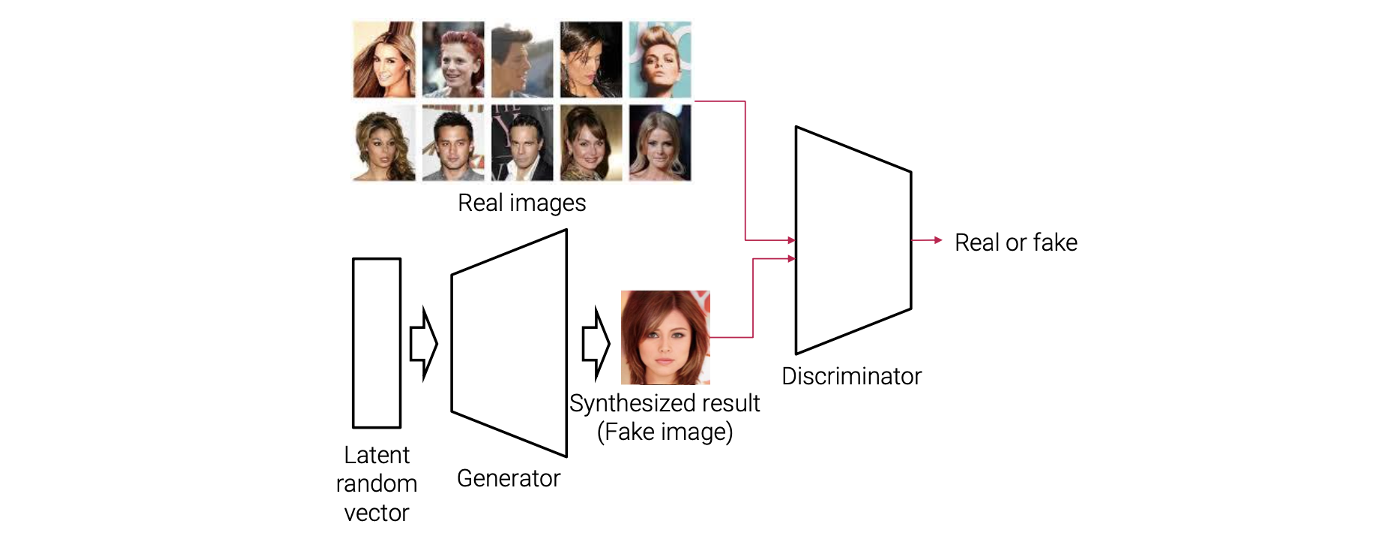 GAN framework는 2개의 neural network로 구성되어 있고, 각각 generator와 discriminator에 포함되어 있다. 여기서 generator가 가짜 image를 random vector로부터 만들어내게 된다. Generator가 latent random vector를 input으로 사용해서 이로부터 합성된 결과인 fake image를 만들어낸다.
GAN framework는 2개의 neural network로 구성되어 있고, 각각 generator와 discriminator에 포함되어 있다. 여기서 generator가 가짜 image를 random vector로부터 만들어내게 된다. Generator가 latent random vector를 input으로 사용해서 이로부터 합성된 결과인 fake image를 만들어낸다.
그리고 discriminator는 오직 학습에만 사용이 된다. Generator가 새로운 image를 만들어내기 위해서 학습이 된다면 discriminator는 주어진 input image가 진짜인지 가짜인지 구분하기 위해서 학습이 된다. 그래서 학습하는 동안에 GAN은 여러개의 real image를 training dataset으로 사용한다. Generator가 만들어낸 fake image와 training dataset으로부터 real image가 discriminator의 input으로 학습이 진행된다. Discriminator는 최종적으로 input image가 진짜인지 가짜인지 구분하게 되고 이는 binary classifier로서 역할을 하게 된다.
우리의 목표는 discriminator를 학습을 잘 시켜서 classification 정확도를 높이는 것이다. Discriminator가 진짜인지 가짜인지 구분을 잘하기 위해서 학습이 된다면, generator는 discriminator를 잘 속이기 위해서 학습이 된다. 결론적으로 GAN을 학습하기 위해서는 번갈아 가며 generator와 discriminator를 학습시켜야 하고, 이들이 서로 경쟁하도록 만들어야 한다. 경쟁하는 과정에서 generator는 더 현실적인 image를 만들어서 discriminator가 제대로 구분하지 못하도록 만들어야 한다.
Applications of GANs
이렇게 학습을 하고나면 최종적으로 generator를 그럴듯한 image를 만들어낸다. 그렇다면 이러한 GAN은 어떻게 적용이되는 것일까?
 사람들이 generation 과정을 잘 조절하게 되면 원하는 결과를 만들어내어 여러 분야에 적용이 가능해진다. Computer graphics나 computational photography 분야에서 사람들이 진정으로 하고 싶은 것은 사용자들이 적절한 통제를 주면서 새로운 image를 합성하는 것이다.
사람들이 generation 과정을 잘 조절하게 되면 원하는 결과를 만들어내어 여러 분야에 적용이 가능해진다. Computer graphics나 computational photography 분야에서 사람들이 진정으로 하고 싶은 것은 사용자들이 적절한 통제를 주면서 새로운 image를 합성하는 것이다.
예를 들어 통제를 해가면서 자연스러워 보이는 image를 합성한다고 해보자. 위에서 input image가 통제 사항이 되면서 동시에 이를 기반으로 현실적인 image를 만들어내야 한다. Input image를 어떻게 주느냐에 따라서 여러 분야에 적용이 가능해진다. 위와 같이 image synthesis, image inpainting, style transfer, super-resolution, image editing 등이 있다. Super-resolution을 예로 보면 저해상도 image로부터 고해상도 image를 만들어야 한다. 그리고 만들어진 image의 구성은 저해상도 image와 같아야 한다. 그래서 GAN이 image restoration의 여러 분야에도 적용이 가능하게 된다.
Generative Models
GAN은 generative adversarial network로 이름에서부터 알다시피 GAN은 generative model이다. Machine learning model을 discriminative model과 generative model로 나눌 수가 있다.
Discriminative model은 image 가 주어졌을 때, label 를 예측해야 한다. 가장 대표적인 예시로 classification model이 있다. 확률의 관점에서 discriminative model은 conditional probability 를 예측하는 것이다. 다만 discriminative model은 conditional probability만을 modeling하고 특정 image에 대한 probability 는 modeling하지 않아서 새로운 image를 만들어내는 것이 불가능하다.
반면, generative model은 를 modeling 할 수 있다. 이는 곧 generative model의 경우 새로운 image를 만들어 낼 수 있음을 의미하게 된다. 그래서 확률 분포가 있을 때 sampling을 통해서 새로운 image를 만들어낸다. 그래서 이 model의 경우 바로 image에 대한 확률을 modeling 할 수 있어서 새로운 sample을 통해서 image를 만들어 낼 수 있다.
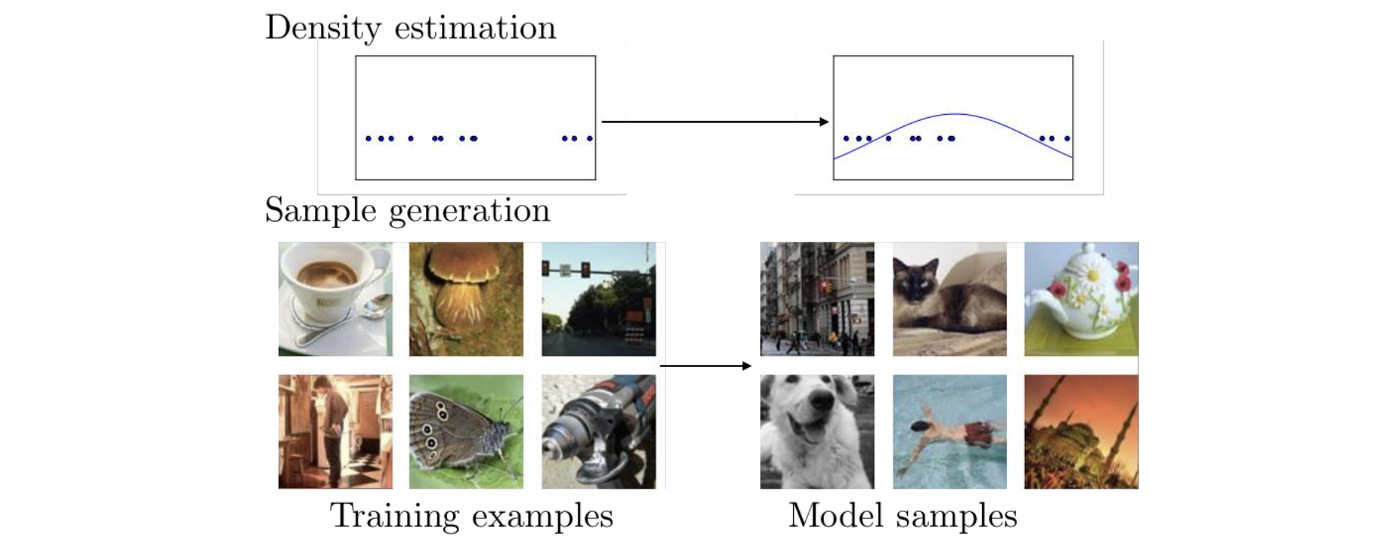 크기가 인 image가 있을 때 크기가 차원인 vector로 나타냈다고 해보자. 그러면 이 vector는 차원에서 하나의 점으로 표현이 될 것이다. 만약 100개의 image가 있다면 점이 100개가 찍힐 것이다. 이 100개의 data point는 새로운 image의 분포로부터 sample에 해당하게 된다. 그러나 실제로 우리는 image의 분포를 알지는 못한다. Generative model의 목표는 이러한 sample 혹은 실제 image의 분포를 예측하는 것이다.
크기가 인 image가 있을 때 크기가 차원인 vector로 나타냈다고 해보자. 그러면 이 vector는 차원에서 하나의 점으로 표현이 될 것이다. 만약 100개의 image가 있다면 점이 100개가 찍힐 것이다. 이 100개의 data point는 새로운 image의 분포로부터 sample에 해당하게 된다. 그러나 실제로 우리는 image의 분포를 알지는 못한다. Generative model의 목표는 이러한 sample 혹은 실제 image의 분포를 예측하는 것이다.
위의 예시에서 data point들은 각각 image에 해당하게 된다. 이 point들로부터 우측과 같은 분포를 예측하는 것이 generative model의 목표이다. 그리고 이렇게 분포를 얻고나면 새로운 sample들을 얻을 수가 있다.
Adversarial Training
Adversarial network는 adversarial training에 사용된다. Adversarial training은 model을 속이기 위한 adversarial sample을 만들어 내고 이렇게 만들어진 sample들을 사용해서 model을 robust하게 만든다. 이러한 과정을 반복해가면서 model을 더 나아지게 만든다.
GAN은 이러한 아이디어를 generative model로 확장시켰다. GAN은 결국 generative model과 adversarial training의 조합이라고 보면 된다. 이러한 이유 떄문에 GAN이라는 이름이 만들어진 것이다.
Training GAN
어떻게 GAN을 학습시키는지 다시 보도록 하자.
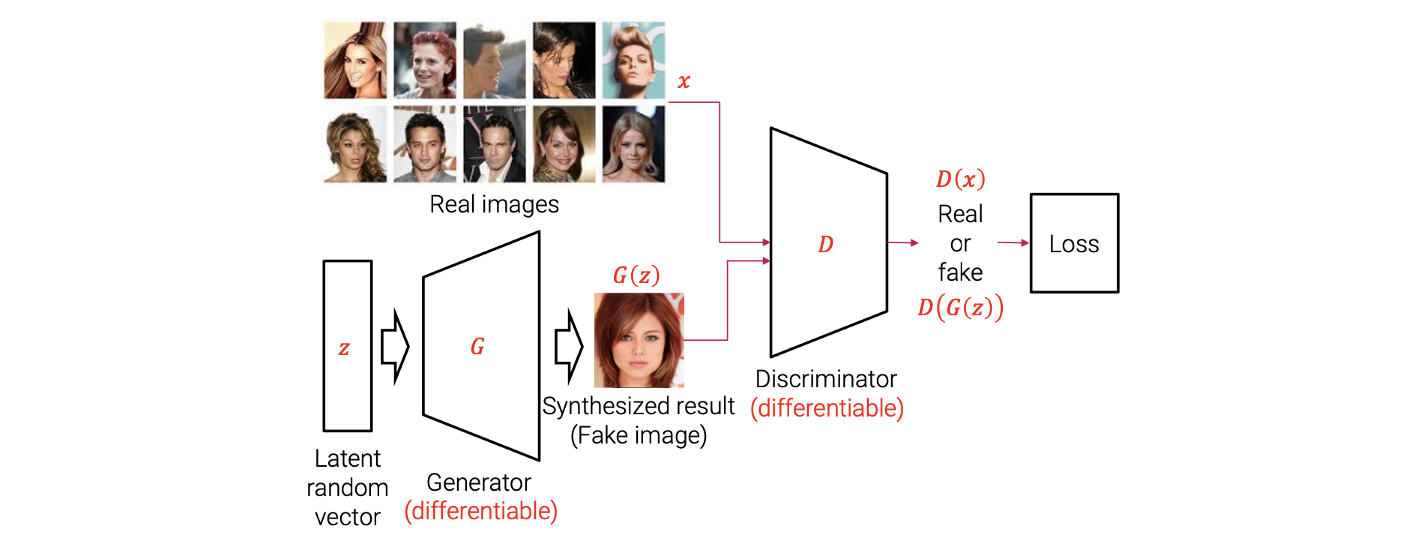 Generator와 discriminator가 있고, 이들은 미분이 가능한 neural network로 구성되어져 있다. Generator는 latent random vector를 input으로 사용해서 fake image를 만들어내게 된다. Generator를 function으로 생각했을 때 latent random vector는 function의 input이 되어 fake image 를 output으로 만들어낸다. Discriminator는 image를 input으로 사용하고, 여기서 image는 real image 와 fake image 를 사용하게 된다. 그래서 이 discriminator는 input image가 real image인지 fake image인지 구별할 수 있도록 학습이 진행된다.
Generator와 discriminator가 있고, 이들은 미분이 가능한 neural network로 구성되어져 있다. Generator는 latent random vector를 input으로 사용해서 fake image를 만들어내게 된다. Generator를 function으로 생각했을 때 latent random vector는 function의 input이 되어 fake image 를 output으로 만들어낸다. Discriminator는 image를 input으로 사용하고, 여기서 image는 real image 와 fake image 를 사용하게 된다. 그래서 이 discriminator는 input image가 real image인지 fake image인지 구별할 수 있도록 학습이 진행된다.
Training Discriminator
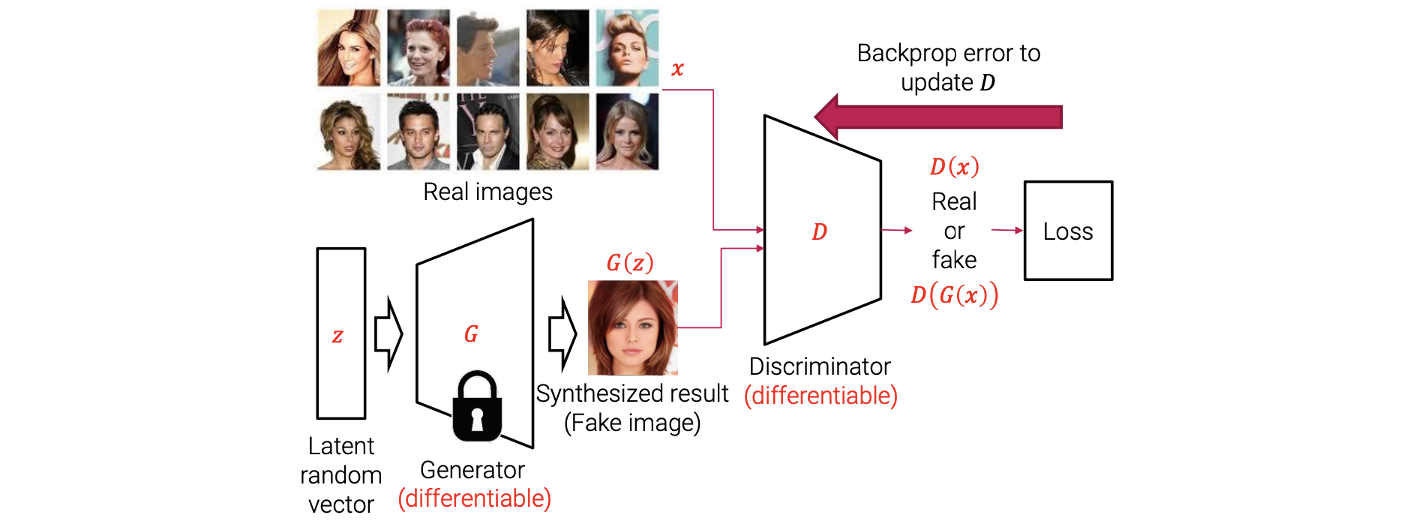 GAN을 학습시킬 때는 번갈아가면서 generator와 dsicriminator를 학습시킨다. 먼저, discriminator를 학습시킨다고 해보자. 우리는 무작위로 latent random vector나 real image를 sampling한다. Latent random vector의 경우 이를 generator를 통해서 fake image를 만들어내고 이 결과를 다시 discriminator에 집어넣게 된다. 그러면 discriminator에서는 들어온 image가 real image인지 fake image인지 구분하게 된다. Discriminator의 output을 기반으로 loss function을 계산하게 된다. 그리고 여기에는 ground truth label이 존재한다. 예를 들어 latent random vector를 sampling하고 fake image를 만들었을 때 이미 ground truth가 존재하기 떄문에 이를 기반으로 loss를 구해서 Back-propagation을 이용해서 gradient를 계산하게 된다. 이를 통해서 neural network의 parameter를 업데이트 할 수 있다. Discriminator를 학습시키기 위해서 generator의 parameter를 고정시키고 오직 discriminator의 parameter만을 업데이트해야 한다.
GAN을 학습시킬 때는 번갈아가면서 generator와 dsicriminator를 학습시킨다. 먼저, discriminator를 학습시킨다고 해보자. 우리는 무작위로 latent random vector나 real image를 sampling한다. Latent random vector의 경우 이를 generator를 통해서 fake image를 만들어내고 이 결과를 다시 discriminator에 집어넣게 된다. 그러면 discriminator에서는 들어온 image가 real image인지 fake image인지 구분하게 된다. Discriminator의 output을 기반으로 loss function을 계산하게 된다. 그리고 여기에는 ground truth label이 존재한다. 예를 들어 latent random vector를 sampling하고 fake image를 만들었을 때 이미 ground truth가 존재하기 떄문에 이를 기반으로 loss를 구해서 Back-propagation을 이용해서 gradient를 계산하게 된다. 이를 통해서 neural network의 parameter를 업데이트 할 수 있다. Discriminator를 학습시키기 위해서 generator의 parameter를 고정시키고 오직 discriminator의 parameter만을 업데이트해야 한다.
Training Generator
 Generator를 학습시키기 위해서는 discriminator의 parameter를 고정시키고 오로지 generator의 parameter만을 업데이트 해야 한다. Generator를 학습시키는 과정도 비슷하게 진행이 되며, 먼저 latent random vector를 sampling을 진행한다. 그리고 이를 generator에 집어 넣어서 fake image를 만들어낸다. 다시 이 결과를 discriminator에 집어 넣으면 discriminator는 들어온 image가 real image인지 fake image인지 구분하게 된다. 이후 예측한 결과를 loss를 구하는데 사용하고 다시 Back-propagation을 사용해서 gradient를 계산하게 된다. 계산이 된 gradient를 사용해서 오로지 generator의 parameter를 업데이트 시킨다. 이렇게 Generator와 discriminator를 번갈아가며 업데이트 시키면서 서로 경쟁을 하도록 만드는 것이 GAN을 학습시키는 과정이 된다.
Generator를 학습시키기 위해서는 discriminator의 parameter를 고정시키고 오로지 generator의 parameter만을 업데이트 해야 한다. Generator를 학습시키는 과정도 비슷하게 진행이 되며, 먼저 latent random vector를 sampling을 진행한다. 그리고 이를 generator에 집어 넣어서 fake image를 만들어낸다. 다시 이 결과를 discriminator에 집어 넣으면 discriminator는 들어온 image가 real image인지 fake image인지 구분하게 된다. 이후 예측한 결과를 loss를 구하는데 사용하고 다시 Back-propagation을 사용해서 gradient를 계산하게 된다. 계산이 된 gradient를 사용해서 오로지 generator의 parameter를 업데이트 시킨다. 이렇게 Generator와 discriminator를 번갈아가며 업데이트 시키면서 서로 경쟁을 하도록 만드는 것이 GAN을 학습시키는 과정이 된다.
Minimax Problem
GAN의 학습 과정을 minimax problem으로 설명할 수 있다.
는 loss function, 는 discriminator의 parameter, 그리고 는 generator의 parameter들이다. 그래서 는 classification accuracy가 된다. Dicscriminator는 input image가 real image인지 fake image인지 구분하게 된다. 그래서 loss function으로 classification accuracy를 나타내도록 했다. Discriminator는 classification accuracy를 최대로 만들려고 노력할 것이다. 동시에 generator는 classification accuracy를 최소로 만들려고 노력할 것이다. 왜냐하면 generator는 discriminator를 속여야하기 때문이다. 즉, generator는 classification accuracy 감소시킬 수 있어야 한다. 이를 기반으로 가장 처음에 GAN 논문에서 제시한 원래의 loss function은 다음과 같다.
는 real image의 distribution, 는 real image sample, 는 latent vector의 distribtuion으로 normal distribution을 가정으로 사용한다. 는 fake image를 의미하게 된다. Discriminator 는 real image 에는 1을 줘야 하고, fake image 에는 0을 줘야 한다. 위의 2개의 term의 구조상 discriminator는 2개의 term 모두 최대로 만들어야 한다. 반면, Generator 는 를 1에 가깝게 만들어야 하기 때문에 를 속여야 한다. 그래서 generator는 오직 2번째 term을 최소로 만들어야 한다.
이때, 우리는 실제로 real image의 distribution을 모르고 있어서 대신에 많은 수의 real image를 sampling함으로써 real image의 근사치를 사용할 수가 있다. 그래서 는 실제로는 많은 수의 real image에 의해서 근사된 결과를 의미하게 된다. 그리고 이것이 GAN에서의 training dataset이 된다.
Generator 는 latent vector에서 real image로의 mapping function이다. 이때 latent vector의 distribution을 N 차원의 noraml distribution으로 가정하고, real image의 distribution의 경우는 임의의 distribution으로 존재할 것이다. Generator를 학습시키는 목적은 image를 sampling할 수 있도록 real image의 probability distribution을 배우게 하는 것이다. 만약 generator가 real image의 distribution을 배우게 된다면 우리는 완벽하게 discriminator를 속일 수 있게 된다.
좀 더 분명히 이야기하자면 의 output이 fake image의 distribution이 되지만, 만약 우리가 계속해서 discriminator를 속이기를 원한다면 fake image의 distribution은 real image의 distribution에 매우 근접해야 한다. 그래서 real image의 distribtuion을 이라고 한다면, real image의 distribution에서 sampling한 data는 로 표기할 수가 있다. 유사하게 fake image의 distribtuion을 이라고 한다면, fake image의 distribution의 sample은 라고 표기하게 된다. 여기서 는 generator의 output으로 가 된다. GAN은 real distribtuion에 근사하며( ), generator는 real distribtuion에 근사하기 위해서 학습이 된다.
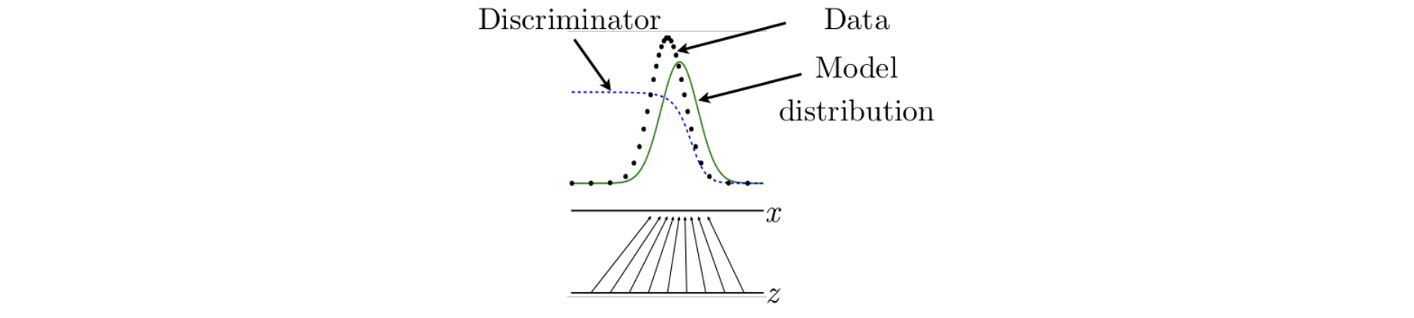 Latent vector space 로부터 임의로 latent vector를 sampling 한다면 generator는 이 latent vector를 image space 에 mapping하기 위해서 학습이 될 것이다. 초록색 선은 model distribtuion, 혹은 fake image의 distribution을 나타내고, 검은 점으로 된 선은 real image의 distribtuion을 나타낸다. 만약 이 2개의 distribution이 서로 매우 근접해있다면 dsicriminator는 이들을 구분할 수 없게 된다. 그렇게 되면 GAN이 성공적으로 학습이 되었다고 이야기할 수 있게 된다.
Latent vector space 로부터 임의로 latent vector를 sampling 한다면 generator는 이 latent vector를 image space 에 mapping하기 위해서 학습이 될 것이다. 초록색 선은 model distribtuion, 혹은 fake image의 distribution을 나타내고, 검은 점으로 된 선은 real image의 distribtuion을 나타낸다. 만약 이 2개의 distribution이 서로 매우 근접해있다면 dsicriminator는 이들을 구분할 수 없게 된다. 그렇게 되면 GAN이 성공적으로 학습이 되었다고 이야기할 수 있게 된다.
Discriminator의 목적은 real image와 fake image를 구분하는 것이다. Image 가 주어졌을 때 optimal discriminator 는 다음과 같이 정의될 수 있다.
는 가 real image일 확률이고, 은 가 model distribtuion으로부터 sampling 될 확률을 의미한다. 즉, 가 fake image일 확률을 말한다. 이는 우리가 discriminator로부터 예상할 수 있는 optimal output이다. 일단 generator가 완전히 학습이 되면 은 와 비슷해야 한다. 그래서 discriminator의 전체 output 는 0.5에 가까워야 한다. Supervised learning을 사용해서 이러한 비율을 예측하는 것은 GAN에 의한 주요 approximation mechanism이다.
GAN Formulation
다음은 GAN의 psuedo-code이다.
 For loop 안에 discriminator update 부분과 generator update 부분이 따로 존재한다.
For loop 안에 discriminator update 부분과 generator update 부분이 따로 존재한다.
Vanilla GAN Examples
다음은 첫번째 GAN 논문에서 보여주는 결과이다.
 결과에서 보이듯이 최초의 GAN 논문에서는 충격적인 결과를 보여줬지만, 실제와 비교했을 때 그리 뛰어난 결과를 만들어내지 못했다. 이 결과들은 GAN에 얼굴 image를 이용해서 만들어낸 결과들이다. 비록 퀄리티가 그리 높지 않더라도, 이러한 결과는 그 당시에는 매우 충격적이었다.
결과에서 보이듯이 최초의 GAN 논문에서는 충격적인 결과를 보여줬지만, 실제와 비교했을 때 그리 뛰어난 결과를 만들어내지 못했다. 이 결과들은 GAN에 얼굴 image를 이용해서 만들어낸 결과들이다. 비록 퀄리티가 그리 높지 않더라도, 이러한 결과는 그 당시에는 매우 충격적이었다.
DCGAN
여러 연구들이 GAN의 퀄리티를 높이기 위해서 있었다. DCGAN도 그 중 하나로 2016년에 "Unsupervised representation learning with deep convolutional generative adversairal networks"라는 논문에서 소개됐다. 이 논문에서 안정적인 학습을 위해서 GAN의 network architecture에 몇가지 제약을 도입했다. 이 논문에서 말하는 문제 중 하나는 GAN 학습의 안정성이다. GAN을 학습한다는 것은 minimzax problem을 푸는 것과 같다. Generator는 loss function을 최소로 만들려고 하고 discriminatro는 loss function을 최대로 만들려고 한다. 우리는 이 둘 사이의 적절한 밸런스를 찾을 필요가 있다. 만약 그렇지 않으면 만족스럽지 못한 결과로 이어지게 될 것이다. 결국 generator나 discriminator가 너무 우세하면 안된다. 이러한 경우에 생긴 image가 바로 부자연스러운 image이다. 이러한 문제를 해결하기 위해 여러가지 방법이 시도되었고 DCGAN이 그 중 하나였다.
학습의 안정성 문제를 해결하기 위해서 DCGAN은 여러 제약을 도입했고, 이를 위해서 여러 실험들이 진행되었다. 실험 결과를 기반으로 DCGAN은 GAN architecture의 가이드라인을 제공했다.
 그리고 다음은 이 논문에서 제안한 network architecture이다.
그리고 다음은 이 논문에서 제안한 network architecture이다.
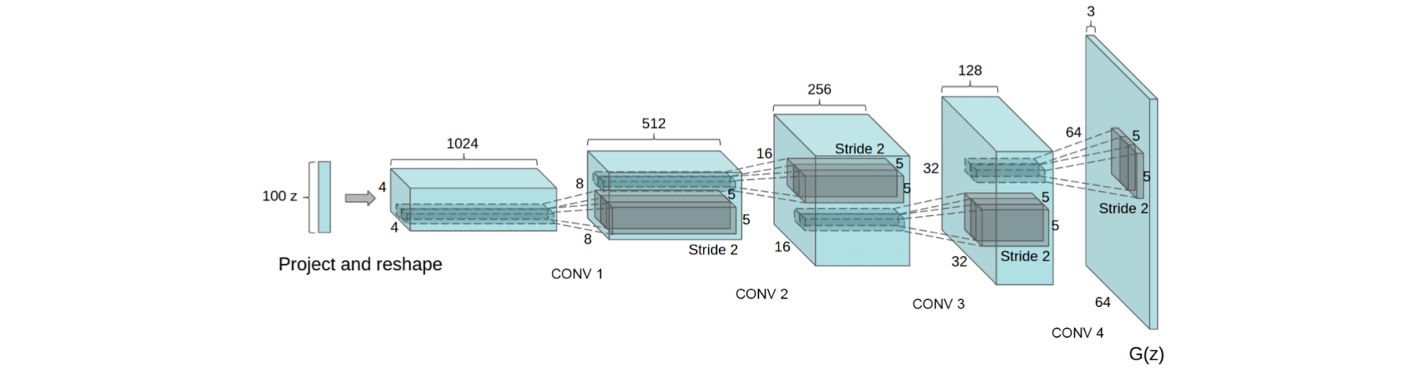 안정된 학습을 위해서 generator는 위와 같은 구조를 가지게 된다. 이 외에도 DCGAN이 가지는 contribtuion은 더 있다. 이 contribtuion이 훨씬 더 중요한 내용을 담고 있다. 이 논문에서는 generator가 vector arithmetic property를 가지고 있음을 보여주었다. 최근에는 이 성질이 매우 유용하게 사용되고 있으며, 여러 image editing application에 적용되고 있다. 자세하게 설명하기 전에 DCGAN의 예시들을 보도록 하자.
안정된 학습을 위해서 generator는 위와 같은 구조를 가지게 된다. 이 외에도 DCGAN이 가지는 contribtuion은 더 있다. 이 contribtuion이 훨씬 더 중요한 내용을 담고 있다. 이 논문에서는 generator가 vector arithmetic property를 가지고 있음을 보여주었다. 최근에는 이 성질이 매우 유용하게 사용되고 있으며, 여러 image editing application에 적용되고 있다. 자세하게 설명하기 전에 DCGAN의 예시들을 보도록 하자.
 DCGAN은 generator의 구조를 업데이트함으로써 더 높은 퀄리티의 결과를 얻을 수 있었다. 이 예시에서는 generator와 discriminator가 실내 image를 사용해서 학습이 진행되었다.
DCGAN은 generator의 구조를 업데이트함으로써 더 높은 퀄리티의 결과를 얻을 수 있었다. 이 예시에서는 generator와 discriminator가 실내 image를 사용해서 학습이 진행되었다.
 이 예시는 generator가 vector arithmetic property를 가지고 있음을 보여주고 있다. Generator가 normal distribtuion으로부터 sampling 된 latent random vector를 사용한다고 해보자. Generator는 latent random vector를 진짜같아 보이는 fake image에 mapping하게 된다. 그래서 우리는 많은 수의 latent random vector를 sampling하고 현실적인 image를 만들어내게 된다.
이 예시는 generator가 vector arithmetic property를 가지고 있음을 보여주고 있다. Generator가 normal distribtuion으로부터 sampling 된 latent random vector를 사용한다고 해보자. Generator는 latent random vector를 진짜같아 보이는 fake image에 mapping하게 된다. 그래서 우리는 많은 수의 latent random vector를 sampling하고 현실적인 image를 만들어내게 된다.
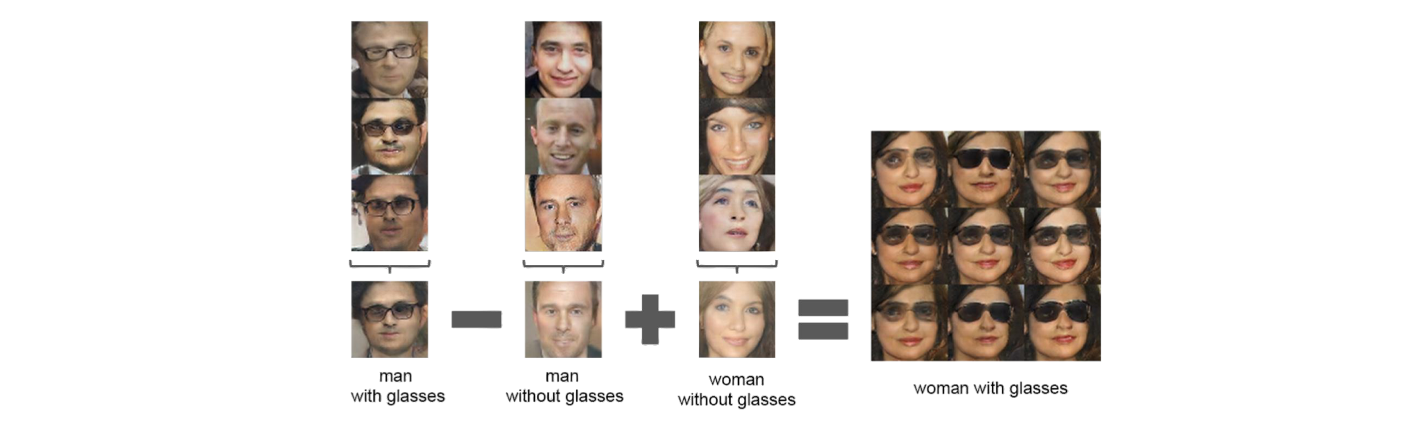
Latent random vector를 사용해서 위와 같이 안경을 쓴 남자, 안경을 쓰지 않은 남자, 그리고 안경을 쓰지 않은 여자로 image들을 나눠볼 것이다. 그리고 각 그룹에서 latent random vector의 평균을 구해서 대표적인 하나의 결과를 각각 만들 것이다. 이렇게 만들어진 평균 latent vector를 generator에 넣으면 대표적인 하나의 fake image를 생성할 수 있게 된다. 원래 각 latent random vector를 generator에 넣어서 fake image를 만들 수 있지만, 평균을 계산해서도 fake image를 만들 수 있다. 이로 보아 latent random vector는 continuous space를 만든다는 것을 알 수 있다.
그리고 여기서 또 할 수 있는 것은 평균 latent vector들을 이용해서 덧셈과 뺄셈 연산을 통해서 새로운 image를 만들어낼 수 있다. 각 그룹에서 평균값을 구한 뒤에 이를 더하고 빼는 연산을 추가로 진행해서 새롭게 구해진 vector를 generator에 넣으면 새로운 fake image를 만들 수 있게 되는 것이다. 이로 인하여 이러한 성질이 여러 image editing 분야에 유용하게 사용될 수 있었다.
Non-Convergence
GAN은 일반적으로 적절하게 학습하는데 어려움이 있다고 했다. GAN의 학습 과정은 neural network의 일반적인 학습 방법과는 차이가 존재한다. 일반적인 학습 과정을 보면 오로지 한명의 선수만이 존재하곤 한다. 즉, 하나의 neural network만이 존재하는 것이다. 하나의 neural network를 학습하는데 있어 예를 들어 SGD 등을 사용해서 loss function을 최소로 만들고자 한다. 그래서 학습의 방향이 단지 하나의 방향으로만 존재해서 항상 적어도 하나의 local minimum을 찾을 수 있다. 이는 convergence가 보장이 된다는 의미이다.
반면, GAN을 학습시키는 경우를 보면 2개의 다른 neural network가 존재한다. 하나는 generator에, 다른 하나는 discriminator에 존재하게 된다. Discriminator는 loss function을 최대로 만들려고 노력하며 generator는 loss function을 최소로 만들려고 노력한다. 그래서 이를 minimax problem으로 정의했던 것이다. 아쉽게도 SGD는 이러한 문제의 해를 찾도록 디자인된 것이 아니다. 즉, generator와 discriminator를 학습할 때 해로 수렴하지 않는 문제가 발생하게 된다. 다음의 예시를 보도록 하자.
 이는 GAN을 학습하는 과정과는 다르지만 훨씬 간다하면서 유사하기에 예로 들었다. Loss function을 2개의 input의 곱으로 나타내었다. 우리는 이 loss function을 에 관해서는 최대로 만들고 싶고, 동시에 에 관해서는 최소로 만들고 싶다.
이는 GAN을 학습하는 과정과는 다르지만 훨씬 간다하면서 유사하기에 예로 들었다. Loss function을 2개의 input의 곱으로 나타내었다. 우리는 이 loss function을 에 관해서는 최대로 만들고 싶고, 동시에 에 관해서는 최소로 만들고 싶다.
초기값으로 두개의 variable 모두 양수라고 가정하자. 그러면 loss function도 자연스럽게 양수가 될 것이다. 에 관해서 loss function을 최대로 만들기 위해서 를 증가시켜야 한다. 동시에 에 관해서 loss function을 최소로 만들기 위해서 를 감소시켜야 한다. 이렇게 한번 업데이트를 하고난 이후에 는 음수를, 는 양수를 가지게 된다. 그러면 다시 loss function은 음수가 된다. 다시 loss function을 에 관해서 최대로 만들고 에 관해서 최소로 만들기 위해서 이번에는 모두 감소시켜야 한다. 왜냐하면 현재 ㅣoss function은 음수이기 때문이다. 두번째로 업데이트를 한 후에 2개의 variable 모두 음수를 가지게 된다. 그래서 loss function은 양수가 된다. 이번 경우에는 loss function을 에 관해서 최대로 만들기 위해서 를 감소시켜야 한다. 그리고 에 관해서 최소로 만들기 위해서 는 증가시켜야 한다. 이렇게 업데이트를 한 후에 는 양수, 는 음수가 될 것이다. 다시 loss function은 음수가 되고, 다시 모두 증가시켜야 한다. 이렇게 state 5까지 도달하면 다시 state 1과 동일한 상태가 된다.
이러한 과정에서 convergence가 존재하지 않게 되고, 학습 과정이 계속해서 반복되게 된다. 그래서 GAN을 학습하는 과정에서 해로 수렴한다는 것을 보장할 수가 없게 된다. 이것이 하나의 issue이다.
Mode Collapse
GAN을 학습하는데 있어 또 다른 issue로는 mode collapse가 있다. 다음과 같이 target distribtuion이 있다고 가정하자.  Generator를 학습시킴으로써 얻고자 하는 것은 target distribtuion을 근사시키는 것이다. 그래서 generator를 학습해서 다음과 같은 model distribtuion을 얻고싶다.
Generator를 학습시킴으로써 얻고자 하는 것은 target distribtuion을 근사시키는 것이다. 그래서 generator를 학습해서 다음과 같은 model distribtuion을 얻고싶다.
 가장 우측의 결과는 정확하게 target distribution에 근사한 것을 볼 수 있다. 그러나 현실에서 model distribtuion은 다음과 같이 존재하게 된다.
가장 우측의 결과는 정확하게 target distribution에 근사한 것을 볼 수 있다. 그러나 현실에서 model distribtuion은 다음과 같이 존재하게 된다.
 예를 들어 개, 고양이, 말의 image들이 있다고 생각해보자. 만약 generator가 적절하게 학습이 되었다면 3개의 image 모두 제대로 만들어낼 수 있어야 한다. 그러나 현실에서 generator를 학습했다면 generator가 오로지 고양이 image만을 만들었을 가능성이 크다. 만약 generator가 3개 다는 아지만 1개라도 현실적인 fake image를 만들어냈다면 이 image를 통해서 discriminator를 완벽하게 속일 수가 있다. GAN을 학습하는데 사용되는 loss function에서 discriminator는 generator가 정말로 다양한 image를 만들었다고 말할 수 없다. Discriminator는 input image가 real image인지 fake image인지를 구분할 수 있도록 학습이 되는데 이러한 경우에는 output이 다양한지 아닌지 말할 수가 없어진다. 그래서 generator가 1개라도 현실적인 fake image를 만들어낸다면 discriminator를 완벽하게 속일 수가 있다. 이러한 문제를 mode collapse라고 한다.
예를 들어 개, 고양이, 말의 image들이 있다고 생각해보자. 만약 generator가 적절하게 학습이 되었다면 3개의 image 모두 제대로 만들어낼 수 있어야 한다. 그러나 현실에서 generator를 학습했다면 generator가 오로지 고양이 image만을 만들었을 가능성이 크다. 만약 generator가 3개 다는 아지만 1개라도 현실적인 fake image를 만들어냈다면 이 image를 통해서 discriminator를 완벽하게 속일 수가 있다. GAN을 학습하는데 사용되는 loss function에서 discriminator는 generator가 정말로 다양한 image를 만들었다고 말할 수 없다. Discriminator는 input image가 real image인지 fake image인지를 구분할 수 있도록 학습이 되는데 이러한 경우에는 output이 다양한지 아닌지 말할 수가 없어진다. 그래서 generator가 1개라도 현실적인 fake image를 만들어낸다면 discriminator를 완벽하게 속일 수가 있다. 이러한 문제를 mode collapse라고 한다.
그래서 다시 위의 예시로 돌아가면 target distribution이 real image의 distribution이라 했을 때 각각의 point를 개, 고양이, 말과 같은 동물로 분류할 수가 있다. 그리고 generator는 오로지 말을 만들어내도록 학습이 된 것이다. 다음은 mode collapse의 실제 예시들이다.
 같아보이지만 모두 다른 latent random vector로부터 만들어진 fake image이다. 그래도 우리가 보기에는 모두 비슷한 개체를 보여주고 있는 것 같다는 생각을 할 수 있다. 이러한 issue는 정말로 다루기 어려운 문제이며 여러 시도들이 지금까지 있었고 여전히 이 문제를 해결하려고 여러 연구들이 진행되고 있다.
같아보이지만 모두 다른 latent random vector로부터 만들어진 fake image이다. 그래도 우리가 보기에는 모두 비슷한 개체를 보여주고 있는 것 같다는 생각을 할 수 있다. 이러한 issue는 정말로 다루기 어려운 문제이며 여러 시도들이 지금까지 있었고 여전히 이 문제를 해결하려고 여러 연구들이 진행되고 있다.
PGGAN
GAN의 퀄리티와 안정성을 높이기 위한 연구들이 많이 있으며, 2018년도에 "Progressiv Grwoing of GANs for improved quality, stability, and variation" 논문에서 PGGAN을 소개했다.
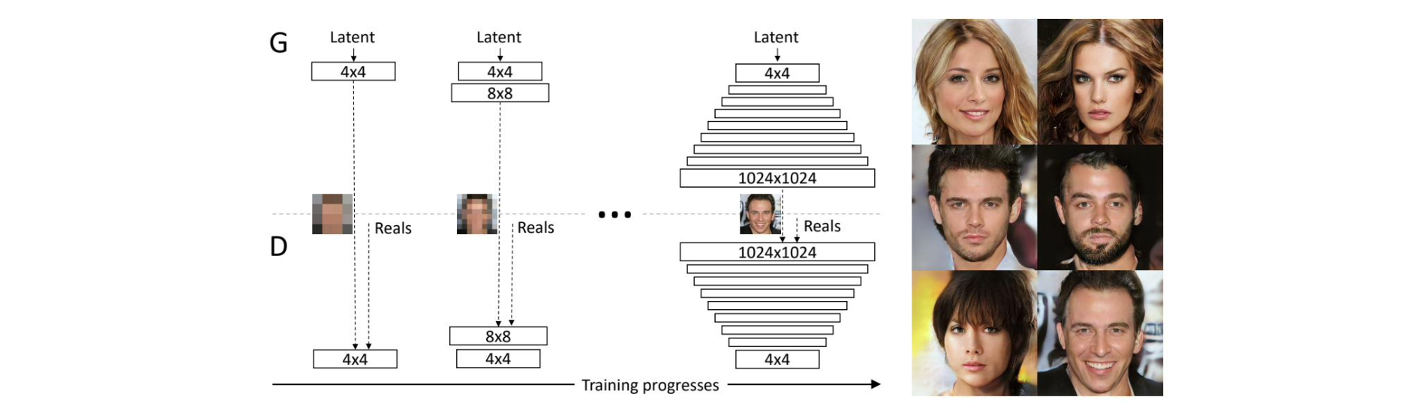 PGGAN은 정말로 인상적인 결과를 만들어냈다. PGGAN은 의 고해상도 image를 만들어낼 수 있다. 이 논문에서 한 것은 generator와 discriminator의 학습하는 과정에서 초기에 generator와 discriminator를 위한 작은 neural network를 build했다. 이 작은 network는 매우 작은 image를 만들어내는데 그쳤다. 그리고 discriminator는 이 작은 image를 사용해서 input image가 real image인지 fake image인지 구분하도록 했다. 이 image는 고작 16개의 pixel을 가지고 있는 저해상도 image이다. 그래서 generator가 현실적인 image를 만들어내도록 학습하는데 굉장히 쉬워진다. 피부 톤에 근접한 몇개의 값만 사용해서 현실적으로 만들 수가 있다. 그러면 이를 이용해서 쉽게 discriminator도 속일 수가 있다. 일단 이렇게 저해상도의 image를 이용해서 학습이 끝나게 되면 새로운 neural network block을 discriminator에 추가하게 된다. 그러면 추가된 network는 output을 기반으로 image를 만들어내고 discriminator 또한 image를 이용해서 학습을 하고 real image와 fake image를 구분하게 된다. 그래서 이 과정에서는 이전의 image보다 높은 해상도의 image를 만들어낼 수 있어서 이제는 이 과정에서 추가된 block이 image에 대해서 쉽게 학습이 될 수가 있다. 그리고 또 다시 학습이 마치게 되면 또 다른 neural network block을 추가하게 된다. 이렇게 계속 진행하다보면 결국에 고해상도의 image를 만들어낼 수가 있다. 이러한 방식을 coarse to fine approach라고 한다.
PGGAN은 정말로 인상적인 결과를 만들어냈다. PGGAN은 의 고해상도 image를 만들어낼 수 있다. 이 논문에서 한 것은 generator와 discriminator의 학습하는 과정에서 초기에 generator와 discriminator를 위한 작은 neural network를 build했다. 이 작은 network는 매우 작은 image를 만들어내는데 그쳤다. 그리고 discriminator는 이 작은 image를 사용해서 input image가 real image인지 fake image인지 구분하도록 했다. 이 image는 고작 16개의 pixel을 가지고 있는 저해상도 image이다. 그래서 generator가 현실적인 image를 만들어내도록 학습하는데 굉장히 쉬워진다. 피부 톤에 근접한 몇개의 값만 사용해서 현실적으로 만들 수가 있다. 그러면 이를 이용해서 쉽게 discriminator도 속일 수가 있다. 일단 이렇게 저해상도의 image를 이용해서 학습이 끝나게 되면 새로운 neural network block을 discriminator에 추가하게 된다. 그러면 추가된 network는 output을 기반으로 image를 만들어내고 discriminator 또한 image를 이용해서 학습을 하고 real image와 fake image를 구분하게 된다. 그래서 이 과정에서는 이전의 image보다 높은 해상도의 image를 만들어낼 수 있어서 이제는 이 과정에서 추가된 block이 image에 대해서 쉽게 학습이 될 수가 있다. 그리고 또 다시 학습이 마치게 되면 또 다른 neural network block을 추가하게 된다. 이렇게 계속 진행하다보면 결국에 고해상도의 image를 만들어낼 수가 있다. 이러한 방식을 coarse to fine approach라고 한다.
 PGGAN의 결과들을 보면 정말로 퀄리티가 높은 것을 볼 수 있다. 그러나 몇몇 결과들을 보면 눈이 없다거나 머리가 2개가 생기는 문제가 아직 남아있음을 볼 수 있다. 그래도 이전의 GAN 결과보다는 퀄리티가 높은 것은 자명하다.
PGGAN의 결과들을 보면 정말로 퀄리티가 높은 것을 볼 수 있다. 그러나 몇몇 결과들을 보면 눈이 없다거나 머리가 2개가 생기는 문제가 아직 남아있음을 볼 수 있다. 그래도 이전의 GAN 결과보다는 퀄리티가 높은 것은 자명하다.
StyleGAN
위에서 본 coarse to fine approach는 styleGAN에서도 사용이 되었다. StyleGAN은 GAN 중에서도 SOTA의 성능을 보여주며 2019년도에 "A Style-Based Generator Architecture for Generative Adversairal Networks"라는 논문에서 소개되었다.
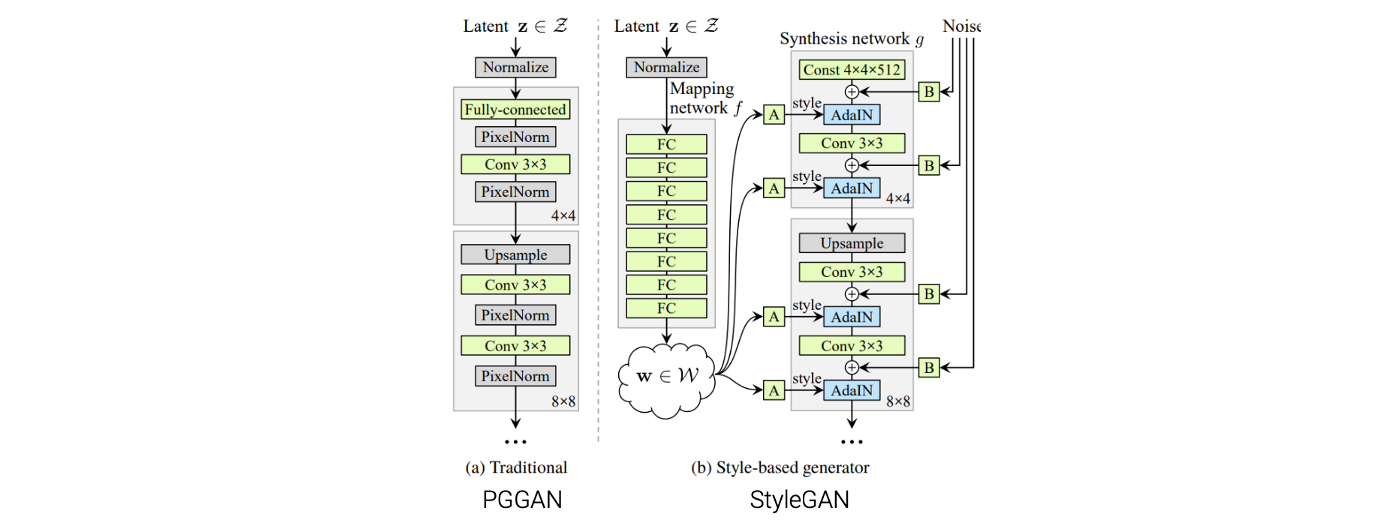 이 StyleGAN은 coarse to fine approach를 사용한 architecture로 이루어져 있으며, generator의 구조 역시 coarse to fine structure를 가지고 있다. Coarse scale image를 다루는 것부터 해서 fine scale image까지 다루게 된다.
이 StyleGAN은 coarse to fine approach를 사용한 architecture로 이루어져 있으며, generator의 구조 역시 coarse to fine structure를 가지고 있다. Coarse scale image를 다루는 것부터 해서 fine scale image까지 다루게 된다.
더불어 styleGAN에서는 mapping network라는 것도 도입했다. 이전의 GAN architeture에서는 전형적으로 latent random vector 가 바로 generator에 input으로 사용되어 라는 output으로 fake image를 만들어냈다. 여기서 는 normal distribution을 따른다는 가정이 있었다. 이 normal distribtuion은 latent random vector에 대해서 최적의 선택이 아닐지도 모른다.
StyleGAN은 mapping network를 도입해서 latent random vector 를 normal distribtuion에서 sampling을 하고 mapping network를 여기서 사용해서 intermediate latent vecotr 로 연결시켜준다. 그리고 이 는 generator의 input으로 사용되고 를 만들어내게 된다. space에는 image와 관련된 더 좋은 성질들이 많이 있어서 서로 잘 엉키지 않아서 를 사용하면 image와 관련된 좋은 성질들을 사용할 수 있게 된다. 이 논문에서는 space를 사용하면 더 쉽게 좋은 성질들을 많이 추가할 수 있다고 말했다.
다시 위의 network architecture를 보면 mapping network가 latent vector 를 input으로 사용해서 로 연결시키는 것을 볼 수 있다. 그러면 transformed latent random vector 는 여러 network layer에 들어가게 되어 generator는 이 를 기반으로 하여 image를 만들어내게 된다. 디테일하게 는 AdaIN layer에 사용이 되어 각 scale마다 image의 style을 변경시켜준다. 그리고 는 자세, 머리, 주근깨 등 high-level의 특징들을 쉽게 다룰 수 있게 해준다.
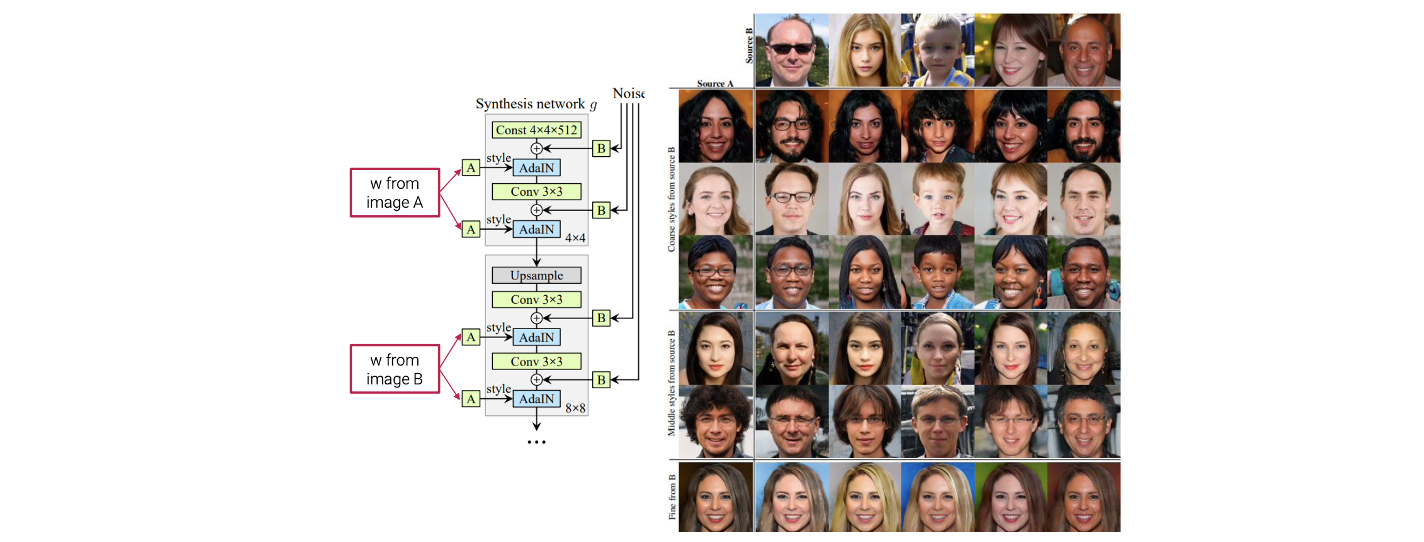 예를 들어 서로 다른 로부터 를 얻어서 generator의 서로 다른 부분에 사용될 수 있다. 이렇게 되면 우리는 서로 다른 style을 섞어서 사용이 가능해진다. 가로와 세로를 보면 서로 다른 로부터 sampling을 한 것이고, mapping network를 이용해서 서로 다른 를 만들어낼 수 있다. 만약 coarse scale에서 가로의 를 사용하고 fine scale에서 세로의 를 사용한다면 이들을 서로 섞어서 새로운 image를 만들어낼 수 있다. 가로의 pose와 세로의 texture를 섞는 것이 가능하다는 이야기이다.
예를 들어 서로 다른 로부터 를 얻어서 generator의 서로 다른 부분에 사용될 수 있다. 이렇게 되면 우리는 서로 다른 style을 섞어서 사용이 가능해진다. 가로와 세로를 보면 서로 다른 로부터 sampling을 한 것이고, mapping network를 이용해서 서로 다른 를 만들어낼 수 있다. 만약 coarse scale에서 가로의 를 사용하고 fine scale에서 세로의 를 사용한다면 이들을 서로 섞어서 새로운 image를 만들어낼 수 있다. 가로의 pose와 세로의 texture를 섞는 것이 가능하다는 이야기이다.
